Database Systems
1/67
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
68 Terms
Function
a relation mapping from input value to specific output value, each input = exactly one output.
Relation
between 2 sets, form collection of ordered pairs.
Relational model concerned with
Data structure - table, column
Data Integrity - null, ref intg
Data Manipulation - rel algebra.
Rel model goals:
data independence - allow changes without affecting the application using it
Control redundancy - not stored in multiple places.
consistency - copies r same, accurate, Utd.
Relational scheme
textual rep of data model
Domain
Set of possible values a column can take
Candidate key
min set of columns unique identifies each row.
primary key
chosen cand key to uniquely identify each row
alternate key
remaining cand keys (also referred as alt keys)
foreign key
column(s) matching candidate key of associate table
composite key
refers to key consisting of 2+ columns
Null Values
required to deal with missing information
Why do we use it – to express an unknow value while completing the database/relation, you cannot save a database with an empty, unpopulated area
You need to complete all entries before you can save your work – therefore we use the null values
•Entity integrity rule: constraint on primary keys

◦Value of a primary key must be unique and
◦not null

•Referential integrity rule: constraint on foreign keys

◦The value of a foreign key must either match the candidate key it refers to
◦or be null

Entity
•An entity represents a group of objects of interest with the same characteristics.

Attributes
•Attributes refer to properties of an entity or a relationship.

Attribute types
•Single-valued
◦Attribute contains a single value for each instance of an entity
◦E.g., date_of_birth
•Multi-valued
◦Attribute may contain more than one value for an entity instance
◦E.g., hobby, telephone number
•Derived
◦Attribute may be derived from other attribute(s)
◦E.g., age is derived from date of birth.

Types of abstraction
•The following types of abstractions are the building blocks for all data models:
◦Classification (grouping concepts) ß done
◦Aggregation (composing)
◦Specialisation/generalisation (hierarchy) ß we are interested in this next

Degree
•The degree of a relationship is the number of participating entities in the relationship.
•
•Degree Types
◦Unary (or recursive)
◦Binary
◦N-ary
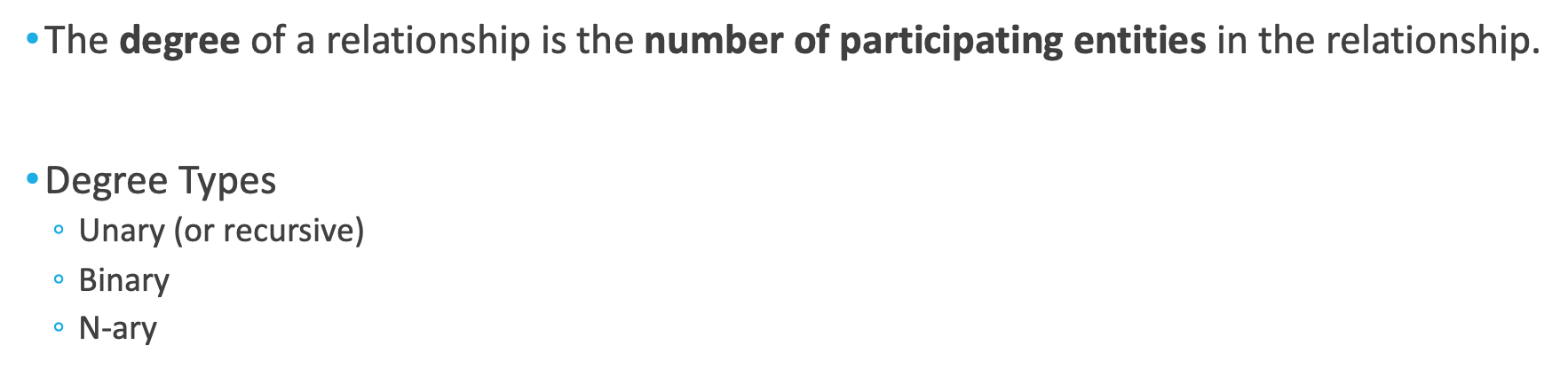
why cant many to many be modelled?
•In a relational model, attribute values are atomic values.
◦That is, one value for each column for a row in a table.
◦More on this when we look at normalisation.
•For many-to-many relationships, we would need multi-valued attributes.
◦This is only possible in a conceptual data model.

how to resolve many to many rel
•In a relational model, a many-to-many relationship is resolved (modelled) by:
◦Introducing an association entity.
◦Replace with two one-to-many relationships.
•For the new association entity:
◦Add the two primary keys from the two entities from the many-to-many relationship.
◦These become foreign keys (FK) in the association entity.
◦Add any attributes that were part of (on) the many-to-many relationship.
◦Determine a Primary Key (PK) for association entity. Two choices:
◦Composite Key from the two foreign keys + any other attribute to make it unique if required
◦Or, add a new attribute to be PK, e.g., an autoincrement ID key

Resolving N-ary Relationships

•An n-ary relationship is resolved by:
◦Introducing a new entity to represent the relationship.
◦Any attributes that are part of the relationship will be added to the new entity.
•For the new entity:
◦Add the primary keys from all the entities that were part of the n-ary relationship.
◦These become foreign keys (FK) in the new entity.
◦Add any attributes that were part of (on) the relationship.
◦Determine a Primary Key (PK) for the new entity. Two choices:
◦Composite Key from the foreign keys + any other attribute(s) to make it unique if required
◦Or, add a new attribute to be PK, e.g., an autoincrement ID key

func depedancy

◦Describes the relationship between attributes in a table.
◦Is a property of the meaning (or semantics) of the attributes in a table.
•Lossless join property

◦To preserve all the rows in the original table.
◦To ensure that no spurious rows are generated when the decomposed tables are combined through a natural join operation

•Dependency preservation property

◦To ensure that constraints on the original table are preserved by enforcing constraints on the decomposed tables.

UNF (Unnormalised Forms)
UNF (Unnormalised Forms:
- Contains repeating groups
1NF
1NF (First Normal Form):
- All attributes contain atomic (single) values.
- Remove repeating groups and select a primary key.
- Example: Flattening the StudentData table to remove repeating groups.
2NF
- The table must be in 1NF.
- Eliminate partial dependencies by ensuring non-key attributes depend on the entire primary key.
- Example: Decomposing the StudentModule table into Student, Module, and Registration tables.
3NF
3NF (Third Normal Form):
- The table must be in 2NF.
- Eliminate transitive dependencies by ensuring non-key attributes depend only on the primary key.
- Example: Further decomposing the Module table to remove the transitive dependency ConvenorID → ConvenorName.
Consistency requirements
In general consistency requirements include
Database integrity constraints: Entity integrity (primary keys cannot be null) and Referential integrity (foreign keys must reference existing records)
Application constraints: For example, the sum of the balances of accounts A and B is the same before and after the transaction T1.
A transaction transforms database from one consistent state to another, although consistency may be violated during
transaction
Why we need transactions
Counting or general statistics on changing data can be error-prone, especially when multiple users are accessing or modifying the data simultaneously.
Transactions provide a consistent snapshot of the database, ensuring that operations are executed in a controlled manner, even when multiple users are interacting with the database at the same time.
For example, a booking system for student wellbeing appointments may come into a number of potential problems:
- Multiple students trying to book the same slot simultaneously.
- Lost Update Problem: The last booking overwrites previous ones, leading to inconsistent data.
The solution is to use transactions and concurrency control mechanisms in order to prevent such issues
ACID Transaction Properties
Atomicity: A transaction is either fully completed or fully aborted (all or nothing).
Consistency: The database remains in a consistent state before and after the transaction.
Isolation: Partial effects of incomplete transactions should not be visible to other transactions.
Durability: Once a transaction is committed, its effects are permanent.
HIGHER NORMAL FORMS
•We generally aim for 3NF, but higher normal forms exist.
•Boyce-Codd Normal Form (BCNF) is a stronger form of the 3NF
◦All determinants in a relation must be candidate keys
◦If all non-key attributes depend only on the complete key, a table is in BCNF
•4NF is based on multi-valued dependencies
◦A table is in 4NF if it is in BCNF and contains no non-trivial multi-valued dependencies
◦Based on lossless join dependency
•5NF involves relations that must be decomposed into three or more tables.

ER Modelling vs. Normalisation

ER modeling | Normalization |
Top-down | Bottom-up |
Informal, intuitive | Formal |
“Real world” oriented | Database oriented |
Can represent full semantics | Limited semantics only, unless additional steps introduced |
Good model not guaranteed but skilled modeler may produce an excellent model | Good model guaranteed if rules applied rigorously but may not necessarily be the best  |
The two main issues that occur with respect to handling concurrent control:
System failures of all kinds: Hardware, Software and Network issues may occur, leading to a failure
Concurrent transaction problems: Multiple people updating data at the same time
In order to counteract this, we can factor these four elements into our control:
Goal: Allow multiple transactions to run concurrently without interfering with each other.
Schedules: A sequence of operations by concurrent transactions. Operations from different transactions can be interleaved.
Serial Schedule: Transactions run one after another with no concurrency. This avoids concurrency issues but has poor performance.
Serializable Schedule: A schedule that produces the same result as a serial schedule, even though transactions are interleaved.
The three kinds of concurreny problems that may occur during a transaction include:
Lost Updates (Dirty Write): One transaction overwrites the changes of another.
Reading Uncommitted Data (Dirty Reads): A transaction reads uncommitted data from another transaction.
Non-Repeatable Reads (Inconsistent Analysis): A transaction reads the same data twice but gets different results due to updates by another transaction.
Pessimistic concurrency
Pessimistic concurrency control techniques assume that conflicts between transactions are likely to occur. Therefore, they prevent conflicts by checking for potential issues before executing operations.
Optimistic concurrency
Optimistic concurrency control techniques assume that conflicts between transactions are rare. Therefore, they allow transactions to proceed without checking for conflicts during execution and only validate for conflicts at the end of the transaction.
All types of locking:
Read Lock (Shared Lock): Multiple transactions can read the same data item, but no transaction can write to it.
Write Lock (Exclusive Lock): Only one transaction can write to a data item, and no other transactions can read or write to it.
Two-Phase Locking (2PL): a concurrency control protocol where a transaction acquires all its locks in a growing phase (Locks are acquired but not released) and releases all locks in a shrinking phase (Locks are released after the transaction commits or aborts), ensuring serializability.
The primary issues that can occur with locks is the fact that it's possible for deadlock and livelocking to occur, thus potentially freezing the entire transaction.
Timestamping:
Each transaction is assigned a unique timestamp, and operations are ordered based on these timestamps. If a transaction tries to read or write data that has been updated by a later transaction, it is rolled back and restarted. The primary advantage of timestamping is the removal of all deadlocks that can possibly occur. However, but frequent rollbacks can occur if conflicts are common, thus possibly slowing down the program.
Optimising query processing
The primary goal of query processing is to transform a high-level query (typically written in SQL) into an efficient execution strategy expressed in a lower-level language (e.g., relational algebra). The strategy is then executed to retrieve the required data.
Particularly when it comes to larger, more complex data structures, it becomes imperative to figure out ways to shorten and compress the ways in which queries are performed and executed.
Optimising query processing, Performance factors
There are a number of factors to consider when looking at performance:
Throughput: The number of tasks (e.g., queries) that can be completed within a given period.
Response Time: The time required to complete a single task (e.g., a query).
Additional performance considerations include:
Time Performance: How quickly the query can be executed.
Space Performance: How much memory or disk space is required for intermediate results.
There are a number of factors to consider when looking at performance:
Throughput: The number of tasks (e.g., queries) that can be completed within a given period.
Response Time: The time required to complete a single task (e.g., a query).
Additional performance considerations include:
Time Performance: How quickly the query can be executed.
Space Performance: How much memory or disk space is required for intermediate results
There are multiple stages with respect to query processing:
Query Decomposition:
-Transform the user query into a sequence of operations on relations.
- Check the query for correctness (syntactically and semantically).
- Select an execution plan (e.g., relational algebra).
Query Optimization: Choose the most efficient execution strategy.
Code Generation: Generate the code to execute the query.
Run-Time Query Execution: Execute the query and retrieve the results.
Key considerations to think about when designing a database include:
Transaction Requirements: Frequency, volume, and type of access (read, update, insert).
System Resources: Main memory, CPU, disk access, storage, and network performance.
Objectives: Fast throughput, acceptable response time, and minimized disk storage.
Trade-offs: Physical design must balance conflicting objectives and adapt to changing requirements.
File Organisation
The three primary types of file organisation are:
Heap (Unordered) Files: Records are stored in insertion order. Efficient for bulk loading but inefficient for selective retrieval.
Sequential (Ordered) Files: Records are sorted by a specified field. Efficient for range queries but problematic for insertions and deletions.
Hash Files: Records are stored based on a hash function. Efficient for exact matches but not suitable for range queries or pattern matching.
Heap (unordered) files
Features of heap files:
Structure: Records are stored in the order they are inserted (chronological order), making the file unordered.
Insertion: Efficient, as new records are added at the end of the file.
Retrieval: Inefficient, as searching requires a linear scan from the start of the file.
Deletion: Problematic because:
- Deleted records are marked as deleted but not immediately removed.
- Periodic reorganization is needed to reclaim space, especially in volatile files (frequent deletions).
Default Structure: Heap files are the default table structure in many databases.
Heaps advantages
Advantages:
- Bulk Loading: Efficient for loading large amounts of data into a table.
- Large Retrievals: Useful when retrieving a large portion of the records.
Disadvantages:
- Selective Retrieval: Inefficient for queries that require searching by key values, especially in large tables.
- Sorting: External sorting (sorting data outside of memory) can be time-consuming.
- Volatility: Not suitable for tables with frequent changes or deletions.
Heap files are simple and efficient for bulk operations but are not ideal for selective retrieval or volatile tables. They are best suited for scenarios where large-scale data loading or retrieval is required, rather than frequent updates or deletions.
Sequential (ordered) files
Features of sequential files:
Structure: Records are stored in sorted order based on the values of one or more fields (e.g., sorted by name or id).
Retrieval: Efficient for:
- Exact matches: Finding records with a specific value in the ordering field.
- Range queries: Retrieving records within a range of values in the ordering field.
- Binary search: Faster than linear search because the data is sorted.
Insertion and Deletion: Problematic because:
- Records must be inserted or deleted in a way that maintains the sorted order.
- This can require shifting records, which is time-consuming.
Sequential (ordered) files advantages
Sequential files are efficient for retrieval operations, especially when searching for specific values or ranges in the ordering fields. However, they are less efficient for insertions and deletions because maintaining the sorted order requires additional overhead. This makes them less suitable for tables that undergo frequent changes.
Hash files
Features of hash files:
Structure:
- A hash function is applied to one or more fields (called the hash field or hash key) to generate the address of a disk block or page (called a bucket) where the record is stored.
- Within each bucket, records are stored in slots in the order they arrive.
- Techniques like division-remainder and folding are used to spread hash values evenly across the address space.
Example:
- A hash function like Mod 3 divides records into 3 buckets based on the hash key (e.g., carId).
- Records with carId values that hash to the same bucket are stored together.
Hash files ADV/DSIADV
Advantages:
- Efficient for Exact Matches: Very fast for retrieving records based on exact matches of the hash key (equality selection).
- Direct Access: Records can be accessed directly using the hash function, avoiding the need for linear searches.
Disadvantages:
- Pattern Matching: Cannot efficiently handle queries that involve partial matches or patterns.
- Range Retrieval: Inefficient for range queries, as records are not stored sequentially.
- Alternative Fields: Searches on fields other than the hash key require linear searches through all buckets/pages.
- Non-Key Fields: Retrieval based on non-key fields is inefficient.
Hash files are highly efficient for exact match queries on the hash key field, making them ideal for scenarios where quick access to specific records is needed. However, they are not suitable for pattern matching, range queries, or searches on non-key fields, as these require linear searches through all buckets. Hash files are best used when the primary access pattern involves exact key-based retrieval.
Table Indexing
Indexes are an important feature of SQL, as they can help to:
- Improve search and retrieval efficiency.
- Improve performance of SQL queries
An index file contains search key values and addresses of records in the data file. Indexes are typically created automatically on primary keys.
B+ Trees
A B+ Tree is a balanced, multi-level index structure used in databases to efficiently organize and retrieve data. Here are its key characteristics:
Dynamic Structure: Expands or shrinks automatically as rows are added or deleted, maintaining balance. Ensures that the tree remains efficient even as the dataset grows or changes.
Full Index: Every record in the data file is addressed by the index, so the data file itself does not need to be ordered. This allows for fast and efficient retrieval of any record.
Balanced Tree: All leaf nodes are at the same depth, ensuring consistent search times for any record. The tree is balanced, meaning the number of nodes searched to find any record is the same.
Node Structure: Each node contains M search key values and M+1 pointers. Non-leaf nodes contain keys and pointers to child nodes. Leaf nodes contain keys and pointers to the actual data records. All leaf nodes are linked in order, making range searches efficient.
Efficient Search: Retrieval is fast because the tree structure allows for binary search-like traversal. For example, to find a record with key C05, the search starts at the root, compares keys, and follows pointers to the appropriate child nodes until the correct leaf node is reached.
Degree of the Tree: The degree (or order) of the tree refers to the number of child nodes allowed per parent node. Trees with a larger degree are broader and shallower, which makes them faster for searches.
B+ TREES ADV/DISAV
Advantages:
- Supports exact match, range queries, and partial key searches efficiently.
- Handles dynamic datasets well, as it automatically reorganizes itself during insertions and deletions.
Disadvantages:
- Slightly higher overhead for insertions and deletions compared to simpler structures like hash tables.
- Requires additional space to store the index structure.
B+ Trees are a powerful and versatile indexing method, offering fast and efficient access to data for both exact and range queries. They are widely used in databases because of their ability to handle large, dynamic datasets while maintaining balanced and consistent performance.
The importance of reliability
DBMSs must ensure that databases are reliable and remain in a constant state when failures occur. Errors that could occur withihn this include:
System crashes: Lost of main memory
Hardware failure: Loss of database storage
Natural disasters: Destruction of database systems
Human errors: Corruption or destruction of data, hardware or software
Reliability is achieved through:
- Minimising the frequence of failures and associated side effects
- Maximising the ability to recover
types of reliability
Primary Reliability:
- Avoid single points of failure
- Realized through hardware replication (e.g., RAID), backup power sources (UPS, emergency generators), etc.
Secondary Reliability:
- Rigorous operating procedures (e.g., script and test DB schema changes, no manual DB access)
- Access controls (e.g., limit access to necessary personnel, prevent physical access)
Database System Failure Types:
- Transaction failure: Deadlock, handled by rollback and restart
- System failure: Power failure, system should recover to a consistent state on restart
- Communication failure: Network losses, handled in distributed setups
- Media failure: Disk failure, recover from backup
Database recovery
Recovery mechanisms within database design should:
- Ensure atomicity (transactions are either completely executed or not at all)
- Ensure durability (changes from committed transactions are permanently stored)
Guarantee database consistency
- Minimize impact on normal processing
High-performance DBMS may use at least three kinds of disks: System and DBMS software, Live data, Transaction logs
Recovery mechanisms within database design should
Recovery mechanisms within database design should:
- Ensure atomicity (transactions are either completely executed or not at all)
- Ensure durability (changes from committed transactions are permanently stored)
Guarantee database consistency
- Minimize impact on normal processing
High-performance DBMS may use at least three kinds of disks: System and DBMS software, Live data, Transaction logs
The DBMS log file contains information about the current states of transactions and database updates. This information usually includes:
- Transaction records (e.g., Transaction ID, type of log record, start, commit, abort records)
- Pages affected by insert, update, or delete actions (e.g., Data page ID, before-image, after-image)
- Checkpoint records (where all changes made to the database are on the disk)
With the Transaction Processing Model:
- Pages needed to process transactions are read from disk into memory buffers.
- Buffer pages are updated, and records of updates are written to the log.
- Buffer Manager:
- Controls the buffer pool, fetches pages from disk as required, and removes pages when no longer needed.
- Modified pages are flushed to disk at the end of a transaction or when the buffer is full.
Types of recovery
Normal recovery: After normal shutdown, start from the last log record (checkpoint written at shutdown).
Warm recovery: After system failure, revert to the last checkpoint in the log, apply committed transactions, and remove effects of uncommitted transactions.
Cold recovery: After media failure, restore from backup/dump and apply log records to reach the latest consistent state.
Checkpoints
- All modified pages in memory are written to disk, ensuring an accurate record of all current transactions in the log.
- A record describing the checkpoint is written to the log, including the list of current transactions.
The Undo/Redo recovery method (warm recovery algorithm)
The Undo/Redo algorithm is widely used, allows buffer manager to flush modified pages before, during, or after commit.
Steps:
1. Create two empty lists: UNDO and REDO
2. Start reading the log at the last checkpoint
3. Put all active transactions on the UNDO list
4. Read the log forwards, adding transactions to UNDO or REDO based on BEGIN-TRANSACTION or COMMIT records
5. At the end, use before-images to undo all on the UNDO list and after-images to redo all on the REDO list
Anderson’s Rule
Anderson's database rule comprises the following:
- A system designed for ease of access is insecure
- A system designed for strict security is difficult to use
Thus this creates a trilemma between security, functionality, and scalability—only two can be optimized at a time.
The trilemma is getting the balance right:
- The more accessible and usable the database, the more vulnerable it is to security threats.
- The more secure and protected the database is from threats, the more difficult it is to access and use.
CIAAAAAAAAAAAAA
The CIA Triad is a widely used model guiding database security:
1. Confidentiality – Prevent unauthorized access to sensitive data.
2. Integrity – Maintain data accuracy, consistency, and trustworthiness.
3. Availability – Ensure reliable access to data for authorized users.
To achieve security, all components of a database system must be protected:
- Users should be identifiable, authorized, and monitored.
- Data must be protected, tamper-proof, auditable, and recoverable.
- Hardware must be maintained and secured from physical tampering.
- Software should be updated and protected from vulnerabilities.
Common database security threats |
Privilege Abuse - Users granted excessive privileges can misuse them. Example: An employee granted both read and write access to an accounts table when only read access is needed. Mitigation: Follow the principle of least privilege (grant only necessary access).
Input Injection - Attackers manipulate user input to execute unauthorized database queries through an SQL injection for example
Malware - Malicious software may steal sensitive data (e.g., database passwords). Mitigations include: Installing and updating anti-malware tools, keeping applications and database software up to date, and educating staff on security risks (avoid suspicious websites & downloads).
Storage Media Exposure - Database backups must be secured to prevent unauthorized access.Mitigations include: Encrypting backups, storing them in secure, locked locations, and using cloud storage with encryption.
Common database security threats 2
Misconfigured Databases - Default installations may have security vulnerabilities. Example: Some MySQL versions install without a root password. Mitigations include: securing default accounts and disable unnecessary features.
Unmanaged Sensitive Data - Sensitive data should be encrypted. Encryption Methods include: Data at Rest – Encrypt stored data (e.g., full-disk encryption, database-level encryption), Data in Transit – Encrypt data sent over networks (e.g., TLS/SSL), Client-side Encryption – Encrypt data before it is transmitted to the database.
Denial of Service - Attackers flood the database server with requests, making it unavailable. Mitigation: Using firewalls and rate limiting, ensuring extra server capacity (CPU, memory, bandwidth), and deploying distributed hosting to prevent single points of failure.
The best practices for database administration include the following:
The best practices for database administration include the following:
- Regularly update software and apply security patches.
- Implement audit trails to track database activity.
- Physically secure servers and backups.
- Ensure Database Administrators (DBAs) undergo regular training.