High Availability
1/28
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
29 Terms
High Availability (HA)
FortiGate HA uses the FortiGate Clustering Protocol (FGCP) to discover members, elect the primary FortiGate, synchronise data among members, and monitor the health of members
FortiGate HA links and synchronises two or more FortiGate devices to form a cluster for redundancy and performance purposes
A cluster includes one device that acts as the primary/active FortiGate, which sends its complete configuration to other members that join the cluster, overwriting most of their configuration
It also synchronises session information FIB entries, FortiGuard definitions, and other operation-related information to be secondary devices, which are also known as standby devices
The cluster shares one or more heartbeat interfaces among all devices/members, for synchronising data and monitoring the health of each member
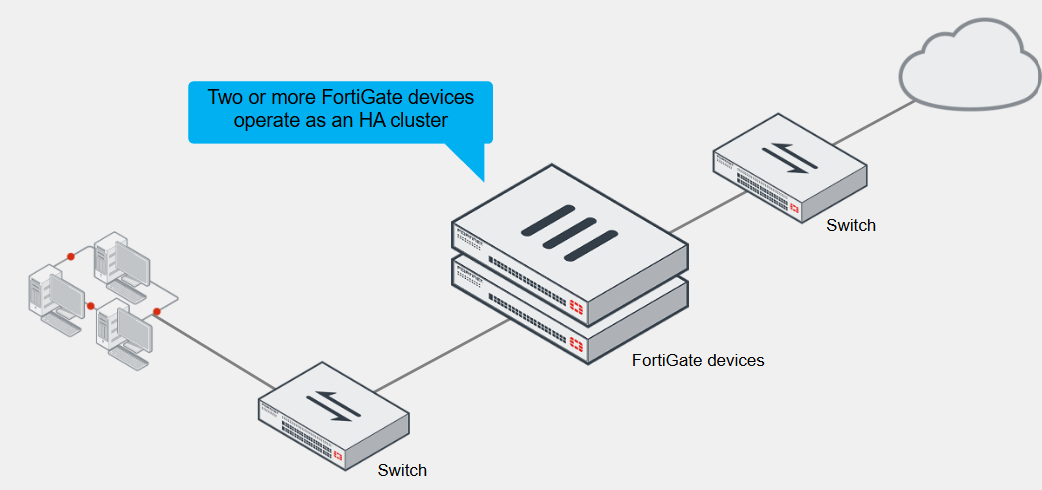
Active-Passive HA
In this mode, the primary FortiGate is the only FortiGate that actively processes traffic
Secondary FortiGate devices remain in passive mode, monitoring the status of the primary device
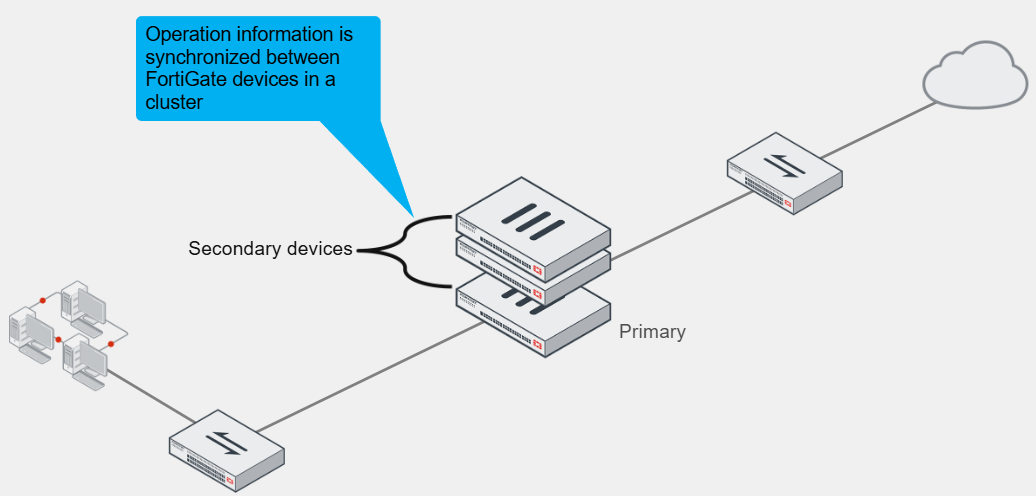
In either of the two HA operation modes, the operation information of the primary FortiGate is synchronised with secondary devices
If a problem is detected on the primary, one of the secondary devices takes over the primary, and this event is called an HA failover
If a secondary FortiGate device fails, the primary updates its list of available secondary FortiGate devices
It also starts monitoring for the failed secondary, waiting for it to come online again
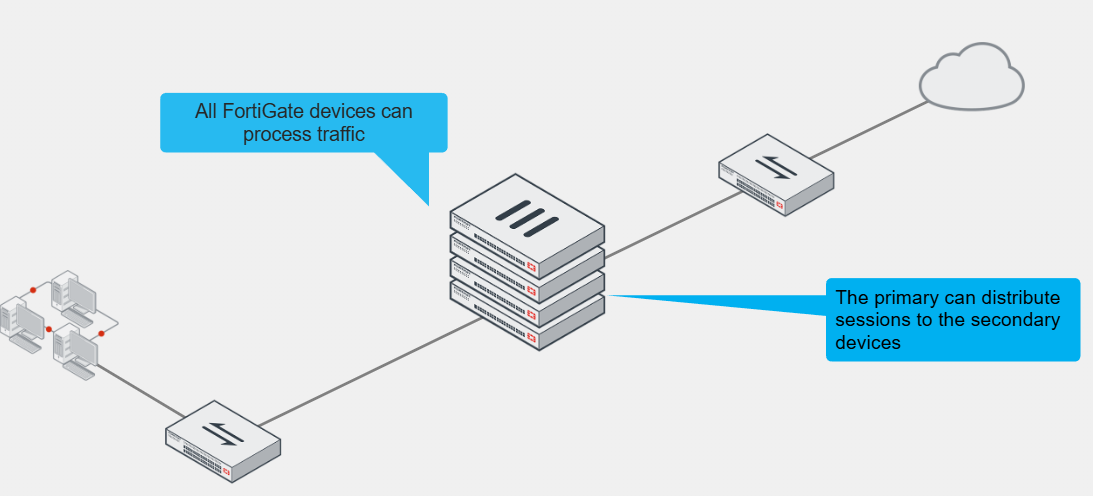
Active-Active HA
Like the other, the operation-related data is synchronised between devices in the cluster
If a problem is detected on the primary device, one of the secondary devices takes over
However, all cluster members can process traffic
Based on the HA settings and traffic type, the primary FortiGate can distribute support sessions to the secondary device
If one of the secondary devices fails, the primary also reassigns sessions to a different secondary FortiGate
HA Requirements
All members must have the same model, firmware version, licensing, hard drive configuration, operating mode (management VDOM)
If the licensing level among members isn’t the same, the cluster resolves to use the lowest licensing level among all members
For example, if you purchase FortiGuard Web Filtering for only one of the members in a cluster, none of the members will support FortiGuard Web filtering when they form the cluster
From a configuration and setup point of view, you must ensure that the HA settings on each member have the same group ID and name, password and heartbeat interface settings
Try to place all heartbeat interfaces in the same broadcast domain, or for two-member clusters, connect them directly
It’s also best practice to configure at least two heartbeat interfaces for redundancy purposes
This way, if one heartbeat links fails, the cluster uses the next one, as indicated by the priority and position in the heartbeat interface list
If you are using DHCP or Point-to-Point Protocol over Ethernet (PPPoE) interfaces, use static configuration during the cluster initial setup to prevent incorrect address assignment
After the cluster is formed, you can revert to the original interface settings
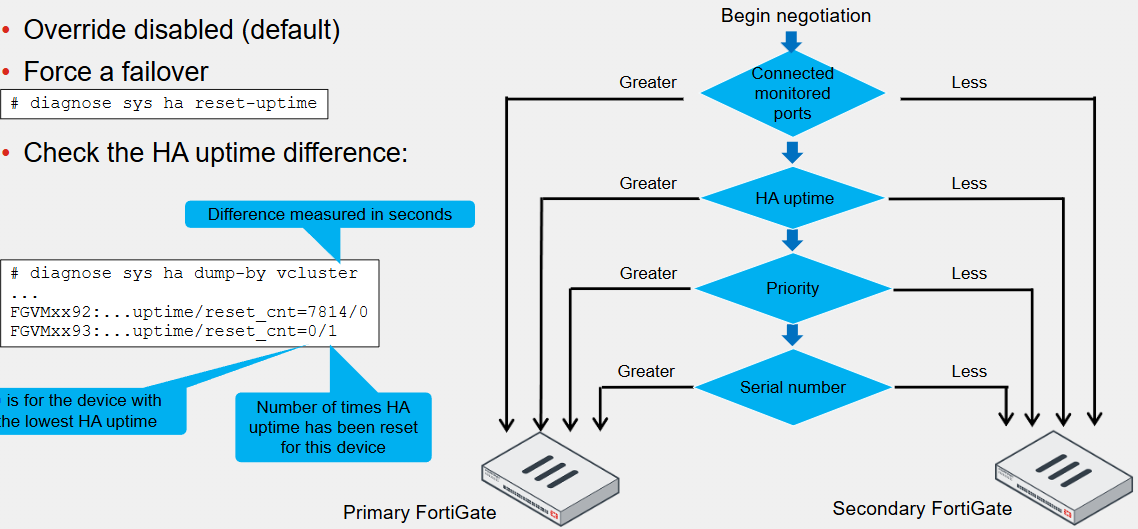
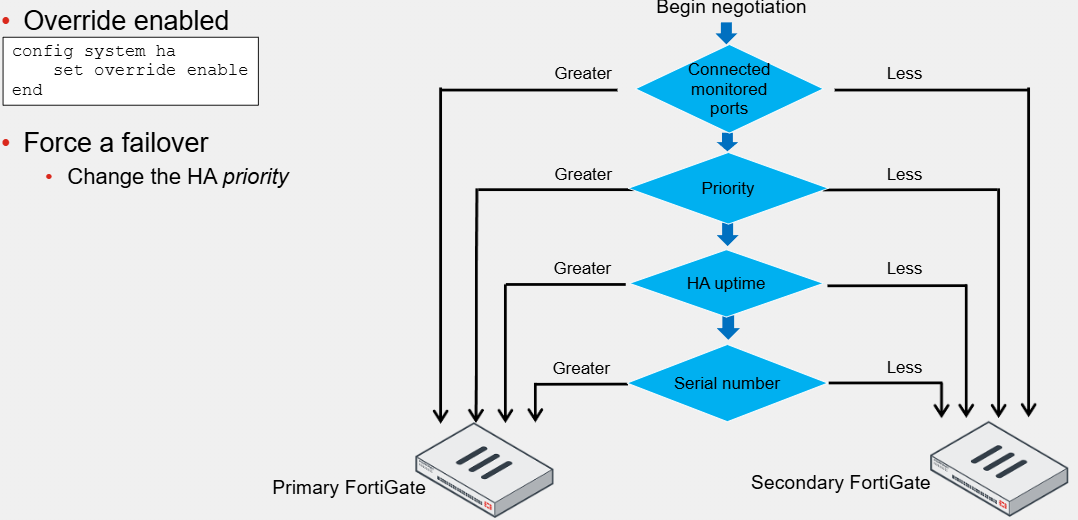
Primary FortiGate Election - Override Disabled
The cluster considers different criteria during the primary FortiGate election process
The criteria order evaluation depends on the HA override setting, and the default is disabled
The election process stops at the first matching criteria that successfully selects a primary FortiGate in a cluster
1. The cluster compares the number of monitored interfaces that have a status of up. The members with the most available monitored interfaces become the primary
2. The cluster compares the HA uptime of each member. The member with the highest HA uptime, by at least five minutes, becomes the primary
3. The member with the highest priority becomes the primary
4. The member with the highest serial number becomes the primary
When HA override is disabled, the HA uptime has precedence over the priority settings
This means that if you must manually fail over to a secondary device, you can do so by reducing the HA uptime of the primary FortiGate
You can do this by running the diagnose sys ha reset-uptime command on the primary FortiGate, which resets its HA uptime to 0
This command resets the HA uptime and not the system uptime
If a monitoring interface fails, or a member reboots, the HA uptime for that member is reset to 0
Primary FortiGate Election - Override Enabled
If enabled, the priority is considered before the HA uptime
The advantage is that you can specify which device is the preferred primary every time by configuring it with the highest HA priority value
The disadvantage is that a failover event is triggered not only when the primary fails, but also when the primary is available again
When the primary becomes available again, it takes its primary role back from the secondary FortiGate that temporarily replaced it
When enabled, the easiest way of triggering a failover is to change the HA priorities
For example, you can either increase the priority of one of the secondary devices or decrease a primary
The override setting and device priority values are not synchronised to cluster members
You must manually enable override and adjust the priority of each member
Primary FortiGate Tasks
Monitors the cluster by broadcasting hello packets and listening for hello packets from other members in the cluster
The members use the hello packets to identify if other FortiGate devices are alive and available
Also synchronises its operation-related data to the secondary members
Some of the data synchronised includes its configuration, FIB entries, DHCP leases, ARP table, FortiGuard definitions and IPsec tunnel security associations (SAs)
Some parts of the configuration are not synchronised because they are device-specific, such as the hostname, HA priority and HA override settings
You can configure the primary FortiGate to synchronise qualifying sessions to all the secondary devices
When you enable session synchronisation, the new primary can resume communication for sessions after a fail-over event
The goal is for existing sessions to continue flowing through the new primary FortiGate with minimal or no interruptions
In active-active mode only, a primary FortiGate is also responsible for distributing sessions to secondary members
Secondary FortiGate Tasks
Also broadcast hello packets for discovery and monitoring purposes
In active-passive mode, the secondary devices act as a standby device, receiving synchronisation data but not actually processing any traffic
Once a cluster is in sync, configuration changes made on a secondary device are propagated to other members
So with a cluster that is in sync, you can make changes on any of its members, not just the primary, and all changes are synchronised
However, it is recommended that you make configuration changes on the primary device because this prevents the loss of configuration changes if there are synchronisation issues between cluster members
In active-active mode, the secondary devices don’t wait passively and process all traffic assigned to them by the primary device
Heartbeat Interface IP Address
FGCP automatically assigns the heartbeat IP addresses based on the serial number of each device
The IP address 169.254.0.1 is assigned to the device with the highest serial number, 0.2 with the second and so on
The IP address assignment does not change when a failover happens
Regardless of the device's role at any time, its heartbeat IP address remains the same
A change in this address may happen when a FortiGate device joins or leaves the cluster
In those cases, the cluster renegotiates the heartbeat IP address assignment
The HA cluster uses the heartbeat IP addresses to distinguish the cluster members and synchronise data
These IPs are non-routable and are used for FGCP operations only
Heartbeat and Monitored Interfaces
Heartbeat interfaces exchange sensitive information about the cluster operation and may require a fair amount of bandwidth for data synchronisation
For this reason, if you use a switch to connect the heartbeat interfaces, it’s recommended that you use a dedicated switch, or at least, that you place the heartbeat traffic on a dedicated VLAN
You must configure at least one port as a heartbeat interface but preferably two
For heartbeat interfaces, you can use physical interfaces only, so you can’t use VLAN, IPsec VPN, redundant or 892.3ad aggregate interfaces, or FortiGate switch ports
For link failover to work, you must configure one or more interfaces
A monitored interface should be an interface whose failure has a critical impact on the network
For example, your LAN or WAN interfaces are usually good choices to be managed
Heartbeat interfaces however should not be configured as monitored interfaces because they are not meant to handle user traffic
As a best practice, wait until a cluster is up and running and all interfaces are connected before configuring link failover
This is because a monitored interface can be disconnected during the initial setup and as a result tirgger a failover before the cluster is fully configured and tested
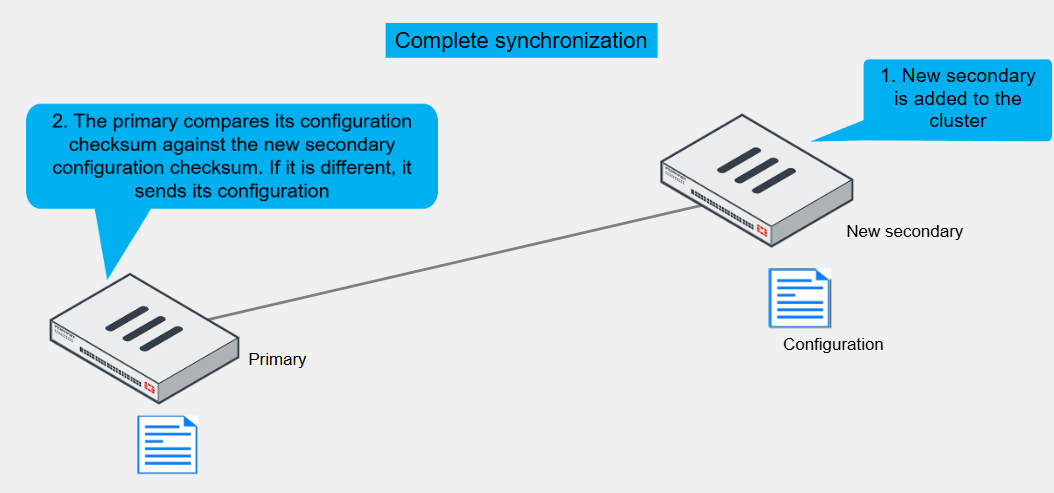
HA Complete Configuration Synchronisation
To prepare for a failover, an HA cluster keeps its configurations in sync
FortiGate HA uses a combination of incremental and complete synchronisations
When you add a new device to the cluster, the primary FortiGate compares its configuration checksum with the new secondary FortiGate configuration checksum
If the checksums don’t match, the primary FortiGate uploads its complete configuration to the secondary one
Periodically:
Some runtime data, such as DHCP leases and FIB entries are also synchronised
By default, the cluster checks every 60 seconds to ensure that all devices are synchronised
If a secondary device is not, it checksum is checked every 15 seconds
If the checksum of the out-of-sync secondary device doesn’t match for five consecutive checks, a complete resynchronisation is done for that device
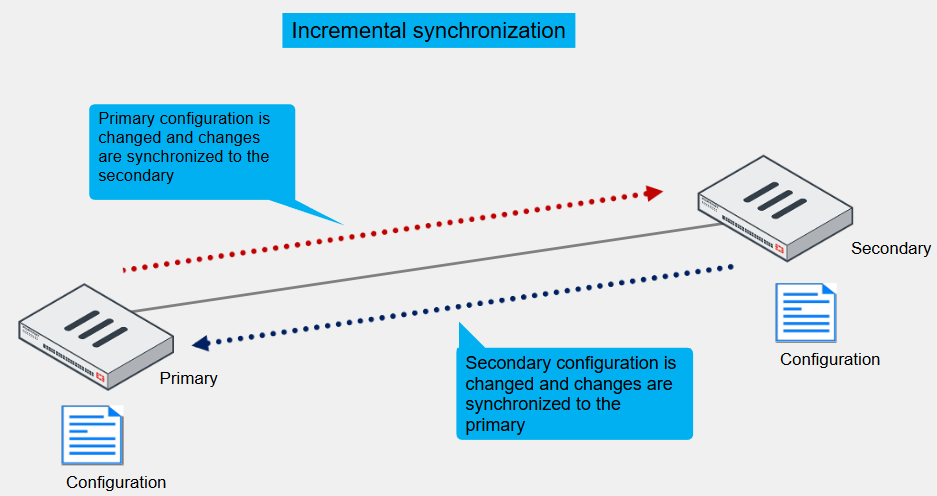
Incremental Configuration Synchronisation
After the initial synchronisation is complete, when a change is made to the configuration of an HA cluster device, incremental synchronisation sends the same configuration change to all other cluster devices over the HA heartbeat link
An HA synchronisation process running on each cluster device receives the configuration change and applies it to the cluster device
For example if you create a firewall address object, the primary doesn’t resend its complete configuration, only the new object
Not Synchronised
System interface settings of the HA reserved management interface and the HA default route for the reserved management interface
In-bad HA management interface
HA override
HA device priority
Virtual cluster priority
FortiGate host name
HA priority setting for a ping server (or dead gateway detection) configuration
All licenses except FortiToken licenses (serial numbers)
Cache
GUI dashboard widgets
Session Synchronisation
Provides seamless session failover
When the primary fails, the new primary can resume traffic for synchronised sessions without network applications having to restart the connections
By default, the feature synchronises TCP firewall sessions that are not subject to proxy-based inspection
An exception to this rule is TCP SIP sessions inspected by SIP ALG
Even though SIP ALG performs proxy-based inspection on SIP sessions, FortiGate can still synchronise such SIP sessions
Firewall sessions, or pass-through-sessions, are user traffic sessions that travel across FortiGate
TCP firewall sessions that are subject to flow-based inspection or no inspection at all, are synchronised to secondary members
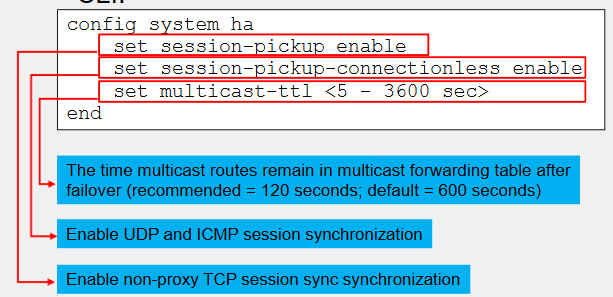
You can also enable synchronisation of UDP and ICMP sessions
Although both are connectionless protocols, FortiGate still allocates sessions for UDP and ICMP connections in its session table
Usually, the synchronisation of these sessions is not required because most UDP and ICMP connections can resume communication if the session information is lost
For multicast traffic, FortiGate synchronises multicast routes only
That is, FortiGate doesn’t synchronise multicast sessions, as most are UDP-based
To ensure the multicast routing information across members is accurate, you can adjust the multicast time to live (TTL) timer
The timer controls how long the new primary keeps the synced multicast routes in the multicast forwarding table
The smaller the timer value, the more often routes are refreshed and the more accurate the multicast forwarding table is
120 seconds is recommended
Local-in and local-out sessions, which are sessions that are terminated at or initiated by FortiGate respectively are not synchronised
For example, BGP peerings, OSPRF adjacencies, SSH and HTTPS management connections must be restarted after a fail-over
IPsec and SSL VPN Synchronisation
The primary FortiGate automatically synchronises all IKE and IPsec SAs to secondary members
This enables the new primary to resume existing IPsec tunnels after a failover
Note that you must also enable sessions synchronisation if you want the new primary to also resume after exiting IPsec sessions
Otherwise, after a failover, you must still restart existing TCP connections made over IPsec tunnels, even though the IPsec tunnels continue to be up on the new primary
For SSL VPN, users have to restart the SSL VPN tunnel after a failover by reconnecting to it
Failover Protection
Most common types of failovers are device failovers and link failovers
Device failovers occur when the secondary devices stop receiving hello packets from the primary
A link failover occurs when the link status of a monitored interface on the primary FortiGate goes down
You can configure an HA cluster to monitor one or more interfaces
If a monitored interface on the primary FortiGate is unplugged or its link status goes down, a new primary FortiGate is elected
When you configure remote link failover, FortiGate uses the link health monitor feature to monitor the health of one or more interfaces against one or more servers that act as beacons
The primary FortiGate fails if the accumulated penalty of all failed interfaces reaches the configured threshold
If you enable memory-based failover, an HA failover is triggered when the memory utilisation on the primary device reaches the configured threshold for the configured monitoring period
You can also enable SSD failover, which triggers a failover if FortiOS detects Ext-fs errors on an SSD on the primary FortiGate
There are multiple events that may trigger an HA failover, such as hardware or software failures on the primary device, an issue on on of the interfaces on the primary, or an administrator-triggered failover
When a failover occurs, an event log is generated
Optionally, you can configure the device to also generate SNMP traps and alert emails
Make sure that you enable session pickup for sessions you want to protect from a failover event
This way, the new primary can resume traffic for these sessions
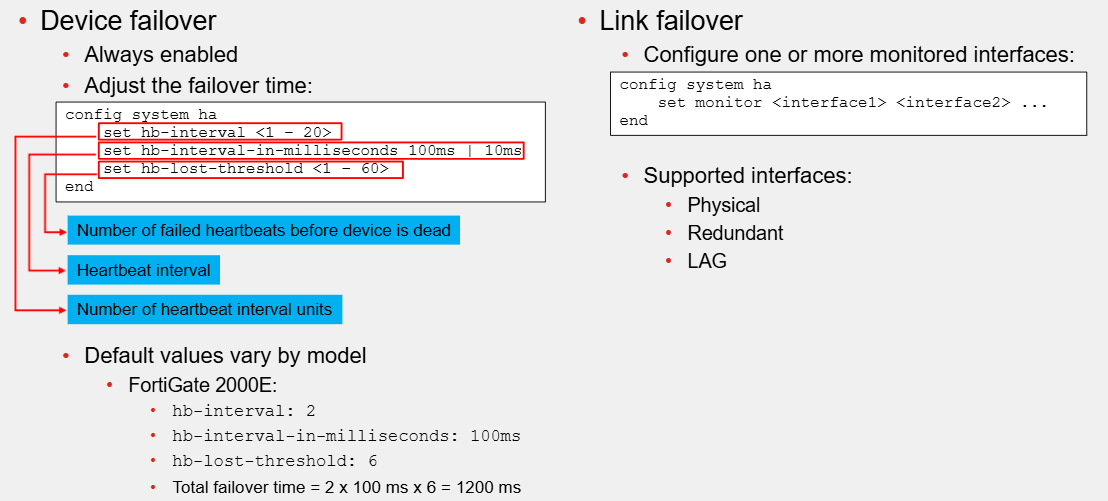
Failover Configuration
When you configure HA, device failover is always enabled
However, you can adjust the failover time settings
To speed up, reduce the value of the number of failed heartbeats before the device is dead, heartbeat interval and number of heartbeat interval units
For default values for the three settings vary by mode
To configure link failover, you must configure one or more monitored interfaces
Note that you can configure only physical, redundant and LAG interfaces as monitored interfaces
Remote Link Failover
First configure the link health monitor
The ha-priority setting in the link health monitor configuration defines the penalty applied to the member after the link is detected as dead
Note that this setting has local significance only, and is not synchronised with other members
Next, configure the HA settings related to the remote link behaviour
If during the primary election, the accumulated penalty of all members is the same, then other criteria, such as monitored interfaces, priority, uptime and so on are used as tiebreakers

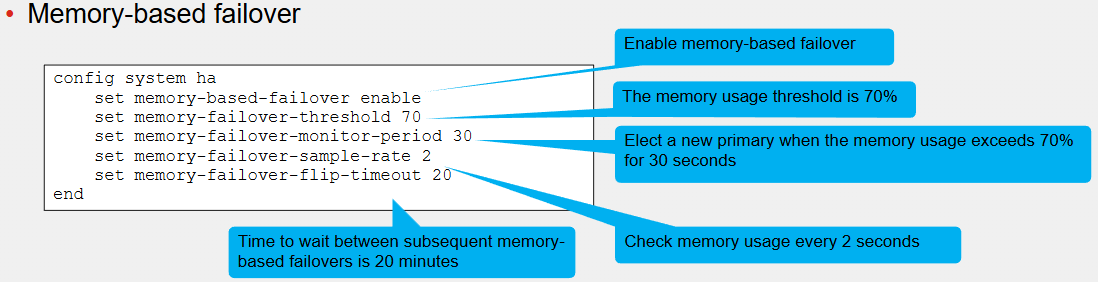
Memory-Based Failover
When the memory on the primary receives 70% threshold for 30 seconds, a new primary is elected
During primary election, a failover occurs when the memory usage of a secondary member is lower than the configured memory threshold and if so, the secondary member becomes the new primary
After a memory-based failover, the same FortiGate member waits 20 minutes before another failover like this can occur
If the cluster members can still initiate a memory-based failover if they meet their criteria
Each member in the cluster checks its memory usage every 2 seconds
If during the primary election, the memory usage of all members is below or above the threshold, then other criteria, such as monitored interfaces, priority, uptime and so on are used as tiebreakers
Virtual MAC Address and Failover
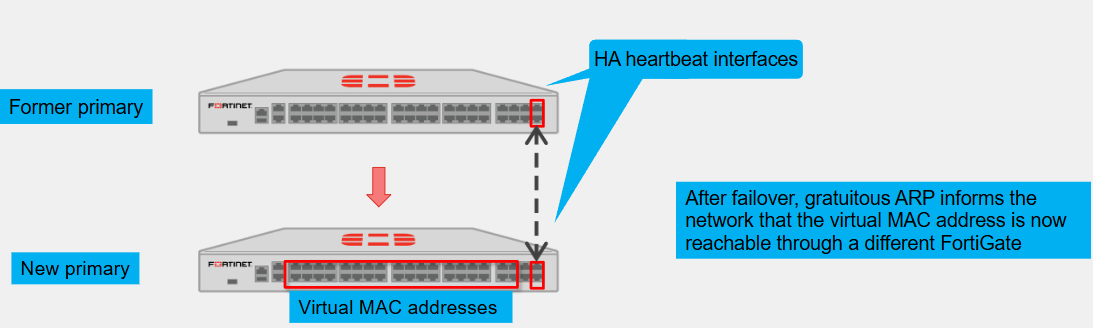
To forward traffic correctly, a FortiGate HA solution uses virtual MAC addresses
When a primary joins an HA cluster, each interface is assigned a virtual MAC address
The HA group ID, virtual cluster ID, and interface index number are used in the creation of virtual MAC address assigned to each interface
So, if you have two or more HA clusters in the same broadcast domain, and using the same HA group ID, you might get MAC address conflicts
For those cases, it is strongly recommended that you sign different HA group IDs to each cluster
Through the heartbeats, the primary informs all secondary devices about the assigned virtual MAC address
Upon failover, a secondary adopts the same virtual MAC addresses for the equivalent interfaces
The new primary broadcasts gratuitous ARP packets, notifying the network that each virtual MAC address is now reachable through a different switch port
Note that the MAC address of a reserved HA management interface is not changed to a virtual MAC address
Instead, the reserved management interface keeps its original MAC address
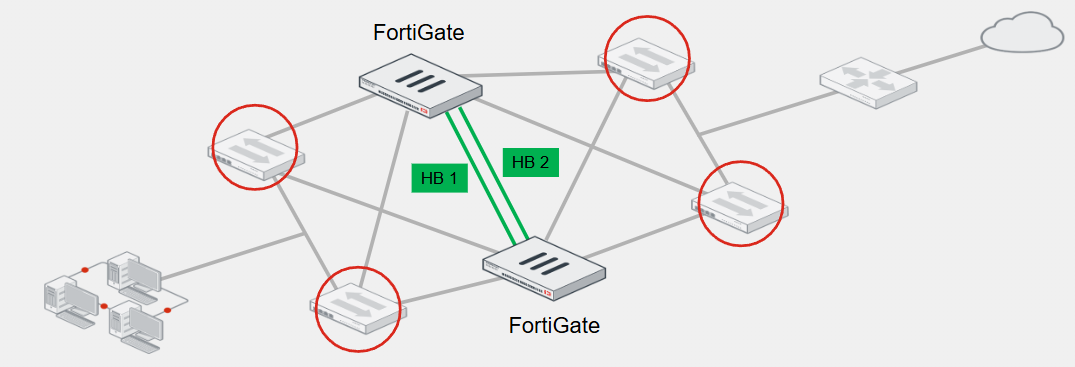
Full Mesh HA
The goal of this topology is to eliminate a single point of failure, not only by having multiple FortiGate devices forming a cluster but also by having redundant links to the adjacent switches
The goal is to have two switches for both upstream and downstream links, and then connect the redundant links to different switches
To achieve redundancy with adjacent switches, you must deploy redundant or LAG interfaces
If you use redundant interfaces, only one interface remains active
This prevents a Layer 2 loop and a standard switch should suffice
However, if you want to use LAG interfaces, then you must ensure that the switch supports multichassis link aggregation group (MCLAG) or a similar virtual LAG technology that enables you to form a LAG whose interface members connect to different switches
FortiSwitch, which is a Fortinet Ethernet switch, supports MCLAG
You can use FortiSwitch as the adjacent switch to deploy a full mesh HA topology with FortiGate
HA Status on GUI
The HA page on the GUI shows important information about the health of your HA cluster
For each cluster member, the page shows whether the members are synchronised or not, status, host name, serial number, role, priority, uptime, active sessions and more
Here, you can remove a device from a cluster
When you remove a device from HA, the device operation mode is set to standalone
You can also enable more columns that display other important information about each member, such as checksum, CPU, and memory
HA Status on CLI
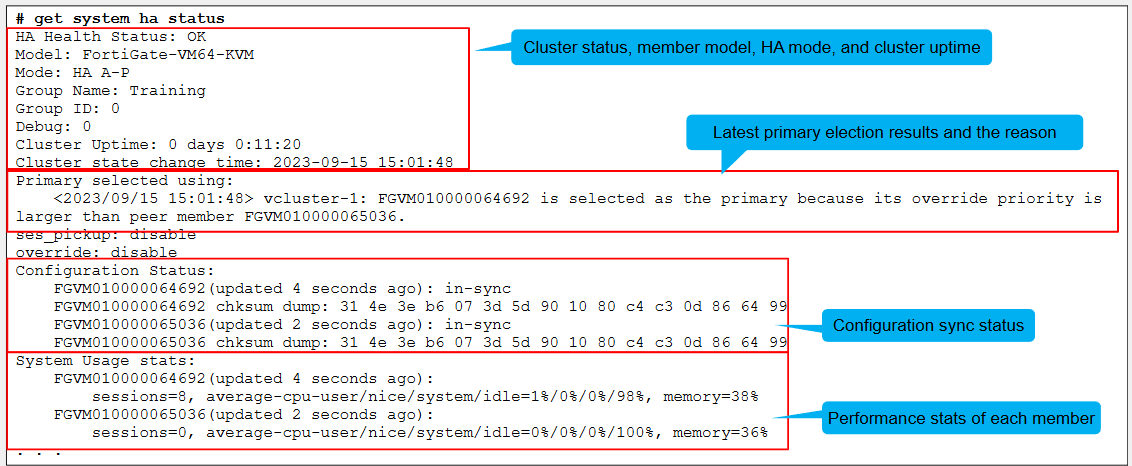
Use get system HA status on CLI
The command displays comprehensive HA status information in a user-friendly output and is usually executed as the first step when troubleshooting HA
The beginning of the output shows the cluster status, the member mode, the HA model in use, and the cluster uptime
Next, you can see the latest primary election events, the results, and the reason
The configuration status information is displayed next indicating the configuration sync status for each member and for both members, the configuration is in sync
Following you can see the system usage statistics, which reports on performance statistics for each member
They indicate the number of sessions that each member handles, as well as the average CPU and memory usage
The sessions field accounts for any sessions that are member handles, and not only the sessions that are distributed when the HA mode is active-active
There is then the status information for the configured heartbeat, monitored, and remote link interfaces, which enable the cluster to perform device failover, link failover and remote link failover protection respectively
Next for each member, it shows the role, hostname, serial number and ID information
Checking the Configuration Synchronisation
The diagnose sys ha checksum command tree enables you to check the cluster configuration sync status
In most cases, you want to use this to view the cluster checksum
The output includes the checksum of each member in the cluster
When you run the command, the checksum is polled from each member using the heartbeat interface
If HA is not working properly or if there are heartbeat communication issues, then the command may not show the checksum for members other than the one you run the command on
An alternative is to connect to each member individually and run the command instead, displaying only the Checksum of the member you are connected to
After obtaining the checksums, identify the configuration sync status by comparing them
If all members show the exact has values for each configuration scope, then everything in sync
To calculate checksums, FortiGate computes a hash value for each of the following configuration scopes:
global: global configuration, such as global scope, FortiGuard settings and so on
root: settings and objects specific to the root VDOM–if you configure multiple VDOMs, FortiGate computes the hash values for each VDOM
all: global and VDOM configurations
In some cases, the configuration of members is in sync even though the checksums are different
For these cases, run the diagnose sys ha checksum recalculate
Switching to the CLI of another Member
When troubleshooting HA, you may need to connect to the CLI of another member from the CLI of the member you are on
You do this by using the execute ha manage command
This command requires you to indicate the ID of the member you want to connect to and the username to log in
To get the list of member IDs, you can add a question mark at the end of the execute ha manage
Connect to a Member Directly
When you connect to a cluster using any of its virtual IP addresses, you always connect to the primary
You can then switch to the CLI of any member in the cluster by using the execute ha manage command
FortiGate provides two ways for the administrator to connect to a member directly
The reserved HA management interface is the out-of-band option
You configure up to four dedicated management interfaces, and assign them a unique address on each member
You can then use these to connect to them directly
You can also instruct FortiGate to use the dedicated management interface for some outbound management services such as SNMP traps, logs and authentication requests
Alternatively, you can configure in-band HA management, which enables you to assign a unique management address to a member without having to set aside an interface for that purpose
You assign the management address to any user-traffic that the member uses, and then connect to the member using that unique management address
If you have unused interfaces, then it’s generally more convenient to use a reserved HA management interface because the user and management traffic don’t have to compete
Many FortiGate models come with a management interface that you can use for this purpose
Also, the routing information for a reserved HA management interface is placed in a separate table, which means that you don’t see the interface routes in the FortiGate routing table
This allows for segmentation between data and management traffic
Firmware Upgrade
You upgrade an HA cluster in the same way you do for standalone devices
You can apply the new firmware using the GUI
In HA, this usually means connecting to the primary FortiGate GUI to apply the new firmware or the CLI
The devices must reboot to apply the new firmware
However, uninterruptible upgrade is enabled by default, so that secondary members in a cluster are upgraded first
After the administrator applies the new firmware on the primary, uninterruptible upgrade works as follows:
1. The primary sends the firmware to all secondary members using the heartbeat interface
2. The secondary devices upgrade their firmware first. If the cluster is in active-active mode, the primary temporarily takes overall traffic
3. The first secondary that finishes upgrading takes over the cluster
4. The former primary becomes a secondary device and upgrades its firmware next
Depending on the HA settings and uptime, the original primary may remain as a secondary after the upgrade
Later, if required, you can issue a manual failover
Alternatively, you can enable the override setting on the primary FortiGate to ensure it takes over the cluster again after it upgrades its firmware as long as the device is assigned the higher priority
If you want to cluster to upgrade at the same time, you can enable simultaneous upgrades, having a service impact
The local-only option for only the local device
The secondary-only option allows you to upgrade the secondary members, but not the primary
These options are only meant to temporarily put the cluster on different firmware versions – to provide more control over which member to upgrade, and when
Configurations will synchronise while the cluster has different firmware versions
Which session type can you synchronise in an HA cluster?
Non-proxy TCP sessions