Duplex Model of Vision
1/97
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
98 Terms
What does it mean to say “vision is not veridical”?
It means vision doesn’t give us an exact, perfect copy of the world. Instead, our perception is constructive
Why is vision considered constructive?
Because the brain can’t represent every single detail of the world. Instead, it distills sensory input into a simplified model that includes rules and predictions about the environment. This mental model is useful for understanding the world, but it’s not a perfect replica of reality.
What limits our visual processing?
Our brain’s processing capacity, it can only handle so much information at once. So vision prioritises certain features and makes predictions rather than processing every detail.
How does the brain’s constructive vision affect perception of reality?
It means what we “see” is actually a mental interpretation shaped by past experiences, rules, and predictions. This is why visual illusions work, they exploit the brain’s shortcuts for building reality.
What are Kanizsa figures in vision science?
They’re visual illusions where the brain perceives shapes or edges that aren’t physically there. They show how vision is constructive — the brain fills in missing information to create a coherent image.
What do most people see when looking at Kanizsa figures?
Most see a white square lying on top of four black circles, even though no square actually exists. The shape is created by the brain interpreting the arrangement of the shapes.
How does the brain create the illusion in Kanizsa figures?
The brain “fills in” edges and surfaces based on surrounding shapes and patterns. In this case, the four “pacman” shapes arranged in a certain way trick the brain into perceiving a square that isn’t there.
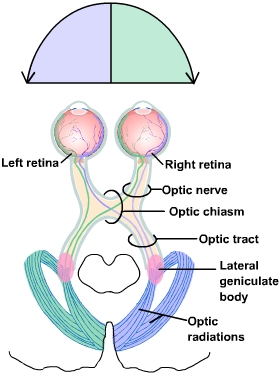
What is the optic nerve?
The optic nerve carries visual information from the retina of each eye toward the brain. Each eye has its own optic nerve. Think of it as the “visual cable” connecting your eye to your brain.
What is the optic chiasm and why is it important?
The optic chiasm is where some of the nerve fibres from each eye cross over to the opposite side of the brain. Specifically, information from the nasal hemiretina crosses over to the other hemisphere, while the temporal hemiretina stays on the same side. This allows the brain to process the left visual field in the right hemisphere and the right visual field in the left hemisphere.
What is the optic tract?
The optic tract is the bundle of nerve fibres that continues from the optic chiasm to the brain. It carries visual information for the opposite visual field (e.g., the left optic tract carries information from the right visual field).
What is the lateral geniculate nucleus (LGN) of the thalamus?
The LGN is a relay station in the thalamus where most visual information is processed before being sent to the cortex. It’s called “geniculo” in the geniculostriate pathway because this is the key station in the pathway.
What is the optic radiation?
Optic radiation is the bundle of nerve fibres that carries visual information from the LGN to the primary visual cortex (V1). You can think of it as the last stretch of the “visual highway.”
What is the primary visual cortex (V1)?
Also called the striate cortex, V1 is where visual information first arrives in the cerebral cortex. It processes the basic features of vision such as edges, orientation, and motion before passing it on to higher visual areas.
What is the primary geniculostriate pathway?
It’s the main pathway for visual information:
Retina → Optic nerve → Optic chiasm → Optic tract → Lateral geniculate nucleus (LGN) → Optic radiation → Primary visual cortex (V1).
What happens to visual information after it leaves the primary visual cortex (V1)?
It moves forward through the visual system to higher-order visual areas. These areas process more complex aspects of visual information, such as motion, depth, and object recognition.
If you see a moving car, V1 processes the basic lines and edges, while later areas (like V5) interpret the motion and areas in the ventral stream identify the car as a “red sedan.”
What does Brodmann’s atlas tell us about visual cortex organisation (V1, V2, etc?
It shows cytoarchitectonic differences — basically differences in how cells are structured and arranged — across different parts of the visual cortex. These differences mean each area specialises in processing certain types of visual information as it moves along.
The primary visual cortex (V1) detects edges, while later areas like V4 specialise in colour perception.
What was Luria’s classification of visual cortex organisation?
Luria divided the visual cortex into primary, secondary, and tertiary visual cortex, representing a hierarchy from basic to complex visual processing.
detecting edges first, then shapes, and finally recognising objects
Why do modern neuroscientists find Luria’s hierarchy overly simplistic?
Research shows the primate visual system isn’t just a simple primary–secondary–tertiary hierarchy — it has specific areas that each handle different kinds of visual processing
One area processes motion, another processes colour, and another processes object shapes
What is the duplex model of vision
The duplex model of vision comes from years of primate research and shows that visual information from the primary visual cortex (V1) travels along two main pathways. These are the dorsal stream and ventral stream, each specialised for different parts of how we see.
they come after V1
Where do the two visual processing pathways originate and where do they project?
Both pathways originate in the primary visual cortex (V1).
Dorsal stream: Projects from V1 to the posterior parietal cortex.
Ventral stream: Projects from V1 to the inferior temporal cortex.
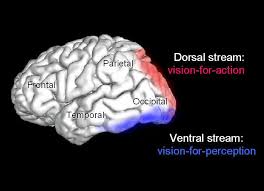
What are the names and functions of the two pathways according to Ungerleider and Mishkin?
Dorsal stream (“where” pathway): Helps you figure out where a coffee mug is on a table and track it if someone moves it.
Ventral stream (“what” pathway): Helps you recognise the mug as ceramic, red, and round, and distinguish it from other objects.
Who were Mel Goodale and David Milner, and what was their contribution to the duplex model of vision?
Mel Goodale and David Milner were neuroscientists who challenged the original “what vs. where” idea from Ungerleider and Mishkin. Based on research with a patient called DF, they suggested the dorsal stream should be seen as a “how” pathway, focusing more on guiding actions than just processing where things are.
Who is patient DF and why is she important in vision research?
Patient DF had visual form agnosia, meaning she couldn’t recognise shapes or objects even though her vision was otherwise normal. Her condition gave key insights into how vision works, showing that recognising objects and using vision to guide actions can happen separately in the brain
What change did Goodale and Milner propose for the dorsal stream?
They proposed that instead of the dorsal stream being a “where” pathway (for object location), it should be understood as a “how” pathway, specialised for visual guidance of action — such as reaching, grasping, or manipulating objects. This reframing highlights the dorsal stream’s role in linking vision to motor control.
Did Goodale and Milner change the ventral stream’s function?
No. Goodale and Milner left the ventral stream’s function unchanged. It remained the “what” pathway, responsible for object recognition and perception — identifying shapes, colours, and textures
How does the “how” pathway concept change our understanding of vision?
It shifts the focus from purely spatial processing to understanding vision as involving two complementary systems:
The ventral stream (“what”) processes object identity and perception.
The dorsal stream (“how”) processes visual information needed for guiding actions in real time, showing vision’s direct link to behaviour.
When picking up a coffee mug, the ventral stream helps you recognise it as a mug, while the dorsal stream guides your hand to grab it correctly. - interaction with objects
What is the geniculostriate pathway, and why is it important for vision?
The geniculostriate pathway is the main route that takes visual information from the retina to the primary visual cortex (V1) through the lateral geniculate nucleus (LGN) in the thalamus. It’s key for detailed visual processing and underlines our understanding of the “what’ and “where” pathways. Differences in how this pathway is built and works help explain why these pathways have different functions
What are the distinct layers of the dorsal LGN
Parvocellular (P) layers
Magnocellular (M) layers
Magnocellular layers
The magnocellular layers (M-layers) in the LGN are the parts that get input from parasol ganglion cells in the retina. These cells are large and fast, and they’re especially good at picking up motion, flicker, and broad outlines.
spot a ball quickly flying toward you, even if you can’t yet see its colour or fine details. They’re tuned to motion and speed, not detail
Parvocellular (P)
The parvocellular layers (P-layers) receive input from midget ganglion cells, allowing for high-resolution vision and colour perception, such as recognising the fine details and colours of a flower.
help you see the vibrant colours and tiny patterns on a butterfly’s wings.
What are the physical differences between magnocellular and parvocellular projections?
Magnocellular projections: Large ganglion cells with large receptive fields.
Parvocellular projections: Small ganglion cells with small receptive fields
cell size = receptive field size. Big cells pull info from wide areas (good for motion), while small cells pull info from narrow areas (good for detail).
What are the functional differences between magnocellular and parvocellular cells?
Magnocellular cells:
Fast, transient responses.
Sensitive to low contrast.
Insensitive to colour.
Optimised for motion detection and spatial awareness.
Parvocellular cells:
Slow, sustained responses.
Sensitive to high contrast.
Sensitive to colour.
Optimised for object recognition and fine detail processing.
How do these functional differences relate to the “what” and “where” pathways?
Magnocellular pathway: Supports the dorsal stream (“where” pathway) because it processes motion and spatial location with fast, transient responses.
Parvocellular pathway: Supports the ventral stream (“what” pathway) because it processes object identity with sustained, colour-sensitive responses.
What is the role of koniocellular (K) layers in visual processing?
Koniocellular layers sit between the parvocellular and magnocellular layers in the LGN. They send signals to other parts of the visual cortex and tend to process information similar to the nearby layers. For example, if a nearby P-layer is colour-sensitive, the adjacent K-layer will usually be too. This means K-cells have specialised but complementary roles in vision.
How does this understanding of the LGN layers enrich the duplex model of vision?
It shows that the split between “what” and “where” pathways starts pretty early — right in the LGN. The P-, M-, and K-layers each handle different types of visual info and send it to specialised parts of the cortex, which helps explain why the dorsal and ventral streams process vision in different ways.
Are M and P projections completely isolated in the dorsal and ventral visual pathways?
No. While M (magnocellular) projections mainly support the dorsal stream (“Where/How”) and P (parvocellular) projections mainly support the ventral stream (“What”), they aren’t completely separate — there’s plenty of overlap and communication between the two.
What does recognising an object involve, and which pathway is responsible for it?
Recognising an object involves identifying its shape, colour, and texture despite changes in size, lighting, orientation, or viewpoint. This ability is handled by the ventral stream (“What” pathway), which is specialised for stable object recognition across varied conditions.
What makes recognising ‘what’ something is so reliable despite changes in how it looks?
Because the ventral stream processes visual info in a way that ignores changes like size, angle, or lighting. This helps us recognise an object’s identity even when it looks different on the retina.
What does picking up an object involve, and which pathway is responsible?
Picking up an object involves calculating its location relative to your body, its orientation, and other dynamic details such as how much of it remains and how heavy it is. These calculations are handled by the dorsal stream (“Where/How” pathway), which specialises in guiding real-time action.
Why does picking up an object require different processing than recognising it?
Because action depends on precise, moment-to-moment information. For example:
Location of the object (where)
Orientation of the object (how to grasp it)
Position relative to your hand
Physical properties (weight, texture, stability)
The dorsal stream constantly updates these details as conditions change, unlike the ventral stream’s relatively stable object recognition.
What are “effector-based” and “scene-based” reference frames, and which pathways use them?
Effector-based reference frames: Used by the dorsal “how” pathway to figure out positions relative to your own body (like where to place your feet).
Scene-based reference frames: Used by the ventral “what” pathway to figure out positions relative to other objects or the scene (like how dancers are arranged on stage).
How do the representations in the dorsal and ventral pathways differ in duration?
Dorsal “how” pathway: Representations are transient — constantly updated for moment-to-moment action adjustments.
Ventral “what” pathway: Representations are long-term — based on stored knowledge and past experience to recognise objects or scenes.
You learn swing dancing over time. Your ventral pathway maintains a long-term representation of the dance style, while your dorsal pathway continually updates your foot and hand placement in real time.
How can we measure differences in processing between visual pathways?
One approach is to measure the kinematics of movements — analysing how the body moves in precise tasks under different conditions
What is meant by “measuring action vs perception”
It means distinguishing between how the brain processes information to:
Perceive (recognise objects, shapes, or scenes — ventral “what” pathway)
Act (guide movement and interaction with objects — dorsal “how” pathway)
Different experimental tasks are used to measure these processes separately.
How does a precision grip experiment measure action?
By analysing movement kinematics — how the fingers and thumb adjust during a precision grip. Measurements such as grip aperture, velocity, and acceleration profiles reveal how visual information is used to control moment-to-moment action via the dorsal “how” pathway.
How does the precision grip experiment differ from measuring perception?
ction measurement: Requires actual movement and precise motor control (e.g., picking up an object). It captures the real-time guidance of action by the dorsal stream.
Perception measurement: Requires judgement without movement (e.g., estimating size or recognising shape). It engages the ventral “what” pathway
What makes the precision grip a good tool for measuring differences between action and perception?
Because it involves fine motor control that relies on precise, short-term visual info, which is what the dorsal stream specialises in, it lets researchers focus on action-related processing and compare it to perception tasks handled by the ventral stream.
How does kinematic analysis in a precision grip experiment answer questions about the division between action and perception?
It shows that:
Action (dorsal pathway) depends on moment-to-moment (constantly updating) kinematic adjustments.
Perception (ventral pathway) is more stable and doesn’t require continuous recalculation.
This provides empirical evidence for the two visual pathways theory and shows how they are functionally distinct.
What is the Ebbinghaus/Titchener illusion?
A size-contrast illusion where two identical central circles appear different in size depending on the size of surrounding circles.
Central circle surrounded by small circles → appears larger.
Central circle surrounded by large circles → appears smaller.
How was the Ebbinghaus illusion used by Aglioti et al. (1995) to study visual processing?
Participants were asked to:
Grasp the central circle (action task).
Estimate its size (perception task).
This tested whether the illusion affected both tasks equally.
What were the main findings of Aglioti et al. (1995)? - from the Ebbinghaus illusion
Perception task (ventral stream): Manual size estimates were fooled by the illusion → the central circle surrounded by small circles was judged larger than it actually was.
Action task (dorsal stream): Grip aperture was not affected by the illusion → adjusted to the true size of the circle.
This showed a functional separation between perception and action pathways.
What happened when there was a delay between viewing the illusion and grasping the object? - Ebbinghaus
Grip size was affected by the illusion, which suggests the dorsal “how” pathway uses short-term visual info for guiding actions. Without a need for immediate action, it leans more on perception-like info — which makes it more likely to be fooled by illusions.
How does the Ebbinghaus illusion support the duplex model of vision?
It provides evidence that:
The dorsal stream is specialised for real-time, accurate action control and is normally immune to visual illusions.
The ventral stream is specialised for visual perception and is influenced by context and illusions.
What is optic ataxia?
It’s a disorder caused by damage to the superior parietal lobe, where a person can still see normally but struggles to use vision to guide their actions.
What task was the patient asked to perform in the video demonstration? - optic ataxia
To fixate on a central point (the student’s nose) while reaching out with either hand to grasp a pencil placed in her left or right visual field.
What deficit does optic ataxia reveal about dorsal stream function?
It shows that damage to the dorsal “how” pathway disrupts the ability to translate visual input into accurate, coordinated reaching/grasping movements.
How does optic ataxia differ from a purely motor problem?
The issue is not with muscle strength or movement itself but with using visual information to guide the action — a visuomotor transformation deficit.
How does optic ataxia support the duplex model of vision?
It demonstrates that perception (ventral stream) can remain intact (the patient can still see and identify the object), while action (dorsal stream) is impaired.
What is visual form agnosia (apperceptive agnosia)?
A disorder caused by ventral stream damage where patients cannot recognize objects using vision alone, despite intact basic visual processing.
How does visual form agnosia differ from optic ataxia?
In visual form agnosia, recognition (ventral “what” pathway) is impaired but visually guided action (dorsal “how” pathway) can remain intact. In optic ataxia, the reverse occurs.
Can patients with visual form agnosia identify objects through other senses?
Yes — when allowed to touch an object, they can typically name it and describe its function, showing intact semantic knowledge and memory.
What does visual form agnosia reveal about ventral stream function?
It highlights the role of the ventral stream in object recognition and visual perception, separate from motor control.
Why is visual form agnosia important for the duplex model of vision?
It provides evidence for a double dissociation with optic ataxia: ventral damage impairs perception but spares action, whereas dorsal damage impairs action but spares perception.
How do visual form agnosics perform when copying drawings?
They cannot copy faithfully; their drawings appear fragmented, reflecting their conscious perceptual experience of disjointed visual components rather than whole images.
What do fragmented copies by visual form agnosics reveal?
They indicate that their perceptual system struggles to integrate visual components into a coherent whole, consistent with ventral stream damage.
How do visual form agnosics perform when asked to draw from memory?
Their drawings from memory are at least recognisable as the intended object, showing intact semantic knowledge and stored visual representations.
What does the difference between copying and memory drawing show?
It highlights a dissociation: visual perception of form is impaired, but stored representations in memory remain intact.
What is Balint’s syndrome
rare neurological condition that arises from bilateral damage to the posterior parietal lobes (often due to stroke
What three symptoms make up Balint’s syndrome?
Psychic paralysis of gaze (hyperfixation, difficulty shifting gaze),
Simultanagnosia (inability to perceive more than one object at a time),
Optic ataxia (misreaching for peripheral objects).
What task did Goodale’s group use to test patient DF (visual form agnosia)?
A posting vs. matching task:
Posting a letter into a slot.
Matching the letter’s orientation to the slot.
How did DF perform on the posting task vs. the matching task?
Posting: Successful — she could insert the letter correctly, showing intact dorsal stream function for guiding action.
Matching: Performed at chance, showing impaired ventral stream object recognition.
What was David Milner’s early observation with DF and a pencil?
When asked to identify a pencil, she could not (ventral deficit). But instinctively, she reached out and grasped it accurately — showing preserved dorsal stream processing of the object’s physical properties.
What does DF’s behaviour demonstrate about dorsal vs. ventral processing?
The dorsal stream supports real-time action guidance (posting, grasping) even without conscious object recognition, while the ventral stream supports conscious perception and identification.
In an experiment testing visual pathways, DF (with visual form agnosia) and RV (with optic ataxia) were asked to grasp irregularly shaped objects. Why was this task challenging, and how is success usually measured?
Efficient grasping requires picking objects up along their principal axes, the most stable grasp points. Success is measured by whether participants choose these stable points.
How did healthy control participants perform when grasping irregularly shaped objects along their principal axes?
Healthy controls had no difficulty and reliably chose the stable grasp points.
How did DF, the patient with visual form agnosia (ventral stream damage), perform on the irregular shape grasping task?
DF grasped objects efficiently along the principal axes, even though she could not consciously discriminate one shape from another.
How did RV, the patient with optic ataxia (dorsal stream damage), perform on the irregular shape grasping task?
RV could visually discriminate shapes, but often chose unstable grasp points when attempting to pick them up.
What does the comparison between DF’s and RV’s performance on the irregular shape task reveal about the two visual streams?
It demonstrates a double dissociation:
DF (ventral damage) → impaired conscious recognition, intact action guidance.
RV (dorsal damage) → intact recognition, impaired action guidance.
Why is it important to understand the consequences of damage to V1 when studying visual pathways?
Because V1 is the main entry point for most visual information into the cortex. Damage to V1 reveals how vision changes without this processing and highlights the existence of alternative visual pathways.
What is the “blind spot” in human vision, and how does it illustrate the constructive nature of vision?
The blind spot is a small area between our eyes where no visual information is detected because of the optic nerve head. The brain “fills in” missing information so we don’t notice it in everyday vision.
How often are we effectively “blind” due to natural causes like blinking or blind spots?
Estimates suggest we experience the equivalent of being blind for nearly 4 hours a day due to blinking alone — yet we never consciously notice this.
What does the fact that we don’t perceive gaps from blind spots or blinks tell us about vision?
Vision is constructive — the brain actively integrates and fills in missing visual information so we perceive a seamless visual world rather than experiencing frequent gaps.
What is the blind spot in human vision and why does it exist?
The blind spot is a portion of the visual field where there are no ganglion cells because the optic nerve exits the retina. This means there is no visual processing for that area.
How does eye movement influence perception of the blind spot?
Our eyes make frequent saccades (quick movements) about every ~200 milliseconds. This constantly changes where the blind spot falls in our visual field, so the brain resamples the world continually.
What does the blind spot experiment tell us about vision?
Vision is active and constructive. The brain doesn’t passively receive sensory data but integrates and infers missing information to maintain a continuous perceptual experience.
What is homonymous hemianopia?
A condition where a person loses half of their visual field in both eyes, typically caused by damage to the primary visual cortex (V1) or optic radiation.
In the representation of homonymous hemianopia, what does the black spot represent?
It represents the blind spot in the visual field for the affected side — in this case, the blind spot for the left eye’s visual field.
What did Lawrence Weiskrantz and colleagues discover in the early 1970s about patients with homonymous hemianopia?
They found that some patients could process stimuli in their blind field at above chance levels, despite reporting no conscious awareness of seeing anything.
How does blindsight challenge the idea that V1 is absolutely necessary for vision?
Blindsight shows that some visual information can still be processed without V1, meaning there are other pathways that can carry visual data to higher brain areas.
Can visual information travel without passing through V1?
Yes — secondary pathways can carry visual information to the brain without going through V1.
What are the main secondary visual pathways that bypass V1?
Direct projections through the superior colliculus.
Connections via the pulvinar that reach extrastriate cortex.
Direct projections through the superior colliculus
The superior colliculus is a part of the midbrain that helps control quick eye and head movements. Some visual info skips V1 and goes straight through it, letting you react fast to things — like turning your head when something suddenly moves in your peripheral vision.
Connections via the pulvinar that reach extrastriate cortex
The pulvinar is a thalamus area that acts like a relay station. It gets visual info (including some that skips V1) and sends it to higher visual areas in the extrastriate cortex. This helps with visual processing when V1 isn’t fully involved and plays a role in attention and noticing where things are.
If you’re distracted while walking and suddenly notice something moving out of the corner of your eye, the pulvinar helps pass that information to higher visual areas so you can quickly pay attention to it — even without fully processing it through V1 first.
Why is the existence of these alternative pathways significant for understanding vision
They explain how some visual functions — like blindsight and certain emotional responses to visual stimuli — can occur even without V1 processing.
What experimental task did Weiskrantz and colleagues use to study patients with hemianopia?
They had patients point to or look at targets that had been briefly flashed in their blind visual field.
How did the patients with hemianopia perform in Weiskrantz’s experiment?
ven though they reported not consciously seeing anything, their responses were above chance, indicating some level of visual processing.
What does the above-chance performance of patients with hemianopia suggest about visual processing?
It suggests that visual information in the blind field can still be processed unconsciously, even without conscious awareness.
In Weiskrantz’s hemianopia experiment, patients could point to or look at targets flashed in their blind visual field despite reporting that they could not see them. How does this finding relate to the concept of blindsight?
It is a key demonstration of blindsight — visual processing without conscious perception, likely via alternative pathways that bypass V1.