(1) BIO BOOK 2: DNA Structure & Replication
1/25
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
26 Terms
Role of DNA (Deoxyribonucleic Acid)
DNA is the genetic material of living organisms as it is inherited and contains the coded information (in the form of genes) for protein synthesis
Role of DNA → Hereditary Material:
Importance of hereditary material:
Life depends on the ability of cells to store, retrieve and translate the instructions required to make and maintain a living organism.
These instructions are hereditary, i.e. they are passed on from a cell to its daughter cells at somatic cell division (mitosis), and from one generation of an organism to the next through the organism’s gametes (meiosis).
They are stored within every living cell as its genes, the information-containing elements that determine the characteristics of a species as a whole and of the individuals within it.
Characteristic Properties of a hereditary material:
Have high capacity for information storage and be chemically stable to be able to encode information without fail. It must not change easily due to age, nutrition, or environment.
Replicate accurately.
Be capable of variation.
Structure of DNA — Nucleotides
Nucleic acids: Macromolecules that exist as polymers called polynucleotides.
Nucleotides: Repeating units / monomers in each polynucleotide
*Nucleosides: Pentose sugar + Nitrogenous base
Parts of each nucleotide:
Pentose sugar (five-carbon sugar)
Nitrogenous base
Phosphate group (negatively charged)
Types of Nucleic Acid:
Deoxyribonucleic acid (DNA) → The pentose sugar is deoxyribose. Deoxyribose-containing nucleotides, the deoxyribonucleotides, are the monomers of DNA.
Ribonucleic acid (RNA) → The pentose sugar is ribose. Ribose-containing nucleotides, the ribonucleotides, are the monomers of RNA.
Structure of DNA — Pentose Sugar
What is pentose sugar:
They are five-carbon sugars and occur as ring forms.
In nucleic acids, the 5’ carbon is linked in an ester bond to the phosphate group
In nucleic acids, the 1’ carbon is linked in a glycosidic bond to the nitrogenous base
Two types of pentose are found in nucleic acids:
Deoxyribose (in DNA)
Ribose (in RNA)
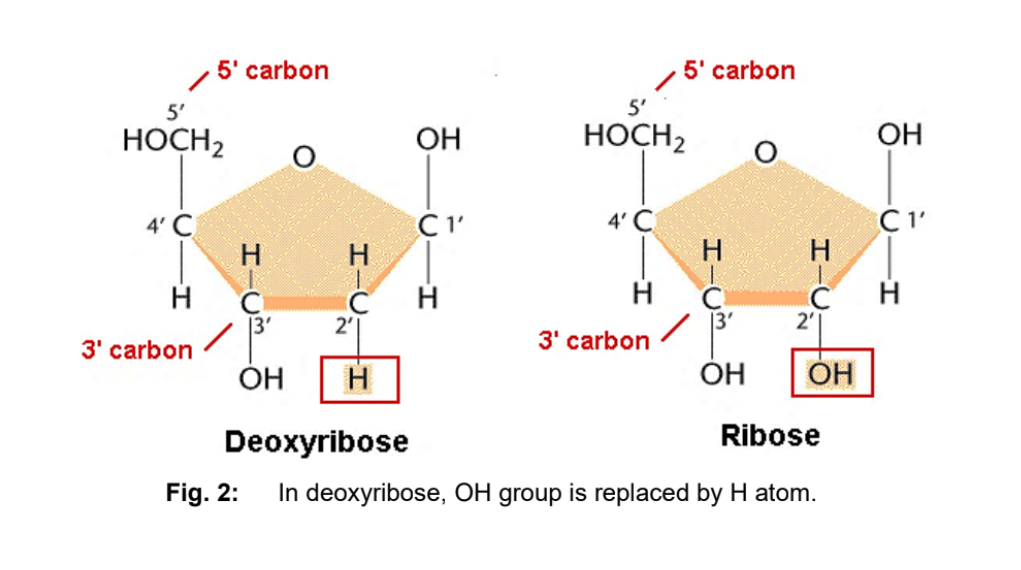
Deoxyribose VS Ribose sugars:
At the 2’ carbon of deoxyribose, the hydroxyl group (-OH) is replaced by a hydrogen atom (H).
Deoxyribose → H attached to 2’carbon
Ribose → OH attached to 2’ carbon
Characteristics:
In ribose, partial negative charge of the hydroxyl group repels the negative charge of the phosphate, preventing the RNA chain from coiling in as tight a helix as it does in DNA.
Deoxyribose → More stable
RNA → More susceptible to chemical and enzyme degradation
Structure of DNA — Nitrogenous Base
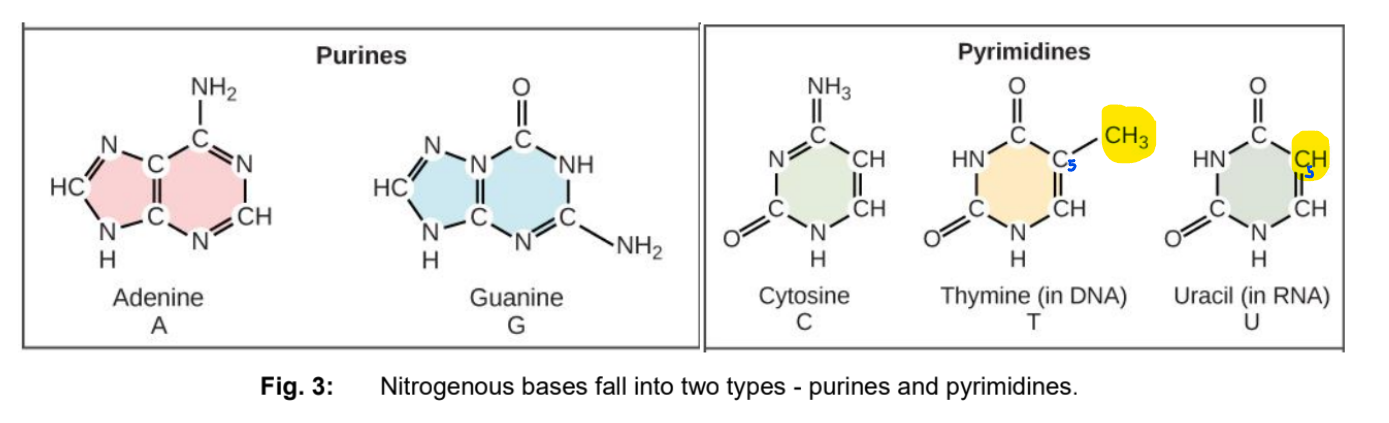
What is nitrogenous base:
A nitrogenous base has a nitrogen-containing ring structure
Two types of nitrogenous bases:
Purines:
Have a 6-membered ring fused to a 5-membered ring (double ring)
Adenine (A) & Guanine (G) → both DNA and RNA
Pyrimidines:
Have a 6-membered ring
Cytosine (C) & Thymine (T) → in DNA
Cytosine (C) & Uracil (U) → in RNA
Only difference between T and U is the presence of a methyl substituent at the C5
Structure of DNA — Nucleoside
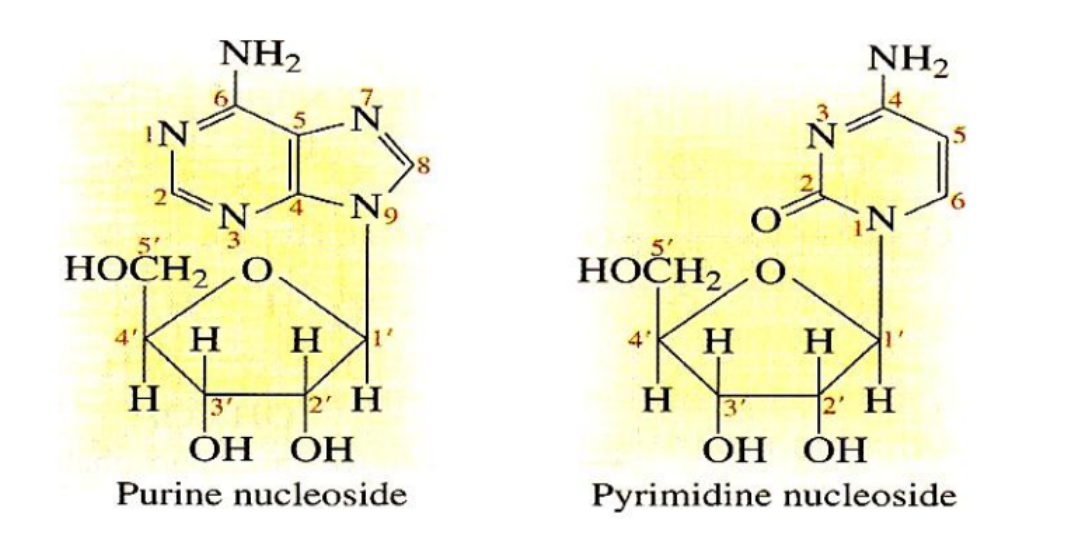
Nucleoside = Pentose Sugar + Nitrogenous Base
Formation of nucleoside:
This occurs with the elimination of water through a condensation reaction
1’ carbon of the pentose is linked in a glycosidic bond to the nitrogenous base
Two types of nucleosides:
Deoxyribonucleosides (DNA)
Ribonucleosides (RNA)
Structure of DNA — Nucleotide
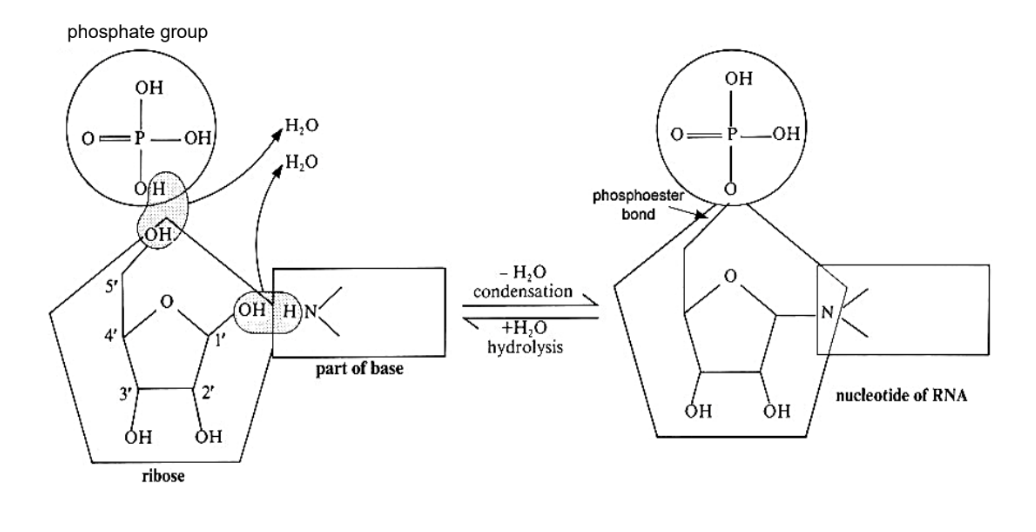
Nucleotide = Nucleoside + Phosphate Group
Formation of Nucleotide:
A nucleotide is formed by further condensation between the nucleoside and phosphate group with the elimination of a water molecule
This forms a phosphoester bond between the 5’ carbon of pentose and the phosphate group
The number of phosphate groups linked together to the 5’ carbon of the pentose sugar varies from 1 to 3:
1 phosphate group → Nucleoside monophosphate (e.g. AMP, adenosine monophosphate)
2 phosphate groups → Nucleoside diphosphate (e.g. ADP, adenosine diphosphate)
3 phosphate groups → Nucleoside triphosphate (e.g. ATP, adenosine triphosphate)
Structure of DNA — Dinucleotides / Polynucleotides
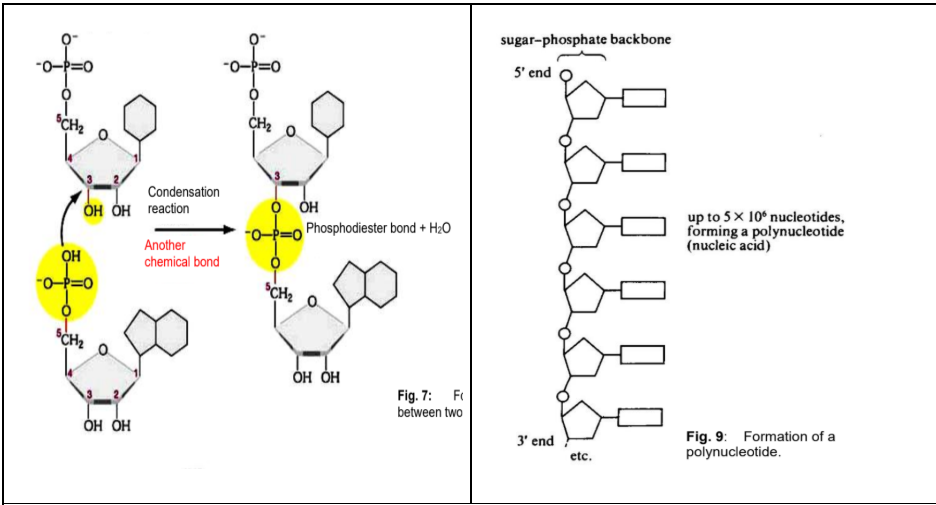
Formation of Dinucleotides:
Two nucleotides join to form a dinucleotide by condensation between the 5’-phosphate group of one nucleotide and the 3’-hydroxyl group of the other to form a phosphodiester bond
The condensation reaction between nucleotides is repeated several millions times to form a polynucleotide (DNA or RNA)
Polynucleotides:
Phosphodiester bonds between 5’ phosphate and 3’ hydroxyl groups of nucleotides form a linear, unbranched sugar-phosphate backbone.
5’ end → Negatively charged due to the free phosphate group
3’ end → Free -OH group which allows more nucleotides to join via condensation
Phosphodiester bonds are strong covalent bonds.
They confer strength and stability on the polynucleotide chain.
This is the basis in preventing breakage of the chain during DNA replication.
Polynucleotides — Polarity / Directionality
Each DNA or RNA strand / chain has two free ends that are chemically different from each other:
5' end with a free 5' carbon carrying a phosphate group; and
3' end with a free 3' carbon carrying a hydroxyl (-OH) group
Where nucleotides are added to:
The manner in which deoxyribonucleoside triphosphates are added to the 3' end of a growing chain
This has resulted in a polynucleotide molecule that has polarity or directionality.
The DNA or RNA base sequence is read in a 5' to 3' direction
Physical Structure of DNA
A DNA molecule → A double-helix comprising two DNA strands
DNA double-helix is not the same as the a-helix of proteins
Observation of DNA from Maurice Wilkins and Rosalind Franklin of King’s College, London in the early 1950s:
It is a long, thin molecule, diameter 2 nm
It consists of 2 strands
It is coiled in the form of a double-helix, the helix making one complete twist every 3.4nm [34 angstrom, Å (1 Å = 1 x 10-10 m)]
It has 10 bases to each complete turn of the helix (10 nucleotides on each strand)
Observation of DNA from Erwin Chargaff et al in 1951:
The base composition of the DNA of an organism is constant throughout all the somatic cells (not gametes) of that organism and is characteristic for a given species
Eg: Skin cells and liver cell have 20 % A; 20 % T; 30 % C; 30 % G in their DNA
There is always equal proportion of adenine (A) and thymine (T) and equal proportion of guanine (G) and cytosine (C)
%A = %T ; %G = %C
There is always equal proportion of purines (A + G) and pyrimidines (C + T)
A + G = C + T
Observation of DNA from Watson and Crick:
Development of double-helix DNA model involving specific complementary base pairing between A on one DNA strand and T on the other, and between G on one strand and C on the other
Physical Structure of DNA — Double-Helix
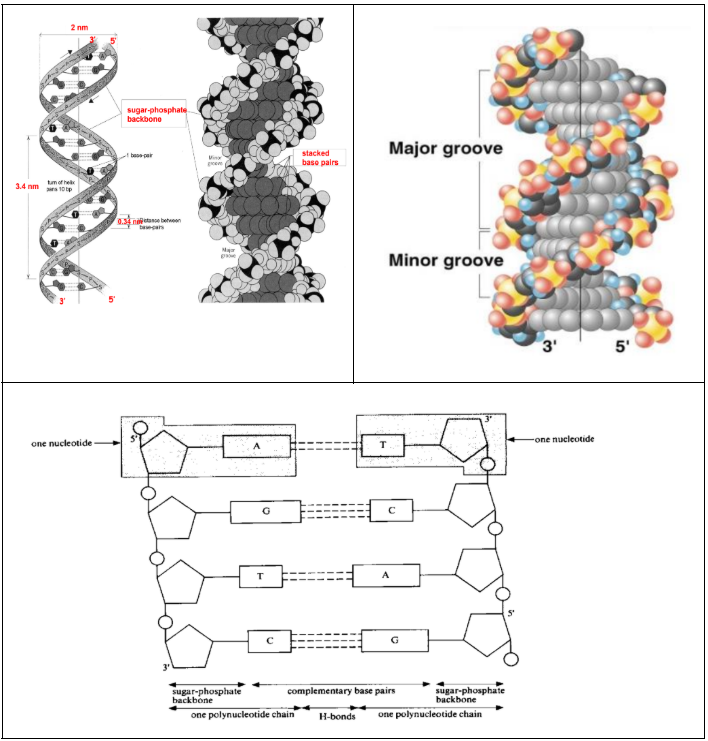
Main Features:
DNA consists of two polynucleotide strands / chains.
Each strand forms a right-handed helix and the two strands coil around each other to form a double-helix.
Terminology: 1 DNA molecule = 1 DNA double-helix = 2 polynucleotide strands / chains
The diameter of the helix is uniformly 2 nm.
There is just enough space for 1 purine and 1 pyrimidine in the centre of the double-helix.
The strands run in opposite directions (antiparallel)
One strand is oriented in the 5’ to 3’ direction whilst the other is oriented in the 3’ to 5’ direction
Each strand has a sugar-phosphate backbone with:
Phosphate groups that project outside the double-helix since they are hydrophilic; and
Nitrogenous bases that orientate inwards toward the central axis at almost right angles, away from the surrounding aqueous medium, since they are relatively hydrophobic
The bases of the opposite strands are bonded together by relatively weak hydrogen bonds between the nitrogenous bases
Complementary base pairing
Base pairs are stacked 0.34 nm (3.4 Å) apart along the central axis of the helix
This allows for hydrophobic interactions between the base pairs to contribute to overall stability of the molecule
The double-helix makes a complete turn every 10 base pairs, so each turn is 3.4 nm (34 Å).
There are grooves of unequal sizes between the sugar-phosphate backbones called the major groove and minor groove
Both these grooves are large enough to allow protein molecules to gain access and make contact with the bases
Accessing these bases lets proteins identify specific DNA sequences without unzipping the double helix
Physical Structure of DNA — Double-Helix — Complementary base pairing
Occurrence:
Between A and T → 2 hydrogen bonds
Between C and G → 3 hydrogen bonds
A-T and C-G pairs are the only ones that can fit the physical dimensions of the double-helix.
Significance of complementary base pairing:
The base sequence in one strand determines the base sequence in the complementary strand.
Eg: If one strand has the sequence 5’-GAATTC-3’, the complementary strand would have the sequence 3’-CTTAAG-5’.
This is necessary in DNA replication and transmission of the genetic information stored
The three-dimensional structure of DNA is only stable when the base pairs are complementary
The weak hydrogen bonds make it relatively easy to separate the two strands of the DNA (eg: by heating)
Separating the A-T pair by heating is easier than separating the G-C pair, since the A-T pair involves 2 hydrogen bonds and the G-C pair involves 3 hydrogen bonds
Why Complementary Base Pairs:
Steric (spatial) Restrictions:
The sugar-phosphate backbone of each polynucleotide chain has a regular helical structure
The DNA double-helix has a uniform diameter of 2 nm.
T and C are pyrimidines, which have a single ring. A and G are purines, which are about twice as wide as pyrimidines.
Purine + Purine = Too wide
Pyrimidine + Pyrimidine = Too narrow
Purine + Pyrimidine = Width consistent with data
The solution is always to pair a purine with a pyrimidine.
Hydrogen Bond Factors:
Each nitrogenous base has chemical side groups (such as H, N and O) that can form hydrogen bonds with its appropriate partner.
Such chemical side groups in purines and pyrimidines have well defined positions.
A is capable of forming 2 hydrogen bonds with T, whilst G is capable of forming 3 hydrogen bonds with C.
Variation of linear base sequence:
Although the base pairing rules dictate the combinations of nitrogenous bases that form the ‘rungs’ of the double-helix, they do not restrict the base sequence along each DNA strand. The linear sequence of the four bases can be varied in countless ways.
For example:
If there is 1 nucleotide, there are 41 = 4 combinations of bases
If there are 10 nucleotides, there are 410 = 1 048 576 combinations of bases.
Human-beings have 3 x 109 nucleotide pairs. We would have 43 x 109 combinations of bases
Hence, each gene has a unique base sequence
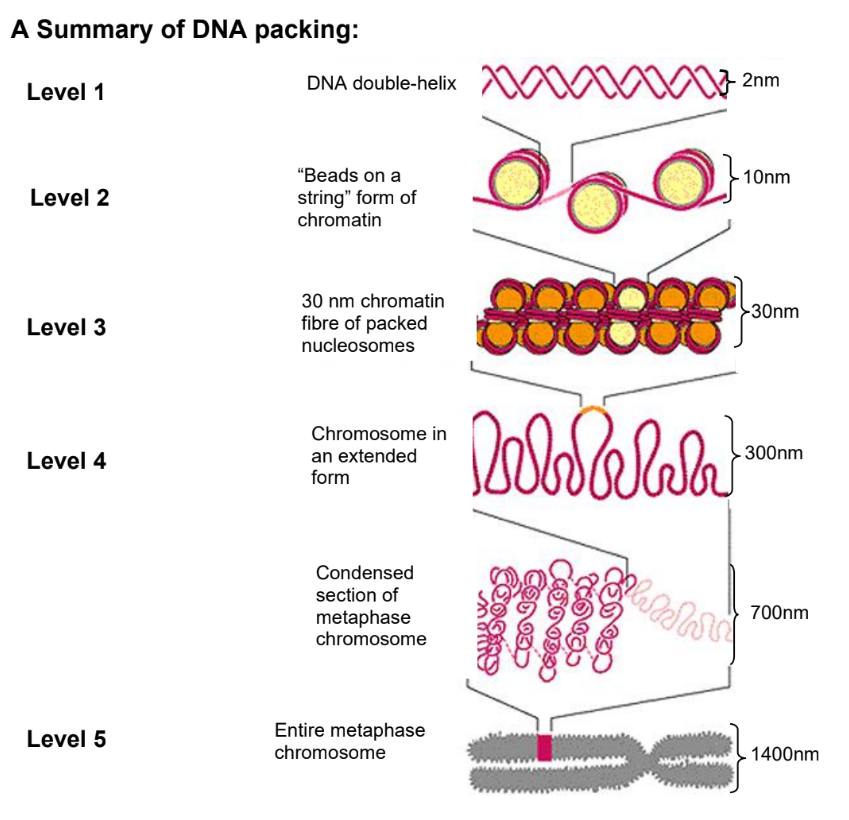
Physical Structure of DNA — Packing of DNA in Eukaryotic Chromosomes
A human cell contains 46 chromosomes (excluding gametes):
Each chromosome is a single DNA molecule bundled up with various proteins.
We inherit 23 chromosomes from each parent (2×23)
Each set of 23 chromosomes encodes a complete copy of our genome and is made up of 6 × 109 nucleotides (or 3 × 109 base pairs).
Genome = 22 pairs of autosomes + 1 pair of sex chromosome = 46 chromosomes
If the DNA in a human chromosome were stretched as far as it would go without breaking, it would be about 5 cm long
The 46 chromosomes (combined) in all represent about 2m of DNA
For each chromosome to be properly distributed to each daughter cell during cell and nuclear division, they must condense into structures that are more easily managed
A multilevel packing system that involves various proteins helping in the folding and condensation of DNA via a precise process is necessary to achieve a highly compact chromosome
Mitosis:
Prophase → Replicate, then condense
Metaphase → The chromosomes (X- shape due to 2 DNA molecules within 1 chromosome) align perfectly along the center of the cell, an imaginary line known as the metaphase plate.
Anaphase → Pulling apart of chromosomes
Telophase → The separated chromosomes reach the opposite poles and begin to uncoil back into long, thin strands. A new nuclear envelope forms around each set of chromosomes, creating two distinct nuclei
Cytokinesis → Cell splits to from a parent cell to 2 daughter cells
Physical Structure of DNA — Stable, Invariant Storage of Genetic Information
Characteristics of genetic information:
The genetic information that must be stored / preserved lies in the specific order of the base pairs
Base sequence must be stable and invariant (doesn’t change)
DNA is a marvellous device for the stable storage of genetic information
It is relatively resistant to spontaneous changes (mutations)
Structural features stabilises the DNA double-helix (both prokaryotes and eukaryotes):
Extensive hydrogen bonds between base pairs
Each hydrogen bond is, by itself, weak, but together, they are strong
Hydrophobic interactions between the stacked base pairs
Exposure to outside influences of only the sugar-phosphate backbone.
Nitrogenous bases being safely tucked inside the double-helix.
For eukaryotes only: DNA double-helix being tightly wound around histones to form a repeating array of nucleosomes
The nucleosomes are eventually folded into higher order structures such as the chromosome, in which the DNA is prevented from thermal and physical damage.
Structural features that results in invariant base sequence:
Specific, complementary base pairing between DNA strands
Genetic information is redundant (present more than once) in the DNA molecule
If the base sequence in one of the two strands is accidentally altered, the cell discards the damaged strand.
It then makes a perfectly good strand by using the remaining intact strand as a template, following Chargaff’s rules of complementary base pairing.
The redundancy of genetic information helps to maintain its integrity.
Replication of DNA — DNA Strands as Templates for Replication
The two strands of DNA are complementary – each stores the information necessary to reconstruct the other.
When a cell copies a DNA molecule, each strand (both strands) serves as a template for ordering nucleotides into a new, complementary strand.
Where there was one double-stranded DNA molecule at the beginning of the process, there are now two – each an exact replica of the ‘parent’ molecule to ensure faithful transmission of genetic instructions.
When DNA is ready to multiply, its 2 strands unwind and pull apart
Along each strand, a new strand forms through complementary base pairing
The old strand and new strand wind, forming 2 DNA molecules
Replication of DNA — Models of DNA Replication
*Semi-conservative Model (Watson and Crick):
The two DNA strands unwind and separate from each other by the breakage of hydrogen bonds between complementary base pairs
Each DNA strand then acts as a template for the assembly of a complementary strand.
Nucleotides line up singly along the template DNA strand according to Chargaff’s rule of complementary base pairing (A-T and G-C)
DNA polymerases join the nucleotides together at their sugar-phosphate moieties.
Upon completion of DNA replication, 2 identical daughter DNA molecules are produced from a single parental DNA molecule.
Each of the two daughter DNA molecules consists of one parental DNA strand and one newly-synthesised daughter DNA strand.
Conservative Model:
Parental DNA molecule emerges from the replication process intact
It is conserved, and generates DNA copies consisting of entirely new molecules.
The 2 parental DNA strands reassociate after acting as templates for new strands, restoring parental double helix
Dispersive Model:
All four strands of DNA following replication have a mixture of old and new DNA.
Replication of DNA — Evidence for Semi-Conservative Replication
Experiment:
The experiment used 2 isotopes of nitrogen: 14N & 15N
For many generations, cells of the bacterium, Escherichia coli, were grown on medium containing only the ‘heavy’ isotope of nitrogen, 15N
15N was incorporated into ALL the nitrogenous bases and the resulting DNA is known as 'heavy DNA'
The bacteria were then transferred to medium containing only the ‘light’ isotope of nitrogen, 14N and allowed to divide just once.
This produces the 1st generation of bacteria.
Density-gradient centrifugation (in caesium chloride, CsCl) was performed on a DNA extract from the bacteria. DNA is separated on the basis of density.
Heavier 15N DNA molecules are denser than the 14N DNA molecules, hence 15N DNA molecules are spun further down in the centrifuge tube where CsCl was denser.
Lighter 14N DNA molecules were closer to the top where CsCl was less dense
Hybrid DNA (one strand containing 15N, the other 14N) have intermediate density → Appears in the middle of the tube
These bacteria were allowed to undergo a second round of replication and binary fission (in the presence of 14N) producing the 2nd generation. DNA was again separated by density centrifugation.
CsCl Density-gradient Centrifugation:
CsCl solution is centrifuged at very high speeds for 48-72 hours
CsCl density gradient with increasing density towards the bottom (the curve part) of the centrifugation tube is formed
This is due to the equilibrium between:
Sedimentation of the CsCl to the bottom of the spinning tube as a result of centrifugal forces; and
Diffusion of CsCl towards the top of the tube
DNA molecules move to the position where their density equals that of CsCl and ‘floats’ at that position.
Results:
Generation 0 (parental) → All heavy DNA (15N/15N)
1st Generation → All hybrid DNA, intermediate in density (14N/15N)
2nd Generation → 50% hybrid DNA (14N/15N), 50% light DNA (14N/14N)
Mechanism of DNA Replication
The process is:
Extremely complex
Extremely fast
Extremely accurate
Requires the cooperation of a large team of enzymes and other proteins, as well as the expenditure of ATP
General steps:
Location of Origins of Replication
Separation of Parental DNA Strands
Synthesis of RNA Primer
Synthesis of Daughter DNA Strands
Mechanism of DNA Replication — Location of Origins of Replication
DNA replication begins at one or more sites on the DNA molecule called origins of replication (oriR)
Each oriR is a specific sequence of nucleotides, which is generally A-T rich
There are only 2 hydrogen bonds between each A-T base pair, hence it is easier to disrupt the bonds as less energy is needed to overcome them
Steps:
Initiator proteins, proteins that initiate DNA replication, recognise this A-T rich, oriR sequence and bind to this sequence [initiator proteins do not break the hydrogen bonds between the nitrogenous base pairs]
The DNA double-helix is separated into two strands, where ATP is required, forming a replication ‘bubble’.
The length of DNA unwound to initiate replication is typically ~ 50 base pairs.
At each end (2 ends) of a replication bubble is a Y-shaped structure called a replication fork, where the new strands of DNA are synthesised. The two replication forks move away from the oriR as replication proceeds bidirectionally (unzipping happens both ways), until the entire DNA molecule is separated
![<p>DNA replication begins at <strong>one or more sites</strong> on the DNA molecule called <strong>origins of replication (oriR)</strong></p><ul><li><p>Each oriR is a <strong>specific sequence of nucleotides</strong>, which is generally <strong><u>A-T rich</u></strong> </p><ul><li><p>There are only 2 hydrogen bonds between each A-T base pair, hence it is easier to disrupt the bonds as less energy is needed to overcome them</p></li></ul></li></ul><p></p><p>Steps:</p><ol><li><p><strong>Initiator proteins</strong>, proteins that initiate DNA replication, recognise this A-T rich, oriR sequence and bind to this sequence <em>[initiator proteins do not break the hydrogen bonds between the nitrogenous base pairs]</em></p></li><li><p>The DNA double-helix is separated into two strands, where <strong>ATP is required</strong>, forming a replication ‘bubble’.</p></li><li><p>The length of DNA unwound to initiate replication is typically ~ 50 base pairs.</p></li><li><p>At each end (2 ends) of a replication bubble is a Y-shaped structure called a <strong>replication fork</strong>, where the new strands of DNA are synthesised. The two replication forks move away from the oriR as replication proceeds bidirectionally (unzipping happens both ways), until the entire DNA molecule is separated</p></li></ol><p></p>](https://assets.knowt.com/user-attachments/2113bab8-c509-4ee8-b5a4-d2a202d3996f.png)
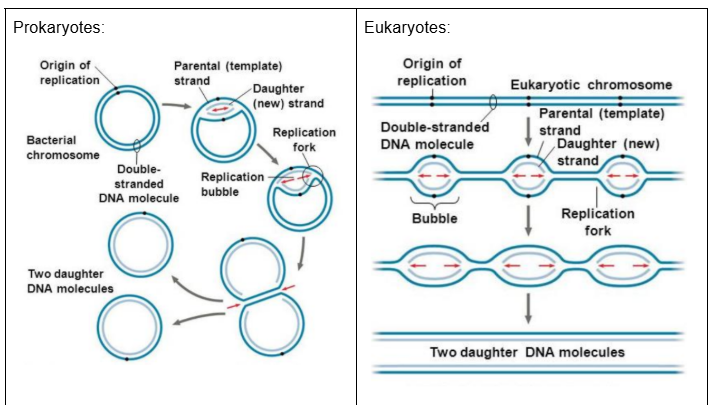
Mechanism of DNA Replication — Location of Origins of Replication — Prokaryotes VS Eukaryotes
Prokaryotes (Bacteria):
The prokaryotic chromosome is a small circular DNA molecule, with a single origin of replication
Hence, DNA replication proceeds bidirectionally from the origin of replication to a termination site located approximately halfway around the circular chromosome, resulting in the synthesis of two daughter DNA molecules
Eukaryotes:
The eukaryotic chromosome is much larger and consists of a linear DNA molecule, with multiple origins of replication
Hence, multiple regions of the chromosome undergo replication at the same time
The advantage of having multiple origins of replication in eukaryotes is speed
Multiple replication bubbles form simultaneously and eventually fuse, thus speeding up the copying of very long DNA molecules
Replication takes approximately eight hours in human cells with multiple origins of replication. If it had only one origin of replication, it would take 100 times longer. This is important given the much larger size of a eukaryotic chromosome.
Steps:
Replication begins at multiple origins of replication, where the two parental strands separate to form replication bubbles.
The bubbles expand laterally, as DNA replication proceeds bidirectionally.
Eventually, the replication bubbles fuse and synthesis of the daughter strands is complete
Mechanism of DNA Replication — Separation of Parental DNA Strands
The need for separation of parental DNA strands:
During replication, there is a continual need for the separation of the base pairs (by breaking the hydrogen bonds between base pairs) of the parental DNA molecule so that both DNA strands can act as templates for the synthesis of daughter DNA strands.
An origin of replication serves as a site where this separation initially occurs.
The strand separation at each fork then moves outward from the origin via the action of a group of proteins.
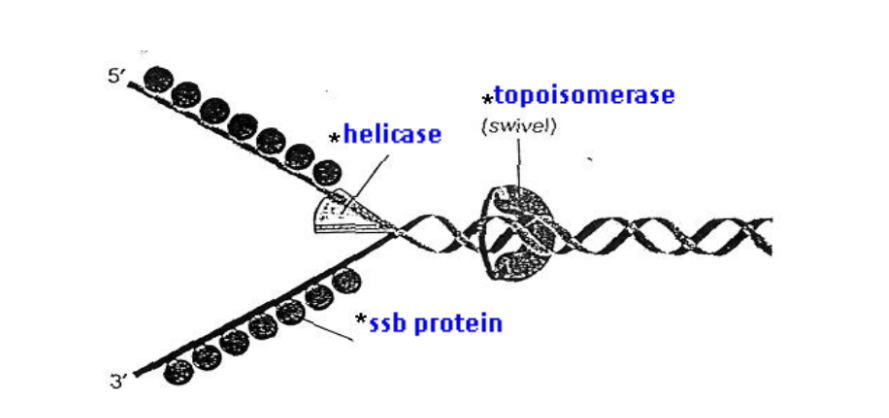
Three proteins involved in the separation process:
Helicases → Unwind and separate
Single-strand DNA binding proteins → Stabilise and protection
Topoisomerases → Relieves tension ahead
Helicases (enzyme):
After initiation, "unwinding" enzymes called helicases bind to one strand of the DNA molecule.
Using ATP as an energy source, helicases break the hydrogen bonds holding the two strands of DNA together.
This unwinds the DNA double-helix and separates the parental DNA strands at the region of the replication fork.
Each of the two parental DNA strands serve as the template for the synthesis of a new DNA strand
Single-strand DNA-binding proteins (SSB proteins):
The unwound single-stranded portion of the DNA double-helix is temporarily stabilised by the binding of single-strand DNA-binding proteins.
Each SSB protein prefers to bind next to a previously bound molecule, long rows of this protein form on a DNA single strand.
This prevents the single-stranded (ss) DNA from re-annealing (form DNA double-helix again) to reform the duplex.
This keeps the two parental strands in the appropriate single-stranded condition to act as template.
This also protects the ssDNA, which is very unstable, from being degraded
Topoisomerases:
Unwinding causes tighter twisting / supercoiling ahead of the replication fork, resulting in tension / torque
Topoisomerases cleave (cut) a strand of the helix (ahead of the replication fork) to create a transient single-stranded nick
This relieves strain on the DNA molecule by allowing free rotation (swiveling) around the intact strand, and then reseal the broken strand
Mechanism of DNA Replication — Limitations of DNA polymerases
Limitation 1:
None of the DNA polymerases can initiate the synthesis of a DNA strand on its own
Solution 1:
To initiate synthesis of a DNA strand in the cellular context, an RNA primer is used
Limitation 2:
DNA polymerases only add dNTPs (nucleotides) to the free 3’ end of a growing DNA strand, never to the 5’ end. Thus, a growing DNA strand can only elongate in the 5’ to 3’ direction
Another factor to consider: The two strands of a DNA double-helix are antiparallel (their sugar-phosphate backbones run in opposite directions)
Problem: Continuous synthesis of both DNA strands at a replication fork is not possible.
Solution 2:
Leading Strand Synthesis & Lagging Strand Synthesis
Mechanism of DNA Replication — Synthesis of RNA Primers (solution 1)
A portion of the parental DNA strand serves as template for making the RNA primer with the complementary base sequence
An enzyme called primase joins the ribonucleotides to make the primer. The primer is about 10 nucleotides long in eukaryotes. Hydrolysis of ATP is involved.
The RNA primer provides a free 3’ OH end that DNA polymerase can extend, thereby priming the synthesis of the daughter DNA strand.
A DNA polymerase with 5’ to 3’ exonuclease activity (DNA polymerase I) later replaces the RNA nucleotides of the primers with DNA versions.
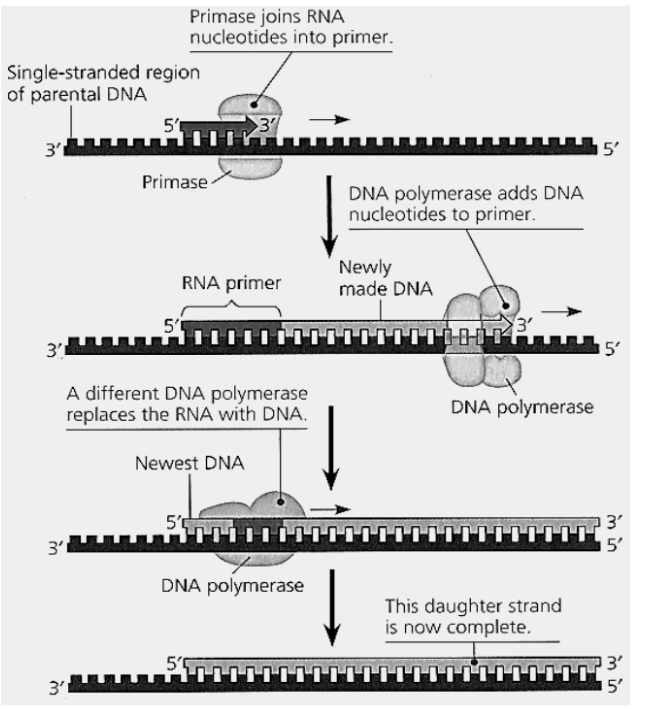
Mechanism of DNA Replication — Synthesis of Daughter DNA Strands
Complementary base pairing between templates and (new) nucleotides
The parental DNA strands, separated at the replication fork and each primed with an RNA primer, serve as the templates for semi-conservative DNA replication.
DNA polymerase reads in the 3’ to 5’ direction of the template strand and assembles the nucleotide monomers (deoxyribonucleoside triphosphates, dNTPs) in the 5’ to 3’ direction (dNTPs are added to the 3’ end of the growing strand) for the newly-synthesised daughter DNA strand based on complementary base pairing
The error frequency of the newly-synthesised DNA strand must be low to ensure that replication is carried out accurately.
When an incorrect base pair is recognised, DNA polymerase reverses its direction by one base pair of DNA. The 3'→ 5' exonuclease activity of the enzyme allows the incorrect base pair to be excised (removed) → this activity is known as proofreading
Phosphodiester bond formation between growing daughter DNA strand and incoming nucleotide
With an RNA primer anchoring the start of the daughter DNA strand, DNA polymerases catalyse the polymerisation (‘joining’) of the strand.
All DNA polymerases catalyse phosphodiester bond formation between a growing daughter DNA strand and an incoming nucleotide.
Because of active site specificity of the DNA polymerases, syntheses of both daughter DNA strands can only occur in one direction, in the 5’ to 3’ direction (2nd limitation of DNA polymerases)
The addition of nucleotide (dNTP) to the growing daughter DNA strand requires the formation of a phosphoester bond between the free 3’ hydroxyl group of the last nucleotide in the growing strand and the free 5’ phosphate group of the incoming dNTP.
In this process, the incoming dNTP loses a pyrophosphate group when they form the phosphoester bond with the growing daughter DNA strand. The energy released from pyrophosphate bond breakage is coupled to phosphoester bond formation.
Mechanism of DNA Replication —Synthesis of Daughter DNA Strands — Leading VS Lagging Strand
Leading Strand Synthesis:
Leading strand is: The complementary daughter DNA strand that is continuously synthesised as a single polymer along the template strand.
Polymerised in the mandatory 5’ to 3’ manner towards the replication fork
Lagging Strand Synthesis:
Lagging strand is: The complementary DNA strand that is discontinuously synthesised as a series of short fragments known as Okazaki fragments
Each Okazaki fragment is polymerised in the mandatory 5’ to 3’ manner against the overall direction (towards replication fork) of the replication fork.
About 100 to 200 nucleotides per fragment in eukaryotes
How Okazaki fragments work:
Each Okazaki fragment requires an RNA primer for strand initiation
The Okazaki fragments are then ligated in two steps to produce a continuous DNA strand
DNA polymerase (specifically DNA polymerase I) removes the RNA primer and replaces it with dNTPs
DNA ligase - a linking enzyme - catalyses the formation of a phosphoester bond between the 3’ end of each new Okazaki fragment and the 5’ end of the growing daughter DNA strand
End Replication Problem
End replication problem:
Occurs in linear chromosomes (i.e. in eukaryotes only) as DNA polymerase is incapable of completely replicating all the way to the ends of linear chromosome, leading to shortening of telomeres with each round of DNA replication.
Telomere is a region of repetitive nucleotide sequences at the end of a chromosome
In mammalian cells, telomere sequence is always: TTA GGG … TTA GGG
More specifically, during DNA replication, the very end of the lagging strand is not replicated
Each time a cell with linear chromosome divides, a small section at the extreme 3’ end of the parental strand does not undergo DNA replication.
This is because when the final RNA primer at the end of lagging strand (at the 3’ end) is removed by DNA polymerase, there is no upstream strand onto which DNA polymerase can build to fill the resulting gap.
Hence the daughter DNA strand resulting from lagging strand synthesis would be shortened with each round of replication
This leaves a 3’ hangover of the parent strand
Replicated DNA gets shorter and shorter, showing the age