memory, persistence and C
1/115
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
116 Terms
what is Memory?
a collection of some data represented in the binary format
How Data is being stored in a computer system?
Machine understands only binary language that is 0 or 1.
Computer converts every data into binary language first and then stores it into the memory.
how to convert decimal to binary? binary to decimal?
quick maths:say and look @ examples
A program always executes in
main memory
The implementation of memory abstraction deals with what two things?
Memory Allocation and Address Mapping
Memory allocation is responsible for
allocating memory to processes
Address Mapping implements what
implements process address space abstraction that allows same code to run in different physical memory in different processes
What is the logical address
aka the virtual address, An address generated by the CPU
What is the physical address
address seen by the memory unit (loaded into the memory address register of the memory)
What hardware device performs the run-time mapping from virtual to physical addresses?
The memory-management unit (MMU).
What is the purpose of the relocation register in a simple MMU scheme?
It stores a base value that is added to every logical address generated by a user process to map it to a physical address.
How are logical addresses different from physical addresses?
Logical addresses:
are generated by the user program within a range (start at 0 to max)
are contiguous
can be generated at compile, load, or execution time
Physical addresses:
are calculated by adding the base value (relocation register) to the logical address(enables dynamic program relocation)
generated at runtime (execution time) by memory management unit (MMU) of CPU
addresses used in MAR (memory address register)
What are the goals of memory allocation?
High Utilization, High Concurrency, Be Fast
Define High Utilization and High Concurrency
ensure as much memory used as possible (minimize waste)
support as many processes as possibly needed
What are the two types of Memory Allocation?
Contiguous and Non-Contiguous Allocation
Define Contiguous Allocation
NO gaps
1. Fixed Partition allocation (parking lot) 2. Variable Partition allocation (side street parking)
Define Non-Contiguous Allocation
HAS gaps
a. Paging
b. Segmentation
c. Paged Segmentation
Fixed Partition Allocation
Idea: divide memory a priori into fixed partitions (can vary in size)
Allocation Policy: process P arrives needing k units of space: choose partition (Ri ) that is smallest but >= k (best-fit)
Utilization Issue: internal fragmentation: parts of allocated partition unused
Variable Partition Allocation
allocate memory chunks as needed (analogous to side street parking)
Allocation policies: process P arrives needing k units of memory
a. Best-fit: choose hole that is smallest but ≥ k
b. Worst-fit: choose largest hole
c. First-fit: choose first hole with size ≥ k
d. Next-fit: choose next hole with size ≥ k
deal with external fragmnetation
Internal vs External Fragmentation
Within the partition, when some of the partition allocated to process P goes unused:
Within the partition, when the partition allocated to P is used up, but there is still space left over in that partition: total memory exists to satisfy request, but not contiguous
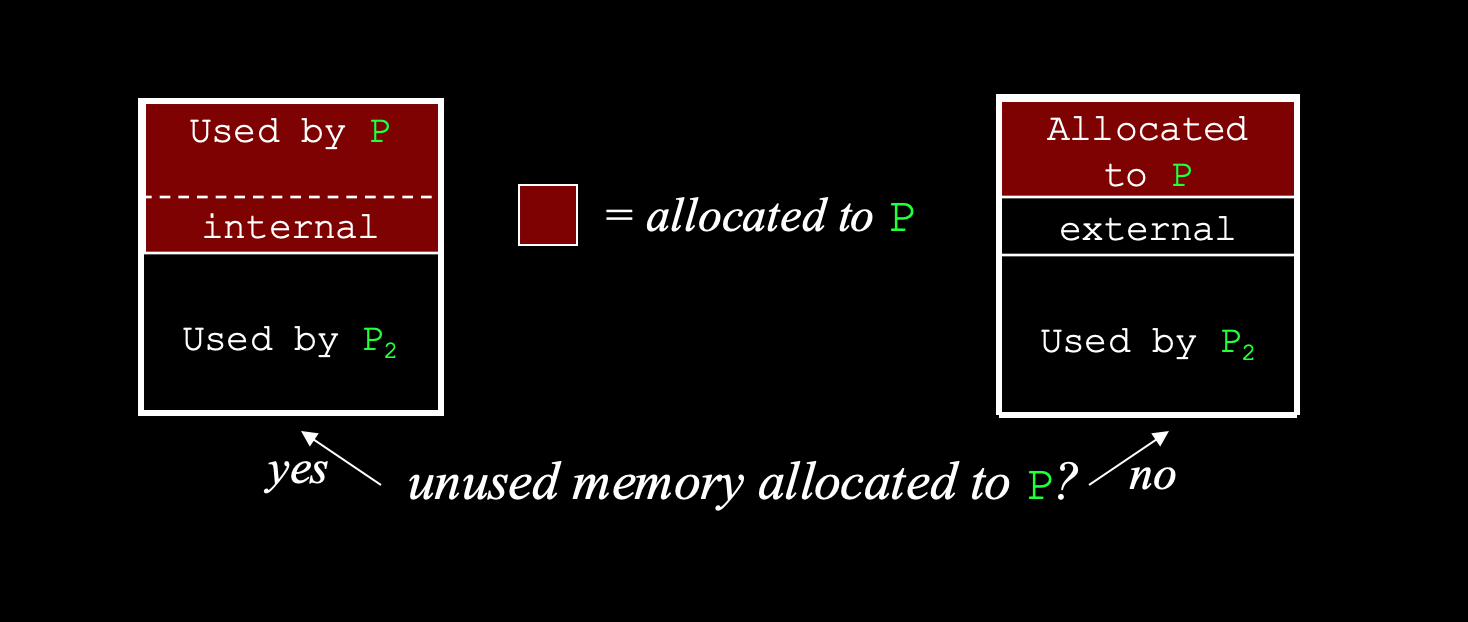
Which partition requires limit and relocation register?
Fixed Variable Partition
what are the limit and relocation register?
Limit register → contains range of logical addresses
Relocation register → contains value of smallest physical address
What is the role of the MMU in memory management?
it dynamically maps logical addresses to physical addresses at run-time.
Why does the user program never access real physical addresses directly?
The logical addresses generated by the program are translated to physical addresses only when the memory is accessed, maintaining abstraction and flexibility.
What are the three common strategies for selecting a free hole in contiguous memory allocation?
First fit, best fit, and worst fit.
What is a hole in memory allocation?
A block space of available memory
What is compaction?
all the free partitions are made contiguous and all the loaded partitions are brought together; eliminates external fragmentation but is inefficient for the OS
What is the idea behind paging?
The Idea behind paging is to divide the process(logical address space) into pages(chunks) so that, we can store them in the memory at different holes(frames).
One page of the process is to be stored in one of the frames of the memory. The pages can be stored at the different locations of the memory but the priority is always to find the contiguous frames or holes.
memory management scheme that permits a process’s physical address space to be non-contiguous
page size needs to be as same as frame size.
The sizes of each frame must be equal.
What is Paging exactly?
divide physical memory into fixed-size blocks (frames)
divide logical memory into same-sized blocks (pages)
within a page, memory contiguous but pages need not be contiguous or in order
The logical address is the address generated by the
CPU for every page while the physical address is the actual address of the frame where each page will be stored.
The logical address has two parts.
Page Number
Offset
the MMU converts the page number to the frame number.
How do you actually find the frame number though?(formula)
Frame Number * framesize + offset
What is the Page Table Implementation
Every Process’ Page Table: is kept in main memory
Its location kept in special registers (saved on context switch in PCB):
Page-table base register: (PTBR)• location of page table for process •
(Page-table length register: PTLR) - size of process page table
The problem with paging is that
it requires 2 memory access, which Translation Look-Aside Buffer (TLB) fixes
Size of Page table can be very big and therefore it wastes main memory.
CPU will take more time to read a single word from the main memory.
what is Translation Look-Aside Buffer (TLB)
fast-lookup hardware cache containing entries of process page table
contains only the entries of those many pages that are frequently accessed by the CPU.
Each page has its own corresponding
Page table in memory
Describe TLB hit and misses
TLB hit is a condition where the desired entry is found in translation look aside buffer. If this happens then the CPU simply access the actual location in the main memory.
However, if the entry is not found in TLB (TLB miss) then CPU has to access page table in the main memory and then access the actual frame in the main memory.
TLB miss results in change of cache contents
High hit ratio due to “locality”(close to CPU)
Some TLBs store address-space identifiers (ASIDs) in each TLB entry – uniquely identifies each process to provide addressspace protection for that process
What is (EAT)
Effective Access Time — (Hit Ratio Cache Access Time) + (Miss Ratio (Cache Access Time + Main Memory Access Time))
the average time it takes a system to access a page in either main memory or secondary storage.
According to the concept of Virtual Memory, in order to execute some process,
only a part of the process needs to be present in the main memory which means that only a few pages will only be present in the main memory at any time.
What is Demand Paging in OS?
DO NOT load any page in the main memory until it is required! otherwise keep in secondary memory ( occurs in virtual memory)
What is a Page Fault?
when the CPU tries to access a page that is not in the main memory(exists in virtual/logical address). The CPU then must retrieve the page from secondary memory, and if the number of page faults is high, increases effective access time.
What is Thrashing:
If the number of page faults is = to the number of referred pages
such high number of page faults cause the CPU to spend most of its time reading pages from secondary memory, leading to extremely high effective access time
Whenever any page is referred for the first time in the main memory, then that page will be found in the secondary memory.
What are the two issues to paging and their solutions?
Two memory accesses / logical address reference Solution: TLB
Very large page tables , Solution: Page the page tables!! (Multilevel, aka Hierarchical, Paging
What is Multilevel/Hierarchical Paging?
Break up the logical address space into multiple page tables
A simple technique is a two-level page table We then “page” the page table [p1][p2]
What is Segmentation?
partitions of logical address space / physical memory are variable, not fixed → partitions based on conceptual divisions rather then page size
There are Segment tables (one per process) , what do they consist of
Segment Number: s
Base: It is the base address of the segment
Limit: It is the length of the segment.
Segment Offset: d
Advantages of Segmentation and Paging
Segmentation:
Easier to implement protections and sharing:Each segment contains the same type of functions such as the main function can be included in one segment and the library functions can be included in the other segment.
Paging:
Can have multilevel paging that allows paging to be noncontiguous, but still suffers from external fragmentation.
How does the segment number work?
The Segment number is mapped to the segment table. The limit of the respective segment is compared with the offset. If the offset is less than the limit then the address is valid otherwise it throws an error as the address is invalid.
In the case of valid addresses, the base address of the segment is added to the offset to get the physical address of the actual word in the main memory.
What is paged segmentation?
the main memory is divided into variable size segments which are further divided into fixed size pages.
The logical address is represented as Segment Number (base address), Page number and page offset.
how does virtual memory work
When main memory lacks space for new pages, the OS replaces the least recently used or unreferenced pages by moving them to secondary memory, making room for the new pages.
The important jobs of virtual memory in Operating Systems are two. They are:
Frame Allocation
Page Replacement.
What are the three types of Page Replacement Algorithms
Optimal Page Replacement Algorithm
First In First Out Page Replacement Algorithm
Least Recently Used (LRU) Page Replacement Algorithm
Approximations of LRU
LFU
Page replacement is saying that:
If no free frames available during page fault, must evict a page -- but which?
First In First Out Page Replacement Algorithm
Replace the page that’s been in memory the longest
Optimal Page Replacement Algorithm
Evict the page that won’t be needed for the longest time
Not practical: Assumes that you know the reference string in advance.
Least Recently Used (LRU) Page Replacement Algorithm
Replace the page with the page which is less dimension of time recently used page in the past.
Approximations of LRU
a. Reference Bits: Approximates LRU:1 =More Recently Used 0 = Less recently Used
b. Reference Bitstrings: Reference Bitstrings, never shift, Replacement: Choose page with longest suffix of 0’s
Least Frequently Used (LFU)
also tries to approximate optimal.
predicts that page that will not be accessed for longest time in future is that which has been accessed the fewest time in past
What is swapping in virtual memory:
ready or blocked processes have no physical memory allocation. Instead, address space mapped to disk
Context switch: → swaps out running process → swaps in next running process
define Reference String”
Page number of consecutive memory references
what is Belady’s Anomaly:(w/FIFO page replacement)
Policy can do worse when it has more resources,
the number of page faults will get increased with the increment in number of frames.
Swapping vs. Demand Paging (Summary):
Swapping moves entire processes between RAM and disk to free memory, operating at the process level.
Demand Paging loads only needed pages into RAM when accessed, working at the page level.
Demand paging is more efficient
SOOO What If No Free Frames?
Page Replacement
what is locality
e tendency of a program to access a relatively small portion of memory repeatedly over a short period=. it is the basis of caching and demand-paging
What is the Working Set Model:
memory management approach where the "working set" refers to the set of pages a process is actively using within a given time window. It focuses on pages that have been recently accessed, assuming they are likely to be used again soon. The model helps optimize memory usage by keeping the working set in memory and minimizing page faults. If the working set exceeds available memory, thrashing may occur.
what is Zipf’s Law
the frequency of an item is inversely proportional to its rank
Malloc / Calloc:
malloc(size): Allocates a block of memory of the specified size (in bytes) and returns a pointer to it. The contents are uninitialized.calloc(num, size): Similar tomalloc, but it allocates memory for an array ofnumelements, each ofsizebytes, and initializes the memory to zero.
Free:
free(ptr): Deallocates the memory that was previously allocated withmallocorcalloc. After callingfree, the pointer is invalid, and accessing it leads to undefined behavior.
What Pointers Are in C:
Pointers are variables that store memory addresses. They allow indirect access to other variables, enabling dynamic memory management and efficient data structures.
Arrays and Pointers in C:
In C, arrays are essentially pointers to a contiguous block of memory. The name of the array is a pointer to its first element, and elements are stored in adjacent memory locations.
Threads in C:
Threads in C represent independent execution paths within a program. They share memory space, allowing for parallel execution, but require synchronization mechanisms (e.g., mutexes) to prevent race conditions.
Why C is Not Safe Compared to Java:
C is not memory-safe like Java because it allows direct memory manipulation via pointers, which can lead to errors like buffer overflows, memory leaks, or accessing uninitialized memory. In contrast, Java has automatic garbage collection and bounds checking, making it safer.
4o mini
explain the process of requesting frames from the disk (i.e. considering page faults)
When a page fault occurs, the OS loads the requested page from disk → memory. If there is no free frame, it uses a page replacement algorithm to evict an existing page.
The evicted page is written to disk if modified, and the new page is loaded into the freed frame. The page table is updated, and the CPU resumes execution. Frequent page faults can slow performance due to slow disk access.
What is the job of the filesystem
Job of FS is to hide the mess of disks(errors, bad blocks etc.) from higher-level software (disk hardware increasingly helps with this)
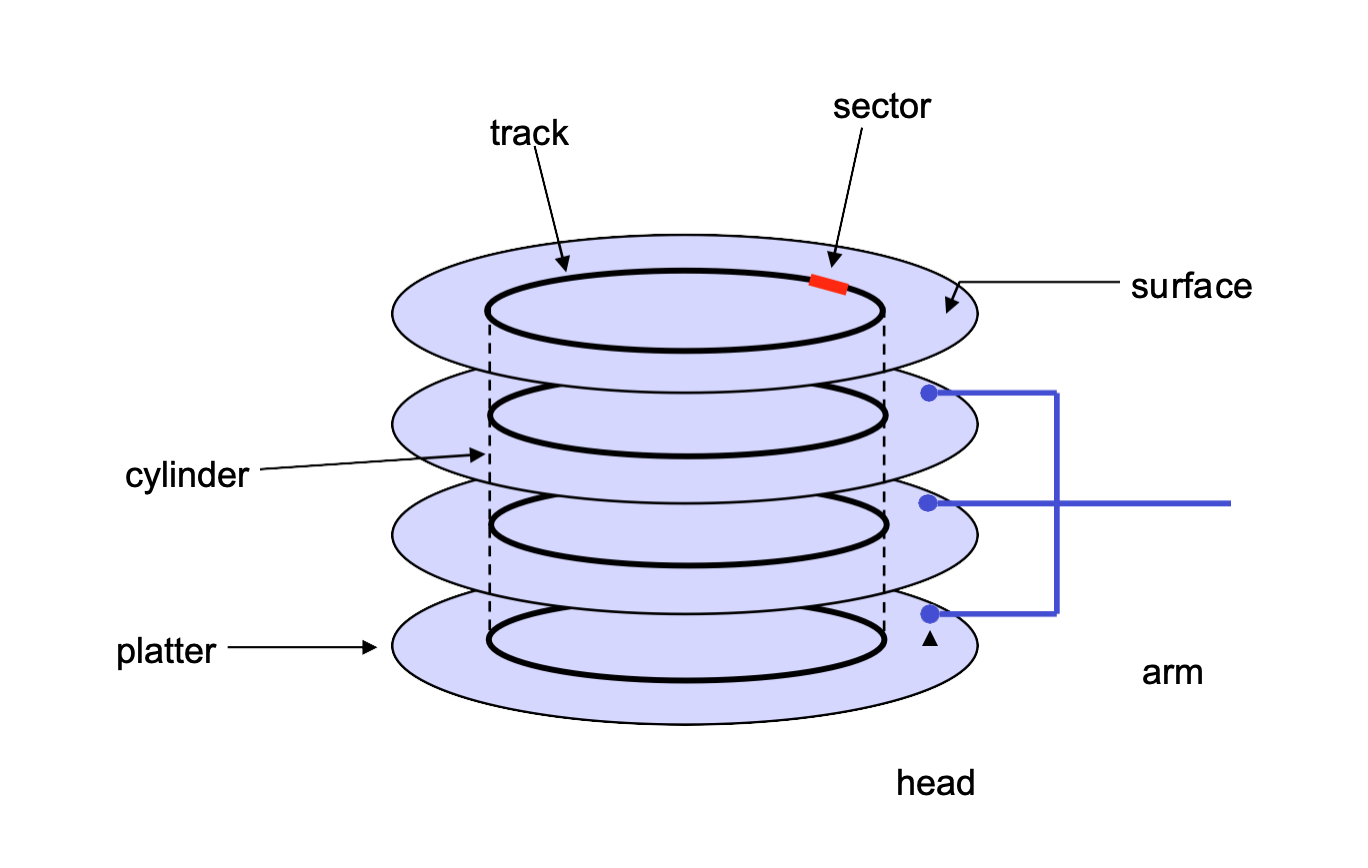
What is the Physical disk structure?
Disk components: – platters – surfaces – tracks – sectors – cylinders – arm – heads
Disk performance depends on a number of steps:
seek, rotation(latency), transfer
What is seek(disk):
moving the disk arm to the correct cylinder
• depends on how fast disk arm can move
What is rotation(disk):
waiting for the sector to rotate under head • depends on rotation rate of disk
What is transfer(disk):
transferring data from surface into disk controller, and from there sending it back to host
• depends on density of bytes on disk
When the OS uses the disk, it tries to minimize the cost of all
these steps: especially seek and rotation
It is important to know that with the disk,
The Disk moves, the Head does not
Main memory is essential a cache
for your disk
How persistence works essentially:
Write to memory, commit to disk, garbage collection
Reading log you know changes make
When committed you know disk has been updated
When garbage collected you know changes were made
What are the File system components?
Disk management: how to arrange collection of disk blocks into files
Naming : user gives file name, not track 50, platter 5, etc.
Protection : keep information secure
Reliability/durability : when system crashes, lose stuff in memory, but want files to be durable.
What are the File Usage/Access Patterns?
Sequential, Random, and (Content-based access)
Sequential Access
- bytes read in order
the OS read the file word by word. A pointer is maintained which initially points to the base address of the file. If the user wants to read first word of the file then the pointer provides that word to the user and increases its value by 1 word. This process continues till the end of the file.
Random Access
read/write element out of middle of array(give me bytes i-j)
three different file system techniques for allocating disk blocks
contiguous, linked, and indexed,
contiguous disk blocks
File header contains: first sector in file file size (# of sectors) Pros & cons: + fast sequential access + easy random access
Linked files
Each block, pointer to next on disk (Alto) File header pointer to first block on disk Pros&cons: + can grow files dynamically + free list managed same as file
Indexed files
User declares max file size; system allocates a file header to hold an array of pointers big enough to point to file size number of blocks file header disk blocks + can easily grow up to space allocated for descriptor + random access is fast
Multilevel indexed (UNIX 4.1)
efficient for small files, but still allow big files
File header: 13 pointers (fixed size table, pointers not allequivalent)First ten, pointers to data blocks. (If file is small enough, somepointers will be NULL.)
UNIX pros&cons:
simple (more or less)
+ files can easily expand (up to a point)
+ small files particularly cheap and easy
- very large files, spend lots of time reading indirect blocks
- lots of seeks
What are Inodes
node are the special disk block which is created with the creation of the file system. The number of files or directories in a file system depends on the number of Inodes in the file system.
each file is indexed by an Inode.
Inode includes the following information
Direct blocks: Pointers to the first 12 file blocks.
Single indirect pointer: Points to an index block for larger files.
Double indirect pointer: Points to a block of index blocks for even larger files.
Triple indirect pointer: Points to a block of pointers to index blocks, used for very large files requiring multiple levels of indirection.
How many blocks are in a byte?
Common block sizes are 512 bytes, 1 KB, 4 KB, or larger. So, a block isn't a fixed part of a byte but a collection of bytes.
Persistence in file systems involves
naming, directories, and the storage of file headers.
Naming and Lookup:
Users name files using text or icons, which are mapped to file indices. Directories act as tables that map names to file indices, allowing for file lookups.
File Header Storage:
File headers store metadata and are located separately from data blocks. In UNIX, headers are stored in an array in the outermost cylinders for reliability and to avoid corruption. This makes file headers smaller than blocks, so multiple headers can be fetched together.
Directory Structure:
Directories are organized hierarchically and stored as files themselves, containing name-index pairs. The file system allows reading directory files (e.g., via "ls") but restricts modification to the OS.