Looks like no one added any tags here yet for you.
Big data is defined as
extremely large set of nontraditional data used to gain meaningful business insights or predict significant business events
The Three V’s of Big Data are
Volume, Variety, Velocity
Volume refers to the
amount of data from many sources
Variety refers to the
two types of data….(multiple formats)
Traditional Data (text, numbers, pictures, video, sound)
Behavioral Data (clicks and pauses)
Velocity refers to the
speed of creation for data
Hadoop is defined as
open-source software framework that is used for storing and processing big data in a distributed computing environment (yellow elephant logo)
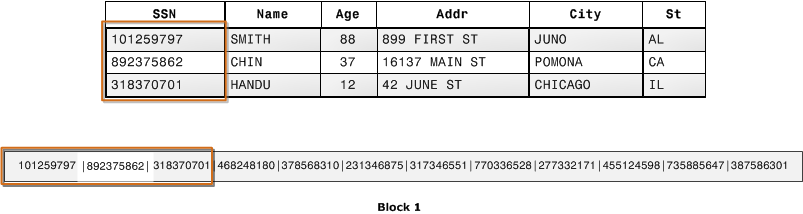
Data redundancy
Nodes in Hadoop are
Devices (Example: Servers)
A Cluster in Hadoop are
groups of nodes
Unstructured Data is
not organized or easily interpreted and is hard to predict how it looks (often stored in nonrelational database systems)
Structured Data is
traditional in its retrieval and storage in DBMS (we know what to expect)
Commodity Hardware is
hardware that is readily available, inexpensive, and amassed in large quantities. Benefits by reducing costs
Hadoop Distributed File System is defined as
a distributed file system designed to run on commodity hardware. It is fault-tolerant (reliable) allowing it to degrade gracefully
Storage component of Hadoop
Graceful degradation is
the ability of a machine or network to maintain limited functionality even when a large portion of it has been rendered inoperative,
The Architecture for the Hadoop Distributed File System is
master/slave architecture
In the master/slave architecture
the master node (name-node) controls the cluster and knows which slave node (server or data node) has what
FAT (File Allocation Table) purpose is to
keep track of where files are stored on a disk and how much space is available for new files
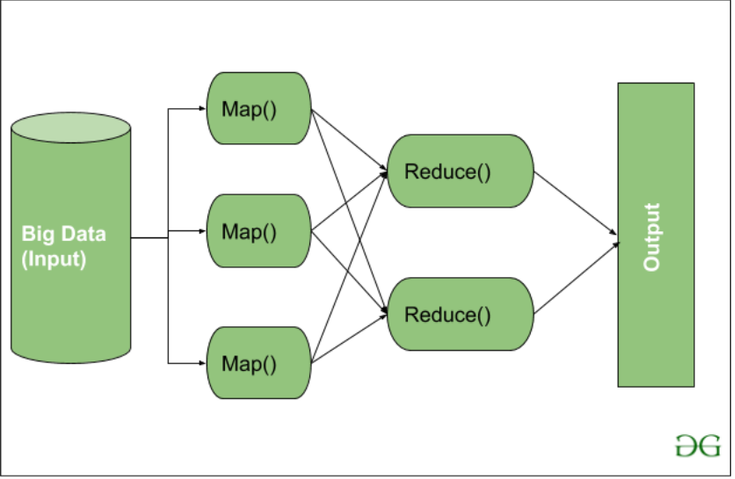
Hadoop Map Reduce
Map: process and map input data, local solution (per node)
Reduce: process the data that comes after map and getting rid of duplicate data, aggregate solution (per cluster)
(Produces a new set of output, which will be stored in the HDFS)
Map Reduce is
batch-oriented, meaning it processes large amounts of data in a batch or group. Need all data that is relational
Not all data is
relational (non-relational data includes movies, text, music, photos, social media)
Hadoop YARN (Yet Another Resource Negotiator) is
Real-time streaming
Opportunistic, meaning it runs when node resources are available
Works with MapReduce
Distributed through cluster nodes
NoSQL
is a non-relational DMBS concept that is distributed and open source. (Geared for Big Data that is unstructured and semi-structured)
Big data is scaled
horizontally (Note: Hadoop grows horizontally)
SQL DBs are scaled
vertically
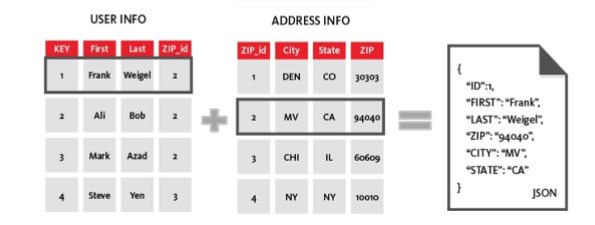
NoSQL Document puts
multi-attribute data in a single “Document”
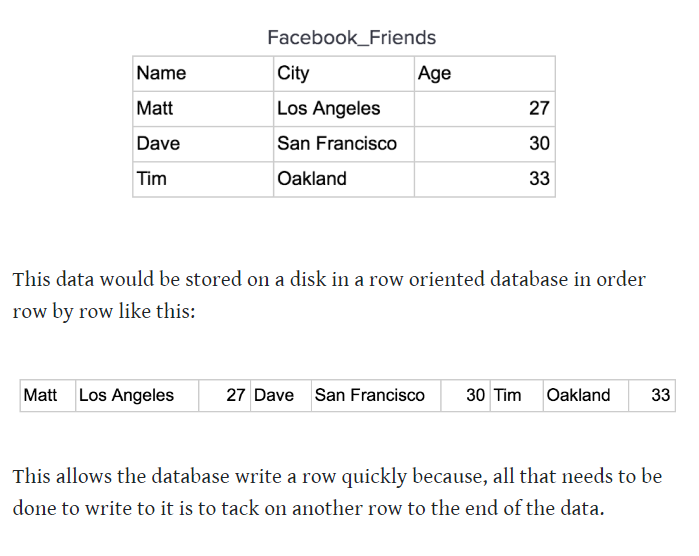
NoSQL Rows vs Columns…
Rows: storing data row by row through a table
Columns: storing data in blocks (more storage=more blocks=longer address= more bits)
LOOK AT IMAGE TO VISUALIZE IT
Columnar Storage is when
data stored in columns, not rows (better performance for single-attributed operations)
Enterprise Applications is defined as
software that supports enterprise-level tasks (powerful, complex, sophisticated, expensive)
Essentially databases
Data Warehousing is defined as
logically centralized large database (physically centralized or distributed)
Powerful enterprise-wide querying applications
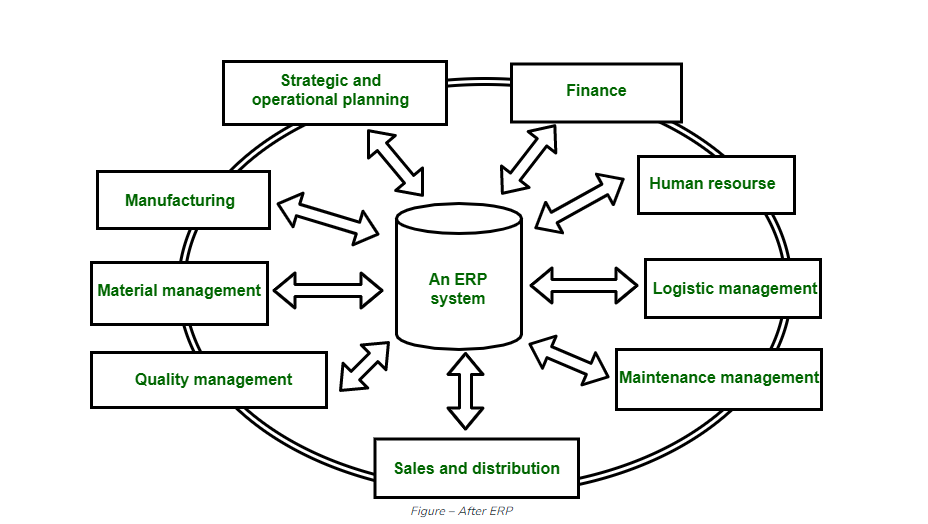
Enterprise Resource Planning are
category of software tools which are used to manage the data of an enterprise and helps deal with different departments of an enterprise
E.T.L stands for
Extract. Transform. Load
(Three database functions that are combined into one tool to retrieve data from one database and place it into another database)
Data Mart is defined as
subset of data warehouse (In other words; a simple form of data warehouse focused on a single subject or line of business)
Data Mart characteristics include being
Topic-Oriented (Ex; region, product, business unit)
Focused (Ex; summary or full data, including other data marts)
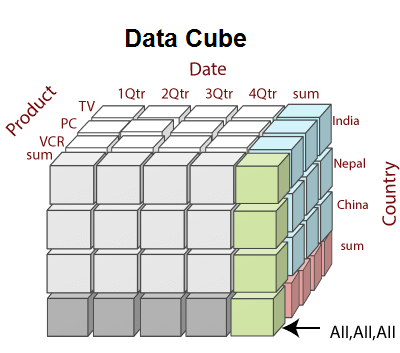
Data Cube is defined as a
multi-dimensional data structure designed to make data query and analysis more efficient (Data mart or not)
For example, a hierarchy (which makes up a single dimension of the cube) for location data might have three levels: states within regions within countries
Data Mining is defined as
practice of uncovering new knowledge, identifying patterns or relationships (Querying requires previous knowledge)
Online Analytical Processing (OLAP) is defined as
is a software that reviews, manipulates, and queries large amounts of data in real time (used during data mining and may use data cubes & data marts)
Federated Databases is defined as
type of distributed DBMS that integrates data from different sources, providing a single interface for all users.
FDs are Heterogeneous, meaning each FD have different schema, data models, formats, making it hard to integrate into one single local database
FDs are Autonomous, meaning they have control over their own data and has its own local users, creating a virtual database.
(KAHOOT QUESTION) An enterprise application is generally not
a. Open-sourced
b. Powerful
c. Complex
d. Single-user
d. single user
(KAHOOT QUESTION) Most, if not all, enterprise apps are, essentially
a. ERP
b. SQL
c. Databases
d. 3NF
c. Databases
(KAHOOT QUESTION) An enterprise data warehouse is not
a. Cheap
b. Large
c. Powerful
d. Complex
a. Cheap
(KAHOOT QUESTION) Selecting, cleaning, and storing the data for an EDW is known as
a. GTL
b. NFL
c. ETL
c. ETL (Extract. Transform. Load)
(KAHOOT QUESTION) True or False, A data cube is an actual cube
a. True
b. False
b. False
(KAHOOT QUESTION) Enterprise Resource Planning is
a. SAP
b. A category software
c. A data warehouse
d. FTW
b. A category software
(KAHOOT QUESTION) Heterogeneous DB environment is
a. Federated
b. Normalized
c. Distributed
d. Stimulated
a. Federated
(KAHOOT QUESTION) Not an enterprise app
a. MySQL
b. Oracle
c. MS Excel
d. SAP
c. MS Excel