Surtel oby dał mi szczęście :D
1/35
Earn XP
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai | Chat |
|---|
No analytics yet
Send a link to your students to track their progress
36 Terms
Moduł TWI procesorów ARM jest odpowiednikiem standardu opracowanego przez firmę Philips (firma Philips posiada patent na interfejs I2C). Cechy interfejsu TWI procesora ARM firmy ATMEL: 9
• Zgodny ze standardem I2C,
• Praca w trybie Master, Multimaster lub Slave,
• Umożliwia dołączenie urządzeń zasilanych napięciem 3,3 V,
• Transmisja danych z częstotliwością zegara do 400 kHz,
• Transfery poszczególnych bajtów wyzwalane przerwaniami,
• Automatycznie przejście do trybu Slave w przypadku kolizji na magistrali
• (Arbitration-lost interrupt),
• Przerwanie zgłaszane, gdy zostanie wykryty adres urządzenia w trybie Slave,
• Automatyczne wykrywanie stanu zajętością magistrali, • Obsługa adresów 7 i 10-cio bitowych.
Organizacja bufora danych opiera się na kolejce FIFO. Stany kolejki: 3
Kolejka pusta: T = H
Brak miejsca w kolejce: (T = 0 & H = size) lub T – H = 1
Dane w kolejce, ilość danych = Kolejka pusta H-T
Algorytm szeregowania - planista to:
algorytm rozwiązujący jedno z najważniejszych zagadnień programowania systemów czasu rzeczywistego, a mianowicie – w jaki sposób rozdzielić czas procesora i dostęp do innych zasobów tj. pamięć, zasoby sprzętowe, pomiędzy zadania,
Planista Adaptacyjnego partycjonowania aby rozwiązywać następujące problemy: 2
• gwarancji współdzielenia czasu procesora na wyspecyfikowanym minimalnym poziomie w czasie przeciążenia systemu;
• zapobieganiu monopolizacji systemu przez nieistotne lub niezaufane aplikacje.
Cechy portu diagnostycznego DBGU (DeBuG Unit): 7
• Asynchroniczna transmisja danych zgodna ze standardem EIA-232 (8 bitów danych, jeden bit parzystości z możliwością wyłączenia),
• Możliwość zgłaszania przerwań systemowych współdzielonych (PIT, RTT, WDT,DMA, PMC, RSTC, MC),
• Analiza poprawności odebranych ramek,
• Sygnalizacja przepełnionego bufora TxD lub RxD,
• Trzy tryby diagnostyczne: zdalny loopback, lokalny loopback oraz echo,
• Maksymalna szybkość transmisji rzędu 1 Mbit/s,
• Możliwość komunikacji z rdzeniem procesora COMMRx/COMMTx.
Jakie są zalety i wady wywłaszczania?
korzyści: -
• zmniejszone opóźnienie;
• szybsza odpowiedź na nowe zdarzenia;
• krótsze opóźnienie przerwania,
koszty:
• wydajność;
• wymaga więcej czasu by wznowić przerwane wywołanie jądra;
• zabiera więcej czasu i zasobów na zachowanie aktualnego stanu i wznowienie wywłaszczonego procesu przekazywania wiadomości.
PCB-Blok kontrolny procesu zawiera wiele informacji związanych z danym procesem, które obejmują: 7
• Stan procesu: Stan może być określony jako nowy, gotowy, aktywny, oczekiwanie, zatrzymanie itd.
• Licznik rozkazów: Licznik ten wskazuje adres następnego rozkazu do wykonania w procesie.
• Rejestry procesora: Liczba i typy rejestrów zależą od architektury komputera; są tu akumulatory, rejestry indeksowe, wskaźniki stosu, rejestry ogólnego przeznaczenia oraz rejestry warunków.
• Informacje o planowaniu przydziału procesora: Należą do nich: priorytet procesu, wskaźniki do kolejek porządkujących zamówienia, a także inne parametry planowania.
• Informacje o zarządzaniu pamięcią: Mogą to być informacje takie, jak zawartości rejestrów granicznych, tablice stron lub tablice segmentów - zależnie od systemu pamięci używanej przez system operacyjny.
• Informacje do rozliczeń: Do tej kategorii informacji należy ilość zużytego czasu procesora i czasu rzeczywistego, ograniczenia czasowe, numery kont, numery zadań lub procesów itp.
• Informacje o stanie wejścia-wyjścia: Mieszczą się tu informacje o urządzeniach wejścia-wyjścia (np. stan bufora klawiatury) przydzielonych do procesu, wykaz otwartych plików itd.
Funkcje jądra: 4
• są spoiwem łączącym cały system;
• programy mają do czynienia z jądrem za pomocą specjalnych procedur bibliotecznych, nazywanych „wywołaniami jądra” ang. „kernel calls”, które wykonują kod umieszczony w jądrze;
• większość podsystemów, włączając aplikacje użytkownika, komunikują się nawzajem używając mechanizmu przekazywania wiadomości, dostarczanego przez jądro za pomocą „wywołań jądra”.
• Wywołania jądra: często będziemy korzystać z wywołań jądra, np. w trakcie komunikacji IPC lub podczas obsługi przerwań, timerów, wątków itp.; to znaczy, że będzie wykonywany kod w jądrze podczas wywołania.
Inwersja priorytetów(odnośnie zakleszczen)
ma miejsce w sytuacji, gdy zadanie o wysokim priorytecie nie otrzymuje czasu procesora, pomimo tego iż powinno dziedziczenie priorytetów – polega na tym że niskopriorytetowy wątek otrzymuje priorytet wątku o najwyższym priorytecie
Ceiling Semaphore Protocol (CSP) (odnośnie zakleszczen)
semafor zapewniający wyłączny dostęp do danego zasobu, jest równy najwyższemu priorytetowi zadania, które może przejąć zasób plus jeden; Zgodnie z protokołem CSP poziom zadania, które zajmuje zasób jest równy pułapowi zasobu. Jest to rozwinięcie idei dziedziczenia priorytetów
FCFS (first come, first serve)
podobny do FIFO, bardzo słaba interaktywność systemu – pojedynczy długi proces blokuje cały system, brak priorytetów nie ma możliwości wywłaszczenia;
SJF (shortest job first)
pierwsze najkrótsze zadanie, wada problem głodzenia długich procesów
Stack Resource Policy (SRP)
zadanie nie może być rozpoczęte dopóki jego priorytet nie jest najwyższy z pośród aktywnych zadań lub poziom wywłaszczenia nie jest wyższy od pułapu systemowego zadanie rozpoczęte nie zostanie zablokowane przed jego zakończeniem, może zostać jednak wydziedziczone przez zadanie o wyższym priorytecie wykorzystuje wspólny stos do przechowywania parametrów wszystkich wykonywanych funkcji i zwracanych adresów
Zarządzanie procesami, które jest podstawowym zadaniem każdego nowoczesnego OS, obejmuje: 4
• alokowanie zasobów dla procesów;
• organizacje wymiany informacji między procesami;
• zabezpieczanie zasobów procesów przed niepożądanym wpływem innych procesów;
• synchronizację współpracy procesów
SCHEMAT LOGICZNY STEROWNIKA PLC
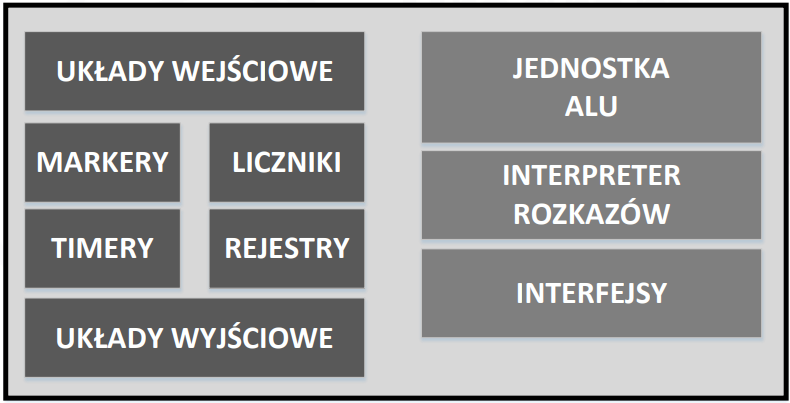
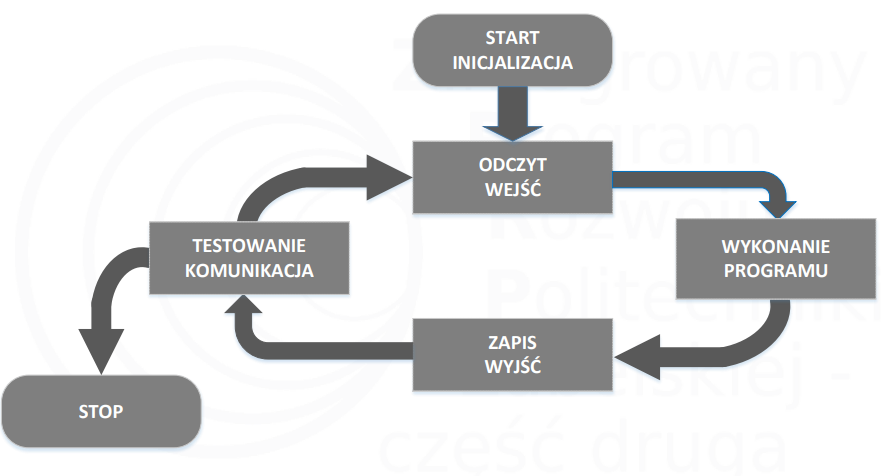
CYKL PRACY STEROWNIKA PLC
Znaczniki zbocza PLC
Klasyczna struktura SCR: odp,wady,zal
Wszystkie moduły współdzielą tą samą przestrzeń pamięci, tworząc jeden duży program
zalety:
• pojedyncza przestrzeń adresowa
• łatwa komunikacja pomiędzy zadaniami
• proste współdzielenie zasobów
wady:
• pojedyncza przestrzeń adresowa
• brak mechanizmów ochrony pamięci
• utrudniony rozwój i testowanie
Monolityczna struktura SCR Z i W: odp,wady,zal
Jądro zawiera oprócz własnej funkcjonalności, również wszystkie sterowniki. Aplikacje są procesami umieszczonymi w chronionej pamięci
zalety:
• aplikacje uruchamiają się w wydzielonej przestrzeni adresowej
• wykorzystanie mechanizmów ochrony pamięci
wady:
• sterowniki w przestrzeni adresowej jądra
• utrudniony rozwój i testowanie
Architektura mikrojądra: odp,wady,zal
System operacyjny zawiera mikrojądro i zbiór współpracujących procesów. Procesy są odseparowane od jądra, więc w przypadku awarii oprogramowania, nie mają one wpływu na jądro. Procesy systemowe i użytkownika komunikują się ze sobą wykorzystując mechanizmy komunikacji IPC – Inter-Process Communication. Oprogramowanie systemowe i aplikacyjne tworzą spójny system.
Zalety:
• elastyczność i niezawodność
• łatwość konfiguracji i rekonfiguracji
• łatwość debugowania
• łatwość wytwarzania oprogramowania
• skalowalność systemu
Wady - koszty:
• więcej przełączeń kontekstu;
• więcej kopiowanych danych.
Architektura dwóch systemów: W/Z
Zalety:
• szybsze przełączanie kontekstu – brak konieczności zmiany rejestru bazowego jednostki zarządzającej pamięcią MMU i czyszczenia bufora TLB - Translation Lookaside Buffer;
• bezpośrednie współdzielenie danych bez konieczności stosowania skomplikowanych mechanizmów komunikacji międzyprocesowej;
Wady:
• rozbudowany mechanizm komunikacji zadań RT z zadaniami non-RT;
• błędy w zadaniach krytycznych mogą powodować awarię całego systemu;
Proces
• program załadowany do pamięci;
• identyfikowany przez id procesu, zwykle nazywany jako pid;
• wspólne zasoby procesu:
- pamięć, włączając kod i dane,
- otwarte pliki,
-identyfikatory: ( id użytkownika, id grupy, )
-timery.
Zasoby należące do jednego procesu są chronione przed innymi procesami.
Wątek
jest pojedynczym strumieniem wykonania posiada pewne atrybuty: priorytet, algorytm kolejkowania, zestaw rejestrów, maska CPU dla SMP, maska sygnałów,
Hard real-time systems – rygorystyczne (twarde): 5
• ograniczenie opóźnień w systemie;
• przechowywanie danych w pamięci o krótkim czasie dostępu;
• pamięć pomocnicza ograniczona do minimum lub jej brak;
• brak pamięci wirtualnej;
• niemożliwa współpraca z systemami z podziałem czasu
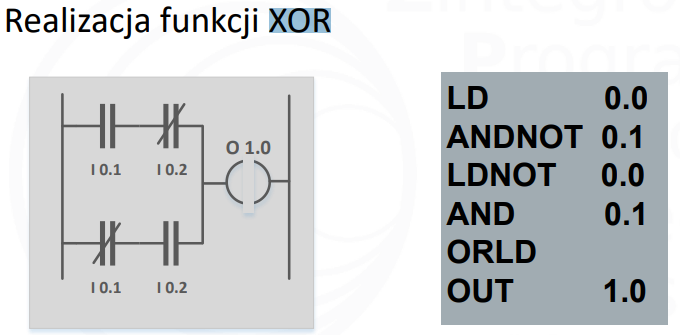
Realizacja funkcji XOR (PLC)
System RTOS przewidziany do działania w urządzeniu opartym na mikrokontrolerze jednoukładowym, musi spełniać szereg warunków: 3
– Zapewniać niezbędne czasy odpowiedzi w określonych sytuacjach
– Działać stabilnie i płynnie w środowisku o bardzo ograniczonych zasobach
– Wykorzystywać specyfikę architektury urządzenia, na którym działa
RMS – Rate Monotonic Scheduling Algorithm
-bazujący na statycznych priorytetach
-uwzględnia okres wykonywania zadania,
-im krótszy okres zadania tym wyższy jego priorytet
-algorytm optymalny w takim sensie, jeśli zadanie nie jest szeregowalne tym algorytmem, to nie będzie szeregowalne według żadnego innego algorytmu bazującego na statycznych priorytetach
-wadą tego algorytmu jest niski limit szeregowalności – 69,3%
EDF - Earliest Deadline First :4
• obecny algorytm szeregowania bazujący na dynamicznych priorytetach:
• im bliższy deadline, tym wyższy priorytet;
• zaletą tego algorytmu jest 100% szeregowalność zadań;
• wadę stanowią narzuty związane z przeliczaniem priorytetów.
Funkcje systemowe w systemach wbudowanych wielozadaniowych i wielowątkowych
stanowią interfejs pomiędzy aplikacją użytkownika a jądrem systemu
UART – Universal Asynchronous Receiver Transmitter: 6
• Prosty, uniwersalny, dobrze udokumentowany,
• Wolna komunikacja: max. 1Mbit/s,
• Po jednym przewodzie komunikacyjnym w każdym z kierunków plus wspólna masa sygnałowa,
• Asynchroniczna – odbiornik i nadajnik muszą wcześniej znać szybkość transmisji oraz format ramki,
• Bity START i STOP normują przesyłanie,
• Możliwe dołączenie informacji o parzystości (kontrola błędów)
Ramka danych w transmisji UART: 3
Zawiera bit startu, sygnalizujący początek kolejnej ramki (od 5 do 9 bitów danych), bit parzystości, służący do kontroli błędów odbioru.
• Może działać w trzech trybach - brak kontroli (no), suma zawsze parzysta (even), suma zawsze nieparzysta (odd).
• Każdą ramkę zamyka od jednego do dwóch bitów stopu.
Cechy interfejsu SPI: 4
• Szeregowa transmisja synchroniczna,
• Transfer full duplex, master-slave lub master-multi-slave,
• Duża szybkość transmisji (>12 Mbit/s),
• Zastosowanie:
- układy peryferyjne (ADC, DAC, RTC, EEPROM, termometry, itp),
- sterowanie pomocnicze (matryca CCD z szybkim interfejsem równoległym),
- karty pamięci z interfejsem szeregowym SD/SDHC/MMC.
SPI - odczyt lub transfer
while ( ! ( SPI->SPI_SR & AT91C_SPI_TDRE ) );
SPI->SPI_TDR = NPCS_CODE_MASK[channel] | dataToSend;
while( !( SPI->SPI_SR & AT91C_SPI_RDRF ) );
receivedData = (uint16_t)( SPI->SPI_RDR );
Do najważniejszych funkcji sterownika SPI należą: 5
void SPI_Konfiguracja - Funkcja konfiguruje główne parametry pracy układu SPI
void SPI_UstawPCS - Funkcja umożliwia zmianę urządzenia, z którym przeprowadzana jest transmisja danych
void SPI_KonfiguracjaCSR - Funkcja umożliwia konfigurację parametrów transmisji dla poszczególnych urządzeń
void SPI_UstawPredkosc - Funkcja umożliwia zmianę aktualnej prędkości transmisji
unsigned int SPI_Transfer - Funkcja używana do transferu danych w obydwie strony. Po wysłaniu znaku, funkcja czeka na odebranie danych od urządzenia
Cechy modułu SPI układu SAM7X:
• Obsługa transferów w trybie Master lub Slave,
• Bufor nadawczy, odbiorczy oraz bufor transceivera,
• Transfery danych od 8 do 16 bitów,
• Cztery programowalne wyjścia aktywujące urządzenia dołączone do SPI (obsługa do 15 urządzeń),
• Programowalne opóźnienia pomiędzy transferami,
• Programowalna polaryzacja i faza zegara.
Architektura ARM Cortex-M4
-Wysoce wydajna, tania i energooszczędna, wykorzystywana w milionach urządzeń
- Cortex-M: Procesory w tych profilach są wykorzystywane do rozwoju systemów wbudowanych opartych na mikrokontrolerach. Cortex-A: Procesory w tym profilu są używane w urządzeniach o wysokiej wydajności, takich jak telefony komórkowe / komórkowe.
-Cortex-R: Główny rynek procesorów tego profilu znajduje się w aplikacji w czasie rzeczywistym, gdzie głównym celem jest planowanie czasu reakcji.
-Cortex-M4 mogą obsługiwać 2^32 = 4 GB przestrzeni adresowej pamięci.