Errores aleatorios y sistemáticos. Confusión
1/28
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
29 Terms
Introducción
Cuando hacemos un estudio queremos saber:
Es válido?
El estimador puntual se acerca al parámetro real?
Está libre de sesgo?
Es preciso?
Si repito el estudio, obtendría valores parecidos?
Qué tan estrecho es el intervalo de confianza?
Esto nos lleva a los dos grandes enemigos:
Error aleatorio (azar) → afecta a la precisión
Error sistemático (sesgo) → afecta a la validez
Error aleatorio
Los errores aleatorios son inconsistentes
Eso significa:
Que a veces te empujan el estimador hacia arriba
A veces hacia abajo
No tienen dirección fija
Son frutos del azar
No sesgan pero aumentan la variabilidad
Afectan a la precisión
De dónde vienen estos errores?
Del error muestral (selección por muestreo)
Porque trabajamos con una muestra, no con toda la población
Si repites el estudio con otra muestra, obtendrás valores ligeramente distintos.
Esto es normal y esperado
Errores de medida
Por ejemplo:
Dos investigadores miden peso: uno redondea hacia arriba, otro hacia abajo
Un tensiómetro mal calibrado
Variabilidad entre observadores (interobservador)
Variabilidad dentro del mismo observador (intraobservador)
Variabilidad intrasujeto
El mismo individuo puede:
pesar distinto por la mañana y por la tarde
tener glucosa distinta según la hora
tener presión arterial variable
👉 Todo esto introduce ruido, no sesgo
Impacto
El impacto clave es:
Aumenta el ancho del IC
IC amplio → poca precisión
IC estrecho → mucha precisión
El estimador puede ser válido (no sesgado), pero si el IC es enorme, no es útil
Cómo reducir el error
Aumentar el tamaño muestral
Reduce el error estándar
Reduce la variabilidad
Estrecha el IC
Mejora la precisión
Es la estrategia más potente.
Mejorar la eficiencia
Para un mismo tamaño muestral, obtener la máxima información.
Ejemplo clásico:
En ensayos clínicos, la asignación 1:1 es la más eficiente.
Diseños como casos y controles emparejados también mejoran eficiencia.
Entrenamiento del personal
Para que midan igual
Para reducir variabilidad interobservador e intraobservador
Mejorar instrumentos de medida
Equipos calibrados
Métodos estandarizados
Protocolos claros
Ejemplo intuitivo para fijarlo
Imagina que quieres medir la altura media de los estudiantes de tu facultad.
Si mides solo a 10 personas → valores muy variables → IC enorme
Si mides a 500 personas → valores muy estables → IC estrecho
Eso es error aleatorio:
no te está empujando hacia arriba o hacia abajo de forma sistemática, simplemente mete ruido
Errores sistemáticos (sesgos)
QUé son los sesgos?
Errores que tienen dirección fija
No se compensan con el tamaño muestral
Afectan a la VALIDEZ (no a la precisión)
Desvían el estimador del parámetro real de forma sistemática
A diferencia del errores aleatorio, no son ruido, son desviaciones estructurales
Si un estudio tiene sesgo:
Puede ser muy preciso (IC estrecho), pero incorrecto
Ej:
Haces estudio de si fumar causa cáncer de pulmón:
Muestra gigante, tamaño muestral grande → error aleatorio pequeño → IC estrechos
PERO, reclutas sólo a trabajadores de oficina (que suelen fumar menos, tienen mejor acceso a salud, etc) → SESGO DE SELECCIÓN
Esto hace que la población del estudio no represente a la población general
Clasificación de los sesgos
Sesgo de selección
Sesgo de información
Confusión
Sesgo de selección
Cuando ocurre?
Ocurre cuando los individuos incluidos en el estudio no representan a la población objetivo
Cuándo puede aparecer?
En el baseline:
Sesgo del voluntario
Quienes aceptan participar suelen ser más sanos, más motivados, más educados…
Sesgo del trabajador sano
Trabajadores más sanos que la población general
Sesgo de no respuesta
Quienes no responden suelen diferir sistemáticamente
Durante el seguimiento:
Pérdidas de seguimiento (atrtrition bias)
Si los que abandonan difieren en exposición o riesgo, distorsionan el resultado
Resultado: el grupo final no es comparable al que querías estudiar
Sesgo de información
Errores de medición de exposición, resultado o covariables
Incluye:
Sesgo de clasificación (misclassification)
Clasificar mal a expuestos/no expuestos
Clasificar mal a enfermos/no enfermos
Puede ser diferencial o no diferencial
Sesgo de observación
El observador sabe la exposición y mide distinto
Ejemplo: médico que examina más a fondo a expuestos
Sesgo de recuerdo
Muy típico en caso-control
Los casos recuerdan más (o exageran) exposiciones pasadas
Los controles olvidan más
Sesgo de reporte
El participante oculta o modifica información (drogas, alcohol, conductas sexuales, etc)
Resultado → medición no refleja la realidad
Confusión
Tipo especial de error sistemático (no es ni de selección ni de información)
→ lo veremos más adelante
Cuales son los diseños con menos sesgos? Cómo reducimos los sesgos?
Con la aleatorización
El diseño con menos sesgos son los ensayos clínicos aleatorizados
Por qué?
La aleatorización elimina el sesgo de selección
El cegamiento reduce sesgo de información
El seguimiento estricto reduce pérdidas
La asignación oculta evita manipulación
No elimina el error aleatorio, pero minimiza el sistemático
Sesgos típicos según diseño
Transversales
Sesgo del voluntario sano
Sesgo de autorreporte
Falacia de Neyman (sobrevivientes)
No respuesta
Cohortes
Clasificación basal incorrecta
Autorreporte
Sesgo de verificación de outcomes
Pérdidas de seguimiento
Efecto Hawthorne (cambian conducta por ser observados)
Caso control
Sesgo de recuerdo
Sesgo de selección de casos
Sesgo de selección de controles
Sesgo de verificación de exposición
Ensayo clínico
Sesgo de asignación
Sesgo de verificación de outcomes
Pérdidas de seguimiento
Sesgo de adherencia
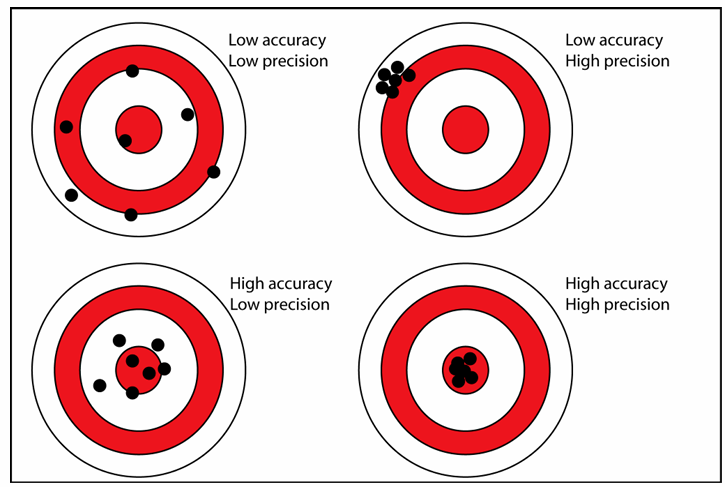
Precisión vs validez
🟦 1. Baja precisión + baja validez
Puntos dispersos y lejos del centro
→ error aleatorio + error sistemático
🟩 2. Alta precisión + baja validez
Puntos agrupados pero lejos del centro
→ sesgo (error sistemático)
→ el estudio es consistente pero incorrecto
🟧 3. Baja precisión + alta validez
Puntos dispersos pero centrados
→ error aleatorio
→ si aumentas tamaño muestral, se arregla
🟥 4. Alta precisión + alta validez
Puntos agrupados en el centro
→ estudio ideal
→ sin sesgo y con poca variabilidad
👉 Esta imagen resume todo el tema:
Error aleatorio = precisión
Error sistemático = validez
Validez
Interna:
Los resultados del estudio son correctos para esa población concreta?
Depende de:
Ausencia de sesgos
Ausencia de confusión
Mediciones correctas
Diseño adecuado
Si no hay validez interna, no hay nada que generalizar
Externa:
Puedo aplicar estos resultados a otras poblaciones?
Depende de:
Si la población del estudio se parece a la población diana
Si el contexto clínico es comparable
Si la intervención es aplicable fuera del estudio
Es más abstracta, menos cuantificable
No siempre interesa (ensayos explicativos vs pragmáticos)
La validez interna es necesaria para la validez externa
Confusión
Es el gran sesgo conceptual
Es un error sistemático, pero no es selección ni información
Es un problema de:
Diseño y análisis
La definición:
Asociación observada entre exposición y resultado está distorsionada porque una tercera variable está relacionada con ambos
Imagen:
Alcohol → infarto
Tabaco → asociado a alcohol y a infarto
Tabaco es un confusor
los que beben más también fuman más
Y el tabaco sí causa infarto
→ La asociación alcohol–infarto está inflada por el tabaco
Requisitos de un factor de confusión
Está asociado al resultado
Debe aumentar o disminuir el riesgo de outcome
Está asociado a la exposición
Debe estar distribuido de forma desigual entre expuestos y no expuestos
No es un mediador
No está en la cadena causal entre exposición → outcome
Si está en la cadena causal, es un mediador, no un confusor
Ejemplo del tabaco:
Tabaco → aumenta mortalidad (criterio 1)
Tabaco → más frecuente entre quienes toman café (criterio 2)
No está en la cadena café → tabaco → mortalidad (criterio 3)
→ Tabaco es confusor
En este caso, un mediador podría ser hipertensión arterial, ya que el alcohol puede aumentar la presión arterial, que aumenta el riesgo de infarto (por lo tanto, está en la cadena causal)
Un confusor es una variable que “explica” parte de la asociación que tú crees que existe
¡CUIDADO! ¡ESTO ES DISEÑO!
Porque la confusión se controla:
antes del análisis
durante el diseño del estudio
Con:
aleatorización
restricción
emparejamiento
estratificación
medición adecuada de covariables
👉 Si no mides el confusor, no puedes ajustarlo después

DAGS
Sirven para:
Visualizar relaciones causales
Identificar confusores (es decir, que variables pueden confuncir)
Distinguir confusores de mediadores
Evitar ajustar por variables que no debes (colliders)
Si una variable apunta a exposición y outcome → sospecha de confusión
Si está en la cadena causal → mediador
Si es un collider → NO se ajusta
Los DAGs básicamente te dicen qué ajustar y qué no
El tabaco es un confusor porque:
afecta al alcohol (exposición)
afecta al infarto (outcome)
no está en la cadena causal alcohol → infarto
¿Cómo se identifican los posibles factores de confusión?
en fase de diseño:
Creación de gráficos acíclicos dirigidos (DAG) teniendo en cuenta la experiencia y la evidencia clínica
Control de la confusión en fases de diseño?
Tenemos 3 herramientas clásicas:
Aleatorización
Solo es posible en estudios de intervención (por eso en los estudios observacionales tenemos que prestar más atención en la fase de análisis con los factores de confusión)
Distribuye confusores conocidos y desconocidos
Hace comparables los grupos
Es la forma más potente de eliminar confusión
Restricción
Incluir como criterio de selección para nuestro estudio una categoría de la variable de confusión (si es cualitativa) o rangos no muy amplios (si es cuantitativa) de manera que no haya desequilibrio entre los grupos comparados
Ejemplo:
Solo incluir no fumadores en un estudio alcohol → infarto.
Ventajas:
Elimina la confusión por tabaco
Limitaciones:
Reduce población elegible
No puedes estudiar el efecto del tabaco
Puede quedar confusión residual si el rango es amplio
Confusión residual → Incluso después de controlar los factores de confusión, aún puede haber confusión porque no se tuvieron en cuenta algunos factores de confusión, porque el control no fue bueno, etc.
Emparejamiento - Matching
Muy usado en caso-control y cohortes retrospectivas
Consiste en emparejar a un individuo expuesto con uno o más individuos no expuestos respecto a posibles variables de confusión
Ejemplo:
Por cada caso de 60 años, eliges un control de 60 años (igualas sexo, edad, etc)
Limitaciones:
Reduce tamaño elegible
No puedes estudiar la variable por la que emparejas
Puede haber confusión residual
Control de la confusión en fases de análisis.
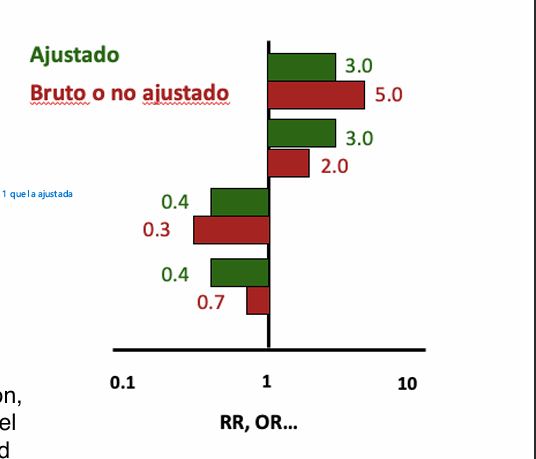
Si el tamaño del efecto bruto es “diferente” de la medida ajustada
Diferente quiere decir >10-20% → mirar imagen!
Cuando haces un estudio, primero calculas la asociación cruda (OR crudo, RR crudo, coeficiente crudo)
→ ese valor incluye todo
La asociación real + la distorsión por los confusores
Luego ajustas por posibles confusores (edad, sexo, tabaco, etc.) y obtienes:
OR ajustado
RR ajustado
👉 Si el crudo y el ajustado son muy diferentes, significa que había confusión
Tenemos dos herramientas para controlar la confusión en la fase de análisis (secuenciales y complementarias)
Estratificación
Divides la muestra en estratos según el confusor.
Ejemplo:
Fumadores
No fumadores
Y calculas el efecto en cada estrato.
Si los OR/RR cambian respecto al crudo → hay confusión.
Limitaciones:
Si hay muchos confusores → demasiadas tablas
Se pierde potencia
Celdas pequeñas → estimaciones inestables
Ajuste multivariable (regresión)
Es lo que se usa en la práctica real.
Ajustas por edad, sexo, tabaco, etc.
Obtienes un estimador ajustado
Regla para detectar confusión (imagen)

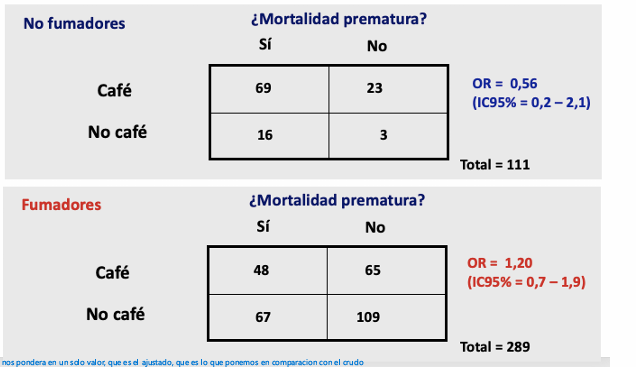
Ejemplo estratificación
Pregunta de investigación: ¿El consumo de café está asociado con la mortalidad?
→ Nos sale que OR = 1.80 (IC 95%: 1,2-2,7)
→ parece que sí que está asociado con la mortalidad, pero puede haber factores de confusión, por ejemplo el consumo de tabaco → hacemos otra tabla de contingencia igual, tanto en fumadores como en no fumadores (imagen)
Estratificas:
No fumadores
OR = 0.56 (no significativo)
Fumadores
OR = 1.20 (no significativo)
Luego haces el OR ajustado (Mantel-Haenszel):
OR ajustado = 1.1
OR crudo = 1.8
Diferencia enorme → hay confusión.
👉 El tabaco inflaba la asociación café → mortalidad.
👉 Conclusión: el café NO está asociado a mortalidad.
La asociación cruda era falsa por confusión
Confusión residual
Incluso después de ajustar:
Puede quedar confusión por variables no medidas
O mal medidas
O por rangos amplios en la restricción
O por mala calidad del ajuste
👉 Siempre existe un poco de confusión residual
Resumen
Confusor = variable asociada a exposición y outcome, no mediador
Se identifica con DAGs y lógica causal
Se controla en diseño: aleatorización, restricción, matching
Se controla en análisis: estratificación, ajuste multivariable
Si el estimador crudo y ajustado difieren >10–20% → hay confusión
El ejemplo del café muestra confusión por tabaco
Cochran–Mantel–Haenszel (CMH)
Permiten el cálculo de una estimación ponderada de las medidas de asociación obtenidas en los estratos de las posibles variables confusoras
Es una estimación ponderada porque
Porque no todos los estratos tienen el mismo tamaño.
No es lo mismo un estrato con 300 personas que uno con 30.
CMH da más peso a los estratos grandes y menos a los pequeños
Qué hace?
Toma los OR/RR de cada estrato (por ejemplo fumadores y no fumadores), los combina de forma ponderada y te da un único valor ajustado
Ese valor es el OR ajustado o RR ajustado.
Y lo que tú interpretas es:
¿El ajustado se parece al crudo?
→ No había confusión¿El ajustado es muy distinto del crudo?
→ Había confusión
Eso es todo
Interpretación:
Lo que interpretamos es si el riesgo relativo se aproxima mucho o poco al ajustado
Es decir:
OR crudo → lo que parece a primera vista
OR ajustado (CMH) → lo que queda después de quitar la confusión
Si el crudo y el ajustado son muy diferentes → confusión

Por qué usamos CMH y no solo mirar estratos?
Porque:
Mirar estratos te dice si hay confusión
Pero CMH te da un único número ajustado
Ese número es el que comparas con el crudo
Y es el que reportas en el estudio
Es la forma clásica de ajustar por un confusor categórico
Confusión positiva vs negativa
Confusión positiva (sobreestimación)
La medida cruda está más alejada de 1 que la ajustada
Es decir:
El efecto crudo parece más fuerte (es decir, más lejos del uno)
El efecto ajustado es más débil o incluso desaparece
👉 La confusión exagera la asociación.
Ejemplo:
OR crudo = 2.5
OR ajustado = 1.3
El crudo está más lejos de 1 → sobreestimación (parecía un efecto enorme, pero como que el ajustado está más cerca del 1, el efecto real es más débil)
Esto fue EXACTAMENTE lo que pasó en el ejemplo del café:
OR crudo = 1.8
OR ajustado = 1.1
→ Confusión positiva por tabaco
Confusión negativa (subestimación)
La medida cruda está más cerca de 1 que la ajustada
Es decir:
El efecto crudo parece más débil
El efecto ajustado es más fuerte
👉 La confusión oculta parte de la asociación real.
Ejemplo:
RR crudo = 1.2
RR ajustado = 2.0
El crudo está más cerca de 1 → subestimación (parecía que no había efecto, pero tenemos un efecto real fuerte)
Cuanto más lejos está el RR/OR de 1, mayor es la diferencia entre los grupos comparados
Y esa diferencia puede ser:
un aumento del riesgo (si es >1)
una disminución del riesgo (si es <1)
Pero cuanto más lejos de 1, más grande es el efecto
Que el efecto sea fuerte significa que hay mayor diferencia entre expuestos y no expuestos, y que hay mayor impacto de la exposición en el outcome, además de mayor efecto real
Entonces:
Más fuerte = más impacto
Efectos agregados a todos los confusores
En la vida real, no hay un solo confusor.
Hay muchos:edad
sexo
tabaco
dieta
ejercicio
nivel socioeconómico
comorbilidades
Cada uno puede:
empujar el efecto hacia arriba
empujarlo hacia abajo
El resultado final (positivo o negativo) depende de la suma de todos ello
La estratificación es suficiente para ajustar confusores?
NO
porque si ajustas por dos confusores, necesitas 4 tablas de contingencia. Si ajustas por tres, necesitas ocho tablas, y así sucesivamente (2x)
→ esto tiene un nombre:
Explosión de estratos
Problemas:
Demasiadas tablas
Celdas con números pequeños
Pérdida de potencia
Imposible de manejar con muchos confusores
Por eso la estratificación es útil para detectar confusión, pero no para controlarla cuando hay muchas variables
Qué hacemos entonces?
→ hacemos modelos de regresión
En estudios observacionales, SIEMPRE necesitas modelos de regresión para controlar confusores.
Porque:
puedes ajustar por muchas variables a la vez
no pierdes potencia
no necesitas estratos
obtienes un único estimador ajustado
puedes incluir variables continuas (edad, IMC, etc)
Ecuación para estimar la relación entre:
Dependiente o resultado (y)
independientes o predictoras (x)
Tipos de modelos según la variable dependiente
Tipo de regresión | Variable Dependiente | Ejemplo |
Lineal | Cuantitativa (estima diferencia media) | IMC, presión arterial |
Logística | Categórica (sí/no) (estima ORa) | Infarto sí/no |
Poisson | Conteos (núm- de veces que ocurre algo), estimas RRa | Número de crisis asmáticas |
Cox | Tiempo hasta evento | Supervivencia (tiempo hasta infarto, hasta muerte…) |
Tipos de modelos según la variable independiente
Univariable → sólo exposición
Multivariable → exposición + confusores
En epidemiología, casi siempre usamos multivariable
Para evitar confusión
Collider
Un collider es una variable que:
recibe flechas de dos variables
no causa la exposición ni el outcome
no es un confusor
NO debe ajustarse
Qué pasa si ajustas por un collider?
Creas una asociación falsa entre alcohol y hepatitis C, aunque no exista en la realidad.
Esto se llama collider bias o sesgo de selección.
Ejemplo intuitivo:
Si seleccionas solo personas con cáncer de hígado:
muchos tienen hepatitis C
muchos beben alcohol
pero dentro de ese grupo, parece que “si no tienes hepatitis C, entonces seguro bebes alcohol”
y viceversa👉 Ajustar por un collider crea una relación que no existe
Mediador
Un mediador:
es causado por la exposición
causa el outcome
explica parte del efecto real
NO debe ajustarse si quieres estimar el efecto total
Qué pasa si ajustas por un mediador?
Rompes la cadena causal.
Ejemplo:
Si ajustas por colesterol, estás diciendo:
“Quiero saber el efecto de la comida rápida en el infarto, pero quitando el efecto que pasa por el colesterol.”
Eso elimina parte del efecto real.
👉 Ajustar por un mediador subestima el efecto total
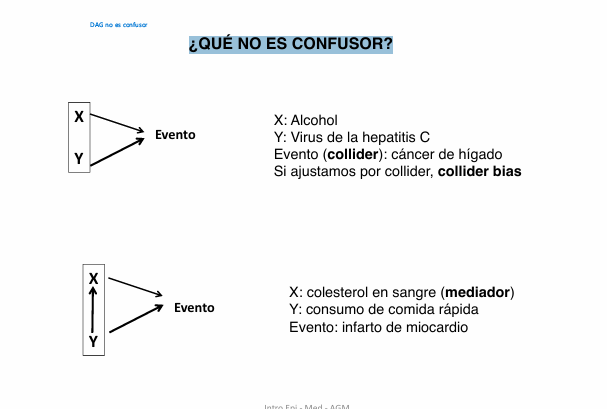
Entonces qué es y que no es confusor?
Entonces, ¿qué NO es un confusor?
Un collider
Recibe flechas
Ajustarlo crea sesgo
Ejemplo: cáncer de hígado en el DAG de arriba
Un mediador
Está en la cadena causal
Ajustarlo elimina parte del efecto real
Ejemplo: colesterol en el DAG de abajo
🎯 ¿Qué SÍ es un confusor?
Una variable que:
Afecta a la exposición
Afecta al outcome
No está en la cadena causal
No es un collider
Ejemplo clásico: tabaco en la relación alcohol → infarto.
No es confusor aquello que está en medio de la cadena causal (mediador) ni aquello que recibe flechas de exposición y outcome (collider). Ajustarlos introduce sesgo
Qué no es confusor?
La imagen te muestra dos casos clásicos:
Un collider (arriba)
Un mediador (abajo)
Ninguno de los dos debe ajustarse cuando estudias la relación entre exposición y outcome
A. Primer DAG: el COLLIDER (arriba)
🔎 ¿Qué muestra el DAG?
Alcohol →
↓
Cáncer de hígado
↑Hepatitis C →
El cáncer de hígado recibe flechas de alcohol y de hepatitis C.
👉 Eso lo convierte en un COLLIDER
🟩 B. Segundo DAG: el MEDIADOR (abajo)
🔎 ¿Qué muestra el DAG?
Comida rápida →
↓
Colesterol
↓
Infarto
Aquí, el colesterol está en medio de la cadena causal.
👉 Eso lo convierte en un MEDIADOR