Lecture 13: the role of negative information in distributional semantic learning
1/28
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
29 Terms
which model is a pre-cursor for large language models?
word2vec
why is word2vec the most plausible model?
because it’s more similar to how people predict words
*prof doesn’t agree with this
define “negative sampling function”
for each positive training example, you will supply the network with unrelated words that shouldn’t be associated
you will make the network predictive of things related to it (positive) and unpredictive of things that aren’t related (negative)
what’s the issue with word2vec?
it doesn’t work well without negative sampling, worse than PMI
negative sampling gives the model power to make it better than other models
what’s a criticism towards neural network models?
you have some input, but you don’t know the output was constructed
from a psychological perspective, it means that it’s hard to understand how the output was produced

define “positive information”
learning of words that co-occur together
define “negative information”
learning of words that don’t occur together
what’s the difference between positive and negative information?
positive: learning of words that co-occur together
negative: learning of words that do not occur together
true or false: the use of negative sampling is based in prediction
true
true or false: word2vec only holds negative prediction and not positive
false: it predicts words that should and shouldn’t co-occur
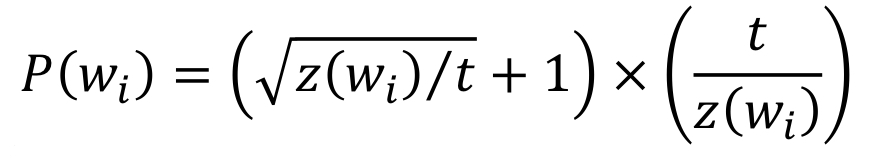
explain the components of the subsampling equation (3)
P(wi): probability of word i being sampled
Z(wi): probability of word i occurring
t: free parameter
define “window size”
number of words around the target word used for accumulating positive information
define “negative samples”
number of samples taken to accumulate negative information
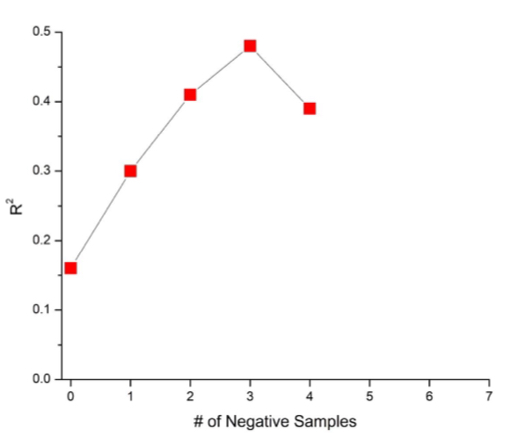
explain this graph
number negative sampling (x-axis) and the balance of positive and negative information (y-axis)
at 3 samples, you get a balance of positive and negative information
at 4 samples, you get more negative information
what can manipulate in sampling distributions? (4)
uniform: all words have equal probability of being sampled
unrelated corpus
related corpus
correct corpus
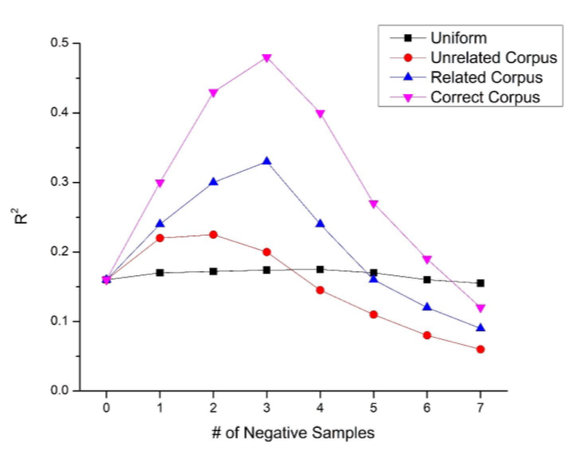
explain this graph
with uniform sampling, there is no overlapping between positive and negative accumulations
with an unrelated corpus, there is some frequency words that are coherent
with a related corpus, there is some overlap between positive and negative accumulations that are important
with the correct corpus, you get the biggest bump: it highlights unique word co-occurrences (co-occurrences that happen above base rate)
what does it mean for co-occurrences to happen above base rate?
co-occurrences happen more often than they should if they were randomly connected to each other
*we use negative sampling to identify them
true or false: similar co-occurrence will appear above base rate
false: only the unique ones will appear above base rate
how does the corpus size affect the base rate?
if you increase the corpus size, the negative sample should increase and make the base rate higher
meaning that the bigger the corpus, the more impact it should have on negative sampling
*however, word2vec doesn’t work with small corpora → negative sampling should have a bigger impact on small corpora
when researching, what are the differences between psychology and computer science?
psychology: coherent theory with clear mechanisms that we understand
computer science: only want something that works well, don’t need to understand the mechanisms
negative sampling allows for highlighting of unique co-occurrence [above/below] base rate
above base rate
true or false: the advantage of negative sampling is due to prediction
false: it‘s due to co-occurrences over base rate frequency (that happen more often than if they were randomly connected)
what are the analytic solutions that are parameter free? (2)
global negative: addition of equal proportion of positive and negative info
distribution of association: transformation of co-occurrence values to z-scores
define “global negative”
addition of equal proportion of positive and negative info
define “distribution of association”
transformation of co-occurrence values to z-scores
true or false: you can combine global negative and distribution of association
true
*global negative: addition of equal proportion of positive and negative info; distribution of association: transformation of co-occurrence values to z-scores
[DOA/global negative] performs better than [DOA/global negative]
DOA better than global negative
how can BEAGLE be made to be as good as word2vec?
with sparse BEAGLE: it will update word co-occurrences so that you can apply DOA and global negative
what’s the difference between between word matrix model and word2vec?
a matrix model requires fewer parameters than word2vec (therefore, better for explanations)
when compared with the same corpus, a matrix model could outperform word2vec (but on average, both were identical)