Robot Vision Test 2
1/25
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
26 Terms
Image Classification
just detects one label, no spatial extent

Semantic Segmentation
labels each pixel, outputs dense label map same spatial size as input

How is semantic segmentation different from instance segmentation
Semantic segmentation only calls out difference in classes
Instance segmentation calls out difference between classes and also differences between the same classes
Object detection
predict bounding boxes and class labels for object; outputs set of (x,y,w,h)

Instance Segmentation
Combo of semantic and object
Most advanced
Analyzes every pixel → creates exact border around object → gives each object their own class
outputs per object binary mask

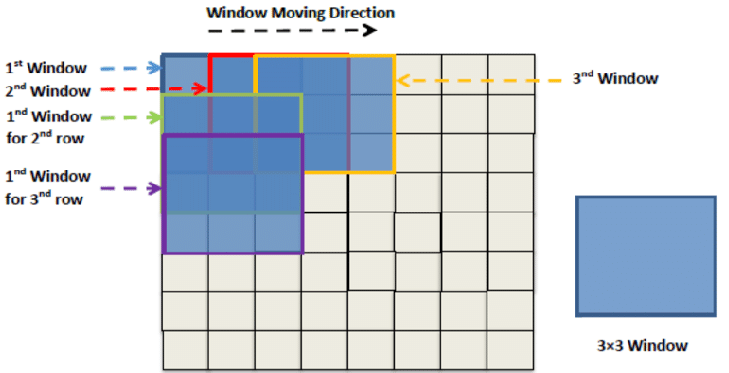
Sliding Window Semantic Segregation
Slide a window around and it identifies what is what inside of the given window
Keep moving the window around until every pixel has been covered once
Form an aggregated map to output what is in image
Major limitation: heavy redundant computation, poor global context & boundary artifacts
List two major inefficiencies/bottlenecks of R-CNN and explain how Fast R-CNN addresses each one (be specific abt shared feature computation and RoI processing). Mention any remaining bottleneck that Fast R-CNN does not remove.
R-CNN bottlenecks: (i) runs a full CNN fwd pass per region proposal → repeated computation; (ii) multi-stage pipeline → slow training and storage overhead
Fast R-CNN fixes: (i) compute one convolutional feature map for the whole image and use RoI pooling to extract per-proposal features → shared computation; (ii) train a single end-to end network w softmax classification and bbox regression → faster and simpler training/inference
Write a squared-error loss suitable for training an autoencoder
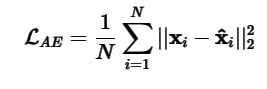
State the core idea of an autoencoder and briefly explain one application (ex: denoising, dimensionality reduction, representation learning, anomaly detection, super-resolution)
Core Idea: to learn an encoder fθ: x → z and a decoder gΦ: z → x̂ that reconstruct x; the input z is a compact representation of the input
Denoising example: train on (xnoisy, x) pairs; at test time, gΦ(fθ(xnoisy)) removes noise
Given a set of token vectors, list the steps to compute self attention: obtaining Q, K, V; computing scores; (optional) scaling/masking; softmax; and weighted sums
Compute Q = XWQ, K = XWK, V = XWV from input X
Scores S = QKT; optionally scale by 1/√dk
Weights A = softmax(S) (row-wise)
Output Z = AV; for multi-head, concatenate head outputs then apply WO
What scale factor is applied to the dot products and why is it needed?
The scale factor: 1/√dk
Reason: prevents softmax saturation therefore stabilizing gradients
Give two ways to feed images into a transformer (Ex: ViT patches of CNN features as tokens)
ViT: split images into patches, flatten/linearly project to tokens (add [CLS] and positional encodings)
What is the purpose of mutli-head attention?
To allow the model to attend to different pos/relations and subspaces in parallel, therefore improving overall modeling capacity
Write the summary equation for scaled dot-product attention Attention(Q, K, V)
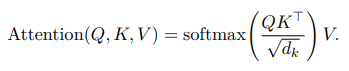
Explain how positional encoding provides order information
Input tokens → parallel processing → lost order → generate unique positional encoding (PE) → add PE to embedding → provides order → transformer understands order
Why is the dot product commonly used as a similarity score in attention?
it is efficient, differentiable, and aligns w cosine similarity after normalization; larger values reflect higher alignment
define a pretext task and a downstream task. Why can solving the former help the latter?
Pretext: self-supervised task on unlabeled data to learn generalizable features
Downstream: target task using learned features
Solving pretext tasks shapes representations useful for downstream tasks. It’s kinda like building the foundation before building the house.
Briefly describe three common pretext tasks: rotation prediction, relative patch location/jigsaw, inpainting/colorization
Rotation prediction: classify rotation angle
Relative patch location/jigsaw: predict spatial relations/permutations among patches
Inpainting/colorization: reconstruct missing regions or color channels from context
Explain the basic idea of contrastive representation learning and what the InfoNCE loss optimizes with 1 positive and N-1 negatives. Why do more negatives generally tighten the improve the performance (mutual-information lower bound)?
Idea: learn an encoder so embeddings of a positive pair (same instance, different views) are close while negatives are apart
with one positive j for anchor i and negatives Ni
More negatives make the denominator harder, encouraging discrimination
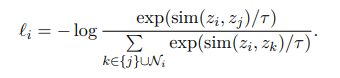
In SimCLR: define a positive pair, list two strong image augmentations used to create views, explain the role of the projection head, and in one sentence each state the role of the temperature parameter and why larger batch sizes help
Positive pair: two augmented views of the same image
Two strong augmentations: random resized crop; color jitter
Projection head: MLP mapping representation h to z for the contrastive loss; improves invariance without hurting h (used for downstream)
Temperature: scals logits; lower τ sharpens softmax, emphasizing hard negatives, higher τ smooths it
Large batches help: provide many in-batch negatives per step, strengthening the contrastive signal
Give two key differences between SimCLR and MoCo, focusing on how negatives are obtained and the encoder(s) and update rules. State one practical implication of these differences
Negatives: SimCLR uses in-batch negatives; MoCo uses a queue/memory bank of keys, decoupling negatives from batch size
Encoders/updates: SimCLR has a single encoder (two views share weights); MoCo uses a query encoder and key encoder updated by momentum (EMA) for consistency
Implication: MoCo attains many negatives with small batches (memory efficient); SimCLR typically benefits from very large batches (more GPU memory)
Compare a standard autoencoder and VAE in terms of latent regularization and generative capability. What is the reparameterization trick and why does it enable backpropagation
AE: deterministic z; no explicit latent prior; good reconstructions but weak generative sampling from random z
VAE: encoder outputs (µ, σ) of qϕ(z|x); loss combines reconstruction and KL divergence to a prior (often N (0, I)); yields smooth, continuous latent spaces with generative capability
Reparameterization: sample ϵ ∼ N (0, I) and set z = µ + σ ⊙ ϵ to make sampling differentiable for backdrop
Describe how a GAN is trained (generator vs discriminator updates; objective type). List two common drawbacks of GANs
Training: discriminator D learns to classify real vs generated; generator G learns to fool D via a non-saturating objective, alternating updates
Two drawbacks: mode collapse (generator covers few modes); training instability/sensitivity to hyperparameters (and no explicitly likelihood)
Explain the idea of fully convolutional networks for segmentation.
The idea: Replace fully connected layers w convolutional layers
Why: so that we keep spatial feature maps
A traditional CNN with FC layers takes a 2D feature map and flattens it into a 1D vector. This destroys spatial information
What is the role of downsampling and upsampling?
Role of downsampling: increases receptive field and decreases memory/compute
Role of upsampling: restores resolution
Why is operation at full resolution so expensive?
Because large feature maps and many channels over pixels