RAG using GenAI and Oracle23ai Vector Search
1/48
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
49 Terms
OCI GenAI and Langchain integration
langchain_community provides a wrapper class for using OCI GenAI as LLM in Langchain applications
langchain_community.llms.OCIGenAI
Langchain application components
LLMs
Prompts
Document Loaders
Memory
Vector stores
Chains
Langchain Models types
LLM - Text completion models, string input, string output
Chat models - LLM tuned for having converstations. chat messages input, AI message as output
Langchain Prompts
Created using Prompt templates
String prompt template
Chat prompt template
Chat prompt template
Supports a list of messages
Each chat message has content + additional parameter called ROLE
Langchain Chains
Used to create chains of components, including LLMs and other types of components
Created using
LCEL
Legacy - python classes like LLM chain, etc
Langchain Expression Language (LCEL)
Create chains declaratively using LCEL
Langchain Prompt, Model, Chain interaction
User query + Prompt (can be from Prompt template) → Prompt value → LLM → Respose
Chain → Prompt | llm
Langchain Memory
To store information about past interactions
Chain interacts with memory twice in a run
After User input but Before chat execution - Read from Memory
After Core logic but Before Output - Write to Memory
Chain retrieves the converstation from memory ising key and passes it to the LLM along with question. Once a new answer is returned, it writes back the query and answer to the memory
Memory types
Summary of contents
extracted entities like Names
OCI GenAI and Oracle 23ai Integration
Langchain supports Oracle23ai as Vector store
Offers python classes to store and search embeddings in Oracle 23ai vector store
OCI GenAI used to generate embeddings outside the db, using DB UTILS and REST APIs.
SELECT AI can use OCI GenAI to generate SQL to query data stored in DB using natural language.
Retrieval Augmented Generation RAG
Method of generating text using additional information fetched from an external data source
Retrieve documents and pass them a seq2seq model
RAG Benefits
Mitigate bias in training data as RAG picks data from other sources
Overcome model limitations like token limits, only topk search results are fed to LLM instead of whole document.
Handle queries without retraining
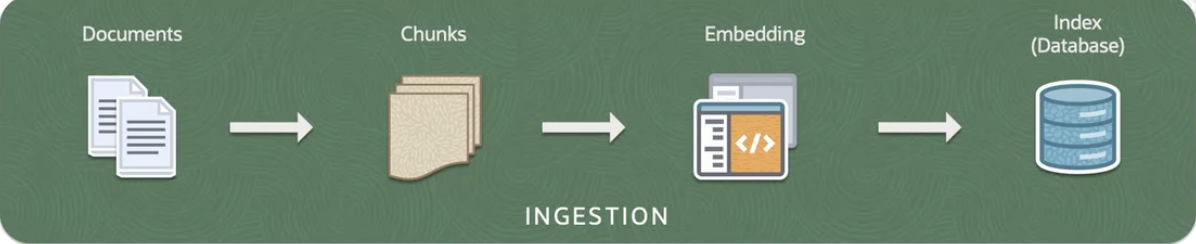
RAG Pipeline
INGESTION
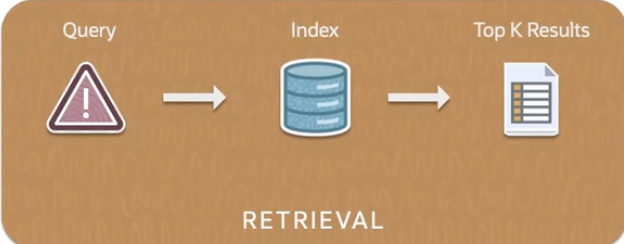
RETRIEVAL
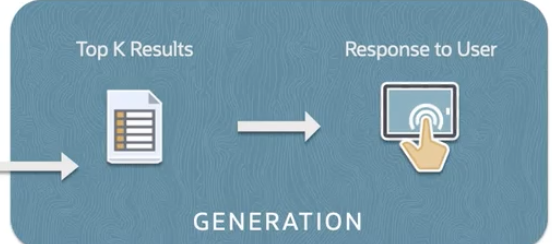
GENERATION
****** INGESTION *****
Loading the documents
Documents broken to chunks
Embedding of chunks
Indexing in a database
***** RETRIEVAL *****
Query → Index → Top K Results
Most relevant chunks retrieved
***** GENERATION *****
Generates a response based on the information retrieved
Selected chunks from Retrieval phase are fed into a generative model
Generative model - Neural network like a transformer
Coherent and contextually relevant response generated
Document Loading
Document loaders used
Data formats - PDF,CSV,HTML,JSON,Web pages, markdown
All docs from a directory can be loaded
Chunking
Text splitters used to split document into chunks
Chunk size - depends on the input size constraints and the context window size
Too small → Not useful semantically
Too large → Not specific semantically
Chunk Overlap
number of overlapping characters between adjacent chunks
Preserves context between chunks
Helps to create a richer prompt
Splitting method.
Default separators - [“\n\n” “\n”, “ “, ““ ]
To keep the chunk semantically meaningful
First tries to retain paragraph, if not sentence, if not word
Read and Split documents
RecursiveCharacterTextSplitter from langchain.text_splitter
BaseDocumentTransformer, Document from langchain_core.documents
text_splitter = RecursiveCharacterTextSplitter - chunksize, chunkoverlap
chunks = text_splitter.split_text(text)
Generating vector embeddings inside Oracle DB 23ai
Download pretrained embedding models
Convert to ONNX format
Import ONNX format models to DB 23ai
Vector Datatype
Stores vector embeddings alongside other business data
Add metadata to chunks and create documents
Document object with page content and metadata
Create a dictionary representing a row of data with keys for id, link and text
Iterate through chunks, extract each page number, and actual text content of the chunk and then create a dictionary using the ID, link and text as keys
Pass dictionary to Docs wrapper function
Function returns a document which wraps metadata and page content
Embed documents and store in the vector database
OracleVS from langchain_communit.vectorstores.oraclevs OCIGenAIEmbeddings from langchain_community.embeddings
DistanceStrategy from langchain_community.vectorstores.utils
embed_model = OCIGenAIEmbeddings (model_id, service_endpoint, compartment_id, auth_type)
knowledge_base = OracleVS.from_documents(docs,embed_model, client, table_name, distancestrategy.DOT_PRODUCT)
Retrieval
User query → Encoded as a vector → sent to AI vector search
AI vector search finds documents that match the users question
DOT Product
Magnitude of projection of one vector onto the other.
Considers magnitude and angle
More magnitude → semantically richer content
COSINE product
Considers only angle between vectors and not magnitude
Less Angle → More similar
Vector Indexes
Specialized data structures designed for similarity searches in high dimensional vector spaces
Uses techniques like Clustering, Partitioning, Neighbour graphs to group similar vectors together
Oracle AI Vector search supports which index types
HNSW → In-memory Neighbour Graph Vector Index
IVF → Neighbour Partition Vector index
Retrieve documents and get response from LLM
RetrievalQA from langchain.chains
retv = vs.as_retriever(search_type=”similarity”, search_kwargs={k:3}
llm = ChatOCIGenAI ( model, service endpoint, comptid, auth_type)
chain = retrievalQA.from_chain_type(llm, retv , return_source_documents=True)
response = chain.invoke(“Tex”)
Langchain python
chain = prompt | llm
response = chain.invoke
Langchain memory
ConversationBufferMemory from langchain.memory
memory = ConversationBufferMemory()
memory.chat_memory
Oracle 23ai DB ports
1521/22
OCI GenAI Agents
Fully managed service that combines power of llms with an intelligent retrieval system aimed at creating contextually relevant answers by searching your knowledge base.
Ex. AI agent to book flight ticket with room booking
Applications of LLMs that are Packaged and validated ,ready to use out-of-the-box
LLM tasks in AI agent
Reasoning
Acting
Persona
Planning
Input for AI agent
Short/long term memory
Tools
Prompt
Knowledge
AI Agent can
Perform complex tasks on its own
Mimics human chainofthought processing
Effective tool for automating processes
Utilize knowledge
AI Agents Concepts
GenAI model
Agent
Knowledge Base
Data Source and Data Store
Data Ingestion
Answerability
Model can generate relevant responses to different user queries
Groundedness
Model generated responses should be tracked to different data sources
Agent Concepts
Session
Agent Endpoint
Trace
Citation
Content Moderation
AI agents can read pdf
Charts - 2d with labeled axes
Tables - with rows and columns
URLs - as is
Number of endpoints that you can create for each agent
Default = 3
No. of files
1000
No. of knowledge bases per tenancy
Default = 3