Data Engineering Exam 1
1/60
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
61 Terms
Data Engineering is ____ and Data Science & Analytics is ____.
upstream, downstream
Explain stage 1 of data maturity: Starting with Data
Challenges include losing organizational momentum, engineers should focus on visible wins, communicate with stakeholders, use off-the-shelf solutions, and only build custom systems where they offer competitive advantage.
Goals of this stage are:
1. Gaining executive support for data archetecture design.
2. Defining the right data architecture.
3. Identify and inspect data that will support key initiatives.
4. Operating the data archeticture.
5. Building a solid foundation for future data analysts to generate reports and valueable models.
Explain stage 2 of data maturity: Scaling with Data
This stage is about scaling data practices, optimizing for growth, and laying the groundwork for broader, company-wide data driven decision-making.
The Goals of Scaling with Data:
1. Establish formal data practices.
2. Create scalable and robust data architectures.
3. Adopt DevOps and DataOps practices lke automatioin, and monitoring.
4. Build systems that support machine learning.
5. Avoid unnecessary complexity and work unless there is competitive advantage.
Explain stage 3 of data maturity: Leading with Data
Stage 3 focuses on maintaining and enhancing data-driven capabilities, while ensuring that data is seamlessly available and usable across the organization.
Goals:
1. Deploy tools for data access to ensure that everone can access the right data.
2. Foster collaboration with engineers, analysts, and others to openly collab and share data.
3. Enable self-service analytics that empower employees at all levels to access and use data independently for analysis.
4. WATCH OUT for complacency, companies need to continuously improve and avoid stagnatiing or regressing to earlier stages.
5. WATCH OUT for technology distractions, temptations to explore new tech may not add business value.
Explain what type A and type B data engineers do:
Type A (abstraction): Avoids undifferentiated heavy lifting, keeping data architecture as abstract and straightforward as possible.
Type B (build): Builds data tools and systems that scale and leverage a company's core competency and competitive advantage.
What are internal-Facing Vs. External Facing Data Engineers?
Internal Facing Engineer: Focuses on activities crucial to the needs of the business and internal stakeholders.
External Facing Engineer: Typically aligns with the users of external-facing applications like social media apps, ecommerce platforms, etc.
What are the 4 primary languages a data engineer should know?
1. SQL
The most common interface for databases and data lakes, essential for querying and managing data.
2. Python
The bridge between data engineering and data science, with strong support for data tools (pandas, Airflow, PySpark, etc.).
3. JVM languages such as Java and Scala
Used for performance and access to low-level features in open-source projects like Apache Spark, Hive, and Druid.
4. bash
Command-line scripting for Linux; useful for automating tasks and managing OS-level operations in data pipelines.
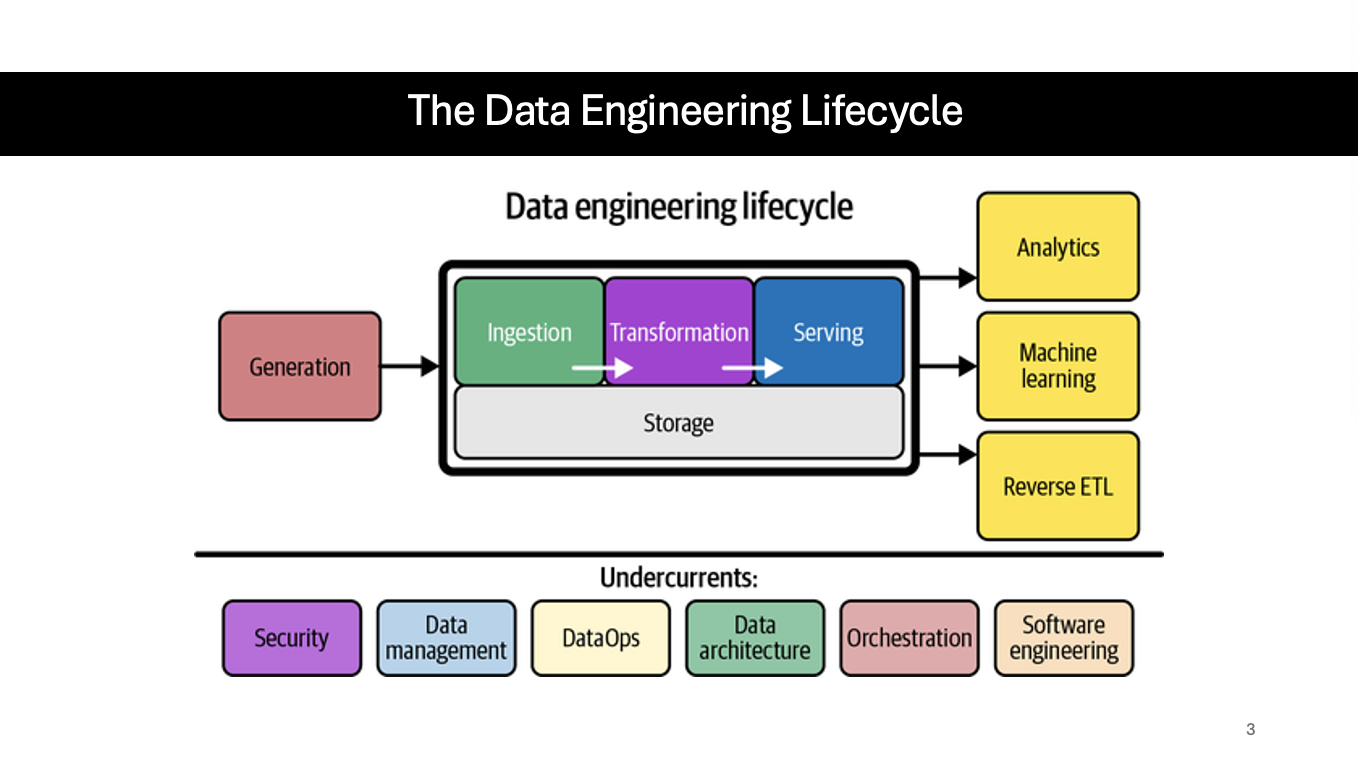
What are the 5 Major Stages of the Data Engineering Lifecycle
Generation
Storage
Ingestion
Transformation
Serving
What is Data Engineering?
Data engineering is the development, implementation, and maintenance of systems that take in raw data and produce info that support analysis and machine learning.
What is Data Maturity?
The progression toward higher data utilization. There are 3 stages including starting with data, scaling with data, and leading with data.
What is the Data Engineering Lifecycle (term and step-by-step goals)
Focuses on the stages a data engineer controls.
Generation —> Storage {Ingestion —> Transformation —> Serving}
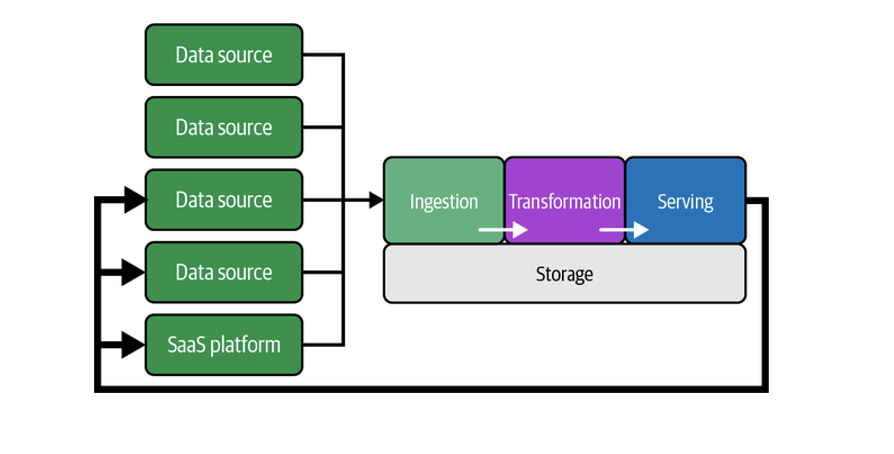
What is data generation?
The source system or the origin of the data used in the lifecycle.
IOT device
Phone, laptop
Application message qeue
Transactional database
E.g. Create a record to transfer 5 dollars from account A to B.
What is a Schema
A database schema is a blueprint that defines the structure and organizatioin of a relational database.
What is important when considering how to STORE your data?
COMPATIBILITY AND SCALE
What is HOT, WARM, and COLD storage?
HOT:
Access: Very frequent
Storage Cost: HIGH
Retrieval Cost: Cheap
WARM:
Access: Infrequent
Storage Cost: Medium
Retrieval Cost: Medium
COLD:
Access: Infrequent
Storage Cost: Cheap
Retrieval Cost: HIGH
What is data INGESTION?
The process of collecting data from various sources and moving it to a central location for further processing and analysis.
Wha is data TRANSFORMATION?
The process of changing from it’s original form into something useful for downstream use cases.
What is data SERVING?
When the data has value and can be used for practical purposes. It can be used in the following forms:
E.g. — Data analytics: Build reports, dashboards, ad hoc analysis, etc.

What is a Reverse ETL?
Reverse ETL takes processed data from the output side of the data engineering lifecycle and feeds it back into source systems.
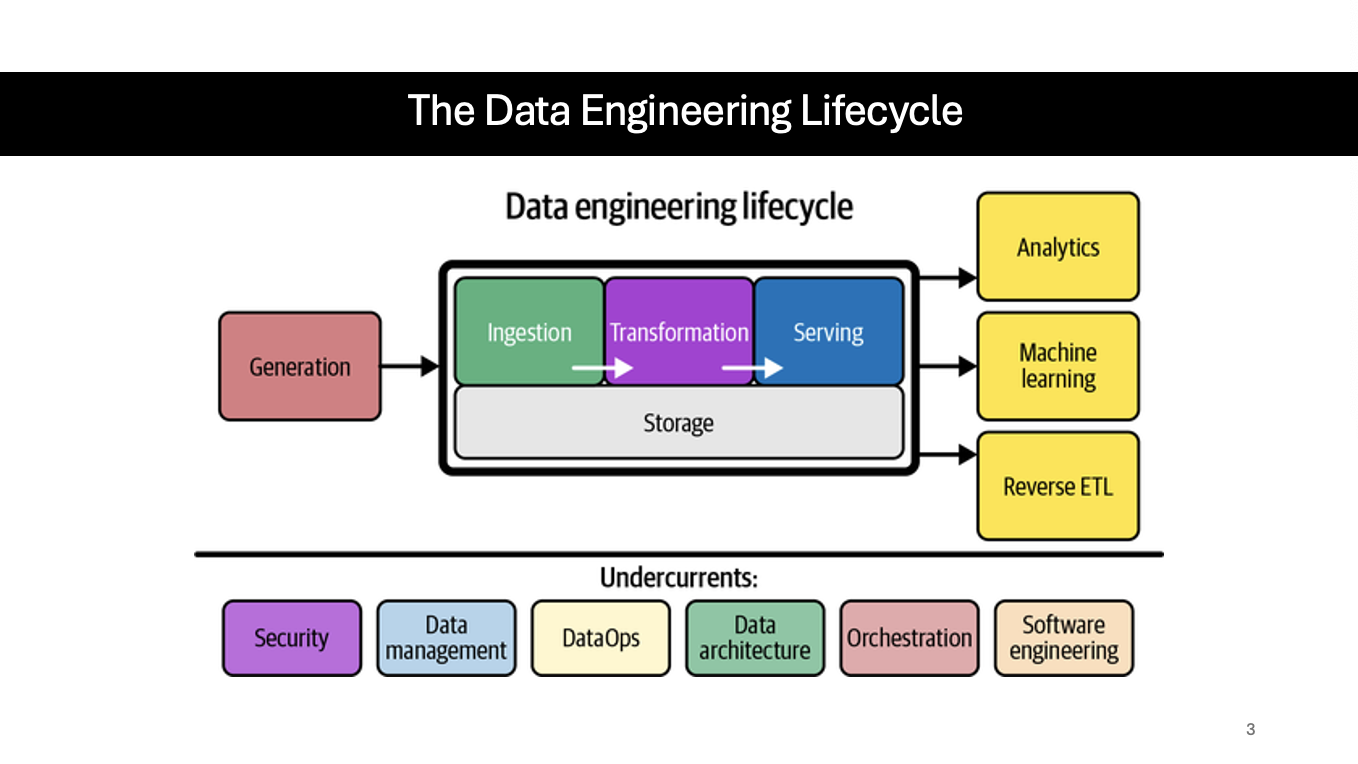
What is DATA SECURITY of the 6 Data Undercurrents Across the Data Engineering Lifecycle?
Security
Competency in managing security of the data. The first line of defense for security is o create a culture of security that teaches all individuals who have access to data, that it is their responsibility to protect the companies sensitive data. Only give access to those that needed for the duration necessary to perform their work.
What is DATA MANAGEMENT of the 6 Data Undercurrents Across the Data Engineering Lifecycle?
Dev., execution,, and supervision of plans, policies, programs, and practices that deliver, control, protect, and enhance the value of data and information assets throughout their lifecycle.
What are DATAOPS of the 6 Data Undercurrents Across the Data Engineering Lifecycle?
A collection of technical practices that enable rapid innovation and experimentation delivering new insights to customers with increasing velocity, low error rates, and clear monitoring.
What is DATA ARCHITECTURE of the 6 Data Undercurrents Across the Data Engineering Lifecycle?
A data architecture reflects the current and future state of data systems that support an organization’s long-term data needs and strategy.
What is DATA ORCHESTRATION of the 6 Data Undercurrents Across the Data Engineering Lifecycle?
Orchestration is the process of coordinating many jobs to run as quickly and efficiently as possible on a scheduled cadence.
What is SOFTWARE ENGINEERING of the 6 Data Undercurrents Across the Data Engineering Lifecycle?
Software engineering is crucial for data engineers. Initially, they worked with low-level coding frameworks like MapReduce, but modern tools like Spark and SQL have made coding more abstract and user-friendly.
What is Data Architecture Defined
Data architecture is the design of systems to support the evolving data needs of an enterprise, achieved by flexible and reversible decisions reached through a careful evaluation of trade-offs.
What is Operational Architecture?
Operational architecture encompasses the functional requirements of what needs to happen related to people, processes, and technology.
What is Technical Architecture?
Outlines HOW data is ingested, stored, transformed, and served along the data engineering lifecycle.
What is principle 1 of Good Data Architecture? (WRITE DOWN OVER AND OVER TO MEMORIZE)
Choose common components wisely.
Common Components have Broad Applicability
Must be Accessible and Secure
What is principle 2 of Good Data Architecture?
Plan for failure
Availability
Reliability
Recovery Time Objective (RTO)
Recovery Point Objective (RPO)
What is principle 3 of Good Data Architecture?
Architect for Scalability
Consider Variability and Permanence of Scale
Elastic Systems – Scale Up, Scale Down, Scale to Zero
What is principle 4 of Good Data Architecture?
Architecture is Leadership
Architects are Decision Makers
Architects Delegate
Command and Control vs. Influence
What is principle 5 of Good Data Architecture?
Always be Architecting
Systems aren’t Static
Architects don’t just Maintain – They Evolve to Meet Business Demand
Baseline vs. Target Architecture
What is principle 6 of Good Data Architecture?
Build Loosely Coupled Systems
Test, Deploy and Change Independently
Services and Contracts
Details are Hidden, Changes don’t Affect Other Components
What is principle 7 of Good Data Architecture?
Make Reversible Decisions
Simplify Architecture, Enable Agility
Two-way Doors Analogy
Pace of Change Makes this a Necessity
What is principle 8 of Good Data Architecture?
Prioritize Security
Hardened-perimeter and zero-trust security models
The shared responsibility model
Data engineers as security engineers
What is principle 9 of Good Data Architecture?
Embrace FinOps
FinOps is the emerging professional movement that advocates a collaborative working relationship between DevOps and Finance, results in an iterative, data drive management of infrastructure pending while simultaneously increasing the cost efficiency and ultimately, the profitability of the cloud environment.
What are domains and services?
A domain can contain multiple services. A service can include things like orders, invoicing, and products.
An accounting domain responsible for basic accounting functions: invoicing, payroll, and accounts receivable.
Tight Coupling VS. Loose Coupling
Tight = Extremely, centralized dependences and workflows, where every part of a domain and service is vitally dependent upon every other domain and service.
Loose = Decentralized domains and services that don’t have strict dependence on each other. It's easy for decentralized teams to build systems whose data may not be usable by their peers.
What are the 4 characteristics of data systems?
Scalability
Elasticity
Availability
Reliability
What are the architecture tiers and explain each one?
Single tier
You database and application are tightly coupled, residing on a single server.
Mulltitier (n-tier)
The upper layers are more dependent on the lower layers.
Three-tier
These tiers include the Data —> Application Logic —> Presentation tiers.
What are MONOLITHS?
A monolith in data refers to a system where all data-related processes—such as data storage, processing, transformation, and serving—are tightly integrated within a single, unified architecture. This often means that the entire data pipeline, from ingestion to analytics, is managed in one system or application, with little separation between components.
What are MICROSERVICES?
Microservices are the opposite of monoliths, it comprises, separate, decentralized, loosely coupled services. Each service has a specific function is the couple from other services operating within its domain. This case, for one service temporarily goes down it won't affect the ability of other services to continue functioning, unlike monoliths.
What is on Premise?
Data and computing resources are hosted locally within an organization’s own infrastructure. Companies maintain complete control over hardware, software, and security but bear all the costs and responsibilities for management and maintenance.
What is Cloud?
Data hosted on third-party cloud providers (like AWS, Azure, or Google Cloud), offering scalability and flexibility. Organizations pay for what they use, and infrastructure management is handled by the provider.
What is Hybrid Cloud?
A combination of on-premise and cloud , allowing organizations to use both environments. Critical data or legacy systems might stay on-prem, while other processes leverage the cloud for scalability and cost-effectiveness.
What is Event-Driven Architecture?
Event-driven workflow, encompasses the ability to create, update, and asynchronously move events across various parts of the data engineering lifecycle.
For example, in an event driven workflow, an event is produced, routed, and then consumed. In an even driven architecture, events are passed between loosely coupled services.
What are the two different types of data architecture projects?
Brownfield Projects
Refactoring and reorganizing an existing architecture.
Greenfield Projects
Fresh start, unconstrained by the history or legacy of a prior architecture.
What is a Data Warehouse Architecture?
A central repository that aggregates data from multiple sources. Data warehouse architecture can be single-tier, two-tier, or three-tier.
What is a Data Lake Architecture?
A flat architecture that stores large volumes of data in its native format. Data lakes can store any type of data, including text and images, from any source.
What should be considered when choosing data technologies?
Team size and capabilities
Speed to market
Interoperability
Ensure that it interacts and operates with other technologies.
Cost Optimization and Business Value
Gaining back the amount spent on data projects + more.
Location
On Premises
Cloud
Hybrid Cloud
Build Versus Buy
Monolith vs. modular
Serverless Versus Servers
Optimization, performance, and the benchmark wars
the undercurrents of the data engineering lifecycle
How do you measure the payback on technology?
Your organization expects a positive ROI from your data projects. The following should be considered:
Direct Costs
Indirect Costs
Capital expenses
Operational expenses
What is an entity?
A noun, a person, place thing or event that you want to track data on
What is an attribute
A property of an entity
What is an attribute?
How entities are related to one another, the association between entities
What is a One-to-many Relationship?
When one entity can be related to many (one or more) instances of another entity
What is a Repeating Group?
When there are multiple values for one or more attributes
Define first normal form:
A table in first normal form has no repeating groups, and each record is unique.
There can be several issues with duplication of data, and insert, update and delete anomalies.
Define second normal form:
Builds on 1NF by ensuring that all non-key attributes are fully dependent on the entire primary key, eliminating partial dependencies (when only part of a composite key determines a non-key attribute).
Without second normal form, you can have issues with update anomalies, inconsistent data, insert anomalies and issues deleting
Define third normal form:
A database is in 3rd normal form if it is in second normal form and all determinants are a candidate key (BCNF).
A slightly weaker form states that there are no transitive dependencies.
Similar to not having a database in 2NF, if a database is not in 3NF, you can experience update anomalies, inconsistent data, insert anomalies, and delete anomalies.
Write the table definition using the common shorthand notation used in the book: e.g. For a department, store the department number and department name. Department number can be used as the primary key.
Department(Department Number, Department Name)