Chapter 11: How to make predictions with a multiple regression model
1/8
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
9 Terms
Refer to the cars DataFrame. This code gets dummy variables for the list of categorical variables called catCols:
a. pd.get_dummies(cars[catCols])
b. pd.getdummies(cars[catCols])
c. pd.get_dummies(cars[[catCols]])
d. cars.get_dummies(catCols)
a. pd.get_dummies(cars[catCols])
Refer to the cars DataFrame. This is a categorical variable:
a. horsepower
b. citympg
c fueltype
d. car_ID
c fueltype
These are all types of categorical variables:
a. ordinal, nominal, continous
b. nominal, ordinal, discrete
c. nominal, ordinal, dichotomous
d. ordinal, continous, dichotomous
c. nominal, ordinal, dichotomous
Refer to the cars DataFrame. This code creates a multiple regression model with two independent variables:
a. x_train, x_test, y_train, y_test = train_test_split(
cars[['enginesize','horsepower']], cars[['price']],
test_size=0.20)
model = LinearRegression()
model.fit(x_train, y_train)
b. x_train, x_test, y_train, y_test = train_test_split(
cars.drop(columns=['price']), cars[['price']],
test_size=0.20)
model = LinearRegression()
model.fit(x_test, y_test)
c. x_train, x_test, y_train, y_test = train_test_split(
cars[['price']], cars[['enginesize','horsepower']],
test_size=0.20)
model = LinearRegression()
model.fit(x_test, y_test)
d. x_train, x_test, y_train, y_test = \
cars.train_test_split(['enginesize','horsepower'],
'price', test_size=0.20)
model = LinearRegression()
model.fit(x_train, y_train)
a. x_train, x_test, y_train, y_test = train_test_split(
cars[['enginesize','horsepower']], cars[['price']],
test_size=0.20)
model = LinearRegression()
model.fit(x_train, y_train)
Based on this chart, the best number of features to use in the multiple regression is
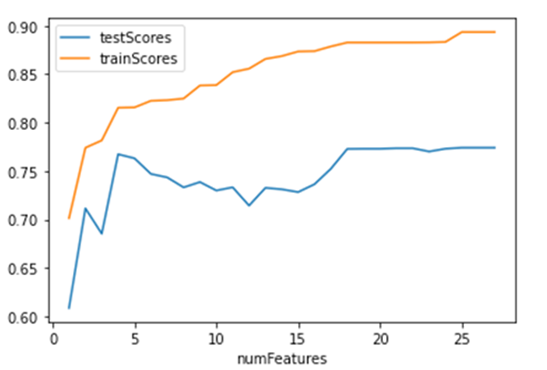
a. 10
b. 4
c. 18
d. 26
b. 4
When you prepare data for a regression model, you need to rescale
a. only the dummy columns
b. all columns
c. all columns except for the dependent variable and the dummy columns
d. all columns except for the dependent variable
c. all columns except for the dependent variable and the dummy columns
This code uses a feature selector to select the top 10 features:
a. FeatureSelector(score_func=mutual_info_regression, k=10)
b. SelectKBest(score_func=mutual_info_regression)
c. FeatureSelector(num_features=10)
d. SelectKBest(score_func=mutual_info_regression, k=10)
d. SelectKBest(score_func=mutual_info_regression, k=10)
Refer to the cars DataFrame. This code rescales the data. Assume the numeric columns are stored in a variable call numCols.
a. scaler = StandardScaler()
cars[numCols] = scaler.fit_transform(cars[numCols])
b. cars.rescale(numCols, inplace=True)
c. scaler = StandardScaler()
cars[numCols] = scaler.fit(cars[numCols])
d. cars[numCols] = pd.rescale(cars[numCols])
a. scaler = StandardScaler()
cars[numCols] = scaler.fit_transform(cars[numCols])
To select the right number of variables, you should
a. choose the number of variables that gives the highest score
b. use a for loop and a feature selector to choose the highest score that doesn’t overfit
c. use the top 10% of variables based on r-value
b. use a for loop and a feature selector to choose the highest score that doesn’t overfit