CAP4612 - Exam 1 Question Bank
5.0(1)
Studied by 6 peopleCard Sorting
1/187
Earn XP
Description and Tags
Last updated 1:33 PM on 2/28/23
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
188 Terms
1
New cards
univariate univariable regression
* 1 outcome and 1 explanatory variable
* often used as the introductory
* often used as the introductory
2
New cards
multivariate multivariable regression
multiple outcomes and multiple explanatory variable
3
New cards
multivariate univariable regression
multiple outcomes and single explanatory
4
New cards
multiple regression/multi-variable regression
Suppose you want to perform regression on an:
* independent variable X1, …, XmX1, …, Xm
* dependent variable Y1, …, YnY1, …, Yn
When m>1, it’s called __________________________.
* independent variable X1, …, XmX1, …, Xm
* dependent variable Y1, …, YnY1, …, Yn
When m>1, it’s called __________________________.
5
New cards
multi-variate regression
Suppose you want to perform regression on an:
* independent variable X1, …, XmX1, …, Xm
* dependent variable Y1, …, YnY1, …, Yn
When n>1, it’s called __________________________.
* independent variable X1, …, XmX1, …, Xm
* dependent variable Y1, …, YnY1, …, Yn
When n>1, it’s called __________________________.
6
New cards
b.) 1 feature to predict the outcome
A univariable regression uses:
a.) 2 features to predict the outcome
b.) 1 feature to predict the outcome
c.) 1 feature in its dataset
d.) At least 2 features in its dataset
a.) 2 features to predict the outcome
b.) 1 feature to predict the outcome
c.) 1 feature in its dataset
d.) At least 2 features in its dataset
7
New cards
c.) root square mean error (RMSE)
A performance measure for regression is:
a.) recall
b.) precision
c.) root mean square error (RMSE)
d.) F1-score
a.) recall
b.) precision
c.) root mean square error (RMSE)
d.) F1-score
8
New cards
b
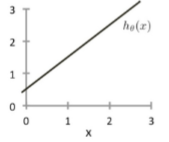
(One-variable regression) Consider the plot below corresponding to h∅(x) = ∅0 + ∅1x. What are ∅0 and ∅1?
a.) ∅0 = 0, ∅1 = 1
b.) ∅0 = 0.5, ∅1 = 1
c.) ∅0 = 1, ∅1 = 0.5
d.) ∅0 = 1, ∅1 = 1
a.) ∅0 = 0, ∅1 = 1
b.) ∅0 = 0.5, ∅1 = 1
c.) ∅0 = 1, ∅1 = 0.5
d.) ∅0 = 1, ∅1 = 1
9
New cards
b.) error
Root Mean Square Error (RMSE) is a measure of how much ________ the system typically makes in its predictions.
a.) confidence
b.) error
c.) bias
d.) variance
a.) confidence
b.) error
c.) bias
d.) variance
10
New cards
c.) outliers
Mean Absolute Error is a preferred performance measure for data with many:
a.) instances
b.) features
c.) outliers
d.) classes
a.) instances
b.) features
c.) outliers
d.) classes
11
New cards
performance measure
two types of _________ _________:
1\.) utility/fitness function
2\.) cost function
1\.) utility/fitness function
2\.) cost function
12
New cards
utility/fitness function
measures how good your model is
13
New cards
cost function
measures how bad your model is
14
New cards
normalization/min-max
During the ________________ feature scaling techniques, values are shifted and rescaled so that they end up ranging from 0 to 1.
15
New cards
standardization
During ____________ feature scaling, we subtract the mean value and then it divides by the standard deviation so that the resulting distribution has unit variance.
16
New cards
c.) x_i = (age of house - 10)/25
If you are using a learning algorithm to estimate the price of houses in a city, you may want one of your features x_i to capture age of the houses. In your training set, all the houses have an age between 10 to 35 with an average of 17. Which of the following would you use as features if you use normalization for feature scaling:
a.) x_i = age of house
b.) x_i = (age of house)/35
c.) x_i = (age of house - 10)/25
d.) x_i = (age of house - 17)/25
a.) x_i = age of house
b.) x_i = (age of house)/35
c.) x_i = (age of house - 10)/25
d.) x_i = (age of house - 17)/25
17
New cards
main challenges
____ ___________ of ML:
1\.) insufficient quantity of training data
2\.) nonrepresentative training data
3\.) poor-quality data
4\.) irrelevant features
5\.) overfitting the training data
6\.) underfitting the training data
1\.) insufficient quantity of training data
2\.) nonrepresentative training data
3\.) poor-quality data
4\.) irrelevant features
5\.) overfitting the training data
6\.) underfitting the training data
18
New cards
insufficient quantity of training data
* amount of training data is very important
* different ML algorithms perform almost identically well on a complex problem when given enough data (Banko and Brill)
* different ML algorithms perform almost identically well on a complex problem when given enough data (Banko and Brill)
19
New cards
nonrepresentative training data
* training data should be representative of new cases you want to generalize to
* add missing data to make model more representative of reality → model parameters changed
* sampling noise and sampling bias can occur
* add missing data to make model more representative of reality → model parameters changed
* sampling noise and sampling bias can occur
20
New cards
sampling bias
sample is too small
21
New cards
sampling bias
very large samples can be nonrepresentative is sampling method is flawed
22
New cards
poor-quality data
* if training data is full of errors, outliers, and noise → it’s harder for the system to detect underlying patterns
* need to clean up training data if instances are clearly outliers or missing a few features
* need to clean up training data if instances are clearly outliers or missing a few features
23
New cards
instances are clearly outliers
solution: discard them or try to fix errors manually
24
New cards
instances are missing a few features
solutions:
* ignore attribute altogether
* ignore these instances
* fill in missing values (with median age)
* train 1 model with the feature and 1 without
* ignore attribute altogether
* ignore these instances
* fill in missing values (with median age)
* train 1 model with the feature and 1 without
25
New cards
irrelevant features
* system is only capable of learning if the training data contains enough relevant features and not too many irrelevant ones
* feature engineering
* feature engineering
26
New cards
feature engineering
* process of coming up with a good set of features to train on
* includes:
* feature selection
* feature extraction
* creating new features by fathering new data
* includes:
* feature selection
* feature extraction
* creating new features by fathering new data
27
New cards
feature selection
selecting the most useful features to train on among existing features
28
New cards
feature extraction
combining existing features to produce a more useful one
29
New cards
overfitting the training data
* overfitting: the model performs well on training data but doesn’t generalize well
* solutions:
* simplify the model by selecting one with fewer parameters → reducing number of attributes in training data, constrain the model with regularization
* gather more training data
* reduce noise in the training data → fix data errors and remove outliers
* solutions:
* simplify the model by selecting one with fewer parameters → reducing number of attributes in training data, constrain the model with regularization
* gather more training data
* reduce noise in the training data → fix data errors and remove outliers
30
New cards
regularization
* constraining a model to make it simpler and reduce the risk of overfitting
* amount of regularization to apply during learning can be controlled by hyperparameters
* amount of regularization to apply during learning can be controlled by hyperparameters
31
New cards
hyperparameter
* parameter of learning algorithm (not model) that can’t be figured out during training process
* configuration that’s external to model and whose value can’t be estimated from data
* configuration that’s external to model and whose value can’t be estimated from data
32
New cards
hyperparameter properties
* often specified by practitioner by experience
* often set using heuristics and rule of thumb
* often best value is searched by trail and error
* often tuned for a given predictive modeling problem
* often set using heuristics and rule of thumb
* often best value is searched by trail and error
* often tuned for a given predictive modeling problem
33
New cards
underfitting the training data
* underfitting: model is too simple to learn the underlying structure of the data
* solutions:
* select a more powerful model with more parameters (increase complexity)
* feature engineering → feed better features to the learning algorithm
* reduce constraints on the model → reduce regularization hyperparameter
* solutions:
* select a more powerful model with more parameters (increase complexity)
* feature engineering → feed better features to the learning algorithm
* reduce constraints on the model → reduce regularization hyperparameter
34
New cards
main steps
_____ _____ in an ML project:
1\.) frame the problem and look at the big picture
2\.) get the data
3\.) discover and visualize the data to gain insights
4\.) prepare the data to better expose the underlying data patterns to ML algorithms
5\.) explore many different models and shortlist the best ones (select a model and train it)
6\.) fine-tune your models and combine them into a great solution
7\.) present your solution
8\.) launch, monitor, and maintain your system
1\.) frame the problem and look at the big picture
2\.) get the data
3\.) discover and visualize the data to gain insights
4\.) prepare the data to better expose the underlying data patterns to ML algorithms
5\.) explore many different models and shortlist the best ones (select a model and train it)
6\.) fine-tune your models and combine them into a great solution
7\.) present your solution
8\.) launch, monitor, and maintain your system
35
New cards
exploring data
different sub tasks while _________ ______:
1\.) Create copy of the data for exploration (sampling it down to manageable size if necessary)
2\.) Create a Jupyter notebook to keep a record of data exploration
3\.) Study each attribute and its characteristics
4\.) For supervised learning tasks, identify the target attribute
5\.) Visualize the data
6\.) Study the correlations between attributes
7\.) Study how you would solve the problem manually
8\.) Identify the promising transformations you may to apply
9\.) Identify extra data that would be useful
10\.) Document what you have learned
1\.) Create copy of the data for exploration (sampling it down to manageable size if necessary)
2\.) Create a Jupyter notebook to keep a record of data exploration
3\.) Study each attribute and its characteristics
4\.) For supervised learning tasks, identify the target attribute
5\.) Visualize the data
6\.) Study the correlations between attributes
7\.) Study how you would solve the problem manually
8\.) Identify the promising transformations you may to apply
9\.) Identify extra data that would be useful
10\.) Document what you have learned
36
New cards
attribute characteristics
* name
* type (categorical, int/float, bounded/unbounded, text, structured, etc.)
* percent of missing values
* noisiness and type of noise (stochastic, outliers, rounding errors, etc.)
* usefulness for the task
* type of distribution (Gaussian, uniform, logarithmic, etc)
* type (categorical, int/float, bounded/unbounded, text, structured, etc.)
* percent of missing values
* noisiness and type of noise (stochastic, outliers, rounding errors, etc.)
* usefulness for the task
* type of distribution (Gaussian, uniform, logarithmic, etc)
37
New cards
data preparation
sub tasks of _____ __________ step:
1\.) data cleaning
2\.) feature selection (optional)
3\.) feature engineering (when appropriate)
4\.) feature scaling
1\.) data cleaning
2\.) feature selection (optional)
3\.) feature engineering (when appropriate)
4\.) feature scaling
38
New cards
data cleaning
* fix or remove outliers (optional)
* fill in the missing values (with zero, mean, median) or drop their rows/columns
* fill in the missing values (with zero, mean, median) or drop their rows/columns
39
New cards
feature selection
drop the attributes that provide no useful info for the task
40
New cards
feature engineering
* discretize continuous feature
* decompose features (ex: categorical, date/time,etc)
* add promising transformations of features (ex: log(x), sqrt(x), x2, etc)
* aggregate features into promising new features
* decompose features (ex: categorical, date/time,etc)
* add promising transformations of features (ex: log(x), sqrt(x), x2, etc)
* aggregate features into promising new features
41
New cards
feature scaling
standardize or normalize features
42
New cards
promising models
sub tasks of shortlisting __________ _______:
1\.) Train many quick-and-dirty models from different categories (linear, naive Bayes, SVM, random forest, neural net) using standard parameters
2\.) Measure and compare their performance → for each model use N-fold cross validation, compute the mean and standard deviation of performance measure on the N folds
3\.) Analyze the most significant variables for each algorithm
4\.) Analyze the types of errors the models make
5\.) Perform a quick round of feature selection and engineering
6\.) Perform 1 or 2 more quick iterations of last 5 steps
7\.) Shortlist the top 3-5 most promising models, preferring models that make diff types of errors
1\.) Train many quick-and-dirty models from different categories (linear, naive Bayes, SVM, random forest, neural net) using standard parameters
2\.) Measure and compare their performance → for each model use N-fold cross validation, compute the mean and standard deviation of performance measure on the N folds
3\.) Analyze the most significant variables for each algorithm
4\.) Analyze the types of errors the models make
5\.) Perform a quick round of feature selection and engineering
6\.) Perform 1 or 2 more quick iterations of last 5 steps
7\.) Shortlist the top 3-5 most promising models, preferring models that make diff types of errors
43
New cards
data snooping bias
To avoid ______ _____________ _____, we should not look at the test set. If we look, we may see an interesting pattern in the test data that leads you to select a particular kind of ML model. Since your model will perform well on the test set because of this selection, you might get an unexpected generalization error.
44
New cards
generalization
To avoid data snooping bias , we should not look at the test set. If we look, we may see an interesting pattern in the test data that leads you to select a particular kind of ML model. Since your model will perform well on the test set because of this selection, you might get an unexpected ____________ error.
45
New cards
stratified sampling
We perform ________________ to guarantee that the test set is representative of the overall population. During this sampling, the population is divided into homogeneous subgroups called strata, and the right number of instances are sampled from each stratum.
46
New cards
strata
We perform stratified sampling to guarantee that the test set is representative of the overall population. During this sampling, the population is divided into homogeneous subgroups called ______, and the right number of instances are sampled from each stratum.
47
New cards
stratum
We perform stratified sampling to guarantee that the test set is representative of the overall population. During this sampling, the population is divided into homogeneous subgroups called strata, and the right number of instances are sampled from each ______.
48
New cards
d.) All of the above
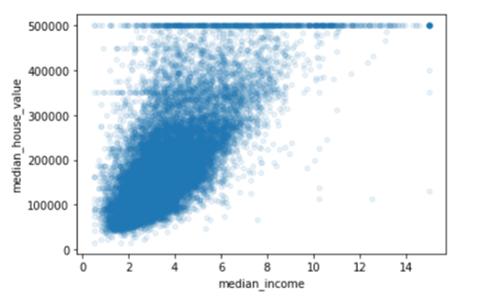
When we draw a scatter plot between house value and income, we notice the correlation between the two attributes as seen in the figure. Which of the followings can be learned about the data from the figure below?
a.) The correlation is indeed strong
b.) The price cap that we noticed earlier is clearly visible as a horizontal line at $500,000.
c.) The plot reveals other less obvious straight lines: a horizontal line around $450,000, another around $350,000
d.) All of the above
a.) The correlation is indeed strong
b.) The price cap that we noticed earlier is clearly visible as a horizontal line at $500,000.
c.) The plot reveals other less obvious straight lines: a horizontal line around $450,000, another around $350,000
d.) All of the above
49
New cards
none
Which of these are not one of the feature engineering steps?
a.) Discretize continuous features
b.) Decompose features (ex: categorical, date/time, etc.)
c.) Add promising transformations of features (ex: log(x), sqrt(x), x2, etc)
d.) Aggregate features into promising new features
a.) Discretize continuous features
b.) Decompose features (ex: categorical, date/time, etc.)
c.) Add promising transformations of features (ex: log(x), sqrt(x), x2, etc)
d.) Aggregate features into promising new features
50
New cards
toy data set
* provided in scikit-learn library
* small data set used to quickly illustrate the behavior of the various algorithms implemented in scikit-learn
* small data set used to quickly illustrate the behavior of the various algorithms implemented in scikit-learn
51
New cards
load_data_set_name
a method used to load a toy data set in scikit-learn
52
New cards
false positives
If you are creating a classifier to filter bad videos for kids (4-6 years) and your classifier predicts the bad videos. Would you willing to tolerate high number of false positive or high false negatives?
53
New cards
multiclass/multinomial classifier
classifier that distinguishes between more than 2 classes
54
New cards
multiclass classification
Strategies to perform __________________ using binary classifiers:
1\.) One-versus-the-Rest (OvR)
2\.) One-versus-One (OvO)
1\.) One-versus-the-Rest (OvR)
2\.) One-versus-One (OvO)
55
New cards
one-versus-the-rest (OVR)
* AKA one-versus-all
* get the decision score from each classifier for that image and select the class whose classifier outputs the highest score
* get the decision score from each classifier for that image and select the class whose classifier outputs the highest score
56
New cards
one-versus-one (OVO)
* train a binary classifier for every pair of binary classifier → one to distinguish 0s and 1s, another to distinguish 0s to 2s, another for 1s and 2s, etc
* If there are N classes, you need to train N \* (N-1)/2 classifiers
* If there are N classes, you need to train N \* (N-1)/2 classifiers
57
New cards
26
We would like to use binary classifiers to detect a letter from the alphabet. We use OvR strategy, how many binary classes do we need to train?
58
New cards
(26\*25)/2
We would like to use binary classifiers to detect a letter from the alphabet. We use OvO strategy, how many binary classes do we need to train?
59
New cards
k
You have a multi-class classification problem with k classes, using one-vs-rest method, how many different logistic regression classifiers will you end up training?
60
New cards
a, b, c
Select the multiclass classification:
a.) Assigning a tag to an email from one of the following: Promotion, Social, Primary
b.) Assigning a patent one of these: not ill, cold, flu
c.) Assigning the weather as one of these: sunny, rain, snow, cloudy
d.) Analyzing a picture and assigning both young/old and male/female options
a.) Assigning a tag to an email from one of the following: Promotion, Social, Primary
b.) Assigning a patent one of these: not ill, cold, flu
c.) Assigning the weather as one of these: sunny, rain, snow, cloudy
d.) Analyzing a picture and assigning both young/old and male/female options
61
New cards
multiple binary tags
A classification system that outputs __________ __________ _____ is called a multilabel classification system.
62
New cards
multioutput-multiclass classification
* AKA multioutput classification
* a generalization of multilabel classification where each label can be multiclass (can have more than 2 possible values)
* a generalization of multilabel classification where each label can be multiclass (can have more than 2 possible values)
63
New cards
classifications
types of _____________:
1\.) binary
2\.) multiclass
3\.) multilabel
4\.) multioutput
1\.) binary
2\.) multiclass
3\.) multilabel
4\.) multioutput
64
New cards
binary classification
ex: digit is 5 or not
65
New cards
multiclass classification
* AKA multinomial
* ex: digit is 0, 1, …, 9
* ex: digit is 0, 1, …, 9
66
New cards
multilabel classification
* AKA multiple binary
* ex: odd or not, greater than 5 or not
* ex: odd or not, greater than 5 or not
67
New cards
multioutput classification
* AKA multiple multiclass
* ex: 28x28 labels for each image and each label value is 1 to 256
* ex: 28x28 labels for each image and each label value is 1 to 256
68
New cards
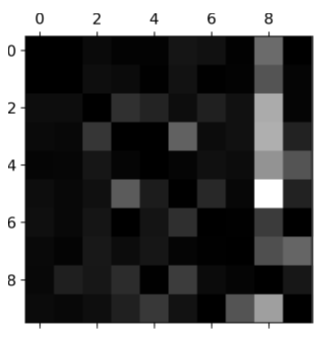
False
For the below error matrix, columns show the predictions and rows show the actual values.
(T/F) The column for class 8 is quite bright, which tells you that many images get correctly classified as 8s.
(T/F) The column for class 8 is quite bright, which tells you that many images get correctly classified as 8s.
69
New cards
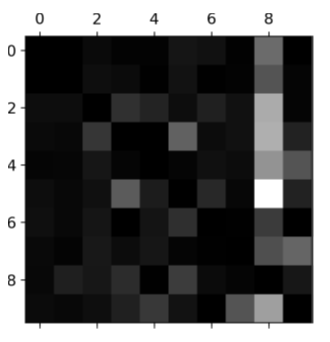
true
For the below error matrix, columns show the predictions and rows show the actual values.
(T/F) The row for class 8 is not that bad, telling you that actual 8s in general get properly classified as 8s.
(T/F) The row for class 8 is not that bad, telling you that actual 8s in general get properly classified as 8s.
70
New cards
d.) all of the above
What can we do to fix a large column of errors in an error matrix?
a.) more training data for digits that look like 8s
b.) engineer more features to help the classifier
c.) process images to make some patterns stand out more
d.) all of the above
a.) more training data for digits that look like 8s
b.) engineer more features to help the classifier
c.) process images to make some patterns stand out more
d.) all of the above
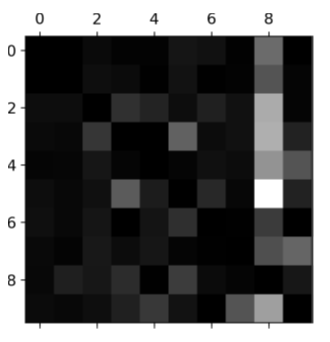
71
New cards
a.) Find the parameters that minimize the cost function
Gradient decent is used for the following purpose:
a.) Find the parameters that minimize the cost function
b.) Evaluate how good the predictions are.
c.) Split the dataset in training and test sets.
d.) Compute the recall
a.) Find the parameters that minimize the cost function
b.) Evaluate how good the predictions are.
c.) Split the dataset in training and test sets.
d.) Compute the recall
72
New cards
gradient descent
types of ________ _______ techniques:
1\.) batch
2\.) stochastic
3\.) mini-batch
1\.) batch
2\.) stochastic
3\.) mini-batch
73
New cards
data used
batch vs stochastic vs mini-batch in terms of ______ ______:
* batch uses the whole data set
* mini-batch uses only a subset of the whole data set
* stochastic uses 1 random data/example
* batch uses the whole data set
* mini-batch uses only a subset of the whole data set
* stochastic uses 1 random data/example
74
New cards
speed
batch vs stochastic vs mini-batch in terms of ______:
* stochastic (fastest) > mini-batch > batch (slowest)
* stochastic (fastest) > mini-batch > batch (slowest)
75
New cards
global minimum
batch vs stochastic vs mini-batch in terms of ______ _________:
* batch reaches the global minimum and then stops
* stochastic and mini-batch walk around the minimum
* batch reaches the global minimum and then stops
* stochastic and mini-batch walk around the minimum
76
New cards
convex
To be able to find the global minimum of a cost function, the cost function should be a _______ function when we use it with gradient descent technique.
77
New cards
a.) Learning rate is too high
Which of the following is true for the following figure?
a.) Learning rate is too high
b.) Learning rate is too small
c.) Cost function is not convex
d.) Gradient descent cannot find global minimum
a.) Learning rate is too high
b.) Learning rate is too small
c.) Cost function is not convex
d.) Gradient descent cannot find global minimum
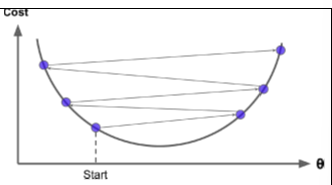
78
New cards
learning schedule
* a function that determines the learning rate at each iteration
* if it’s reduced too quickly, you may get stuck in a local minimum
* if it’s reduced too quickly, you may get stuck in a local minimum
79
New cards
mini-batches
At each step, instead of computing the gradients based on the full training set (as in Batch GD) or based on just one instance (as in Stochastic GD), Mini-batch GD computes the gradients on small random sets of instances called *____________.*
80
New cards
d.) All of the above
Which of the following is true for Normal Equation, Batch Gradient Descent (GD), Stochastic GD and Mini-Batch GD?
a.) After training, all these algorithms end up with very similar models and make predictions in exactly the same way.
b.) Batch GD’s path actually stops at the minimum, while both Stochastic GD and Mini-batch GD continue to walk around global minimum.
c.) Mini-batch GD will end up walking around a bit closer to the minimum than Stochastic GD - but it may be harder for it to escape from local minimal
d.) All of the above
a.) After training, all these algorithms end up with very similar models and make predictions in exactly the same way.
b.) Batch GD’s path actually stops at the minimum, while both Stochastic GD and Mini-batch GD continue to walk around global minimum.
c.) Mini-batch GD will end up walking around a bit closer to the minimum than Stochastic GD - but it may be harder for it to escape from local minimal
d.) All of the above
81
New cards
b.) Stochastic Gradient Descent
Given a training set with millions of features, the fastest algorithm to use to perform a search for a global minimum is:
a.) The Normal Equation
b.) Stochastic Gradient Descent
c.) Mini-batch Gradient Descent
d.) Batch Gradient Descent
a.) The Normal Equation
b.) Stochastic Gradient Descent
c.) Mini-batch Gradient Descent
d.) Batch Gradient Descent
82
New cards
a.) Convex
Gradient Descent will converge when training a Logistic Regression model because the cost function is:
a.) Convex
b.) Complex
c.) Collocated
d.) Core optimized
a.) Convex
b.) Complex
c.) Collocated
d.) Core optimized
83
New cards
a.) local minimum
Gradient Descent cannot get stuck in a _______________ when training a Logistic Regression model
a.) local minimum
b.) global minimum
c.) plateau
d.) summit
a.) local minimum
b.) global minimum
c.) plateau
d.) summit
84
New cards
c.) a-left is underfitting, b-center ideal separation, c-right is overfitting
Given the following set graphs (a –left, b-center, c-right), what is the statement that better describe the undermining / overfitting situation?
a.) a-left overfit the training set, b-center is an ideal separation, c-right underfit the training set.
b.) a-left is an ideal separation, b-center is underfitting, c-right is overfitting
c.) a-left is underfitting, b-center ideal separation, c-right is overfitting
d.) a-left is an ideal separation, b-center is overfitting, and c-right is underfitting.
a.) a-left overfit the training set, b-center is an ideal separation, c-right underfit the training set.
b.) a-left is an ideal separation, b-center is underfitting, c-right is overfitting
c.) a-left is underfitting, b-center ideal separation, c-right is overfitting
d.) a-left is an ideal separation, b-center is overfitting, and c-right is underfitting.
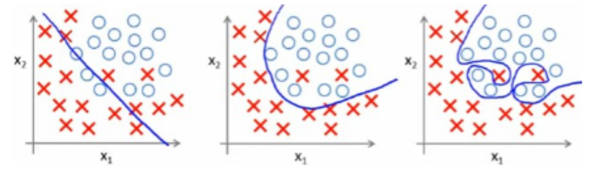
85
New cards
a, b, c, d
Which of the followings are an indication of underfitting?
a.) The model performs poor on the training data and also generalizes poorly.
b.) The training and validation learning curves reach a plateau and they are close and fairly high.
c.) Adding more training data does not help improving the performance on the training data
d.) We need more complex model or come up with better features
a.) The model performs poor on the training data and also generalizes poorly.
b.) The training and validation learning curves reach a plateau and they are close and fairly high.
c.) Adding more training data does not help improving the performance on the training data
d.) We need more complex model or come up with better features
86
New cards
a, b, c
Which of the followings are an indication of overfitting?
a.) The model performs well on the training data but generalizes poorly according to the cross-validation metrics.
b.) The error on the training data is low but considerable high on the validation data
c.) There is a gap between the learning curves for training and validation data
a.) The model performs well on the training data but generalizes poorly according to the cross-validation metrics.
b.) The error on the training data is low but considerable high on the validation data
c.) There is a gap between the learning curves for training and validation data
87
New cards
normal equation
* used to find the value of θ that minimizes the cost function
* closed-form solution (mathematical equation)
* closed-form solution (mathematical equation)
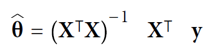
88
New cards
variance
A high-degree polynomial model is likely have high ________, and thus to overfit the training data while a high bias model is most likely to underfit the training data.
89
New cards
overfit
A high-degree polynomial model likely have high variance, and thus to ______ the training data while a high bias model is most likely to underfit the training data.
90
New cards
bias
A high-degree polynomial model likely have high variance, and thus to overfit the training data while a high ___ model is most likely to underfit the training data.
91
New cards
underfit
A high-degree polynomial model likely have high variance, and thus to overfit the training data while a high bias model is most likely to ______ the training data.
92
New cards
true
(T/F) Machine learning systems improve their performance in a given task with more and more experience or data.
93
New cards
b.) A dataset that contains the desired solution
A labeled training set is:
a.) A dataset that contains specific names
b.) A dataset that contains the desired solution
c.) A dataset that contains Boolean instances
d.) A dataset that contains sufficient instances
a.) A dataset that contains specific names
b.) A dataset that contains the desired solution
c.) A dataset that contains Boolean instances
d.) A dataset that contains sufficient instances
94
New cards
a.) Unsupervised learning task
Clustering is a type of:
a.) Unsupervised learning task
b.) Supervised learning task
c.) Regression learning task
d.) Batch learning task
a.) Unsupervised learning task
b.) Supervised learning task
c.) Regression learning task
d.) Batch learning task
95
New cards
a.) Reinforcement learning
The best learning type to teach a robot to learn to walk in various unknown terrains is:
a.) Reinforcement learning
b.) Supervised learning
c.) Semi-supervised learning
d.) Other types of learning
a.) Reinforcement learning
b.) Supervised learning
c.) Semi-supervised learning
d.) Other types of learning
96
New cards
b.) Clustering task
Customer segmentation into group is a type of:
a.) Classification task
b.) Clustering task
c.) Regression task
d.) Reinforcement task
a.) Classification task
b.) Clustering task
c.) Regression task
d.) Reinforcement task
97
New cards
a.) Online learning
This type of learning method is capable of adapting rapidly to both changing data and autonomous systems, and of training on very large quantities of data.
a.) Online learning
b.) Offline learning
c.) Reinforcement learning
d.) Semi-supervised learning
a.) Online learning
b.) Offline learning
c.) Reinforcement learning
d.) Semi-supervised learning
98
New cards
true
(T/F) An online learning system can learn incrementally
99
New cards
false
(T/F) Batch learning systems learn dynamically
100
New cards
true
(T/F) A hyperparameter is a parameter of the learning algorithm itself, not of the model