L3_Computer Vision and the concept of layers
1/21
Earn XP
Description and Tags
Flashcards based on Deep Learning Lecture 3 - Computer Vision and the Concepts of Layers
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
22 Terms
What is the point of deep learning?
Deep learning aims to automatically discover intricate features from data, enabling the modeling of complex relationships. Think of it like learning to recognize a cat: instead of manually defining features like 'whiskers' or 'pointed ears,' deep learning algorithms automatically learn these features from many cat photos. Neural networks are the tools used to achieve this, capable of modeling complex patterns but requiring a vast amount of data, like showing the algorithm millions of cat photos to become an expert.
How does each node in a fully-connected feed-forward network compute an output?
Each node computes its output by weighing inputs, adding a bias, and applying an activation function. Imagine each node as a chef following a recipe: inputs are ingredients, weights are the amount of each ingredient, bias is a seasoning adjustment, and the activation function is the cooking process that transforms the ingredients into the final dish. The formula is y = f(\sum{i=1}^{n} wi x_i + b), where y is the output, x_i are the inputs, w_i are the weights, b is the bias, and f is the activation function.
What is a problem with treating every pixel as a feature in image classification?
Treating each pixel as a feature makes the system sensitive to changes in position or size (translation or dilation). Consider recognizing a face: if you only focus on pixel locations, a slight shift in the face's position would throw off the recognition. CNNs solve this by learning to recognize patterns that are consistent regardless of these changes.
What is convolution?
Convolution recognizes and localizes patterns using a kernel or filter. It is a fundamental operation involving sliding a filter over the input data to compute the dot product at each location. Envision it as using a magnifying glass to find specific shapes in an image. When the shape under the lens matches the lens's shape, the convolution produces a high value, indicating the shape's presence.
What happens to convolution with discrete data such as images?
With images, the convolution integral becomes a sum, involving a kernel and an image. The convolution slides the kernel over the image, summing the element-wise product between the kernel and the image. Think of it as overlaying a stencil (the kernel) on an image and calculating how well the colors align at each position.
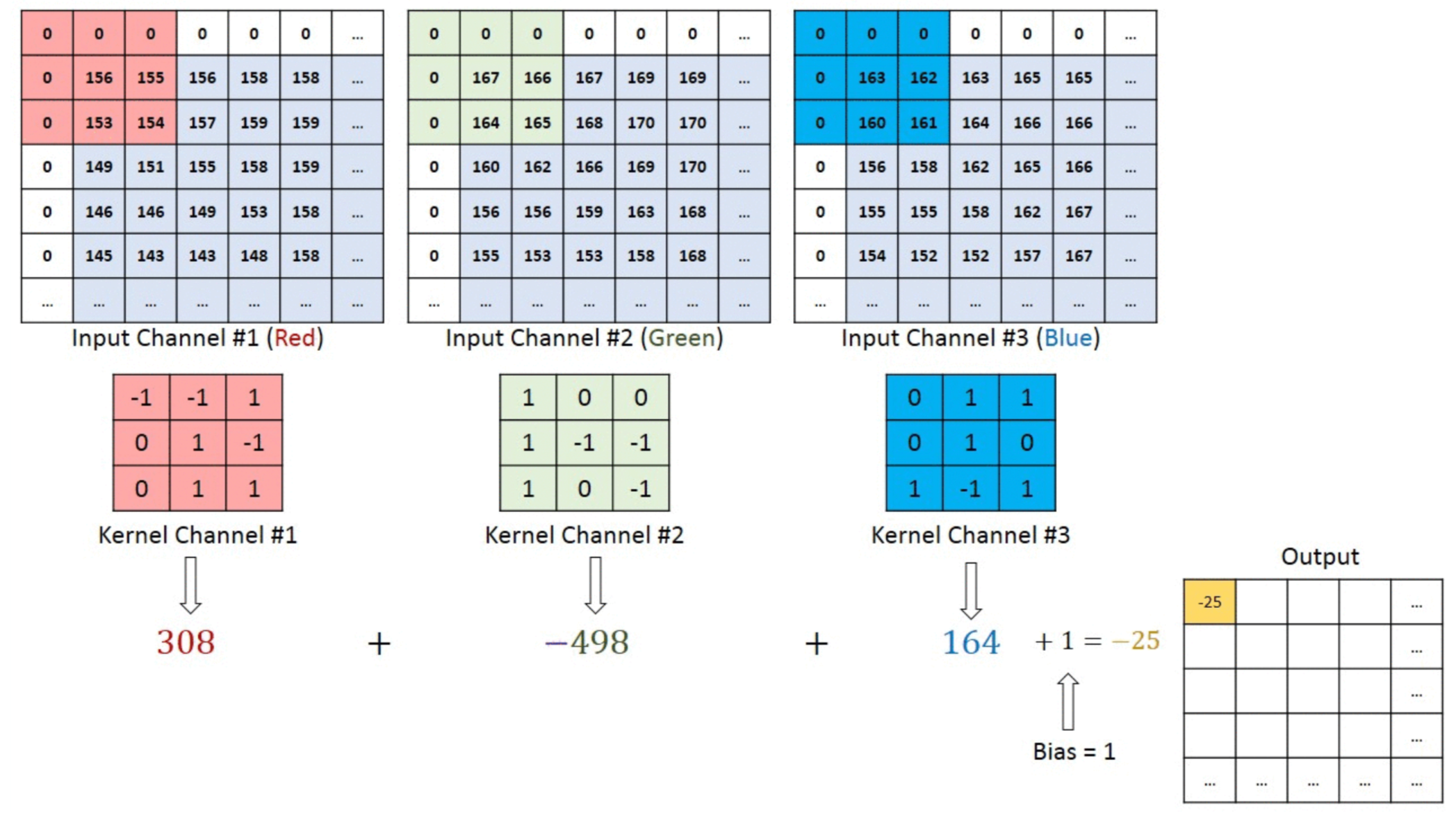
How is convolution performed over RGB color images?
Convolution over RGB images is done per color channel (Red, Green, and Blue), and the results are summed, extracting features from each color channel and combining them into a comprehensive feature map. Picture shining different colored lights on an object and combining the shadows to reveal its complete shape.
What is the core to digital image processing?
Convolution is key to image processing because it identifies features such as lines via predefined kernels. These kernels detect edges and other features by computing weighted sums. Think of it as using various stencils to highlight different aspects of an image, like edges or textures.
What is the effect of an average filter?
An average filter blurs images, smoothing out details. It's like gently blurring a photograph to soften harsh lines and reduce noise. It reduces the intensity variation between adjacent pixels.
What does a Sobel filter do?
A Sobel filter detects edges in images. It's like using a tool to trace the outlines of objects in a picture, highlighting where distinct shapes meet. It does this by approximating the gradient of the image intensity.

What is a better approach than trying to handcraft filters/kernels for image recognition?
Using multiple small, data-learned filters is better than handcrafting. It is like having a team of specialized detectives who automatically learn what clues to look for rather than relying on a single detective's assumptions. Instead of manually designing filters extract features from the images themselves.
What three layer types are needed for our proposed solution?
The solution needs Convolution layers for feature extraction, Pooling layers for downsampling, and Fully-connected layers for prediction. It's like a manufacturing process: Convolution extracts raw materials, Pooling refines materials, and Fully-connected assembles into a final product.
What is the purpose of Convolution layers?
Convolution layers extract image features. It is like having a series of lenses that each focus on different aspects of a scene, highlighting various details, such as edges, textures, and shapes. The 2D convolutional layer (Conv2D) is especially effective for processing images as it is designed to take 2D image data as input. The layer has a number of filters that travel across the image, extracting features and creating feature maps.
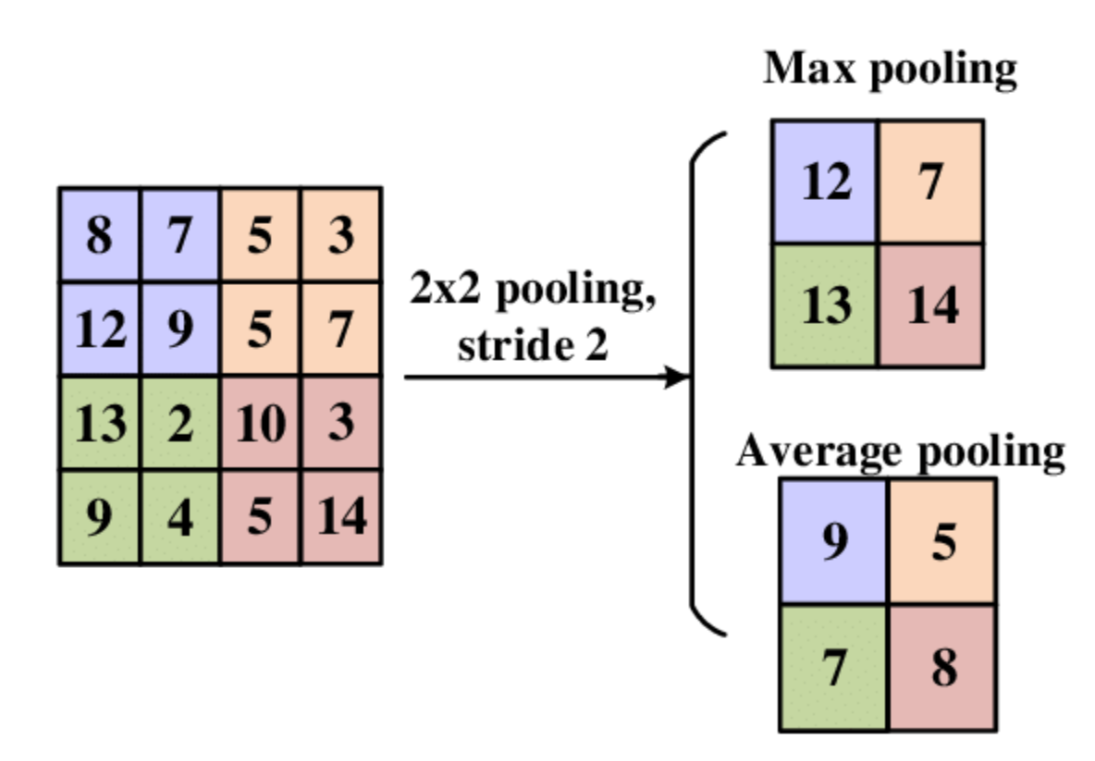
What is the purpose of Pooling layers?
Pooling layers downsample and aggregate features, reducing complexity and capturing essential information. Imagine zooming out on a map: you lose fine details but retain key landmarks, making the map easier to navigate. They reduce the spatial size of the representation to reduce the number of parameters and computation in the network.
What is the purpose of Fully-connected (dense) layers?
Fully-connected layers compute the final prediction. It’s like a decision-making body that weighs all the evidence to reach a conclusion based on extracted attributes after the features have been aggregated. Each neuron in a fully connected layer is connected to all neurons in the previous layer. These layers take the high-level features extracted by convolutional layers and pooling layers and use them to classify the input image. They apply weights to these features and combine them to produce a set of scores; these scores determine the likelihood of the image belonging to each class. The final layer typically uses a softmax activation function to output probabilities for each class.
In the Conv2D layer, what do filters refer to?
Filters in Conv2D are the number of feature detectors used (typically ranging from 32 to 512). Think of it as having multiple flashlights looking at different aspects of an object; each filter detects a specific pattern or feature in the input image.
In the Conv2D layer, what does kernel_size refer to?
Kernel_size is the filter's size (e.g., 3x3). The kernel determines the spatial extent of the filter. Think of it then as the size of the magnifying glass, how large of an area you are inspecting at any given time. It affects the receptive field of the convolutional layer.
In the Conv2D layer, what do strides refer to?
Strides determine how many pixels the filter moves (typically 1 or 2). Think of it as the size of steps that an observer is taking when scanning an image to find those features. A stride of 1 means the filter moves one pixel at a time, while a stride of 2 means it moves two pixels.
In the Conv2D layer, what does padding refer to?
Padding adds pixels around the image edges, like putting a frame around a photo. With padding, one can further control the output sizes of the feature maps. It helps in preserving the border information and controlling the spatial size of the output feature maps.
What are two reasons for downsampling the image features in Pooling layers?
Downsampling learns a spatial hierarchy and reduces parameters. Spatial hierarchy is like learning from broad outlines to fine details, while reducing parameters simplifies the model. It is like summarizing a book by outlining the most important features while leaving out the minutiae. It also helps in making the network translation invariant to some extent.
In the MaxPooling2D layer, what does pool_size refer to?
Pool_size is the pooling window's size (e.g., 2x2 or 3x3). This defines the zone where the maximum value is computed during pooling. Max Pooling is like taking the brightest point within different distinct regions of an image -- you're essentially taking only the most salient features and simplifying things further.
In the MaxPooling2D layer, what do strides refer to?
Strides are the step size used when the pooling window moves. The window is typically set to the pool_size, resulting in non-overlapping regions. The step size of a pooling window can be thought of like how big your footsteps are when you are summarizing that region of an image; it determines how much the pooling window shifts at each step.
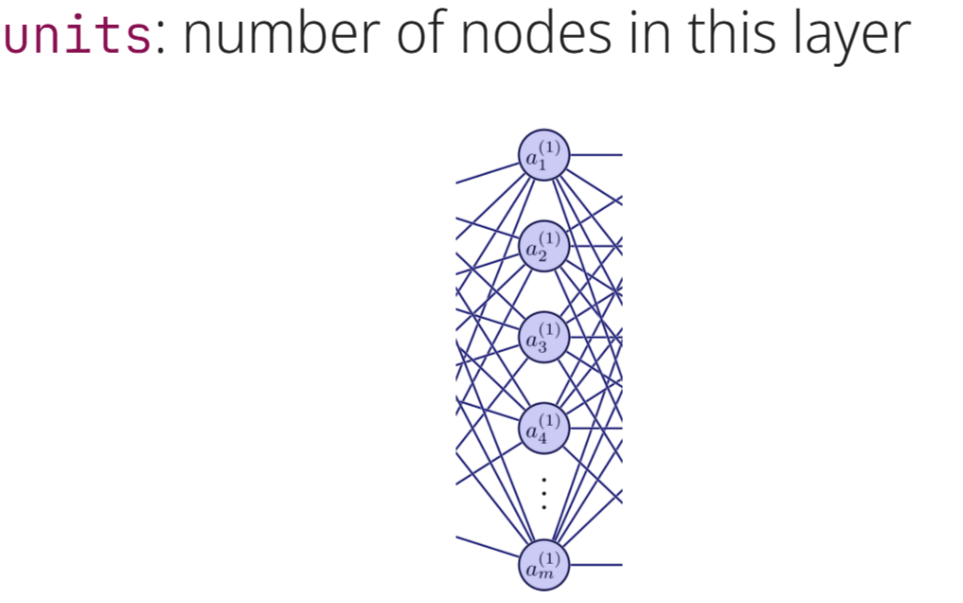
In the Dense layer, what do units refer to?
In the Dense layer, units are the number of nodes that can be found within the layer. Each one of the nodes is like a calculator, and the number of units determines the size and dimensionality of the ultimate product. The more nodes that are in the dense layer, the more complex relationships it can learn, and the more computation that is required.