Computer Architecture Final Exam
1/38
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
39 Terms
What are the five main architectural components of a computer?
Input, Output, Memory, Datapath, Control
Why did processor clock speeds, which had increased for decades, finally stop increasing in the last decade?
The power wall: as frequency increases, so does power consumption, and eventually power consumption became too high to allow feasible cooling or battery life.
Where are increasing transistor counts being used now?
What about in the past?
More processor cores.
Deeper pipelines.
What is a meaningless metric?
A metric that doesn't convey any true performance and may vary entirely independently from performance.
x86 ISA has shown incredible resisiency due to backwards compatibility. Why is backwards compatibility so important?
Given this, why is ARM popular?
Software (binaries) generally lives much longer than hardware and there's more money invested in software than hardware.
ARM is a new platform and has no old binaries that need continued support.
Many x86 instructions require the destination register to also be one of the source registers... Why?
This eliminates one of the register specifiers from the instruction op code, i.e., requires fewer bits.
What is the RISC ISA and what are the advantages?
Which ISA is this?
Make the most simple instructions possible at high speed
Fewer instruction formats and addressing modes leads to simpler hardware
MIPS
What is the CISC ISA and what are the advantages?
Which ISA is this?
Complete the task in as few lines of code as possible
Higher code density
Operations work directly on memory
Larger immediate fields
x86
What is the ideal speed of of a N stage pipeline?
What issues prevent ideal speedup?
N- times speed up
Work cannot be divided equally into N parts resulting in wasted execution time.
What problem is caused by long pipelines?
Branch/flush penalties become very high.
Five basic pipeline stages
IF - Fetch
ID - Identify
EXE - Execute
MEM - Memory
WB - Writeback
What does branch prediction eliminate?
Stalls due to control hazards
What does pipeline forwarding eliminate?
Stalls due to data hazards
What are the disadvantages of compiler managed static multiple issue?
Different implementations will require different instruction placement because branch outcomes and memory stalls are not statistically predictable.
How does multiple issue impact data hazards and forwarding paths in an in-order-pipeline?
More instructions executing in parallel means there are more hazards to check for and more forwarding paths are required.
What is the best CPI a superscalar CPU with N pipelines can achieve? What performance metric do we use instead of CPI to discuss superscalar pipelines?
The best CPI possible is 1/N, though never achieved.
IPC - Instructions per cycle.
Which hazard: a required resource is busy
structure hazard
Which hazard: Need to wait for previous instruction to complete its data read/write
Data hazard
Which hazard: Deciding on control action depends on previous instruction
Control hazard
Which type of locality: Items access recently are likely to be accessed again soon (Instructions in a loop)
Temporal Locality
Which type of locality: Items near those accessed recently are likely to be accessed soon (array data)
Spatial locality
In the following C++ code segment for a matrix-matrix multiply, specify for each of the
matrices A, B, and C whether the matrix's accesses primarily have spatial, temporal, or no
locality. (Accesses fewer than N words apart are considered to have spatial locality).
for(k = 0; k < N; k++)
for(i = 0; i < N; i++)
for(j = 0; j < N; j++)
C[i][j] += A[i][k] * B[k][j];
A: temporal (loop invariant to innermost loop)
B: spatial
C: spatial
Suppose you are able to parallelize 80% of a particular program such that it can make use of
1000 parallel processors. What speedup will you achieve for the entire program?
Speedup = 1/[(1 - affected) + (amount_improved / affected)] = 1 / [(1 - .8) + (.8 / 1000)]
= 1 / 0.2008 = 4.98x
In a cache-coherent multi-core system, a cache sometimes has to invalidate one of its entries... What happens to trigger this invalidate?
A tag match on an invalidation message on the bus, indicating another core is writing the same block.
How do GPU's hide long latency operations?
Hardware multi-threading, they switch to another available thread.
What are the advantages of shared-memory multiprocessing systems?
Fast communication through shared memory
Lower administration costs
What are the advantages of distributed systems?
Easier to design, program, and scale
No need for special OS
Moore's Law
The number of transistors doubles ~ every two years
Amdahl's Law
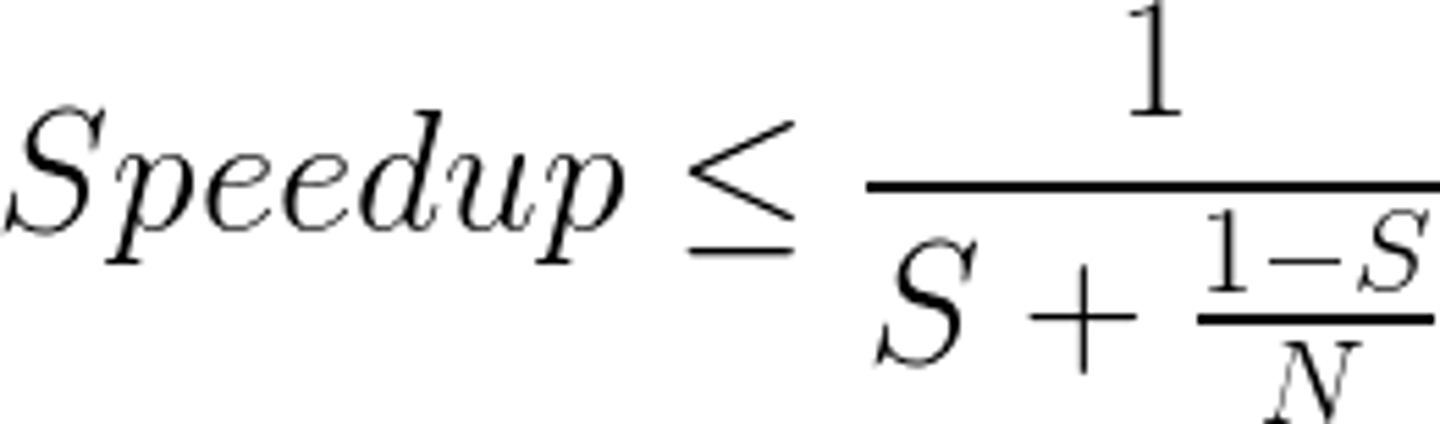
What are 32 consecutive threads called in a GPU?
Warp
How does lookup work in a 4-way set
associative cache?
The set is referenced by an index from a simple hashing.
How is a branch predictor structured?
With a two bit counter and a TLP.
Average CPI calculation
For the multi-cycle MIPS
Load 5 cycles
Store 4 cycles
R-type 4 cycles
Branch 3 cycles
Jump 3 cycles
If a program has
50% R-type instructions
10% load instructions
20% store instructions
8% branch instructions
2% jump instructions
CPI = (4x50 + 5x10 + 4x20 + 3x8 + 3x2)/100 = 3.6
Comparison using classic CPU Performance Equation
The three factors are, in order, known as the instruction count (IC), clocks per instruction (CPI), and clock time (CT). CPI is computed as an effective value.
What's the only meaningful metric?
Wall clock time
Weak vs. strong scaling for parallelism
Weak: Run a larger problem, greater problem size
Strong: run a problem faster, same problem size
Average Memory Access Time (AMAT)
Hit Time + Miss Rate * Miss Penalty
Five Forwarding Paths
EXE/MEM -> ID
EXE/MEM -> EXE
MEM/WB -> ID
MEM/WB -> EXE
MEM/WB -> MEM
Memory hierarchy
SRAM -> DRAM -> SSD -> HDD