Transformers
1/151
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
152 Terms
Foundation
What is a transformer?
A transformer is a neural network architecture that uses self-attention to process all tokens in a sequence in parallel, so it can learn which parts of the input should attend to which others.
What does attending mean?
What does token A attends to token B mean?
Attending” just means paying attention to something more than other things.
it means the model is focusing more on token B when deciding what token A should mean.
What is the self-attention? simpler terms?
Self-attention is where each token in a sequence ‘looks at’ all the other tokens and learns how much to weight each one when computing its own representation.
That way, the model can focus on the most relevant context for every token.
Simpler: tokens look at themselves (same sequence).
What problem does self-attention solve?
It helps the model decide which other tokens are most important when updating the representation of a given token.
What is masked self-attention?
Masked self-attention is where we block a token from attending to some other tokens—usually future tokens—by using a mask. In the decoder of a transformer, we mask future positions so the model can only use past and current tokens when predicting the next one
What is cross-attention? simpler terms?
Cross-attention is where queries come from one sequence and keys/values come from another, so the model can use information from the input sequence when generating each output token.
tokens in one place (e.g., the decoder) look at tokens from somewhere else (e.g., the encoder output) to get information.
What problem do Transformers solve?
Transformers model long-range dependencies in sequences (text, audio, DNA, etc.) efficiently and in parallel, avoiding the sequential bottlenecks of RNNs/LSTMs.
What are the two major Transformer roles?
Encoders produce contextual embeddings of inputs;
Decoders generate outputs token-by-token while attending to both prior outputs and the encoder.
Architecture (encoder/decoder/blocks)
What is a Transformer block?
A transformer block is made of two main parts:
a multi-head self-attention layer and a position-wise feed-forward network, each wrapped with residual connections and layer normalization (plus dropout for regularization)
Multi-head (self-)attention → Add & LayerNorm → Feed-forward MLP → Add & LayerNorm
(with dropout inside the attention and MLP).
How do encoder and decoder differ?
Encoder blocks use full self-attention;
Decoder blocks use masked self-attention (to prevent peeking ahead) plus cross-attention over encoder outputs.
What are residual connections for?
Residuals help gradient flow and stabilize deep networks by adding the block input to the block output.
Why is layer normalization used?
LayerNorm stabilizes activations and gradients within each token’s feature vector, improving training stability.
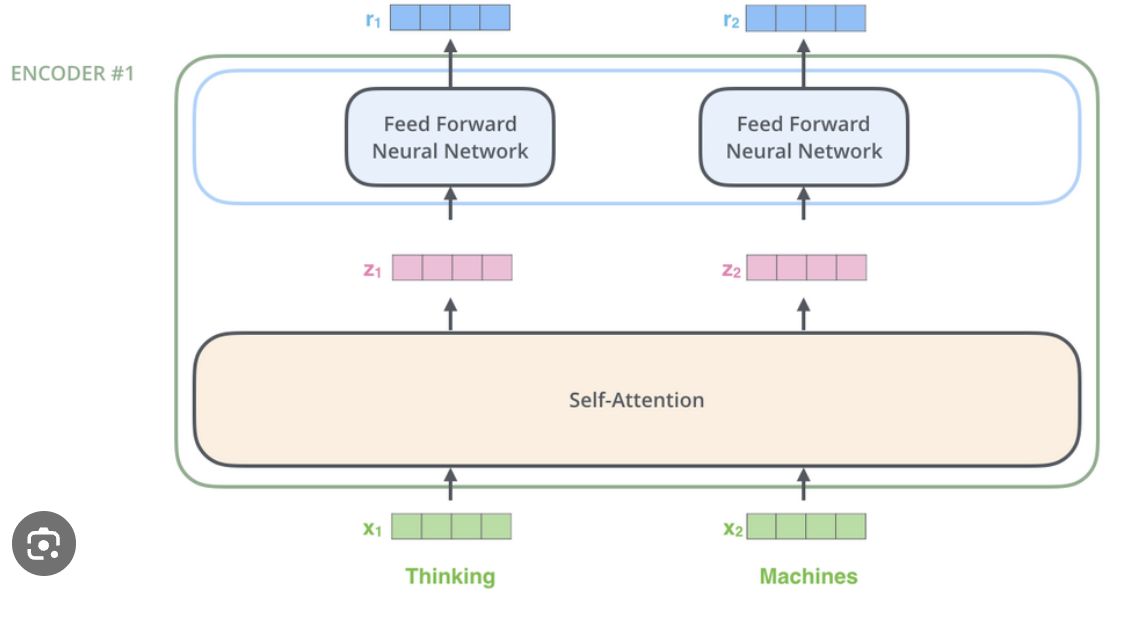
What does the feed-forward network (FFN) do?
The FFN applies two linear layers with a nonlinearity (e.g., GELU/ReLU) to each token independently, increasing model capacity.
Attention mechanics (Q/K/V)
What are Query, Key, and Value?
The model projects token embeddings into
Queries (what I’m looking for),
Keys (what I offer),
Values (the information to aggregate)
How is scaled dot-product attention computed?

Why “multi-head” attention?
Multiple heads learn different relationships in parallel (e.g., syntax vs semantics), then their outputs are concatenated and mixed.
What is masked attention and why is it needed?
A causal mask ensures token t only attends to ≤ t, preventing information leakage during generation.
What is cross-attention?
Cross-attention uses the decoder’s Queries with the encoder’s Keys/Values so generated tokens can attend to the encoded input.
Positional information
Why do we need positional encodings?
Because attention is permutation-invariant; positional encodings inject order information so the model knows token positions.
What are common positional schemes?
Sinusoidal (fixed), learned absolute, and relative/rotary (RoPE) encodings; relative/rotary often generalize better to longer contexts.
Tokenization & embeddings
How does tokenization work here?
Subword tokenizers (e.g., BPE/WordPiece) split text into units that balance vocabulary size with coverage, then map tokens to embeddings.
What is weight tying?
The input embedding matrix is reused as the output projection, reducing parameters and sometimes improving performance.
Training & Objectives
How are encoder-only models trained?
They are often trained with masked-language modeling (MLM), predicting randomly masked tokens from context.
How are decoder-only models trained?
They use causal language modeling (CLM), predicting the next token given previous tokens.
What is teacher forcing?
During training, the ground-truth previous tokens are fed to the decoder instead of its own predictions to stabilize learning.
What loss is typically used?
Cross-entropy loss over the next-token distribution is standard.
Scaling & Efficiency
What is kv-cache during inference?
It stores Keys/Values of past tokens so each new token reuses them, speeding autoregressive decoding.
What is quantization?
Quantization stores weights/activations in lower precision (e.g., INT8/INT4) to reduce memory and increase speed with minimal accuracy loss
Practical Usage
When do you choose encoder-only vs decoder-only?
Use encoder-only for understanding tasks (classification, retrieval); decoder-only for generation (chat, writing code); encoder-decoder for seq2seq (translation, summarization).
How does fine-tuning differ from prompt-only use?
Fine-tuning updates parameters for a task; prompting keeps the model fixed and steers behavior via context.
What are adapters/LoRA at a high level?
They add small trainable modules or low-rank updates on top of frozen backbones to achieve task adaptation with far fewer trainable parameters.
Common pitfalls & Stabilization
Why do Transformers sometimes “stall” in training?
Poor learning rates, initialization, or normalization can cause instability; optimizers like AdamW and warmup schedules help.
What is gradient clipping and why use it?
Clipping caps gradient norms to prevent exploding gradients, improving training stability.
Why use dropout/attention dropout?
They regularize the model, reducing overfitting by randomly zeroing parts of activations/attention weights
Why divide by √d_k in attention scores?
It keeps dot-products in a stable range so softmax does not saturate, which stabilizes training.
General Specifics
How do sampling strategies affect outputs?
Greedy/beam search improve determinism but reduce diversity; top-k/top-p sampling increases diversity at the cost of possible errors.
Why does context length matter?
Longer context lets the model condition on more prior information, but increases compute and memory; extrapolation beyond training length can degrade quality.
Evaluation & safety (interview-ready)
How do you evaluate a Transformer on NLP tasks?
How do you evaluate a Transformer on NLP tasks?
Use task-appropriate metrics: accuracy/F1 for classification, BLEU/ROUGE for generation, perplexity for language modeling, and human eval for quality/safety.
What causes hallucinations and how to mitigate them?
Hallucinations arise when the model confidently generates unsupported content; mitigations include retrieval-augmented generation, better prompts, and post-hoc verification.
Implementation Knobs
Why use GELU over ReLU in FFNs?
GELU often improves performance in language models due to smoother gating around zero.
What is pre-norm vs post-norm?
Pre-norm applies LayerNorm before attention/FFN and is more stable for deep stacks; post-norm normalizes after sublayers.
Why increase model depth vs width?
Depth often improves hierarchical abstraction; width increases per-layer capacity. The best choice depends on data/compute budgets.
What is weight decay (AdamW) doing here?
It regularizes by penalizing large weights, improving generalization without entangling with Adam’s moment updates.
Modern variants
What is a Vision Transformer (ViT)?
ViT splits images into patches, embeds them as tokens, and applies the standard Transformer encoder for image classification.
What is an encoder-decoder LLM (e.g., T5) vs decoder-only LLM (e.g., GPT)?
T5 uses seq2seq with MLM-style objectives, good for conditioned generation; GPT uses causal decoding, strong for open-ended generation.
What is Rotary Positional Embedding (RoPE)?
RoPE encodes relative positions by rotating Q/K in complex space, enabling better length generalization and extrapolation.
What is multi-query attention (MQA)?
MQA shares Keys/Values across heads while keeping separate Queries, reducing memory and speeding up decoding with minimal quality loss.
Foundations (Deep Dive)
What core limitation of RNNs/LSTMs do Transformers fix?
They remove the sequential dependency during training, so long-range context is learned with parallel matrix ops instead of step-by-step recurrence.
Why does “self-attention” scale better conceptually than recurrence?
Because each token directly attends to all other tokens in one shot, avoiding vanishing dependencies across many time steps.
What is the central object a Transformer learns?
It learns a contextual embedding for each token such that meaning depends on both the token and its surrounding context via attention.
Why is attention described as “content-based addressing”?
Queries retrieve Values by matching to Keys, so tokens fetch information based on semantic similarity rather than fixed positions.
Why use the softmax in attention?
Softmax converts similarity scores into a probability distribution, emphasizing a few relevant tokens while keeping gradients stable.
Why divide by √dₖ in attention?
It keeps dot-products in a numerically stable range so the softmax does not saturate early in training.
What is the learning signal in language modeling?
Cross-entropy between the predicted token distribution and the ground-truth next (or masked) token provides gradients to all layers.
Why do Transformers need positional information at all?
Self-attention is permutation-invariant; positional encodings inject order so the model can distinguish “cat chased dog” from “dog chased cat.”
How does multi-head attention increase capacity without huge cost?
It splits the hidden size across heads, letting each head specialize in different relations, then concatenates and mixes them with a linear layer.
When do we prefer encoder-decoder over decoder-only?
We prefer encoder-decoder when the task is explicitly sequence-to-sequence (e.g., translation, summarization with long sources) because cross-attention cleanly conditions on the encoded input.
What does “causal” mean in decoder-only LMs?
Causal means each position can only attend to previous positions, enabling next-token prediction without leaking future information.
What is weight tying and why use it?
It reuses the input embedding matrix for the output projection to reduce parameters and often improve perplexity.
What is the kv-cache and why is it crucial for generation?
It stores past Keys/Values so decoding a new token only computes attention against cached states instead of recomputing all previous layers.
Architecture (Anatomy + Shapes)
What is the minimal Transformer block recipe?
[LayerNorm] → Multi-Head Self-Attention → Residual add → [LayerNorm] → Feed-Forward (two linear layers with activation) → Residual add. (Pre-norm shown.)
Why pre-norm over post-norm in modern LLMs?
Pre-norm improves gradient flow in very deep stacks and is empirically more stable.
What does the FFN actually do?
It expands the hidden dimension (e.g., 4×) with a nonlinearity (GELU/ReLU) and projects back, acting as a per-token MLP to increase representational power.
What are typical tensor shapes in attention?
For batch B, length n, hidden d, heads h, head dim d_h = d/h:
Embeddings: (B, n, d) → Q/K/V: (B, h, n, d_h) → scores: (B, h, n, n) → output: (B, n, d).
What is the output projection after multi-head attention?
Concatenated head outputs (B, n, h·d_h) are linearly projected back to (B, n, d) to mix information across heads.
How do encoder vs decoder blocks differ structurally?
Encoders: self-attention + FFN.
Decoders: masked self-attention + cross-attention (to encoder) + FFN.
What is cross-attention wiring?
Decoder Queries attend to Keys/Values produced by the encoder, allowing the decoder to condition on the source sequence.
What does LayerNorm normalize?
It normalizes features within each token vector (mean/variance across the hidden dimension) to stabilize activations.
Why choose GELU over ReLU in FFNs?
GELU provides smoother gating around zero and empirically improves language model quality.
What is Multi-Query Attention (MQA) and why use it?
MQA shares Keys/Values across heads while keeping separate Queries, reducing memory and latency in decoding with small quality loss.
What is Grouped-Query Attention (GQA)?
GQA is a middle ground where Keys/Values are shared within groups of heads, balancing speed and quality.
Where do positional encodings plug in?
They are added or applied to token embeddings (absolute) or to Q/K (relative/rotary) before computing attention.
What does the final LM head do?
It projects the decoder’s hidden states to vocabulary logits; with weight tying, it shares weights with the input embeddings.
Attention Mechanics (Key Terms)
What is a Query?
A learned linear projection that represents “what information this token is seeking.”
What is a Key?
A learned linear projection that represents “what information this token offers.”
What is a Value?
A learned linear projection that carries the actual information aggregated by attention.
What is a Scaled Dot-Product Attention?
Compute scores = QKᵀ/√dₖ → softmax → weighted sum over V.
What is a Head?
One parallel attention subspace with its own Q/K/V projections; multiple heads run in parallel.
What is a Residual Stream?
The pathway carrying the token representations through the stack; sublayers add to it via skip connections.
what is Pre-LN vs Post-LN?
Pre-LN normalizes inputs to sublayers; Post-LN normalizes outputs. Pre-LN is more stable for deep models.
What is a Causal Mask?
A binary mask that blocks future positions to ensure valid next-token prediction.
Tokens, Embeddings, and Input Representation
TEIR
What is a token in a Transformer?
A token is the basic unit of input, such as a word, subword, character, or image patch, depending on the application.