LIS 7010 Midterm Study Set
1/116
Earn XP
Description and Tags
Library and Information science course; organization of information; Louisiana state university school of information studies graduate program; page numbers listed refer to the pages in the electronic version of the 4th ed. of The Organization of Information by Joudrey and Taylor (2018)
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
117 Terms
What do we mean by organize? Why do we organize information?
organize: to form into a coherent unity or functioning whole; to arrange or order things so that they can be found easily and quickly;
Why?
to understand and make sense of things in daily life;
save time- to be quick and efficient in accessing information or things;
to collocate- bring similar things or ideas together into groups, useful for finding similar resources nearby;
retrieve: we need to be able to find things and this makes that possible
Function Requirements for Bibliographic Records (FRBR) IDs what key tasks organizing info helps with:
1. find (entities that match specific criteria)
2. identify (confirm that an entity corresponds with the one sought)
3. select (choose a resource that is appropriate to the user’s needs
4. obtain (gain access to the resource)
5. explore (discover resources and entities)
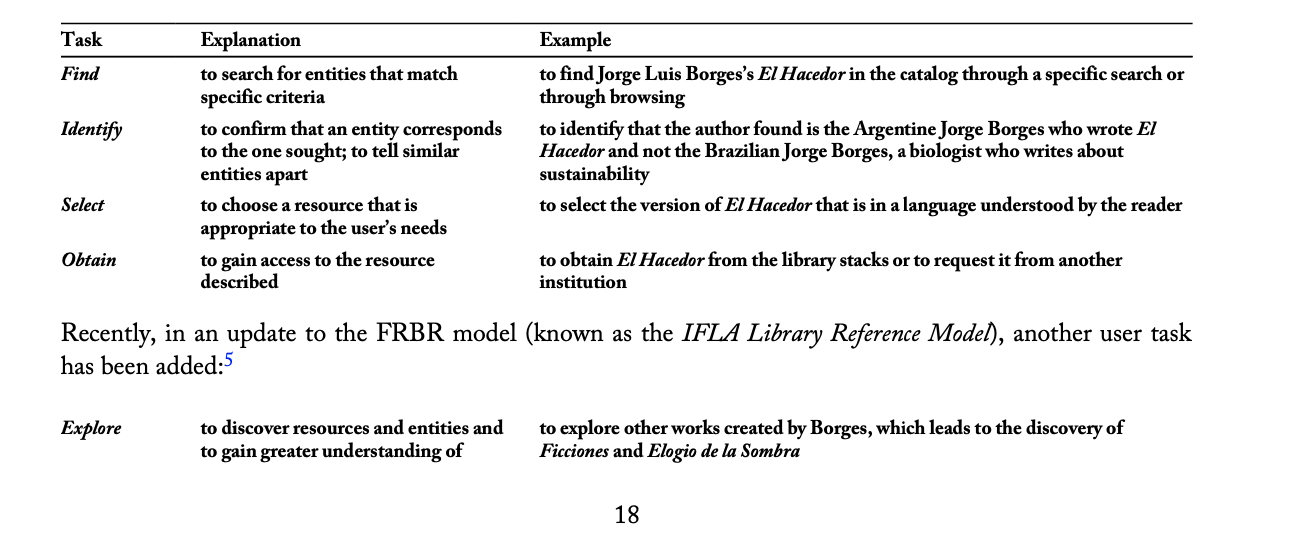
Information Organization
the process of describing resources and then providing name, title, and subject access to the description; resulting in resource descriptions that serve as surrogates for the actual items of recorded information and in resources that are logically arranged
also known as bibliographic control
knowledge
exists in the mind of an individual who has studied a subject, understands it, and perhaps has added to it through research or other meansd
information
the communication or reception of knowledge; data converted into a meaningful and useful context
basic attributes of information resources
title (what we call a resource)
creator (who is responsible for it)
subject (what it it about)
these attributes can collectively be referred to as metadata
metadata
data about data; basic attributes of recorded information; structured information that describes the attributes of resources for the purposes of identification, discovery, selection, use, access, and management; the purpose of this is to provide a level of data at which choices can be made as to which resources a person wishes to view without having to search through massive amounts of irrelevant text
surrogate record
not the information resource itself- an entry that describes the resource using metadata attributes; a presentation of the characteristics of a resource in one complete package (i.e. record, bibliographic record, metadata); often placed into retrieval tools to point to actual information resources
what activities are involves in organizing recorded information (p. 20)
identifying the existence of all types of information resources as they are made available
identifying the works contained within those resources
systematically pulling together these resources into collections
producing lists of these information resources prepared according to standard rules for citation
providing name, title, subject, and other useful access to these information resources
providing the means of locating a resources
access point
a name, word, phrase, or identifier chosen by a cataloger or indexer and placed in a particular field in a record that describes a resource; may be used to obtain that record from a retrieval tool or other organized system; metadata that is used to retrieve the information resource
authority control
often practiced by using a unique character string to represent each name, work, or subject, in order to achieve consistency within the catalog or other retrieval tool; must create explicit relationships between different names, works, or subjects; provides consistency for authorized access points
the process of bringing together all of the forms of name that apply to a single entity; gathering together all the variant titles that apply to a single work; and relating all the synonyms, related terms, broader terms, and narrower terms that apply to a particular subject heading.
cataloging
how resources are organized and integrated into the collection- especially within libraries; the goal is to create a multifaceted list of resources to which the library can provide access;
comprises 2 major activities: descriptive cataloging and subject cataloging
combined, cataloging activités involve: Creating a description, choosing access points, ensuring authority control, choosing classification notations (based on standardized notation style of the organization)- original cataloging
descriptive cataloging
(p. 25) describes the makeup of an information resource and identifies the entities responsible for its intellectual and/or artistic contents without references to its classification by subject; the phase of cataloging process that is concerned with the identification and description of a resource, the recording of this info in a bibliographic records, and the election and formation of access points (except for subject access points)
activities involved: creating a description; choosing access points, ensuring authority control
2 major outcomes of cataloging are 1: the arrangement of collections & 2) creation and maintenance of the catalog that provide primary means of access to the collections
subject cataloging
(p.25) the second major process of cataloging; involves 2 major activities called conceptual analysis and translation
conceptual analysis: the process of determining the aboutness (subject matters) of a resource
translation: the process of transforming the resources’ aboutness into controlled subject languages: involves these activities- choosing controlled vocabulary terms and choosing classification notations
copy cataloging
libraries often acquire copies of the same resources so catalogers can share metadata by adapting a copy of the original cataloging recored created by another library for their own catalogs
cooperative cataloging
the working together by independent institutions to share network memberships or to create cataloging that can be used by others
union catalogs
catalogs that contain records from more than one library; concept was expanded to show what at least one of the cooperating libraries had; more recently the addition of records for online resource has meant that catalogs now contain records for what the library provides access to
discovery layer of catalog
also referred to as discovery interface; a technological add-on to the catalog by allowing users to have a greater variety of interaction with a library’s information stores
provenance
respect des fonds; the individual, family, organization, or institution that is responsible for the creation, maintenance, or us of the materials; principle dictates that records of different origins should be kept separate to persevere their context
the place of origin or earliest known history of something - used for museums and archives. Not the same as the date of a resource in a library; Provenance in archives drives the principles of organization. Collections are organized according to their provenance. In art history, the provenance of a work is connected to the ownership and authenticity of the work.
original order
second fundamental principle of archives; directs archivists to maintain the organization or sequence of materials established by the creator of those materials
accession record
summarizes information about the source of the collection, gives the circumstances of its acquisition, and briefly describes the physical details and contents for a collection
finding aid
provides detailed notes on the historical and organizational context of an archival collection and continues by describing its content, providing an inventory outlining what is in each box; may contain subject headings, authority-controlled access points, and physical details such as the presence of brittle or fragile materials
tend to be longer than typical catalog records as archives maintain control over entire collections; some of these are not publicly accessible, but this increasingly rare; its often linked to a summary description of the collection in a catalog record
aka registers, inventories, container lists
DACS is used to create these
types of info found in a typical one: Provenance, physical extent and condition, scope and content notes, order & structure, administrative info (93)
Describe the history of the encoding standard for archives
MARC-AMC (archival and manuscript control); MARC; EAD (Encoded Archival Description) (p. 28)
Name metadata schemas for Museums, and art/object collections
CDWA (Categories for the Description of Works of Art); Thesaurus for Graphic Materials (TGM); The Getty Vocabularies; Iconclass; CCO (Cataloging Cultural Objects)
internet directory
an organized collection of links to websites on particular topics
semantic web
an extension of the World Wide Web; the traditional web provides linkages between online resources usually at the level of the whole resource or a discrete part of it. this would provide linkages around statements about resources, in a format semantically meaningful to, and actionable, by computers; linked data is generally the basis for this;
idea that the web should shift from identifying and retrieving documents for human consumption only to identifying and retrieving the data in those documents for humans and for better machine understanding, manipulation, and processing.
linked data
(35) the basis for the semantic web; an approach to encoding data from a wide range of different sources and publishing it on the web in such a way that it may be understood by computers as related to the same resource or concept; characteristics:
is machine-readable
has meaning explicitly defined
is linked to other external data sets
is linked to from external data sets
digital collections
hese online spaces, generally, contain collections of digitized or born-digital resources that have been selected for inclusion for the purposes of access and preservation for posterity. A specific digital collection may be referred to as a digital library, a digital archives, or an institutional repository.
must contain an organized collection of digital resources (it is not a set of hyperlinks to other material);
is created for a particular audience, group of users, or community;
takes advantage of technology and human resources (e.g., librarians);
provides fast and efficient access to digital resources, often without cost (although membership in a community might be required); and
owns, controls, or has rights to the digital resources distributed by it. (37)
information architecture
the process of designing, implementing and evaluating information spaces that are humanly and socially acceptable to their intended stakeholders;
The structural design of shared information environments.
The synthesis of organization, labeling, search, and navigation systems within digital, physical, and cross-channel ecosystems.
The art and science of shaping information products and experiences to support usability, findability, and understanding.
An emerging discipline and community of practice focused on bringing principles of design and architecture to the digital landscape.
Big IA: the process of designing and building information resources that are useful, usable, and acceptable; top-down, conceiving the full product and its human or organizational impact
Little IA: user experience and organization acceptance of the resource; more bottom0up, addressing the metadata and controlled vocab aspects of info organization (p. 40)
process of this: research, strategy, design, implementation, administration (p. 40)
Indexing vs abstracting
Both are approaches to distilling information content into an abbreviated, but comprehensive, representation of an information resource. Indexing can be back-of-the-book, database, or web style but in all forms information resources is analyzed and the aboutness is described concisely. Abstracting, however, is more of a synopsis or summary of the resource.
Indexing: the process by which the content of an information resource is analyzed and the aboutness of that item is determined and expressed in a concise manner (3 basic types: back of the book, database, and web) p. 41
Abstracting: a process that consists of analyzing the content of information resource and then writing a succinct summary or synopsis of that work; typically done for academic publication or prof. journal. several types of abstracts: indicative, information, critical, structured, modular (42)
records management
the control and disposition of records created in offices and other administrative setting; has strong relationship with archives; the field of management responsible for the efficient and systematic control of the creation, receipt, maintenance, use, and disposition of records.
records system characteristics located on page 43

personal information management
“the practice and the study of the activities a person performs in order to acquire or create, store, organize, maintain, retrieve, use, and distribute the information needed to complete tasks and fulfill various roles and responsibilities.”
2 issues that make this challenging:
information overload: when a perceive receives more info that can be processed
information fragmentation: having information items scattered across multiple personal devices and tools in different formats
knowledge management (KM)
the process of capturing, developing, sharing, and using organizational information to make good, well-informed decisions. comprises three major components: people, processes, and technology.
primacy of the author
Western idea influenced by Greek civilization; This creates the idea that the main entry, or the thing that dictates where an item falls in the list, ought to be the author
Callimachus
Writers have quoted from the pinakes of Alexandria, which was created by Callimachus. The work may have been a catalog, or it may have been a bibliography of Greek literature. Callimachus has been given credit as being the first cataloger of whom we have knowledge. 56
how subjects were defined in the medieval period
broadly defined; some using only 2 categories- biblical and humanistic
analytical entry
an entry made for each work in a volume, as opposed to making only one entry for the entire volume; was a third part of the innovation in the development of cataloging in the European Renaissance through a list compiled by John Whytefield (one list that may justly be called a catalog)
cross-references
also knows as reference; a pointer from one part of the catalog where someone may logically search to another place where the information is actually found; a new practice developed in the 15th century (European Renaissance)
bibliography
the study of books as physical and cultural objects, which often results in creating extensive lists; the invention of printing press led to the need of this new area of expertise as collections grew
national cataloging code
cataloging code: set of guidelines or instructions on how to catalog; French government created 1st instance of a national code; the French Revotion provided impetus for new kind of catalog in the form of playing cards where playing cards were used to record cataloging inform;
led to card catalog: catalog in which every resource description is written, typed, or printed on cards that are placed in file drawers in a particular order (usually alphabetically or classified order)
Charles Coffin Jewett
considered to be an expert in the practices of constructing and evaluating library catalogs; extended the principle of corporate authorship; developed a plan to create a stereotyped (method of printing using a metal copy of a typeset image) plate of each titles cataloged, store the plates, and use them over and over for production of printed cataloging, have them numbers in order they were printed and keep them in alphabetical order - numbers could be used by libraries to indicate which titles were owned by that library; also allowed for the printing of a union catalog
Charles Ammi Cutter
created rules for a dictionary catalog- credited as foundation of American cataloging; created expansive classification (EC) system (began with letters of alphabet, expanded with second letters, then expanded further with numbers for different facets- 64; LC ended up creating scheme based off his main class structure) and was the genius behind book numbers called Cutter numbers (still used today)
felt that catalogs should not just point the way to an individual publication but also assemble and organize literary units= catalogs as collocation devices
first to make rules for subject headings as a way to gain subject access to materials through the catalog ( 61)
Melvil Dewey
issued first edition of classification- it divided all knowledge into 10 main classes, with each of those divided again into 10 divisions, and each of those divided into 10 sections—giving 1,000 categories into which books could be classified. Like its predecessors, it was enumerative in that it listed specific categories one by one. In later editions he added decimals so that the 1,000 categories could be divided into 10,000, then 100,000, and so on. Dewey Decimal Classification (DDC)
introduced the first hints of number building (or faceting) when he made tables for geographic areas and for forms of material. Notations from these tables (today referred to as subdivisions) could then be appended to the base number to show a certain subject as being relevant to a particular geographic area or being presented in a particular form (64)
4 principal theories of cataloging
Legalistic—cataloging with a rule for everything, and an authority to settle any question at issue,
Perfectionistic—cataloging performed so well the first time that it is done once and for all,
Bibliographic—cataloging made into a branch of descriptive bibliography with extremely detailed physical descriptions and notes, and
Pragmatic—cataloging according to the needs of particular types of libraries and/or users. (p. 62)
retrieval tools
systems created for discovering information; designed to help users find, identify, select, obtain, and explore information resources of all types; assist users by retrieving info directly (through web search) or through relevant documents that are part of organized collections (catalog search) p. 74
also contain records that act as surrogates for records (surrogate records/description/metadata)
basic retrieval tools
bibliographies, catalogs, indexes, finding aids, registers, search engines
bibliographies
list of resources on a given subject, by a given author, from a particular time period or place, and the like; generally there is a particular focus or arrangement and often 2 or more of the foci are combined in the bibliographies
some include annotations (brief reviews indicating the subject matter and/or commenting on the usefulness of the info resource)
will include citations (short description consisting of creator, title, edition or version, publisher, place, and date of publication for a book or other whole entity); each citation usually only appears in one place (under creator typically), which usually only provides one access point
can be attached to scholarly work, consisting of the info resource consulted by the author of the work or can be completely separate entities in their own right (p. 76)

library guides
also known as pathfinders, subject guides, research guides
a special kind of bibliography found in libraries that is truly meant to be a retrieval tool
they focus on the resources in a defined subject area available in a particular setting; may also include list of locally accessible databases to search, specific instructions on how to search the local catalog, and a list of specific reference resources related to the subject area
software products like LibGuides or SubjectsPlus have been developed for the creation and management of these (p. 76)
catalogs
provide access to individual items within collections of information resources; each resource is represented by a description that is a little longer than an entry in a bibliography; descriptions are assigned 1 or more access points (76) and they are constructed according to a standard style selected by a particular community
traditionally serve 2 main user groups: employees of the institution and users of the institution who wish to borrow material or make use of it on the premises (77)
they also serve as an inventory of the collection
they can come in multiple forms
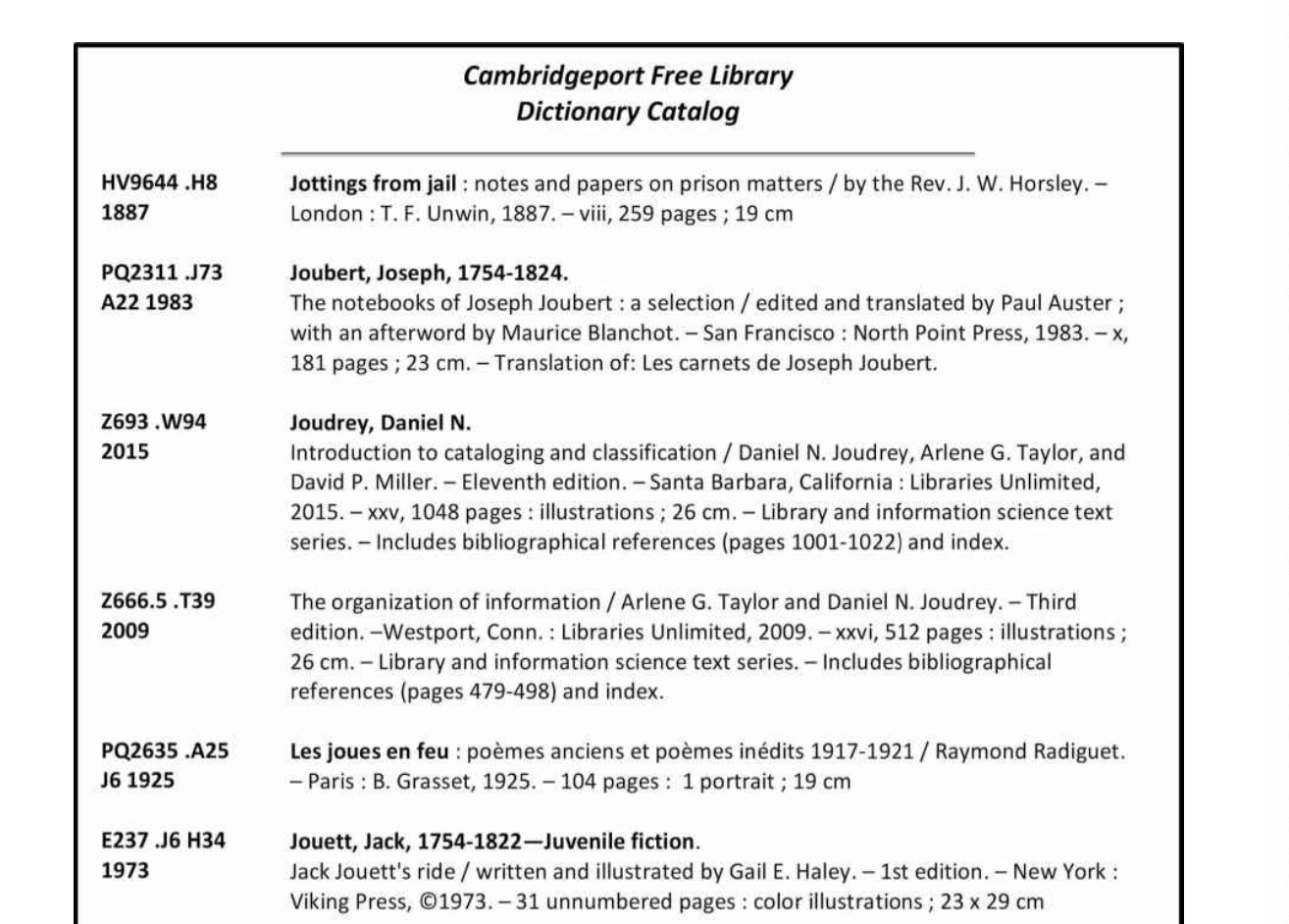
book catalogs
were originally handwritten lists but were eventually printed lists
have mostly been replaced by other catalog forms, but are still sometimes used in cases for rare materials, catalogs of exhibits, artists’ works, help make the contents of special collections known to users in many locations, etc. (p. 80)
example provided in picture.

card catalogs
catalog in which every resource description is written, typed, or printed on cards (usually 7.5 × 12.5 cm or 3×5 in) that are placed in file drawers in a particular order (usually alphabetically or classified order)
were originally written with library hand until typewriters and other forms of printing made that obsolete
users of these could go from library to library, confident they could use local and distant catalogs with ease
online catalogs have mostly replaced these
microform catalogs (COM catalogs)
produced on microfiche or microfilm and require a microfilm reader to use them;
produced like book catalogs; unpopular though and were quickly replaced
online catalogs
OPACS - predominant form of catalog in the US and other countries today; records are stored on a local or remote server and records are displayed only as needed and the display is flexible
have not been standardized
has been criticized in recent years for its complex use
classified catalog arrangements vs alphabetical catalog arrangements
note: this mostly refers to printed catalogs, not online ones; they are possible in online catalogs, but they aren’t the only choices
classified: catalogs that usually have more than 1 section; the “main” section, the arrangement or display is in the order of the classification scheme used in that institution (DDC, not subject terminology); advantage that users can look at records for broader and narrower concepts at the same place they are looking for records on a specific concept (like browsing the stacks); have traditionally been used in European and other countries where several languages are spoken
alphabetical: catalog with entries arranged or displayed in alphabetical order rather than according to the symbolic notation of a classification; led to divided catalogs, which are alphabetical catalogs that were partitioned into 2 or 3 possible section (authors and titles in one part; subject headings in another part, etc.)
p.85- 89
relevancy ranking
another catalog arrangement; OPACS can be programmed to return search results in arrangements based on their relevancy or the resources most closely connected to the search terms are ranked higher in the search results
determined algorithmically and defined differently in each system- based on a variety of factors (placement, field weighting, term frequency, etc.)

Indexes
retrieval tools that provide access to the analyzed contents of information resources; a bibliographic tool that provides access to the analyzed contents of resources (e.g. articles in a journal, short stories in a collection, papers in a conference preceding); not limited to what is available in a local setting or a particular collection and do not usually give location info as such
Not necessarily talking about back of the book indexes or A-Z indexes, the ones being talked about are ones that are separate from the resources being analyze (back of the book indexes analyze the resource they are a part of- we are concerned with ones that are NOT a part of the resource)
Database indexes are what we are discussing:
they tend to be created by for-profit organizations; they can be created by people (mostly by people though) and machines (KWIC indexes); The current application of automatic indexing is in search engine indexing. A search engine is sometimes referred to as an index but, more accurately, a search engine creates lists of terms that are referred to as indexes.
pg. 90-92
search engine
a computer program that searches web documents for specified keywords via a program called a spider. The list of documents is returned to an internal database and placed in order by the indexing program according to the words or concepts contained in the document; a type of automatic indexing
were developed for the purpose of searching full text documents; they automatically collect information from web resources and places it into a databased of records or into a full-text index; The spider is typically programmed to go onto the web to retrieve and download copies of web pages and everything linked to them, everything linked to the links, and so on. Massive collective indexes— created from the spider’s database—are stored in data centers around the world. These indexes (some comprising over 100 million gigabytes of data) are what are searched when users enter terms into the search box (p. 98)
have become routine part of user’s interactions with the world
usually issues with homographs though- if you search bridge, you can get results about architectural structures, card games, geographic spaces, organizations with bridge in the name, etc.
displays of search results are usually arranged according to relevance, which can be calculated in various ways.
registers
the primary collections control tool for museums; also called accession log
functions like a catalog with additional access points (donor, style, provenance, etc.)
process of registration is similar to cataloging- the registrar identifies a lot of information and assigns an identification number
usually internal and not made available to the public (p. 96)
note: museums may also provide databases for public access online
directories
organized collections of links to websites; an alternative for finding web resources rather than through search engines
importance of retrieval tools
it is often tempting to think that nothing more than a search engine is ever needed. however, much of the world’s information is not online at this time and that much of that information probably never will be. In addition, a great deal of what is available in electronic form is not necessarily freely available to all. Information is still a commodity.
there are times that users and information professionals need more advanced types of searching that are currently not available in the search engine approach (e.g., an author search rather than a general keyword search)
3 basic functions information systems perform
1) storage: data organization
2) retrieval: based on queries
3) display: the interface or presentation design
all are necessary and system designs decisions must take all three into consideration (p.105)
Why did libraries automate?
provide access to the complete catalog from multiple locations,
increase and improve access points,
increase and improve search capabilities,
eliminate or reduce inconsistencies and inaccuracies of card catalogs,
reduce the increasing problems and costs of maintaining card catalogs, and
deal with pressures and influences for change p. 105
automation does not solve all issues of organizing information though.
databases
one of the most basic tools used for organizing information
organized collections of data; a set of records that are all constructed in the same way and are often connected by relationship links; the structure underlying retrieval tools; are necessary when there is too much info for humans to process and analyze by themselves
they serve various functions: hold administrative data, a collection of images, or raw numerical data; may contain surrogate records or hold the actual information resources of interest; may be repositories of full text articles or might keep track of inventory and sales: generally their functions fall into 2 categories
1) reference databases: contain links or pointers to info sources help outside the database
2) source databases: contain the actual information sought (p. 106)
relational database vs hierarchical databases
relational: most database applications are this; designed using an entity-relationship model; collection of metadata typically found in a surrogate record is divided into parts (entities), which are held in various tables. These parts are linked to each other to form individual metadata displays that show how the various entities are related. to interact with and retrieve info in a database, query language is used like SQL (Structured Query Language)
hierarchical: used in the past; used a traditional tree structure as a model for holding information; They consisted of one file composed of many records, which in turn were made up of numerous data fields. These databases tended to be rather inflexible and used more space as data was often repeated. (p.106)
Bibliographic networks
a corporate entity that has as its main resource a bibliographic database; access to the database is available for a price and members of the network can contribute new records and download existing ones
they usually acquire many MARC records from LC; the records contain 2 kinds of information: cataloging data like title, subjected, creator AND holdings information for libraries that have added specific items to their collections (107)
they are designed to automate cataloging and allow for record sharing
3 major ones: OCLC, SkyRiver, Auto-Graphics
integrated library systems (ILSs)
computer system that includes various modules to perform different functions while sharing access to the same database; more than just an OPAC
example modules it may support: acquisitions, authority control, cataloging, circulation, interlibrary loan, system admin, public access, serials management, etc.
This is different from an LSP (Library services platform), which are designed to go beyond the tradition ILSs. ILS has been designed to manage print collections, but an LSP integrates seamlessly the management of both print and digital resources
LSPs
enables libraries to acquire and manage their collections, spanning multiple formats of content;
supports multiple acquisitions processes, including those for ownership, paid licenses and subscriptions, and open-access sources;
supports multiple metadata schemas, including at a minimum, MARC and Dublin Core;
may include an integrated discovery service or support a separately acquired discovery interface;
provides all staff and patron functionality though browser-based interfaces; and
provides knowledgebases that represent the body of content extending beyond the library’s specific collection
incorporates more current technology and architecture like cloud computing (p. 108)
what are some suggestions for the next generation of catalogs past the OPAC?
simpler interfaces (e.g. Google search);
expanded searching (allow for searching electronic and print resources at the same time through single, integrated search box)
increased direct access (provide access to more than just surrogate records; links to full text documents and digital objects)
faceted browsing (Browsing can be done using facets such as subject, genre, format, call number, library branch, language, geographic area, time period, and so on.)
increased interaction (In recent years, catalogs and discovery interfaces have allowed for more user input, similar to Web 2.0 applications where users review, rank, recommend, or tag information resources.)
what are the 2 basic approaches to searching?
querying and browsing
querying
can be phrase matching or keyword matching; is useful when users know exactly what they want (i.e. known item searching)
phrase matching: matching a particular search string to the exact text located in records in the system (or more precisely, to particular indexes created by the system). demands that the words of the string be found together in the same order as given in the search query (i.e., left-anchored searching); does not allow for the terms or strings to be found in various fields (or indexes).
keyword matching: involves matching discrete words to the system’s indexes, often using Boolean operators or proximity formulations to combine them. Keywords may be matched against terms that occur in more than one field or index; allows the terms to be separated (p. 112)
browsing
can be pre-sequenced, linear, system-based browsing or faceted browsing
pre-sequenced, linear, system-based browsing: allows users to scan lists of terms, names, or brief titles to find topics, creators, or items of interest. This is the more structured approach, using the system’s internal organization of the data to guide browsing activities.
faceted browsing (nonlinear and multidirectional): This is browsing that is more serendipitous. It is unstructured. It uses or can use hypertext links to navigate between various items and may be more exploratory or seemingly more random. In recent years, the phrase faceted browsing has come into use; it refers to system-based browsing that exploits various types of data found in metadata records.
What are some issues with system design?
When the metadata is clear, understandable, easily retrieved, and well presented, the user usually does not notice system design or organizing elements. It is only when there are problems or confusion that these elements are discussed. (p. 111)
1) most current systems are oriented toward exact match queries in an all or nothing approach; In order for a system to work fairly well, users must have a good idea of what they are looking for. It places the burden on the users; need more intuitive system design (under retrieval models, p.113)
2) a user’s need for standardized description has not been acknowledged in online systems, leading to a loss of familiarity for the user. Some areas in which standardization has been recommended include the following (p.113):
Display: divided into 2 categories- display of retrieved results (p. 114) and display of metadata in surrogate records (p.115)
Basic search queries: When approaching an unfamiliar information system, users must determine in which ways they can search. While some search types may be fairly typical among systems, the ways in which systems are indexed are anything but consistent (p.116).
Treatment of initial articles: Another example of the lack of consistency among systems is the handling of initial articles (a, an, the, and their equivalents in other languages) (p.117)
Use of Boolean operators, proximity, and truncation (p.118)
Punctuation: should punctuation be used for querying? if so, which punctuation? And what do different punctuation types mean? (p. 118)
federated searching
also known as meta-searching; the ability to search and retrieve results from multiple sources of information while using only a single, common interface; features an all-inclusive overlay (one- search box) to multiple systems, which may include catalogs, indexes, databases, and other electronic resources.
a downside to it: searching functionality is limited to the level of the lowest common denominator. That is, if very sophisticated searching is available in System A but not in System B, then the searching that can be done from the more sophisticated System A is limited to the searching allowable in System B. (p. 119)
user-centered design
there is disagreement on the definition of this
3 keys to it are:
observation and analysis of users at work
assistance from relevant aspects of design theory
iterative testing with users
some ideas for this include universal design; accounting for multiple languages and scripts; and a variety of other aids for users such as spell-check programs, providing explaining error messages for search results; help screens that explain the search process; standard stopword lists across systems
universal design
UD is one approach to user-centered design
it is a strategy that extends design to be as inclusive as possible; the practice of designing for all people, or as it is often defined, designing for barrier-free access, specifically with the intent of creating barrier-free access to . . . spaces for persons with a disability. (p. 120)
precision vs recall
precision: a measurement of how many of the documents retrieved are relevant; enhanced by the use of standardized forms of names
recall: a measurement of how many of the relevant documents in a system are actually retrieved; improved by the system of references created (p. 121)
ideally, you want high recall AND high precision
this is related to authority control; if authority work is consistent and thorough, it should help with precision and recall; an example of system linkage through authority control is found on page 122.
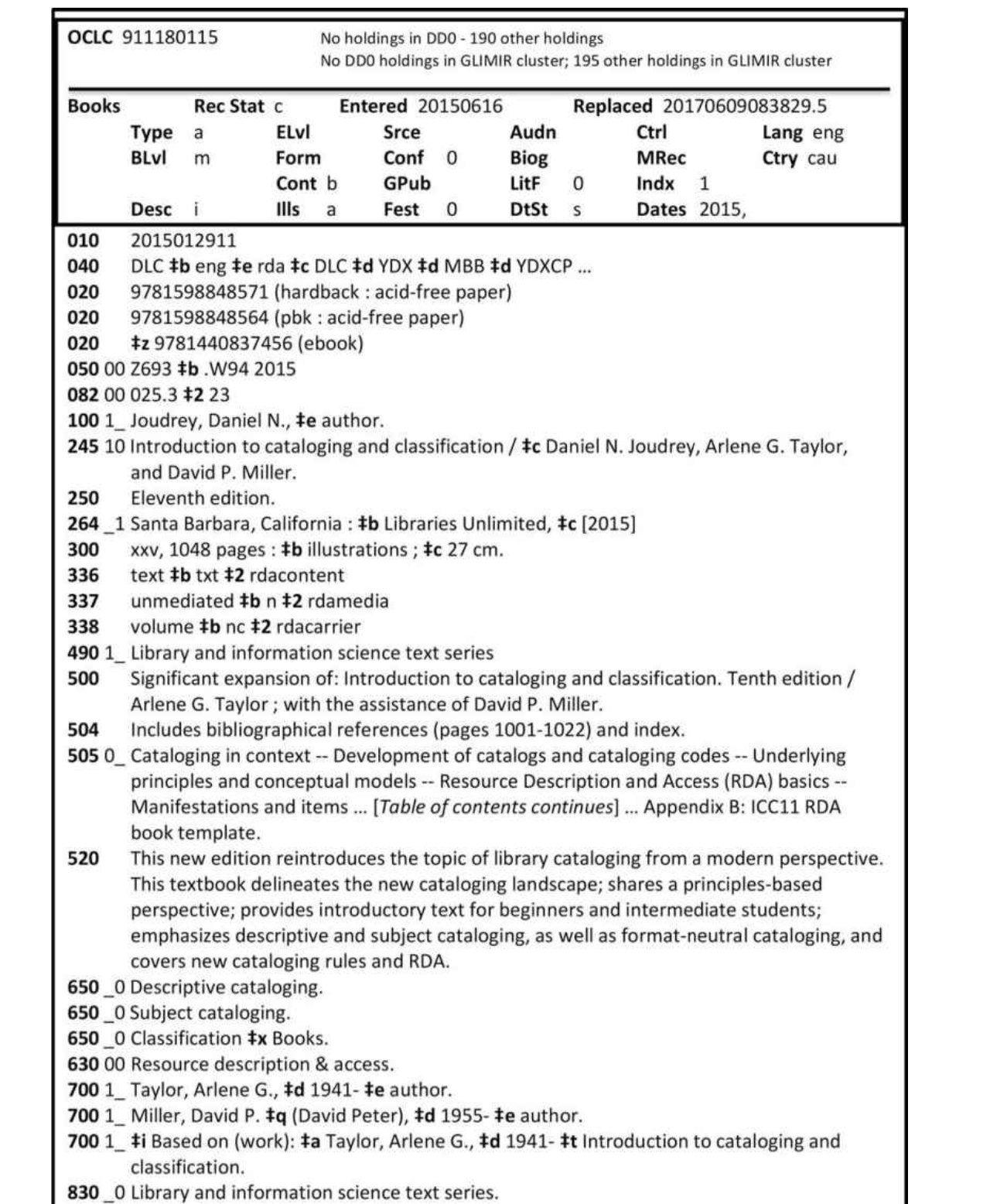
MARC
(machine readable cataloging)
encoding standard currently being used to create bibliographic records stored in most library catalogs; has been used in some museums and archives though
a standard that prescribes codes that precede and identify specific elements of a bibliography, authority, or holdings records allowing the record to be read by a machine. The machine then displays the data in a fashion designed to make the record intelligible to users.
comprises of a leader, a directory, and 2 types of variable fields (control fields and data fields)
strengths: its a mature standard, is well understood and well tested, has been adopted by libraries around the world, millions of records have been created with it and have been available though bibliographic networks and is the established format for ILS
weaknesses: unknown outside libraries, which limits ability of non-MARC information institution to use bibliographic data created by libraries; has size limitations and cannot convert hierarchical or complex relationship among entities
meta-language
a markup language for creating markup languages; a set of rules for designing markup languages (SGML developed as one for encoding electronic texts)
encoding standards vs content standards
processes that are entwined
encoding standards/syntax act as a container that holds the metadata content
content standards direct the metadata content held by encoding standards;
the same content can be encoded with a number of different standards;
Note: The metadata content held in the container may be guided by a separate descriptive standard, or in a few rare cases, by the encoding standard itself. For example, the metadata entered into a MARC record is usually controlled by outside descriptive cataloging rules (e.g., RDA: Resource Description & Access), by the conventions of a thesaurus (e.g., Library of Congress Subject Headings), and by the rules of a classification scheme (e.g., Dewey Decimal Classification); there are, however, some MARC 21 fields for which the rules for content appear only in the MARC 21 standard itself (e.g., the MARC 21 field 007 gives specific codes for certain materials, such as microforms or motion pictures). p. 174
encoding of characters
Each letter of an alphabet, each numeral, and each symbol in every language that exists has to be represented by a code, because, fundamentally, computers just deal with numbers. They store letters and other characters by assigning a code to each one.
the International Organization for Standardization (ISO) created the first standardized character set with the purpose of including all characters in all written languages of the world (including all mathematical and other symbols)- was called Universal Coded Character Set (UCS)
Unicode was created as an American industry counterpart
unicode
an American industry counterpart to UCS, which permits computers to be able to handle the large number of characters sets used in various languages
its aim is to embrace 3 characteristics: universality (covering all modern written languages); uniqueness (no duplication of characters even if they appear in more than one language); uniformity (each character being the same length in bits) p. 175
syntax
the arrangement of parts of elements so that they become constituents of a connected or orderly systems; metadata’s syntax is described by its encoding schema (e.g. MARC, XML), just as a languages syntax is described by its grammar;
how metadata records and statements are encoded in electronic form- by assigning tags, numbers, letters, or words (codes) to discrete pieces of information in the description p. 175
fields/elements
an individual category of field that holds an individual piece of description of a resource; typical metadata elements include title, creator, creation date, subject, etc.; individual parts of the metadata
encoding and its purposes
using a record syntax or a coding scheme to make metadata electronically accessible; ensures that metadata is structured logically and that it may be communicated, shared, and displayed easily
entails the setting off of each part of a record (or each metadata statement) so that
each of the parts can be identified clearly
the parts of statements may be displayed in certain positions according to the wishes of those creating the display mechanism
certain parts of a record can be searchable (p. 175)
also allows many languages and scripts to be displayed and search in the same file and is used for the transmission of data
leader
one component of the MARC format; identifies the beginning of a new record and provides coded information for record processing;
its fixed in length and contains 24 alphanumeric characters that identify things like record length, record status, character-coding scheme (UCS/Unicode), encoding level, and the kind of info resource being described (p. 176_

directory
a component of a MARC record contains a series of 12-character fixed length segments that identify the field tag, length, and stating position of each data field in the record p. 177
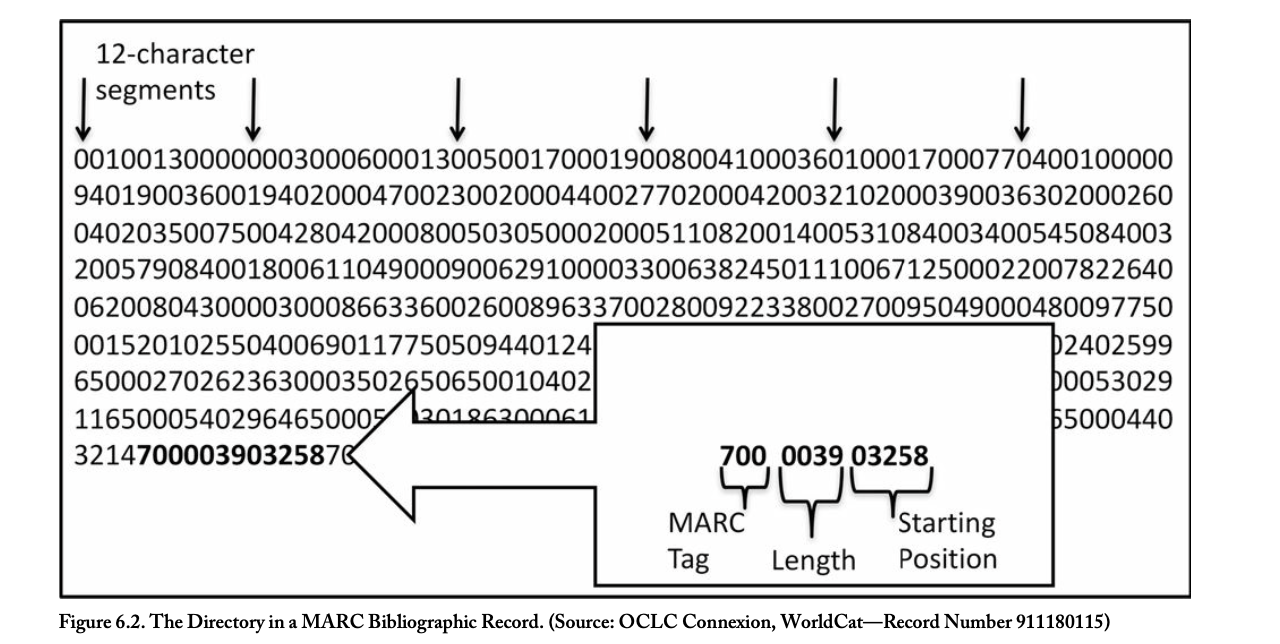
the two types of variable fields of MARC format
variable control fields: carry alphanumeric data elements; used for processing machine-readable bibliographic records; in MARC 21, these field tags begin with 2 zeros (00X fields); used for data like fixed-length descriptive data, LC control numbers, and codes for data and time of latest transaction
variable data fields: carry alphanumeric data of variable length; contain traditional cataloging data but can also carry info such as playing time, URLS. and linking entries; they often have several subfield to achieve greater granularity in encoding; (e.g. 020 for ISBNs, 082 for DDC #s, 100 for primary creator, 500 for general notes, etc.); they are made up of tags, indicators, and subfield codes (p. 177-178)
tags: 3 digit 3s (001-999) that designate the kind of content that will be entered into the field
indictors: 2 character positions following a tag; contain coded information interpreting or supplementing the data in the field
subfield code: consists of a delimiter and a letter or number; to introduce greater level of granularity to MARC encoding by identifying elements in a field that might require separate treatment (delimiter- unique character that indicate beginning of a subfield; data element identifies (letter or #) species content found in subfield ep. 182
177-178
MARC 21
a MARC standard agreed upon by Canadian and U.s. representations; represents a consolidation of USMARC and CAN/MARC; has been adopted by many other countries though
has 5 formats for different types of data (bibliographic format, authority format, community information format, holdings format, classification data format, p. 184)
UNIMARC
Universal MARC; meant to act as a vehicle for interchange of MARC records between national bibliographic agencies; At first it was thought that it would act only as a conversion format. In this capacity, it requires that each national agency create a translator to change records from UNIMARC to the particular national format and vice versa. When a translator is in place, records can be converted to UNIMARC to be sent to other countries, and records received from other countries can be translated from UNIMARC to the national format. In addition to this use, a few national agencies that did not already have a MARC format have adopted UNIMARC as the standard in their countries. (p. 184)
SGML
standard generalized markup language; an international standard for document markup for machine readability; its a meta-language and a set of guidelines for designing hardware-independent markup languages. Markup languages describe the structures of documents so that documents may be interchanged across computer platforms (p. 184-185)
does not contain predefined set of tags that can be used to mark up documents like MARC does; allows documents to be represented in such a way that the document structure (coding that says this piece of text is a title, etc.) may be identified independently from the content.
defines data in terms of entities, elements, and attributes
prescribes markup that consists of delimiters defined symbols (e.g., <, >, </, ''), and are used to construct tags, and tags (<author> is a tag). Tags usually appear before and after an element. For example, if an element (such as an author’s name) is to be coded, then that name is placed between two tags identifying the type of element:<author>Edward Gaynor</author>
because it does not contain a prescribed set of tags, it requires some form of structure to be provided through a particular application or through a DTD (an sgml or xml application; defines the structure of a particular type of document) at the beginning of a document (p. 186)
very complex and lengthy programming though
HTML and XML are derivatives
entity vs element vs attribute
as used in SGML;
entity: a thing to be encoded (a document, a part of a document, a surrogate record, etc.)
element: a particular component in the entity, such as a title, chapter title, section heading, paragraph, classification #, etc. Tags usually appear before and after an element. <author>Edward Gaynor</author>
attribute: provides particular information about an element (the type of place, the language used in the element); delimited by using quotation marks (''. . .'' or '. . .').
p. 185
HTML
hypertext markup language; developed for the creation of web pages; a basic markup language that allows almost anyone to be a web author. It defines the content, the layout, and the formatting of web documents. It provides for creation of a simple structure, enables display of images, and provides for establishment of links between documents.
Document-centric standard for web resources - Hypertext Markup Language; code that helps make the data found within websites more meaningful to search engines and web crawlers (31); a scheme for encoding text, pictures, and the like so they can be displayed using various programs as the coding is entirely made of ASCII text
it is possible to encode rudimentary metadata; it was rare to find metadata encoded in HTML, but major search engines are beginning to trust metadata annotations that are being embedded within the HTML coding of web docs
has been criticized as being too simplistic b/c it focuses on display aspects and was not good at representing complex doc structures (186-188)

XML
extensible markup language; a subset of SGML designed specifically for web documents that omits some features of SGML and indulges a few additional features (a method for reading non-ASCII text); allows designers to create their own customized tags, thus overcoming many of the limitations of HTML; focuses on structural markup and leaves issues of display to style sheets instead.
uses the same components of SGML: entities, elements, attributes, but does not require a DTD; there is an alternative to DTD known as an XML schema, which are richer forms of DTDs
DTD
document type definition; an XML or SGML application that defines, with its own notation, the structure of a particular type of document. It gives advance notice of what names and structures can be used in a particular document
type, so that all documents that belong to a particular type will be alike. It could be thought of as a template particular type of document. Typically, the following are defined in a DTD:
the elements that might be part of that particular document type
element names and whether they are repeatable
the contents of elements (in a general way, not specifically)
what can be omitted
tag attributes and default values
names of permissible entities (p. 189)

XML schema
a richer form of a DTD; an alternative to a DTD; provides definition and structure to XML documents. It outlines the constraints of XML documents and provides a mechanism for their validation by identifying approved elements and attributes, the number and order of elements, data types, and some values.
is expressed in XML syntax (unlike a DTD) and follows XML rules so developers don’t have to learn another notation
an XML schema defines:
elements and attributes that can appear in a document
parent-child relationships among elements
the order and number of child elements
whether an element is empty or can include text
data types for elements and attributes
default and fixed values for elements and attributes (p. 189)
there are many XML schemas that have been created and are in general use: TEI schema (for encoding literary texts), EAD schema (encoding archival finding aids), ONIX DTD and schema (encoding publishers records), MARCXML Schema and MODS (encoding MARC 21 records in XML) p. 190


TEI Schema
text encoding initiative; has evolved in an XML schema; created to overcome the difficulty of having multiple encoding schemes being used to encode old, literary, and/or scholarly texts.
intended to mark up a wide variety of materials for numerous user communities. By necessity, the set of tags included in the schema must be large, and may be considered unwieldy to some. (p. 190).
To facilitate the ease of use of TEI, the consortium has designed particular customizations (i.e., subsets of the schema). These include tag sets specially designed for speech representations, dramas, manuscripts, journal articles, and the like.
One particular component of TEI is of special interest to those who organize information: the TEI Header.
It provides descriptive metadata about the electronic version of the resource encoded in the TEI document and the original source document, as well as administrative metadata about the encoding process, revisions, and so on.
The TEI Header has five sections, only one of which is required.
file description (required), encoding description, text profile, container element, revision history (p. 244)

EAD Schema
Encoded Archival Description Schema; an XML schema created specifically to encode finding aids; provides the structure of an archival finding aid and defines its data components; used in archives and libraries; eases the ability to exchange finding aids among institutions and allows users to find out about collections in distant places. photo shows the minimum set of EAD tags required for an online finding aid
Its design principles state: “EAD is a data structure and not a data content standard. It does not prescribe how one formulates the data that appears in any given data element—that is the role of external national or international data content standard
EAD does not need to contain prescriptions for content. However, it has a header section that was originally based on the TEI Header (see below). The header contains metadata about the creation and maintenance of the EAD document itself.
creation of EAD3 is driven by four principles:
“Achieving greater conceptual and semantic consistency in the use of EAD.”
“Exploring mechanisms whereby EAD-encoded information might more seamlessly and effectively connect with, exchange, or incorporate data maintained according to other protocols.”
“Improving the functionality of EAD for representing descriptive information created in international and particularly in multilingual environments.”
“Being mindful that a new version will affect current users.” (p. 243)

ONIX DTD and Schema
Online Information Exchange; the book industry standard for representing and communicating product information in an electronic format; designed to carry the kind of information traditionally carried on jacket covers and optionally, also to carry excepts, book reviews, cover images, author photos, etc. (p. 193)
a family of standard XML formats that publishers and others in the book trade can use to distribute ONIX messages—electronic information about their books, serials, and other publications. An ONIX message contains both (1) a header that contains information about the sender, addressee, and administrative metadata, and (2) a product record that contains information about the resource being described. The product record may contain six blocks of data: product description, marketing collateral detail, content detail, publishing detail, related material, product supply
It includes a data dictionary that defines the content of the elements. The elements allow a publisher to present online the information that was previously contained on book jackets and in publishing brochures and catalogs—information such as synopses, quotations from reviews, author biographies, intended audience, and so on. (p.248)
MARCXML Schema and MODS
The MARCXML Schema supports XML markup of full MARC 21 records, featuring lossless conversion to and from MARC 21 records, a conversion toolkit, and style sheets. It simply duplicates the MARC content designation structure in a native XML encoding format. (p.197)
MODS: an XML schema that is intended to be able to carry selected data from existing MARC 21 records in an XML environment. It is also used to create original metadata records. It includes a subset of MARC fields and uses language-based tags rather than numeric ones (e.g., <title> is used rather than 245). In some cases there has been a regrouping of elements from the MARC 21 bibliographic format. Because it is only a subset of MARC, after records have been converted to MODS, the MODS records cannot be converted back to MARC 21 records without a loss of data.
BIBFRAME
bibliographic framework initiative; a project stated by LC to provide a replacement for MARC as the primary encoding standard for library-generated metadata. Based on linked data principles; replaces self-contained bibliographic and authority records with authoritative statements about resource- statement that are encoded for use in the Semantic Web
intended to move library metadata from the record-bound MARC structure to RDF-based individual metadata statements that are not confined to a catalog.
also designed to continue the basic MARC functions of “representation and communication of bibliographic and related information in machine-readable form. BIBFRAME Vocabulary has a defined set of classes (groups of things or entities) and properties (relationships or attributes) to describe bibliographic resources. The BIBFRAME Vocabulary, at this writing, comprises over 60 classes or subclasses
comprises 3 main high-level entities: work, instance, and item (p. 201)

3 parts of creating metadata for an information resource
providing a description of the resource along with other info necessary for the management, preservation, and structure of the resource
providing access to this description
providing the syntax of the metadata (i.e. encoding) p. 207
metadata statement
a standalone description of a single attribute of a resource. (p. 207)
<dc:title>Cataloging and Acquisitions Home</dc:title>