Lecture 14: the role of negative information in distributional semantic learning
1/35
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
36 Terms
why do we try to integrate other types of information in distributional models?
it’s related to how humans use language and how it’s applied in the perpetual world
it’s how we use language but also how it’s applied to the perceptual world
language isn’t only cognitive, we use to to navigate the social environment
define the “user” extra-linguistic information
who produced the reddit comment
define “discourse” extra-linguistic information
in what subreddit the comment was produced in
what are the extra-linguistic information that can be extracted from reddit? (2)
user: who produced the comment
discourse: in what subreddit it was produced in
define “usage based theory”
kids don’t have sophisticated language processing abilities from abstract rules
they are sensitive to social information and pay attention to people around them
kids will mimic how others use language
why is reddit a popular choice when trying to get textual information from someone?
it provides all the comments made by a user, but also the social context it was made in (which subreddit) → helps us understand how communication plays a role in the large social scale
true or false: all models use sentences as a linguistic context
true: usually due to the model’s requirements
what is the problem with using sentences as a linguistic context when training a model?
it works well for models, but that’s not how human condition words: we don’t store information as sentences
define “ecological validity”
extent to which the findings of a research can be generalized to real-life naturalistic settings
define “word frequency”
the amount of time each word happens in a corpus
how is our language system organized?
as we process things more and more, there is some processing in our brain that makes something more represented easier to access
meaning, the cognitive system is adapted to the environment based on the frequency of word usage
we organize language usage based on how often we need to communicate with certain people
define “user contextual diversity” (UCD)
number of people who used a word across reddit
define “discourse contextual diversity”
number of subreddits a word was used in
what’s the difference between user contextual diversity and discourse contextual diversity?
user: number of people who used a word
discourse: number of subreddits a word was used in
*based on the idea that communication and language organization are social
in user contextual diversity, what does a word used commonly used across multiple users signify?
when you start interacting with someone new, you will likely need to use or process that word
*user contextual diversity: number of subreddits a word was used in
according to UCD, how do we organize linguistic information?
not with language itself, but according to the environment it was used in
what are the different forms of model? (3)
WW: word x word model
UD: user x discourse model
column = user
word count for a word = number of subreddits a user produces the word in
DU: discourse - user model
column = discourse
one element = number of users who produced a word in that subreddit
define “UD model”
word x word model
define “UD model”
UD: user x discourse model
column = user
word count for a word = number of subreddits a user produces the word in
define the “DU model”
DU: discourse - user model
column = discourse
one element = number of users who produced a word in that subreddit
true or false: the WW, UD and DU models were all trained on different corpora
false: it was the same corpora, but organized differently
WW: trained on sentences
UD: corpus organized by users
DU: corpus organized by discourses
[UD/DU] worked better than [UD/DU]
UD better than DU
true or false: when we build models, social information is negligible
false: it’s important
why do we need optimization?
when we have to do parameter settings, we need to have a model that will best fit with the data → optimization
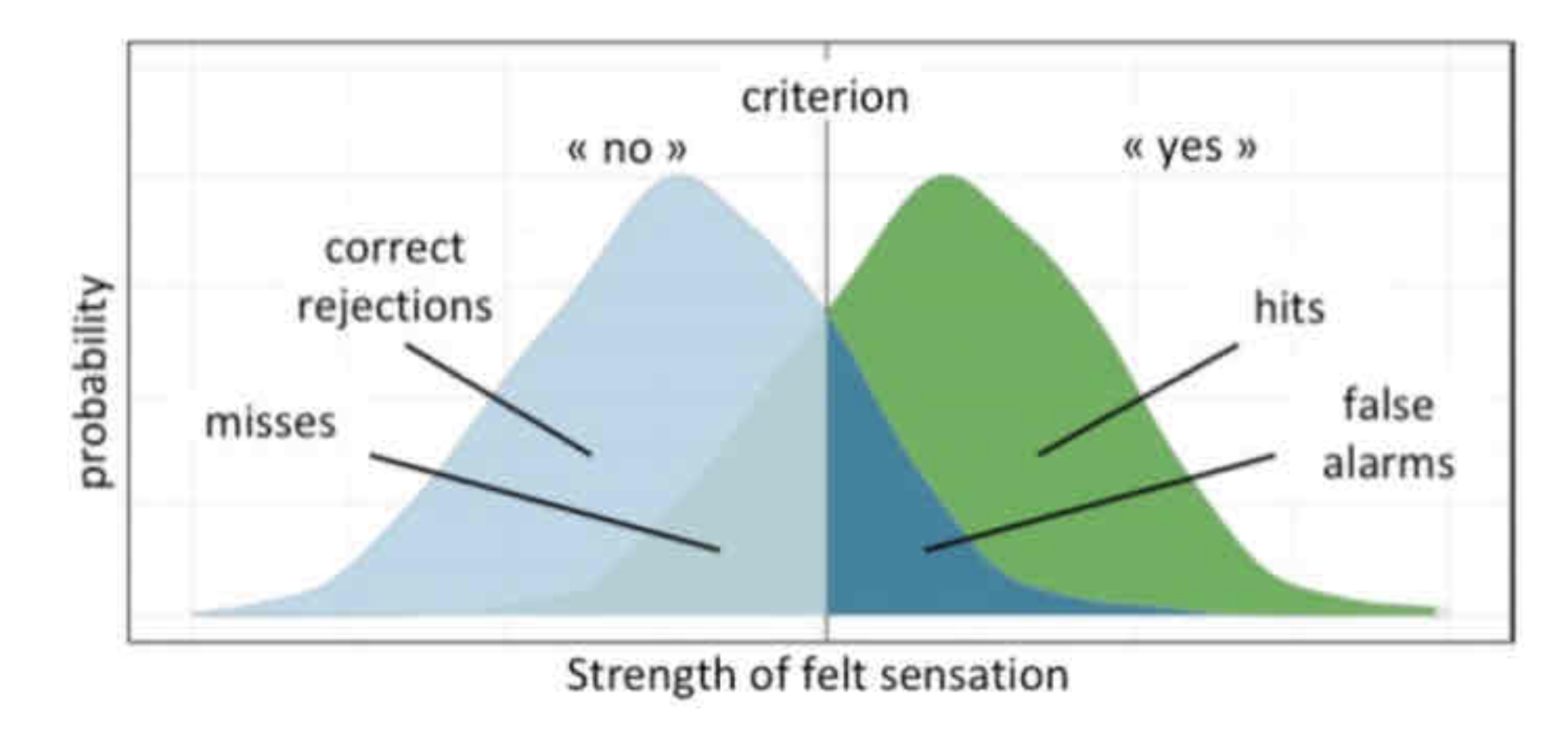
explain how the signal detection theory works
there are two distributions:
green: there is a stimulus
if the sensation/memory is above the criterion, the person felt/remember the stimulus
hits: there was something and the person detected it
misses: there was something and the person did not detect it
blue: there is no stimulus
if the sensation/memory is below the criterion, the person will say they did not feel/remember the stimulus
false alarms: there was no stimulus and the person “detected” it
correct rejection: there was no stimulus and the person did not detect it
criterion = beta
explain the grid search optimization algorithm
test every possible combination of the parameters your have
measures the fit of model: red area is a better fit than blue
best way to optimization because you find the best settings
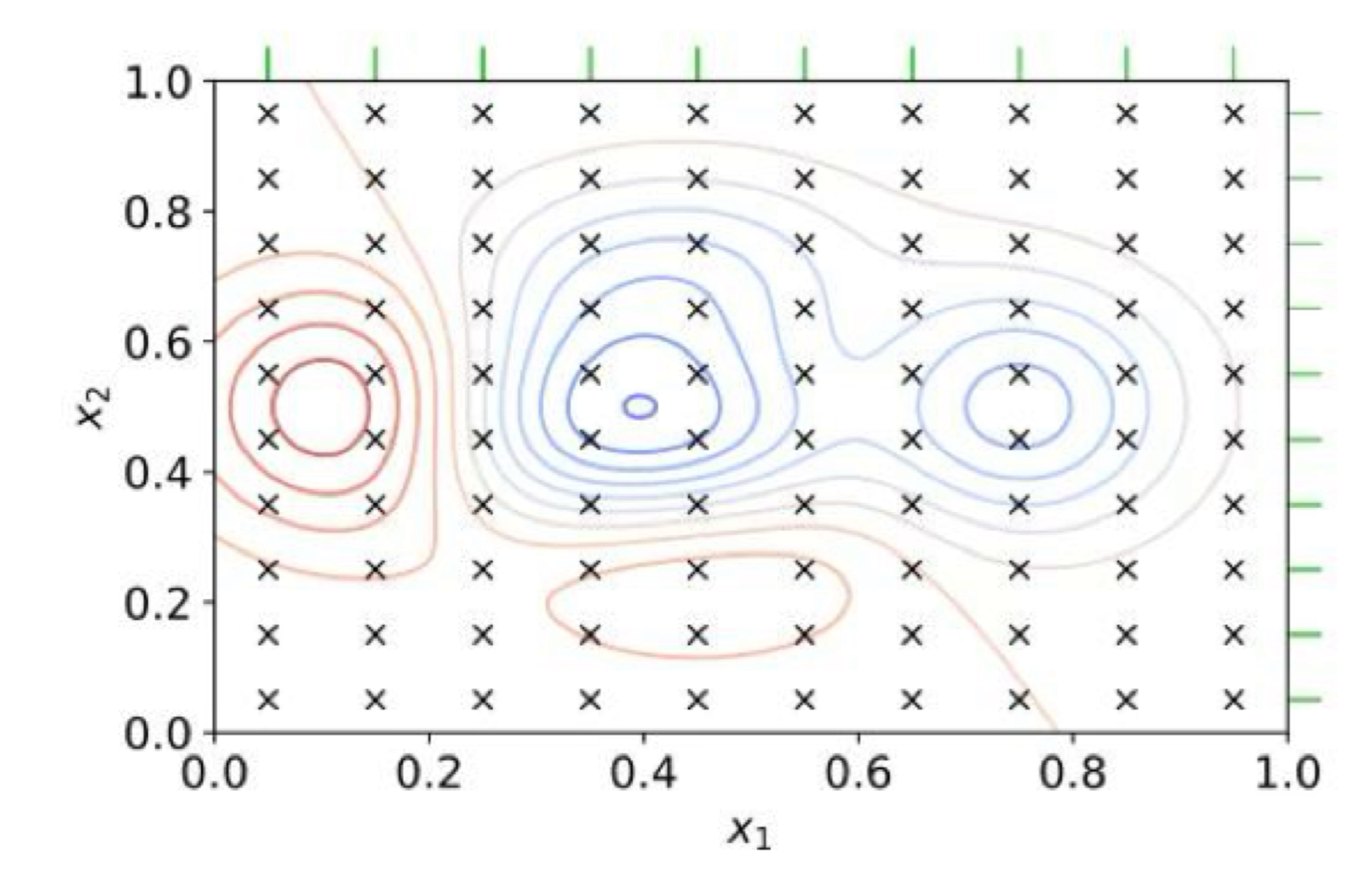
when can you not do a grid search optimization?
it only works with a small amount of parameters: with too many parameters, it can become uncomputable
explain how drift diffusion models work
you have a starting parameter and you will drift towards a yes or a no response
non-decision time: cognitive processing before making the decision
drift rate/evidence accumulation: you have some process by which you are floating towards a yes or no decision based on environmental information
there is a threshold/boundary: where you need to drift to make a decision
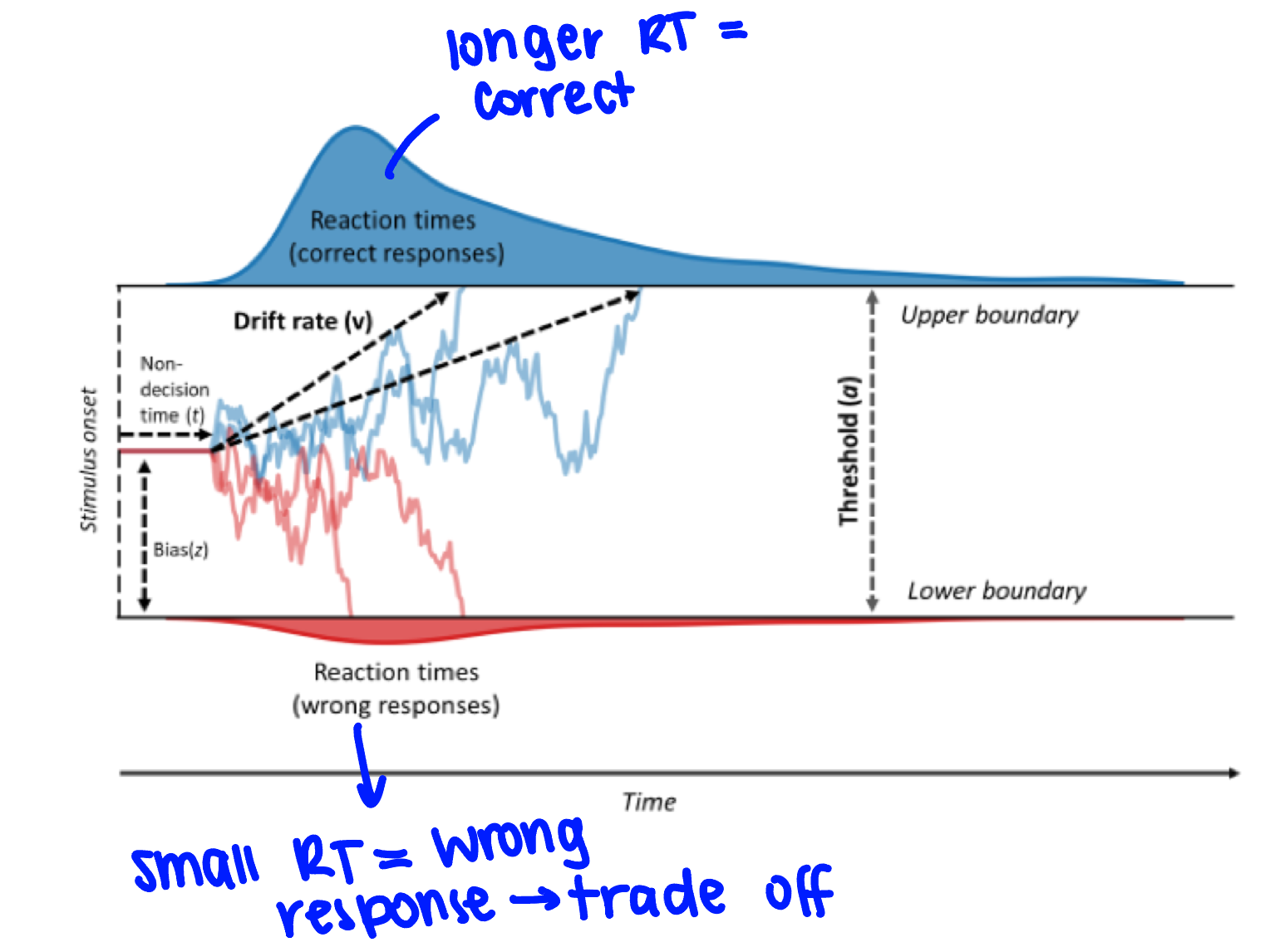
what do drift diffusion models measure?
reaction time when making a decision
*pretty powerful, can explain a lot of data
what’s the problem with drift diffusion models? (2)
it requires a lot of computations (parameters)
bias factors: in some tasks, you are more likely to say yes or no
how does the simplex algorithm work?
it’s a sample of the parameter space
at first, it will test random parameters on the sample and find the area that seem to work best
it will then sample around that position
it will then go down to smaller spaces until it finds the best fitting setting
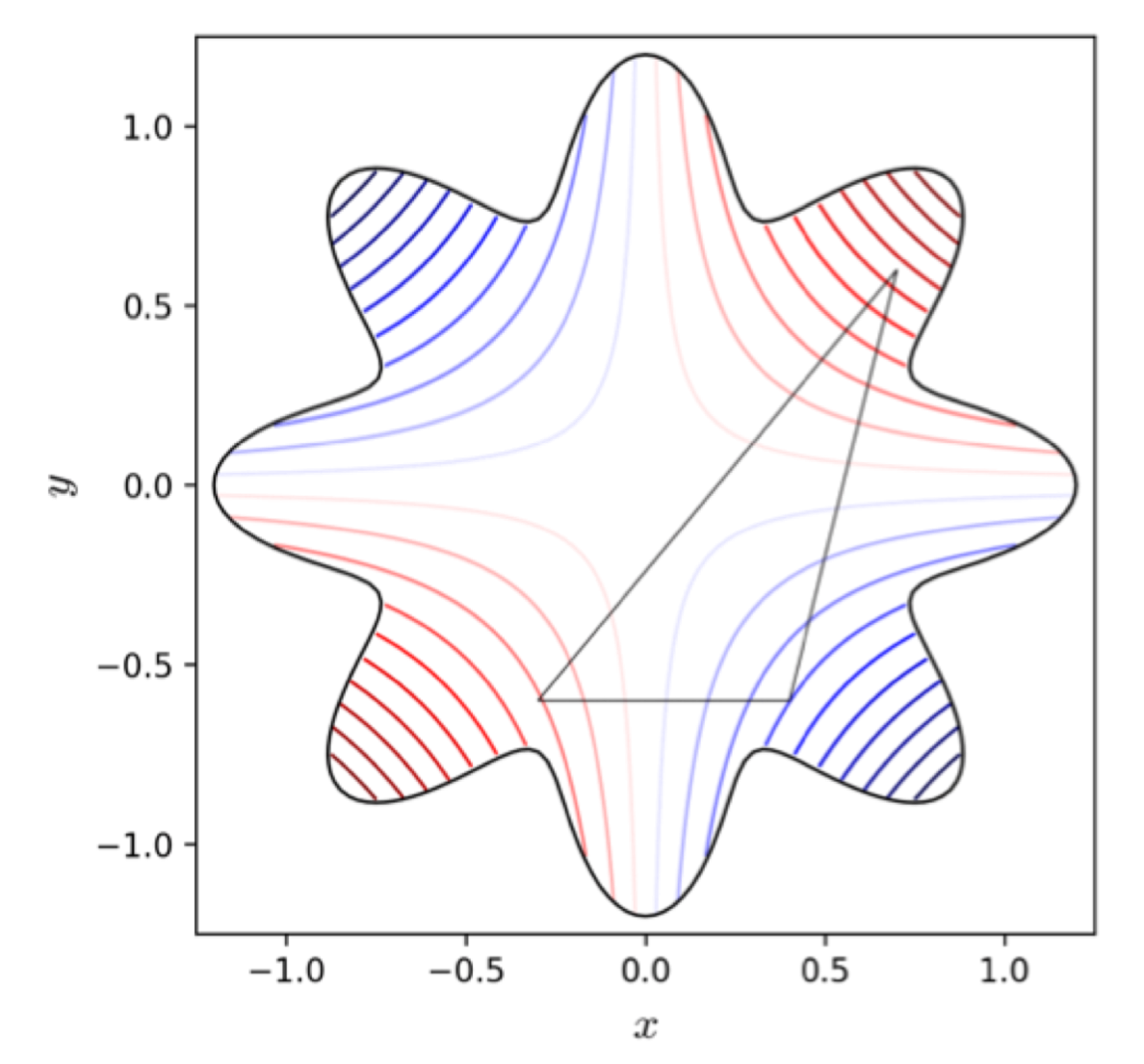
what’s a problem encountered with the simplex algorithm?
when there are local maxima: it will sample at the local maxima but forget about the global
true or false: the simplex optimizing function can be applied to all problems
false: some of them don’t have a deterministic space
*ex: drift diffusion models are not deterministic because they have no predictable path
what’s the efficient form of a grid search? explain it
random search optimization/genetic algorithms
you start with different models with different settings
you select the most fir and they will breed with each other
the selected or produced models are the next generation
you evaluate their fit and select the best performing
(there can be some slight randomness)
you will find a solution without needing all the parameters combination
true or false: backpropagation is an optimization algorithm
true: this means that LLM (large language models) and word2vec are optimized (to some extent)
what is needed in the parameter space of a BEAGLE? (3)
vector dimensionality
n-gram size window
vocabulary size