SECT 5
1/69
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
70 Terms
Unsupervised Learning
Process of analyzing data without pre-classified labels in order to uncover hidden meaning and structure.
Algorithm creates and designs labels based on similarity
Purpose of Unsupervised learning
basis for exploration, interpretation and supervised learning
discover meaning and structure of the data
Clustering
process of grouping unlabeled data where similiar ones are in one cluster and dissimilar in another
Purpose of Clustering
Data Understanding
Class Identification
Outlier and Noise detection
Clustering Methods
Partition based
Hierarchical Based
Density based
Partition Based
Divide data in k groups based on similarity
K means Clustering Idea
Each point is assigned to cluster with nearest centroid
each cluster is represented by a centroid
Centroids values update till their assignments stabilize
K means Setup
K value i.e no. of clusters must be defined
Centroids must be initialized i.e can be random pts, diff values result differently
K means Algo
works best for compact, well-defined clusters

K means pros
efficient O(tkn)
easy
widely used
K means cons
sensitive to outlier and noise
must define k
assumes convex and spherical clusters
may converge to local optimum
requires a well-defined mean
k medoids idea
each cluster is centered around a medoid (most central point)
points are assigned to nearest medoid
each iteration chooses medoid as most representative point
k medoids over k means
medoids are actual data points
robust to noise n outliers
k medoid algo
useful when robustness and interpretability are more imp than speed

k medoids pros
easy to implement
medoids are real datapoints
works with any distance measure
robust to noise n outliers
k medoids cons
may converge to local optimum
must predefine k
assumes convex n spherical clusters
computationally more expensive
PAM (Partitioning Around Medoids)
classic k medoids algo
for medoid selection uses systematic swap
more robust but costly
CLARA(Clustering LARge Applications)
runs PAM on a sample
reduces runtime but quality depends on sample
CLARANS(Clustering Large Applications upon RANdomized Search)
Randomized version of PAM
only on a subset of possible swaps
balances efficiency and quality
Commonalities of k means n k medoids
belongingness to a cluster is dependent on distance to the center element, thus represents Vornoi diagram
Limitations of k means and k medoids
assums a convex partioning
must predefine k
Expectation Maximization
With incomplete data, it helps find missing values with expectation and helps to refine the model with maximization
Need for EM
provides a principled, probabilitic process
genereal use in clustering, Handling Missing Values, HMMs
EM For Clustering Idea
Each cluster is a gaussian distribution(cov, mean, weights)
points assigned probabailitically
best when clusters are non spherical and need probabilitic assignment
EM for clustering pros
captures elliptical/non-spherical clusters
more flexible
soft clustering
grounded in probabilitic work
EM Clustering Steps
assign pts to cluster distributions
reestimate mean n variance

EM Clustering cons
computationally heavy
must predefine k
sensitive to initialization and can converge to local optimum
assume all clusters follow same distribution
Silhouette coefficient
measures how well a point fits in its own cluster vs othger clusters
used for evaluating clusters
Silhouette Coefficient Formula

Hierachical Clustering
builds a hierachy of nested clusters without defining the no. of clusters
Hierachical Clustering idea
in the beginning each pt is it’s own cluster
clusters are merged or split
produces a dendogram to cshow the different clusters
Types of hierachical Clustering
Single linkage
complete linkage
centroid linkage
Dendogram
is a tree diagram that shows the arrangement of clusters produced by hierarchlical clustering
a cut in the dendogram shows hoe to partition the clusters
Hierarchical clustering Algo

Single Linkage
Distance is defined as the minimum distance between any pair of points
O(n2 )
sensitive to noise and outliers
good for detecting arbitarily shaped clusters
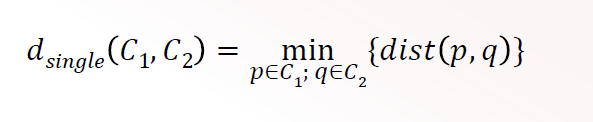
Complete Linkage
maximum distance between any pair of points
O(n2 )
favours compact, spherical clusters
still sensitive to outliers
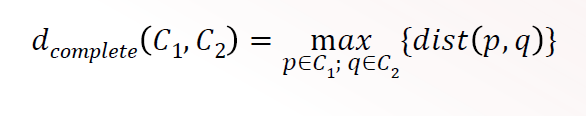
Centroid Linkage
Distance is defined as distance between the centroids of 2 clusters
O(n)
can produce inversions
considers all points
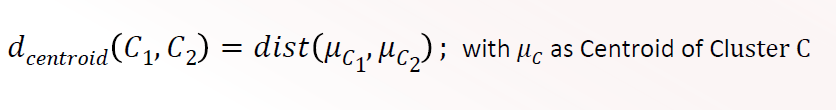
Density Based Clustering
Clusters are defined dense regions of points separated by areas of low density
density based clustering idea
points inside a cluster are densely connected
sparse regions act as separators
noise n outliers are unassigned
Density based clustering advantages
tackles noise and outliers
no need to define no. of clusters
works for arbitary shaped clusters
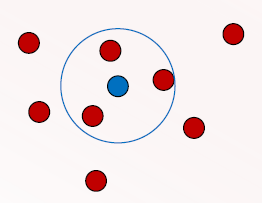
Core object
An object with atleast minpoint no. of neighbours within ε
forms heart of the region
border object
lies within neighnourhood of core object but it itself has <Minpt no. of neighbours
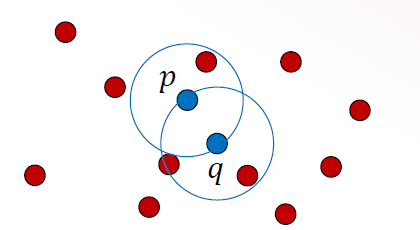
Directly density reachable
a point p is directly density reachable to a point q if p lies within ε of q and q is core object
density reachable
a point p is density reachable to point q if there exist a chain from q to p such that each point in the chain is directly density reachable pointing towards p
q is core object p can be a border object
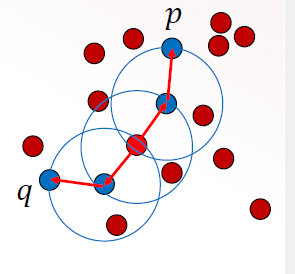
Density connected
two points p and q are density connected if both are density reachable to a common core object
p and q can be border objects
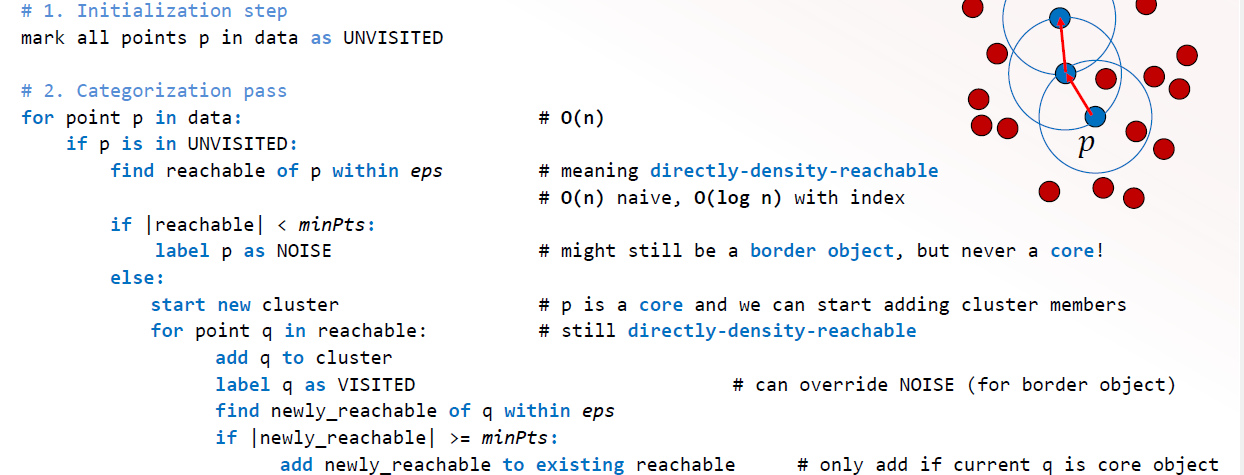
DBSCAN (Density BasedSpatial Clustering with Applications of Noise
identify core obj and find the minpoints within ε
grow clusters by connectly density reachable points
pts that are not density reachable to any core obj are labelled as noise
DBSCAN Algo
DBSCAN Pros
detectsd noise n outliers
detects arbitary shape
works well for evenly dense clusters
DBSCAN Cons
Require 2 params
sensitive to param changes
only for uniformly dense
degrades in in performance for high dimension
OPTICS(Ordering Points to Identify Clustering Structure)
use an ordering of points based on density
produces a reachability plot
works for varying density
generalizes DBSCAN ; is flexible
Reachability plot
shows valleys for clusters and peaks for sparse regions
core distance
minimum ε such that point becomes a core object
Reachability distance
measures how far a point is from prev point
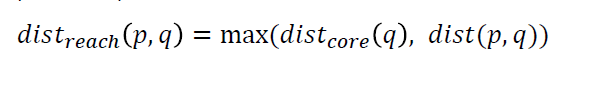
why clustering given deep learning era
unsupervised learning is essential:1st step of exploration, reveal structure
complements deep learning: used for pretraining n representation learning
practically applicable : faster, cheaper and simpler
Drawbacks of clustering
curse of dimensionality: distances becomes less meaningful, clusters lose separation
partition based: vornoi breaks down in high dim
hierarchical: overpowered by noise
density: sparseness
Clustering in High dimension
ADAPT: dimensionality reduction, subset clustering: search clusters in subsets, feature selection or weighting: reduce noise dimensions
However distance is still unreliable and most of it depends on preprocessing chossing
Solution: instead of grouping in clusters we find patterns as in association rule mining
Transaction Data
Transaction DB: set of transactions
each transactions contains a set of item I
I is the itemset i.e collection of items
Support
Fraction of Transactions that contain an itemset
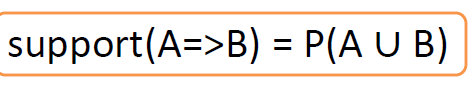
Frequent Itemset
has support >= minsup threshold
Association rule
defines relationship between 2 itsemsets in a database
Confidence
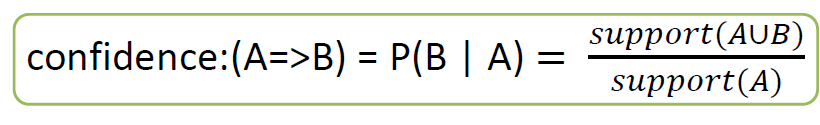
Types of Associations
Single dim
multi dim
binary/boolean
quantitative
Association Rule Mining Steps
Find all freq itemsets (min Sup)
generate association rules based on thes(min sup, min conf)
Problem with no. of itemset
possible no. of freq itemsets is exponential, i.e if an itemset is freq its subsets r also freq
=> 2no. of elems in freq itemset - 1
Brute Force Approach
Each itemset has candidates for a candidate freq itemset
count support of each candidate by scanning database
=> O(NMW) N= no. of transcations, M= no. of candidates, W= width of Itemset
Improvement on Brute force
Reduce no. of Candidates: Pruning
Reduce no. of Transcations: as it increases
Reduce no. of NM comparisons: Use efficient data structures for either one
Apriori Principle Idea
If itemset is freq, then all its subsets are freq
If itemset is infreq then superset need not be tested
Apriori Algo

Association Rules generation
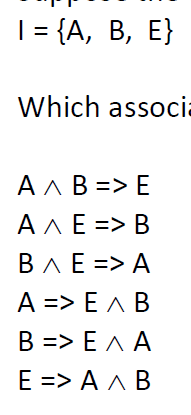
Uses of Assoc Rule Mining
Test doc clustering
microarray clustering
market basket analysis
Reccomendation system