IAU
1/299
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
300 Terms
Do akých hlavných kategórii sa deli Machine Learning (types of machine learning)?
Supervised learning - Task driven, all data is labeled
Unsupervised learning - Data driven, all data is unlabeled
Reinforcement learning - Learn from errors
Vymenuj typy Supervised learning
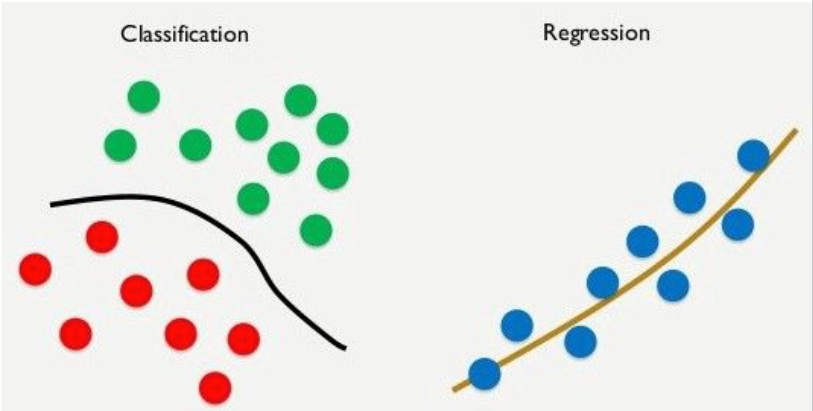
Classification - klasifikacia
Regression - regresia
Vymenuj aplikacie Unsupervised learning
Clustering
Dimensionality reduction
Vymenuj aplikacie Reinforcement learning
Real-time decisions
Robot navigation
Game AI
Skill acquisition
Ako vyzera Data Science Lifecycle?
Cyklus:
Define problem statement - presne definovať problém
Data collection - Zber dát:
Primárny zber dát - Zber nových dát, ak žiadne podobné neexistujú
Sekundárny zber dát - Použitie už existujúcich dát z rôznych zdrojov
Data Quality Check and Remediation - zabezpečenie, že dáta sú presné, úplné a bez chýb
EDA (Exploratory Data Analysis) - porozumieť štruktúre dát
Modeling the Data - vytváranie a trénovanie strojových modelov
Data Communication - Model Deployment:
Komunikácia - Prezentácia zistení cieľovej skupine (napr. ukázanie výsledkov projektu)
Nasadenie - implementovaný do produkčného prostredia
Co je hlavnou podstatou Data Science?
Využívanie dát na riešenie problémov
Z čoho sa skladá práca dátového vedca?
Understand the data
Extract useful information out of it
Apply this in solving the problems
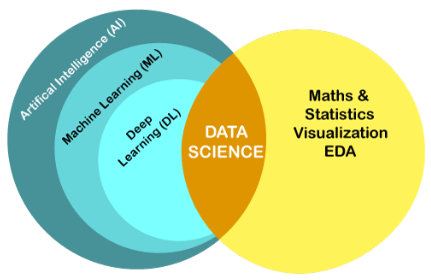
Vysvetli vzťah medzi Data Science, AI a ML
Data Science:
Najširší koncept
Zbieranie, prípravu a analýzu dát
Celý dátový cyklus
AI:
Podmnožina dátovej vedy, ma pod sebou ML
Technológie, ktoré umožňujú strojom rozumieť, interpretovať, učiť sa a robiť inteligentné rozhodnutia
ML:
Podmnožina AI
algoritmy, ktoré sa dokážu učiť a zlepšovať na základe dát
Vymenuj požiadavky na prácu v dátovej vede
Netechnické:
Zvedavosť
Kritické myslenie
Komunikačné zručnosti
Technické:
ML
Štatistika
Matematické modelovanie
Počítačové programovanie
Databázy
Čo je to CRISP-DM?
Cross-Industry Standard Process for Data Mining
štandard pre získavanie, analyzovanie, modelovanie a aplikáciu dát
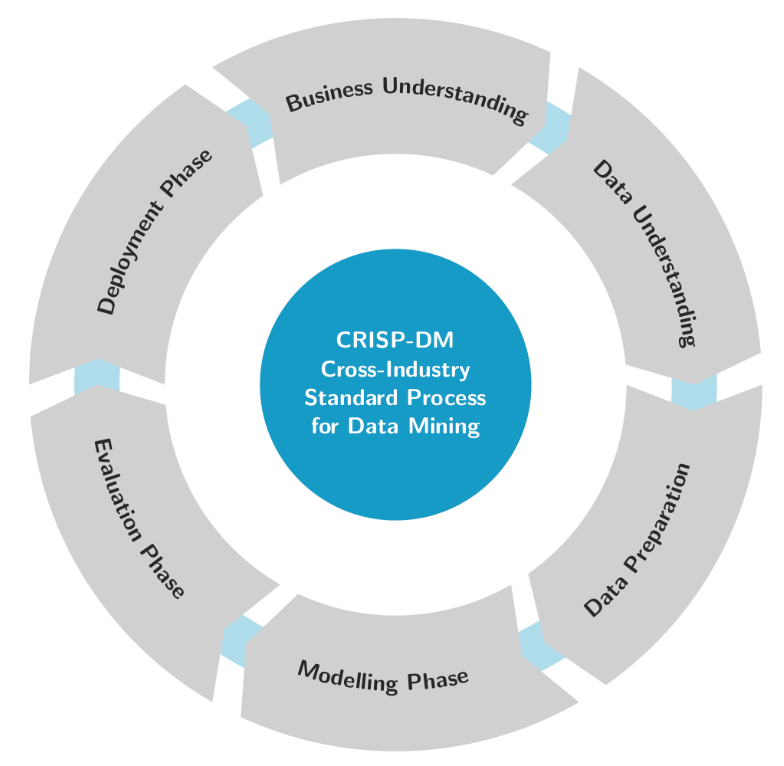
Vymenuj kroky CRISP-DM.
CRISP-DM je repetitive a kroky, až na deployment sa môžu opakovať.
Business Understanding - Jasne definovať problém, ktorý treba riešiť.
Data Understanding - EDA
Data Preparation - môže zabrať až 80 % času projektu
Modeling
Evaluation
Deployment / Production
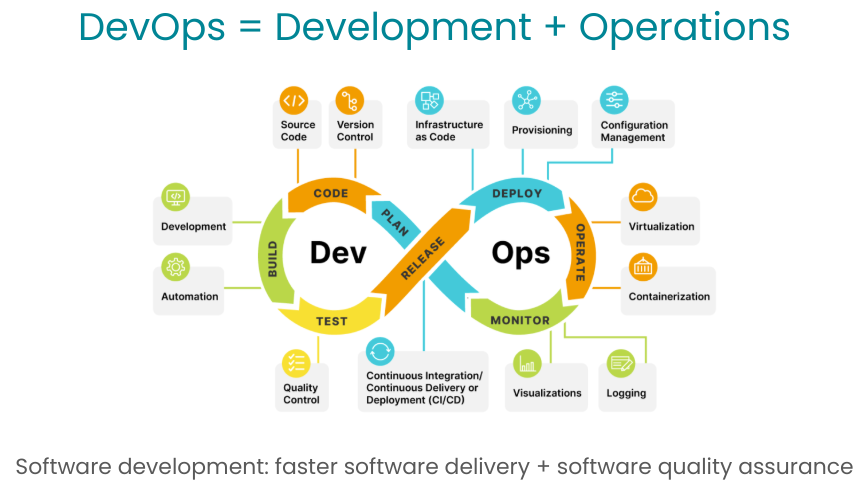
DevOps diagram fáz
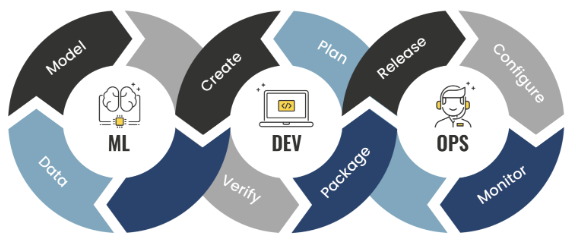
MLOPs diagram fáz
Data Science Ethics
Protect user and public
Collect only needed data
Promote transparency
Guard privacy
Identify and scrub (remove) sensitive data
React quickly and professionally to data breaches
Ako znie filozofia EDA?
EDA ako súbor nástrojov, medzi ktoré patria grafy, vizualizácie a štatistiky
EDA ako mindset, kde ide o porozumenie dát a ich spájanie s procesmi
EDA ako osobný proces medzi analytikom a dátami
Data variable types s ich popismi a podtypmi
Numerical / quantitative:
Continuous = float
Discrete = integer
Categorical / qualitative:
Nominal - bez prirodzeného poradia, napr. red, green, blue
Ordinal - majú prirodzené poradie, napr. always, usually, sometimes, rarely
Boolean
Text
Time series - timestamp
Multimedia - video, audio, image
EDA postup / stratégia
Analýza jednotlivých premenných
Analýza vzťahov medzi premennými
Vizualizácia dát v grafoch
Analýza štatistických metrík
Iteratívny proces - opakuj potrebné body
Identifikuj otázky na analýzu dát a zoradiť ich od najmenej dôležitých po čo najviac
Hľadaj odpovede na otázky pomocou grafických a analytických prístupov
Zodpovedaj na otázky a následne z nich vyvoď ďalšie
Objectives of EDA
Discover patterns
Spot anomalies
Frame hypothesis
Check assumptions
Ako vyzerá Uniform distribution?

Ako vyzerá Bernoulli distribution?

Ako vyzerá Hypergeometric distribution?

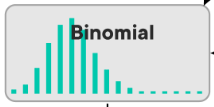
Ako vyzerá Binomial distribution?
Ako vyzerá Negative Binomial distribution?

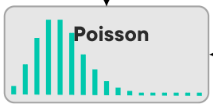
Ako vyzerá Poisson distribution?
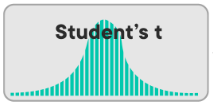
Ako vyzerá Geometric distribution?
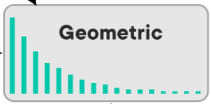
Ako vyzerá Exponential distribution?
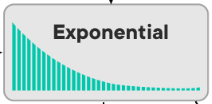
Ako vyzerá Normal / Gaussian distribution?
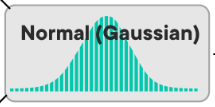
Ako vyzerá Student’s t distribution?
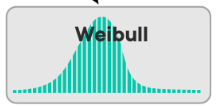
Ako vyzerá Weibull distribution?
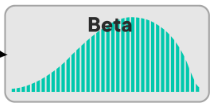
Ako vyzerá Beta distribution?
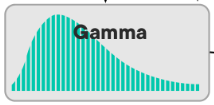
Ako vyzerá Gamma distribution?
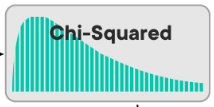
Ako vyzerá Chi-Squared distribution?
Ako vyzerá Log Normal distribution?
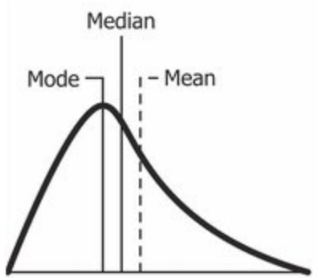
Ako vyzerá Normal distribution, ktorá má Positive Skew?
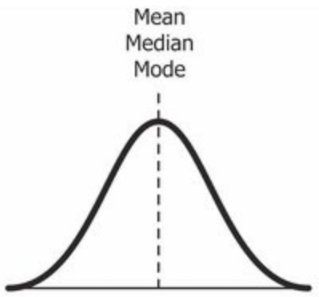
Ako vyzerá Normal distribution, ktorá má Symmetrical Distribution?
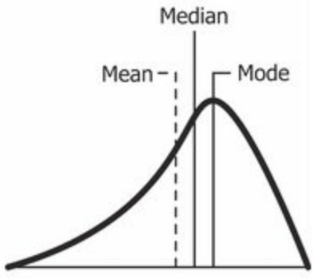
Ako vyzerá Normal distribution, ktorá má Negative Skew?
Čo je to central tendency?
Centrálna tendencia je stred dátovej distribúcie, vyjadruje kde sa sústreďuje väčšina dát.
Vymenuj Measurements of Central tendency
mean - priemer
median - stredná hodnota
mode - najčastejšie sa vyskytujúca hodnota
Vymenuj Measurements of Dispersion.
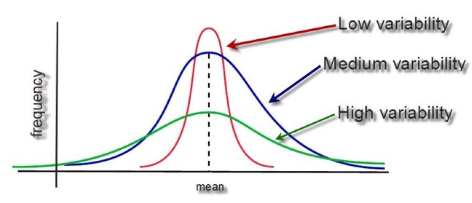
Variance - rozptyl, meria priemernú kvadratickú odchýlku každej hodnoty od priemeru
Standard deviation - štandardná odchyľka, je odmocnina z rozptylu
Aký je rozdiel medzi Population variance a Sample variance?
Population variance:
Meria, ako sa jednotlivé hodnoty v celej populácii odlišujú od priemeru populácie.
Používa celú populáciu a presný priemer populácie.
Sample variance:
Odhad variability na základe vzorky z populácie.
Používa len vzorku a odhaduje priemer vzorky.
Graf s rôznymi Variances of Samples
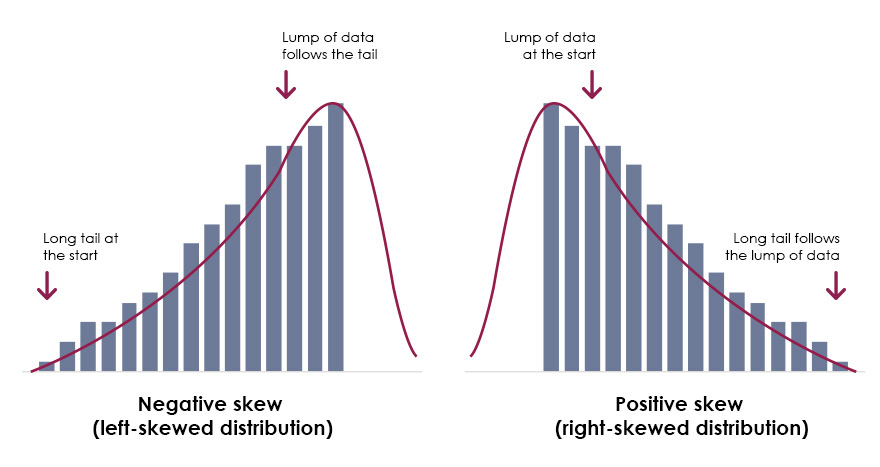
Čo je to Skewness a aké je jej rozloženie?
šikmosť
Skewness is a measure of asymmetry
Rozloženie:
= 0 - normally distributed
> 0 - more weight in the left tail - positive skew
< 0 - more weight in the right tail - negative skew
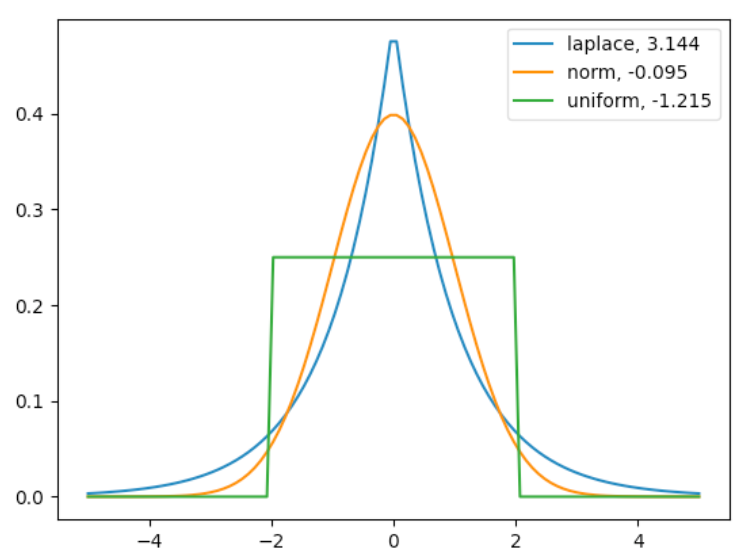
Čo je to Kurtosis?
špicatosť
meria, či má rozloženie ostrý vrchol (peaked) alebo plochý vrchol (flat top) v porovnaní s normálnym rozdelením
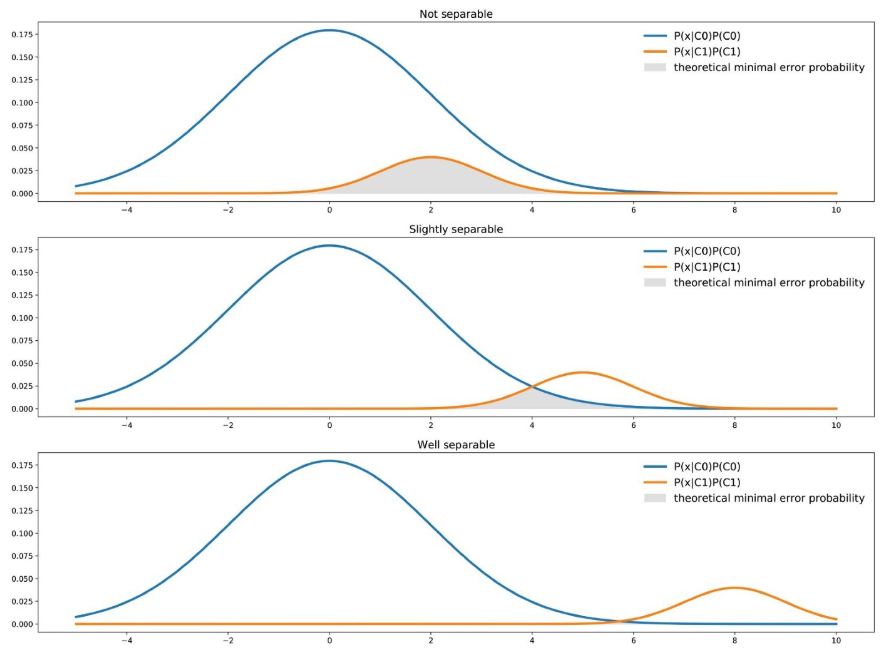
Aký má vplyv normálová distribúcia na kvalitu klasifikácie?
Čím je väčší prekryv medzi distribúciami, tým je vyššia pravdepodobnosť chyby
prípady:
Not separable - výrazne sa prekrývajú (sú veľmi podobné), vysoká pravdepodobnosť chyby
Slightly separable - rozdelenia tried sú oddelené, ale stále sa mierne prekrývajú, Pravdepodobnosť chyby sa znižuje, ale stále nie je zanedbateľná
Well separable - rozdelenia tried sú takmer úplne oddelené, veľmi nízka pravdepodobnosť chyby
Čo je to Correlation coefficient, typy a hodnoty?
meria silu a smer lineárneho vzťahu medzi dvoma premennými
typy korelácií:
Pearson correlation coefficient - PCC
Matthews correlation coefficient - MCC
Phi coefficient
Ak je hodnota korelačného koeficientu:
= 1 - perfektná kladná korelácia
= 0 - žiadna korelácia
= -1 - perfektná záporná korelácia
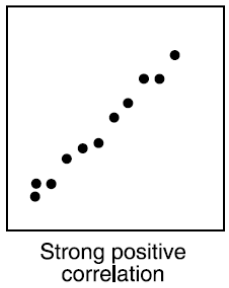
Ako vyzerá graf dvoch premenných, medzi ktorými je Strong positive correlation?
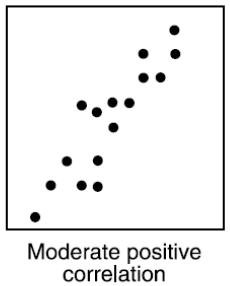
Ako vyzerá graf dvoch premenných, medzi ktorými je Moderate positive correlation?
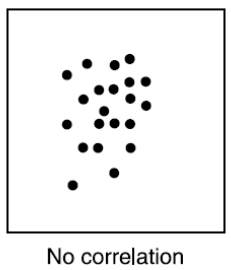
Ako vyzerá graf dvoch premenných, medzi ktorými je No correlation?
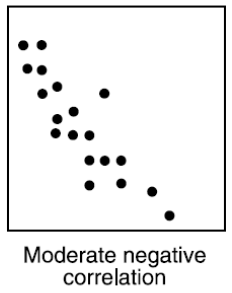
Ako vyzerá graf dvoch premenných, medzi ktorými je Moderate negative correlation?
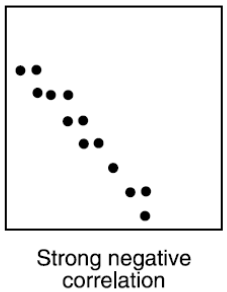
Ako vyzerá graf dvoch premenných, medzi ktorými je Strong negative correlation?
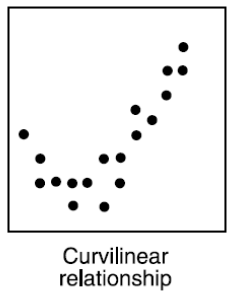
Ako vyzerá graf dvoch premenných, medzi ktorými je Curvilinear correlation?
Čo je to podobnosť?
Podobnosť (similarity) medzi objektami vyjadruje, ako blízko sú si v určitej dimenzii.
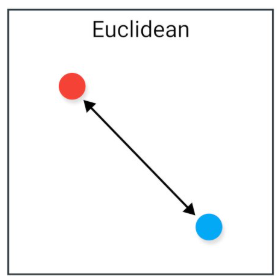
Čo je to Euclidean distance?
Meria „priamu“ vzdialenosť medzi dvoma bodmi v n-dimenzionálnom priestore.
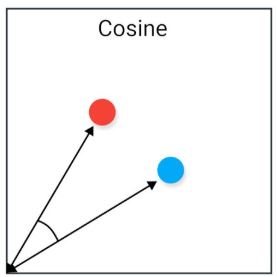
Čo je to Cosine similarity?
Meria uhol medzi dvoma vektormi v priestore, pričom ignoruje ich veľkosť (vektorová normalizácia).
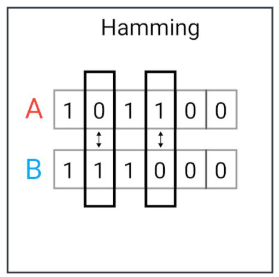
Čo je to Hamming distance?
Počet pozícií, na ktorých sa dva binárne reťazce (alebo vektory) líšia.
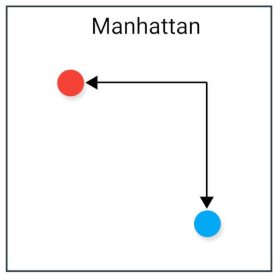
Čo je to Manhattan distance?
Meria vzdialenosť ako súčet absolútnych rozdielov medzi súradnicami.
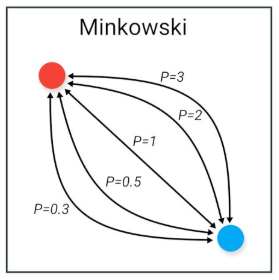
Čo je to Minkowski distance?
Generalizuje Euklidovskú a Manhattanskú vzdialenosť.
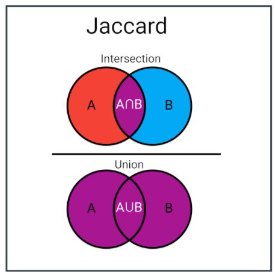
Čo je to Jaccard similarity?
Meria podobnosť medzi množinami.
Čo je to Haversine distance?
Používa sa na výpočet vzdialeností medzi bodmi na sfére.
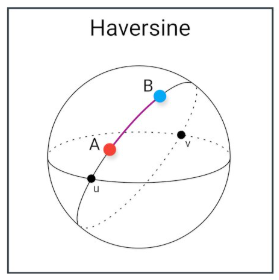
Vymenuj typy korelácii s ich metódami.
Linear correlations - Merajú lineárny vzťah medzi dvoma premennými.
Information Gain
R2
Rank Correlations - Merajú, ako sa poradie hodnôt jednej premennej zhoduje s poradiami hodnôt druhej premennej.
Spearman
Kendall
Heatmap - Grafická reprezentácia korelačných koeficientov medzi premennými v matici.
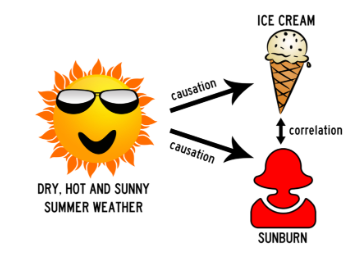
Does correlation imply causation?
Znamená korelácia príčinu súvislosti?
Nie. Aj keď dve premenné vykazujú silnú koreláciu, neznamená to, že jedna priamo spôsobuje zmenu v druhej.
Correlation = ako silne sú dve premenné lineárne závislé
Causation = zmena v jednej premennej spôsobuje zmenu v druhej premennej
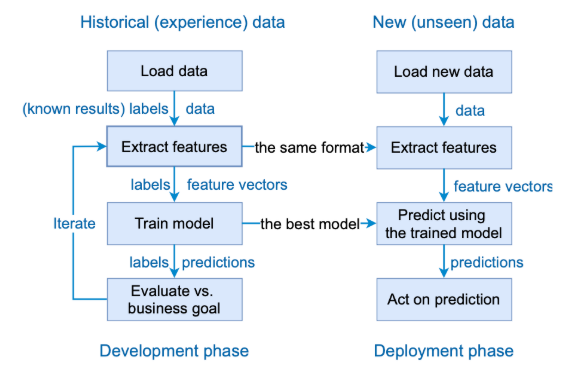
Workflow pre machine learning v kontexte supervised learning
Čo je to data drift a aké má dôsledky?
Zmenu v distribúcii dát, ktoré prichádzajú v produkcii, v porovnaní s distribúciou dát použitou počas tréningu modelu.
Dôsledkom je zníženie presnosti modelu, pretože model už nedokáže správne generalizovať na nových dátach
Čo je to concept / model drift a aké má dôsledky?
Znamená, že vzťah medzi vstupmi a výstupmi, ktorý model zachytil počas tréningu, sa mení. Pokročilejšia forma data drift, kde dochádza k zmene samotnej podstaty problému.
Dôsledkom je, že začne robiť nesprávne predikcie, pretože jeho pôvodný koncept už neplatí.
Aké sú zásady pri data sampling?
musia byť reprezentatívne pre celú populáciu, z ktorej boli získané
musia obsahovať dostatok informácií, aby model dokázal generalizovať na nové, nevidené dáta
je dôležité zahrnúť všetky relevantné premenné (features), pretože medzi nimi môžu byť závislosti alebo vzťahy, ktoré ovplyvňujú výsledky
Aké sú kľúčové kroky pri data sampling?
Take multiple samples - použitie viacerých vzoriek z populácie zvyšuje spoľahlivosť výsledkov
Repeat the survey - Opakovanie zisťovania pomáha overiť, či výsledky skutočne reprezentujú celú populáciu
For big sample size, use cross-validation - Rozdeľte dáta na tréningové a testovacie časti. Pomocou krížovej validácie otestujte model na rôznych častiach dát a overte jeho výkon.
Čo je to Subsampling?
Subsampling je technika, ktorá sa používa pri práci s veľkými datasetmi, aby sa z nich vybrala podmnožina dát, ktorá:
Reprezentuje celý dataset
Znižuje výpočtové náklady
Umožňuje generalizáciu modelu
Ako sa delia dáta?
Training sample - Používa sa na trénovanie modelu / naučenie vzťahov medzi features a cieľovými premennými. Pomocou nich sa učí parametre modelu.
Testing sample - Používa sa na hodnotenie výkonu modelu na nevidených dátach. Nesmú byť použité pri tréningu modelu.
Validation sample - Používajú sa na doladenie hyperparametrov modelu. Slúžia na priebežné hodnotenie modelu počas tréningu.
Všetky vzorky musia reprezentovať populáciu dát.
Shuffling sa používa na zabezpečenie náhodnosti v rozdelení dát.
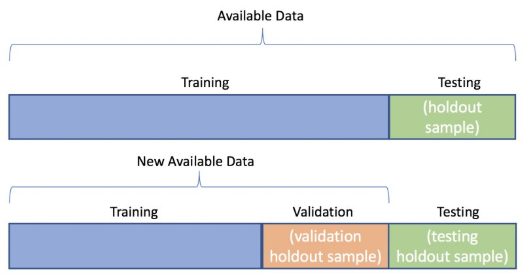
Aké sú najštandardnejšie pomery rozdelenia dát?
train / test
65 / 35
70 / 30
75 / 25
80 / 20
Čo je to a ako funguje coss-validation?
Technika používaná v ML a štatistike na hodnotenie výkonu modelu. Získať presnejšie odhady toho, ako dobre model generalizuje na nevidené dáta, a zároveň efektívne využíva dostupný dataset.
Funguje tak, že rozdelí dáta na časti, nazývané foldy. Následne opakuje raz jeden fold použije na trénovanie a druhý na testovanie. Výsledná premenná sa vypočíta ako priemer týchto foldov.
Čo je to test statistic?
Číslo vypočítané pomocou štatistického testu.
Slúži na kvantifikáciu rozdielu medzi pozorovanými dátami a tým, čo by sme očakávali podľa nulovej hypotézy.
Pomáha rozhodnúť, či zamietneme alebo prijmeme nulovú hypotézu.
Aké sú hlavné predpoklady statistical tests a čo robiť ak ich dáta nespĺňajú?
Dáta sú normálne rozložené
Skupiny, ktoré sa porovnávajú, majú podobnú varianciu
Dáta sú nezávislé
Ak dáta spĺňajú tieto predpoklady, tak treba použiť parametrické štatistické testy.
Ak dáta nespĺňajú tieto predpoklady, tak treba použiť neparametrické štatistické testy, lebo neparametrické testy majú menej predpokladov, ale poskytujú slabšie závery.
Čo je to Frequency Analysis a čo všetko sem patrí?
Frekvenčná analýza sa zameriava na identifikáciu základných štatistických vlastností datasetu.
Pomáha pochopiť, ako sú dáta rozložené, a poskytuje prehľad o ich centrálnych hodnotách, rozptyle a percentiloch.
Patrí sem:
Measures of Central Tendency
Measures of Dispersion
Percentile Values
Ako vyzerá Normal Q-Q Plot, ktorý je light tailed?
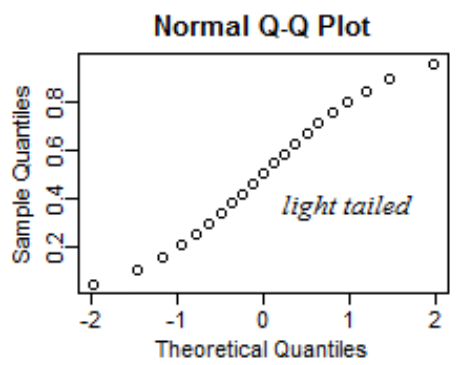
Ako vyzerá Normal Q-Q Plot, ktorý je left skew?
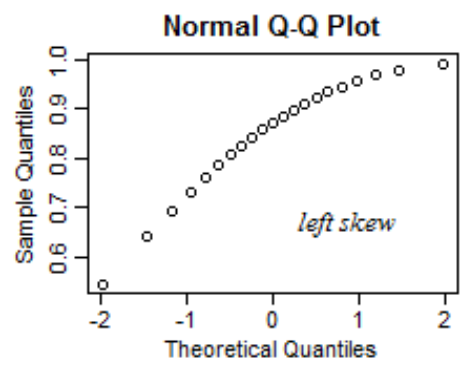
Ako vyzerá Normal Q-Q Plot, ktorý je normal?
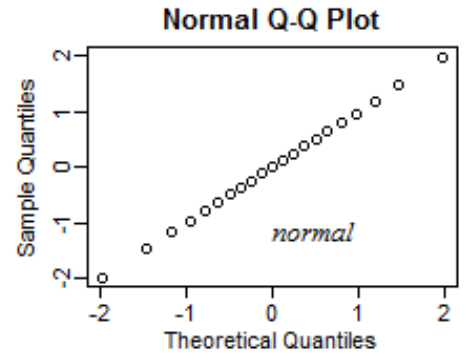
Ako vyzerá Normal Q-Q Plot, ktorý je bimodal?
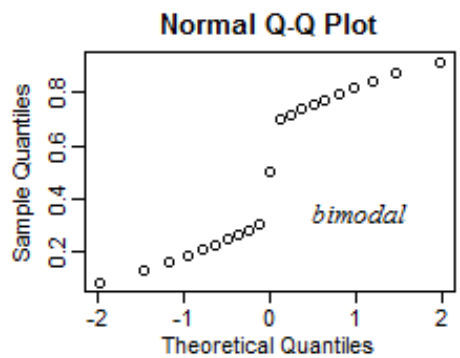
Ako vyzerá Normal Q-Q Plot, ktorý je heavy tailed?
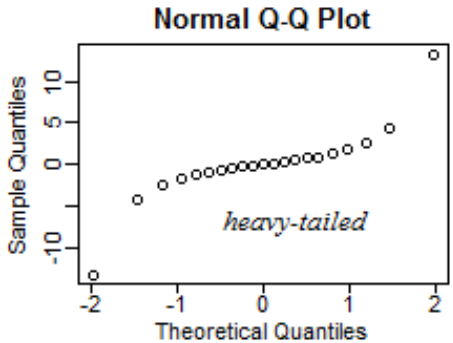
Ako vyzerá Normal Q-Q Plot, ktorý je right skew?
Čo je to a čo určuje Shapiro-Wilk test?
Overuje, či dáta pochádzajú z normálneho (Gaussian) rozdelenia.
Hypotézy:
Nulová hypotéza: Dáta sú normálne rozložené.
Alternatívna hypotéza: Dáta nie sú normálne rozložené.
Ak je p-hodnota:
> 0.05 tak dáta sú normálne rozložené
<= 0.05 tak dáta nepochádzajú z normálneho rozdelenia
Akú má nevýhodu Shapiro-Wilk test?
Pri veľkých vzorkách (n > 5000) sa často odmieta nultá hypotéza, aj keď rozdiely od normálnosti sú malé a prakticky nevýznamné.
Alternatívy pre veľké vzorky:
Anderson-Darling test
Kolmogorov-Smirnov test
Čo je to Levene Test?
Testuje homogenitu variancií medzi skupinami, teda či všetky skupiny majú približne rovnaké variancie.
Homogenita variancií je dôležitým predpokladom mnohých štatistických testov.
Ako sa nazýva equal variances across samples?
homogeneity of variance
Ako si vybrať ktorými testami budem testovať hypotézy?
Podľa typu dát, ak :
sú dáta Gaussian - používajú sa parametrické metódy:
Student's T-test
Analysis of Variance (ANOVA)
nie sú dáta Gaussian - používajú sa neparametrické metódy:
Mann-Whitney U Test
Kruskal-Wallis H Test
Ako rozhodnúť o type dát (či sú alebo nie sú Gaussian)?
Vizualizácia dát:
Histogram, Q-Q graf, boxplot.
Testy normálnosti:
Shapiro-Wilk Test
Kolmogorov-Smirnov Test
Anderson-Darling Test
Aký je rozdiel medzi parametrickými a neparametrickými testami?
Parametrické:
Predpokladajú, že dáta pochádzajú z konkrétneho rozdelenia
Majú prísne požiadavky na dáta, ktoré musia byť splnené, aby boli výsledky spoľahlivé - Citlivé na porušenie predpokladov
Majú vyššiu štatistickú silu, ak sú splnené predpoklady
Vyššia presnosť
Neparametické:
Nevyžadujú konkrétne štatistické rozdelenie dát
Fungujú aj pri nenormálne rozložených dátach alebo nerovnakých varianciách
Majú nižšiu štatistickú silu
Nižšia presnosť
Popíš Student’s T-test / T-test.
Overiť, či existuje štatisticky významný rozdiel medzi priemermi dvoch populácií alebo vzoriek.
Predpoklady:
normal distribution
randomly sampled data from population
homogénne dáta - variancie medzi dvoma skupinami by mali byť rovnaké
Nulová hypotéza: Priemery dvoch populácií sú rovnaké.
Možné výsledky:
Fail to reject H0 - Priemery dvoch skupín nie sú štatisticky rozdielne (p > 0.05)
Reject H0 - Existuje štatisticky významný rozdiel medzi priemermi dvoch skupín (p <= 0.05)
Popíš Analysis of Variance (ANOVA).
Testuje, či sa priemery dvoch alebo viacerých skupín významne líšia.
Rozkladá variabilitu v dátach na:
Between group variability
Within group variability
Predpoklady:
normal distribution
independence - Pozorovania v skupinách musia byť nezávislé
homogénne dáta - variancie medzi dvoma skupinami by mali byť rovnaké
Nulová hypotéza: Priemery všetkých skupín sú rovnaké.
Možné výsledky:
Fail to Reject H0 - Medziskupinové rozdiely sú zanedbateľné, Skupiny majú rovnaké priemery.
Reject H0 - Aspoň jedna skupina má priemer výrazne odlišný od ostatných.
Popíš Mann-Whitney U Test / Wilcoxon rank-sum test.
Testuje, či sú rozdelenia dvoch nezávislých vzoriek rovnaké (napr. mediány).
Predpoklady:
Nezávislé pozorovania - Vzorky musia byť nezávislé od seba.
Veľkosť vzorky - Odporúča sa aspoň 20 pozorovaní v každej vzorke (väčšie vzorky zvyšujú štatistickú silu).
Nulová hypotéza - Medzi rozdeleniami dvoch vzoriek nie je žiadny rozdiel.
Možné výsledky:
Fail to Reject H0 - Distribúcie dvoch vzoriek sú rovnaké.
Reject H0 - Existuje štatisticky významný rozdiel medzi distribúciami dvoch vzoriek.
Popíš Kruskal-Wallis H Test.
Testuje, či rozdelenia viacerých nezávislých vzoriek sú rovnaké.
Predpoklady:
Nezávislé pozorovania - Vzorky musia byť nezávislé od seba.
väčšie vzorky zvyšujú štatistickú silu
Nulová hypotéza - Všetky vzorky pochádzajú z rovnakého rozdelenia.
Možné výsledky:
Fail to Reject H0 - Distribúcie všetkých skupín sú rovnaké.
Reject H0 - Aspoň jedna skupina má odlišné rozdelenie.
Ekvivalencie parametrických a neparametrických testov.
Param <=> Neparam
Student’s T-test <=> Mann-Whitney U test
Analysis of Variance <=> Kruskal-Wallis H test
O čom hovorí nulová hypotéza a alternatívne hypotézy?
H0:
Vždy predpokladá, že v dátach nie je žiadny vzťah, efekt alebo zmena, a slúži ako základ pre testovanie
Ha:
Naopak tvrdí, že v dátach existuje nejaký vzťah, efekt alebo zmena
Vymenuj 4 basic steps of hypothesis testing.
Určenie nulovej a alternatívnej hypotézy
Set a significance level 𝛼 - Hodnota α určuje prah pre rozhodovanie, typicky 0.05 (5 %).
Výpočet p-hodnoty pomocou vhodného testu
Rozhodnutie:
Ak p ≤ α => reject H0 a accept H1. Výsledok je štatisticky významný.
Ak p > α => fail to reject H0 a reject H1. Výsledok nie je štatisticky významný.
Čo robiť, ak α nie je preddefinovaná?
Typicky sa používa α = 0.05, čo znamená, že ak p-hodnota p ≤ 0.05, výsledok sa považuje za štatisticky významný.
Ak neexistuje preddefinovaná hladina významnosti, tak sa takto nastavuje podľa sily podpory:
p > 0.10 - not significant
p <= 0.10 - marginally significant
p <= 0.05 - significant
p <= 0.01 - highly significant
Ako sa nazýva bod na osi x, ktorý oddeľuje α od zvyšku rozdelenia?
Critical values
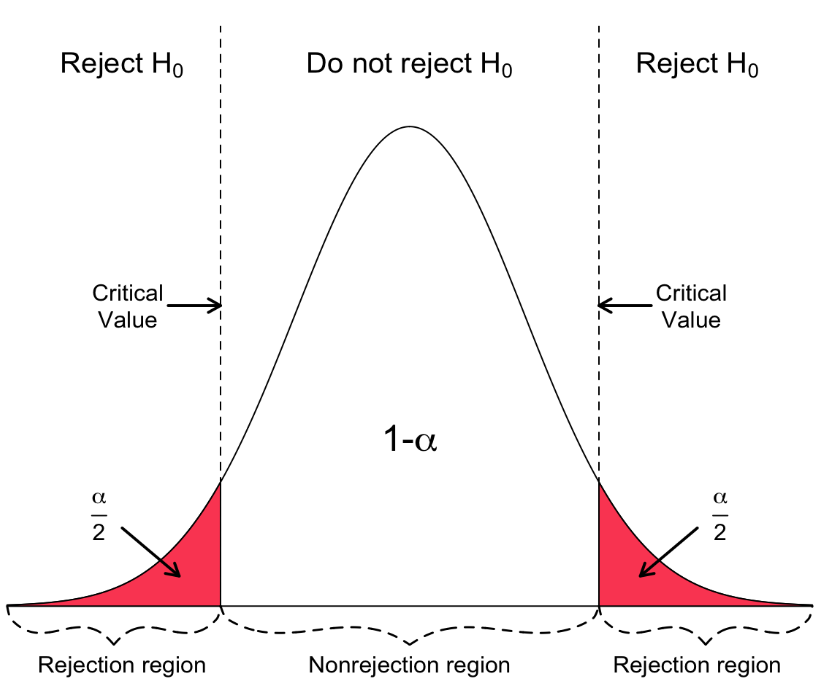
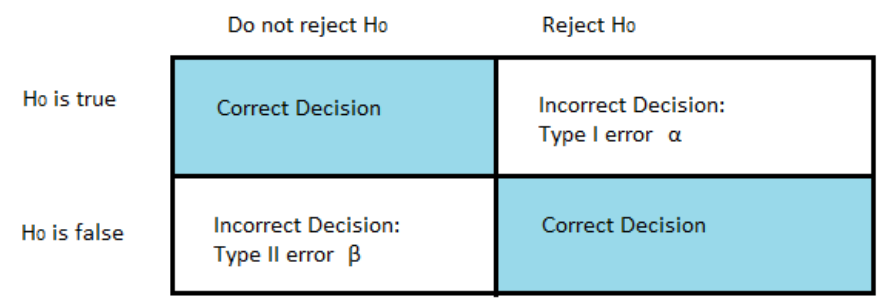
Vymenuj chyby, ktoré môžu nastať pri výsledkoch štatistických testov.
Typ I Error (α):
Chyba, keď odmietneme nulovú hypotézu, hoci je v skutočnosti pravdivá.
Pr. Lekár tvrdí, že pacient je tehotný (pozitívny test), ale pacient v skutočnosti nie je tehotný.
Typ II Error (β):
Chyba, keď neodmietneme nulovú hypotézu, hoci je v skutočnosti nepravdivá.
Pr. Lekár tvrdí, že pacient nie je tehotný (negatívny test), ale pacient je tehotný.
Čo je Degree of freedom (df)?
Defines the number of values in a dataset having the freedom to vary.
Počet hodnôt v štatistickom výpočte, ktoré sú voľné na variáciu.
Počet nezávislých kusov informácií v dátovej vzorke, ktoré môžu byť použité na výpočet štatistiky.
Vzťah k veľkosti vzorky: df ≤ n, kde n je veľkosť vzorky.
Aký má Degree of freedom Single Sample Test?
df = N − 1
Aký má Degree of freedom T-test with two samples?
df = (N1 + N2) − 2
Aký má Degree of freedom Chi-Square Test?
df = (r − 1) × (c − 1)