Big Data Final Exam
1/150
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
151 Terms
RDDs can hold ____ elements
primitive types: integers, character, booleans
sequence types: strings, lists, arrays, tuples, dicts (including nested)
scala/java objects (if serializeable)
mixed types
Pair RDDs
RDDs with key-value pairs
double RDDs
RDDs with numeric data
we can add, multiply, find mean, standard deviation, etc
RDDs are resilient because
if the data is lost the data can be reconstructed
if a partition fails we can reconstruct data
sitting on that partition, if the whole node fails we can reconstruct on another node
lazy execution
we free data at the record level as well, free data from the part once the child gets the data
transformations create
a new RDD
you can create RDDs from collections
sc.parallelize(collection)
**make sure to call pyspark first
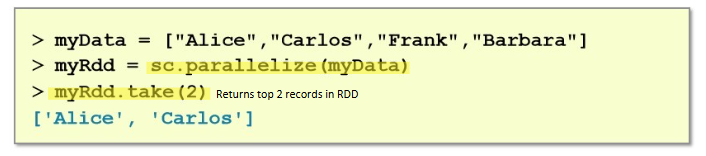
collection
array of mixed types
creating RDDs from collections is useful when
testing
generating data programmatically
integrating
creating RDDs from files
sc.textFile(“filename”)
accepts a single file, a wildcard list of files, or comma-separated list of files
each line in the file is a separate record in the RDD

files are referenced by ____ URI
absolute URI
relative URI

what happens when we do
MyweblogsRDD1= sc.textFile("file:/home/training/training_materials/data/weblogs/")
nothing, happens quickly because no action has been performed
what happens when we do
MyweblogsRDD1.count()
it will take a long time and count all the number of lines (records) in all the files in that directory
when creating RDDs from files, textFile maps
each line into a separate RDD element

textFile only works with _________ text files
line-delimited
sc.wholeTextFiles(directory)
maps entire contents of each file in a directory to a single RDD element
works only for small files (element must fit in memory)
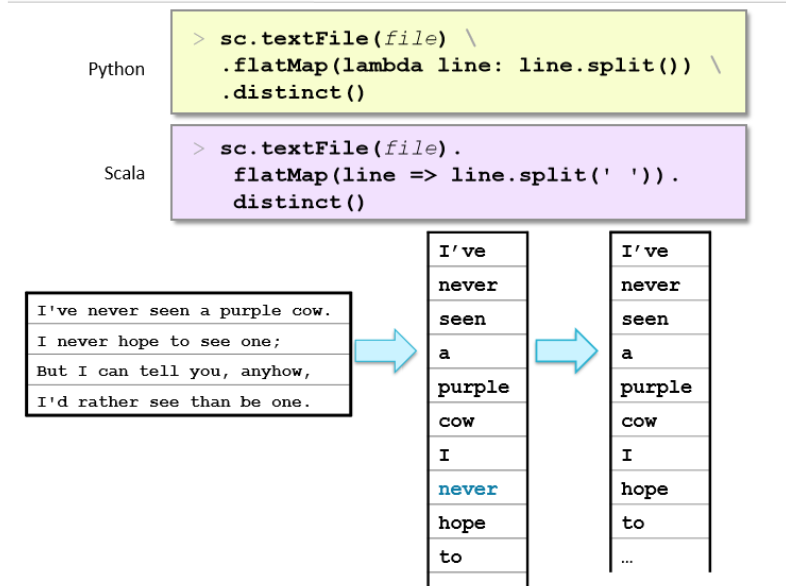
flatMap
maps one elements in the base RDD to multiple elements
distinct
filter out duplicates
sortBy
use provided function to sort
intersection
create a new RDD with all elements in both original RDDs (must be common to both)
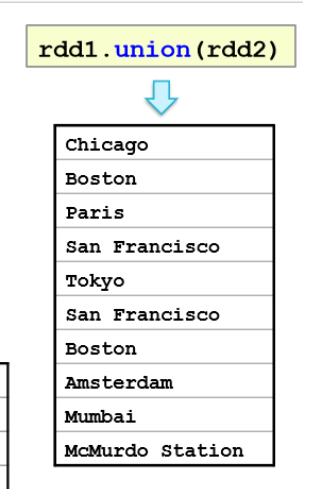
union
add all elements of 2 RDDs into a single new RDD
zip
pair each element of the first RDD with the corresponding element of the second
what does Rdd1= sc.textFile("purplecow.txt").flatMap(lambda line:line.split()) do
Takes purple cow file, creating RDD, can do it all in one line w lambda instead of creating RDD per line manually; splits based on white space because unspecified; iterates record by record and split based on white spaces (each word is split, not line)
flatmap vs map
map- number of records = number of records output
flatmap- number of input and output does not equal
.distinct()
creates a new RDD
.collect()
retains values as a list
what happens if u do .collect().distinct()
error because lists dont have attribute distinct
what doe rdd1.distinct().count() do
counts the number of distinct elements
what does Rdd1= sc.textFile("purplecow.txt").map(lambda line:line.split()) do
Will give 4 because map the first half gives 4 and number of inputs = output
Splitting but each record has multiple elements (sentence rather than by line)
rdd1.subtract(rdd2)
retains rdd1 elements that are in rdd1 but not rdd2
rdd1.zip(rdd2)
error if rdd1 and rdd2 do not have the same number of elements
will return
(rdd1,rdd2) pairs for each element
rdd1.union(rdd2)
first
returns the first element of the RDD in natural ordering 123, abc
foreach
apply a function to each element in an RDD
top(n)
returns the largest n elements using natural ordering
ex: A, C, D in RDD2; rdd2.top(1) will return D
sample
create a new RDD with sampling of elements
takeSample
return an array of sampled elements
double RDD operations
statistical functions like mean, sum, variance, stdev
takeSample is
an action not a transofrmation, which is why takeSample().count() will give an error
in takeSample and sample, True = ____ and False = _______
replacement
no replacement
RDDs can be created from:
files
parallelized data in memory
other RDDs
parallelizing data in memory
When you parallelize data, you're telling Spark to:
Split a collection (like a list or array) into smaller chunks and spread them across multiple workers/nodes.
Each chunk becomes a partition, and each partition is processed in parallel by different cores or machines.
pair RDDs
each element must be a key-value pair (2-element tuple)
keys and values can be any type
why do we use pair RDDs
use with map-reduce algorithms
many additional functions are available like sorting, joining, grouping, counting
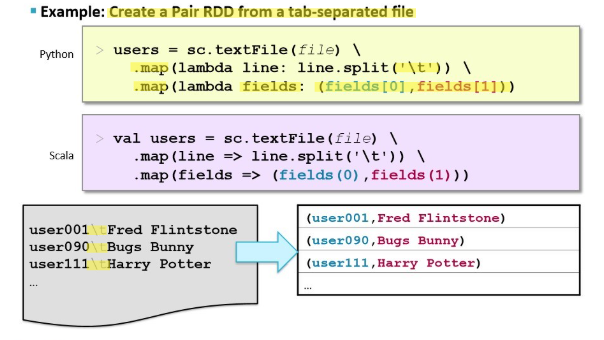
creating pair RDD from a tab-separated file
what happens if we do
Rdd1= sc.textFile(file)
File= "/home/training/mysparksolutions/Lecture12/127.txt"
error, it will look in HDFS but the file is in local file system so we do
File= "file:/home/training/mysparksolutions/Lecture12/127.txt"
Rdd1= sc.textFile(file)
File= "file:/home/training/mysparksolutions/Lecture12/127.txt"
Rdd1= sc.textFile(file)
Rdd1.count()
3
Rdd2= rdd1.map(lambda line: line.split('/t'))
Rdd2.count()
Gives 3
Rdd2.collect()
Does not give us a key-value pair because theres no parenthesis
Rdd3= rdd2.map(lambda fields:(fields[0],fields[1]))
Doesn't have to be called fields could have been x:x[0],x[1]
Rdd3.collect()
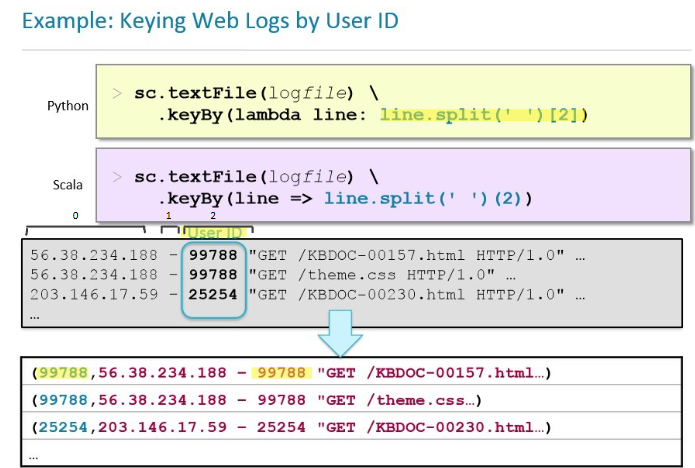
keyBy
transforms RDD into key-value pair RDD based on a keying function similar to map but creates KV pairs by extracting the key from each element in the RDD
Whatever functions you pass to it, it retains the key
Value will become part of value itself
mapping single rows to multiple pairs
mapreduce

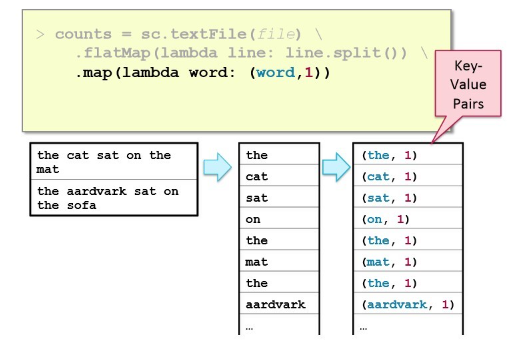
mapreduce in spark; map
a programming model for processing large datasets with a distributed algorithm on a cluster. It includes a 'Map' step that transforms input data into key-value pairs, followed by a 'Reduce' step that combines these pairs based on their keys.
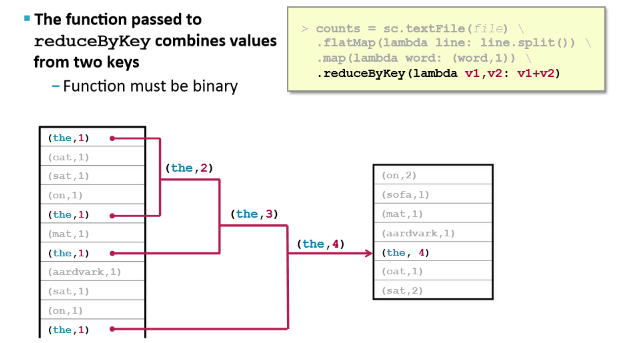
reduceByKey
the function might called in any order therefore must be commutative (addition/subtraction) or associative (muiltiplication/division)
why do we care about counting words
word count is challening over massive amounts data, using a single compute node would be too time-consuming and number f unique words could exceed available memory
statistics are often simple aggregate functions that are distributive in nature
mapreduce breaks complex tasks down into smaller elements which can be executed in parallel
many common tasks are very similar to word count
operations specific to pair RDDS
countByKey
groupByKey
sortByKey
join
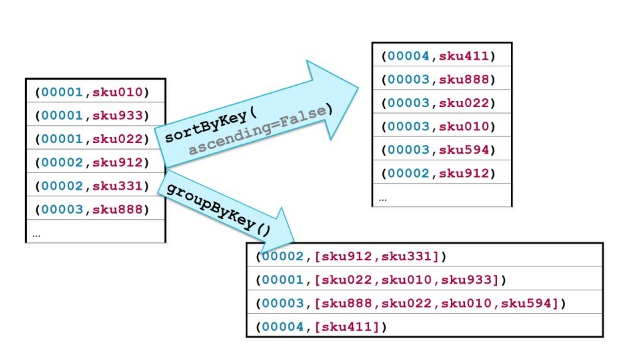
countByKey
returns a map with the count of occurrences of each key
groupByKey
groups all the values for each key in an RDD
sortByKey
sort in ascending or descending order
join
returns an RDD containing all pairs with matching keys from 2 RDDs that combines records from both RDDs based on the key.

keys
return an RDD of just the keys without the values
values
return an RDD of just the values without the keysValues from an RDD in Spark.
lookup(key)
returns values for a key
leftOuterJoin, rightOuterjoin, fullOuterJoin
joins including keys defined left, right, or full
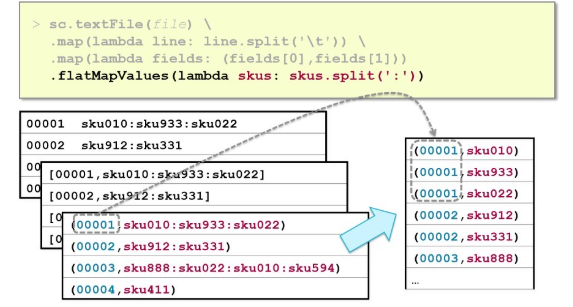
mapValues, flatMapValues
execute a function on just the values, keeping the key the same
mapreduce is a generic programming model for distributed processing

apache spark is
a fast and general engine for large-scale data processing
spark shell
interactive for learning or data exploration
python or scala
spark applications
for large scale data processing
python, scala, or javathat run on the Spark framework and utilize its various libraries for tasks such as data analysis and machine learning.
what does the spark shell do
provides interactive data exploration (REPL)
every spark application requires
a spark context
the main entry point to the spark API
the object that allows u to start working in Spark
RDD (resilient distributed dataset)
resilient- if data in memory is lost, it can be recreated from the storage device
distributed- processed across the cluster; RDD puts the files in memory rather than disk, when a file is in memory its RDD, we have partitions instead of blocksa collection of data elements that can be processed in parallel.
dataset- initial data can come from a file or be created programmatically
____________ are the fundamental unit of data in Spark
RDDs
most spark programming consists of
performing operations on RDDs
3 ways to create an RDD
file or set of files
data in memory
from another RDD
actions
returns values
transformations
define a new RDD based on the current ones
how to search for file in local file system
[training@localhost ~]$ sudo find / -name purplecow.txt
how to get into python spark
pyspark
in RDD we look for file in
HDFS home directory /user/trainingthe Hadoop Distributed File System (HDFS).
actions
count()
take()
collect()
saveAsTextFile(file)
count()
return the number of elements
take(n)
return an array of the first n elements
collect()
return an array of all elements from a distributed dataset to the driver program.
saveAsTextFile(file)
save to text file(s)
rdd1.saveAsTextFile("rdd1_saved")
creates a directory w 2 files one w a flag and the other w the actual content of the file containing the data from the RDD.
rdd1.count()
will show the count of the lines
RDDs are mutable or immutable?
immutable
data in an RDD is never changed
transform in sequence to modify the data as needed
common transformations
map(function)
filter(function)
map(function)
creates a new RDD by performing a function on each record in the base RDD
filter(function)
creates a new RDD including or excluding each record in the base RDD according to a boolean function
anonymous functions
functions with no name that must start with lambda (indicates that it is an in-line function)
lazy execution
data in RDDs is not processed until an action is performed
RDD is not truly loaded w the data until an action is performed
If we have an RDD and do a transformation we get a new RDD
In spark everythings a transformation until we get what we want
what happens when we do
rdd= sc.textFile("fjhskjhfssdjhdfjshsjfsk")
Once we press enter it will not give an error
rdd.count()
Now there will be an error bc it's acc looking for the file and loading the data
rdd5= rdd.map(lambda line:line.upper())
This is a transformation
No error
rdd5.count()
NOW u will have an error bc we tried to load data for a file that does not exist
This is intentional as Spark would not work otherwise
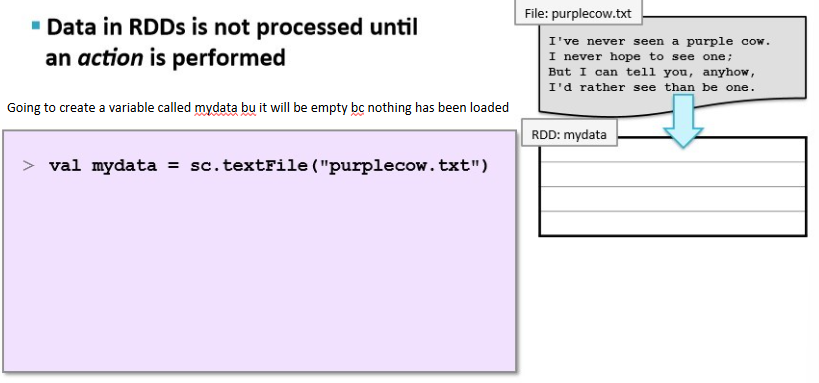
when we create a variable
it will be empty bc nothing has been loaded
when we take a variable and apply a transformation like map or filter
its still empty
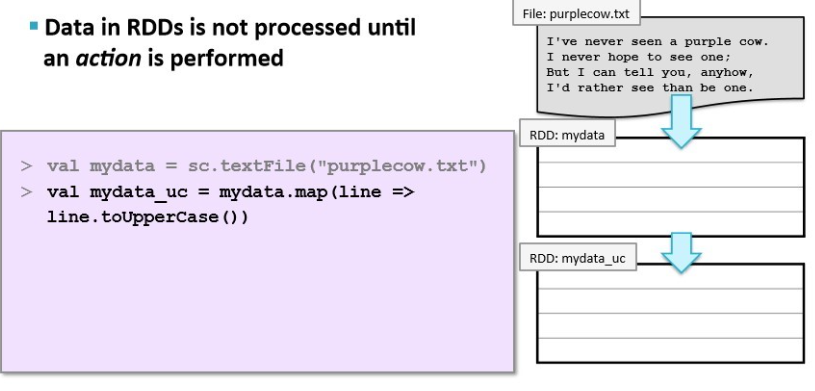
data in RDDs is not processed until
an action is performed
Each file will load 10 GB at a time -> a lot of memory gets utilized for one application -> could eat all of your memory
Loading all at once is not a good idea, loading piece by piece is even worse
When you call an action everything is empty; bottom most will ask for parent for data -> up the whole tree until it goes to the top and then it loads data into memory for that file now we occupy 10 GB in memory then we do a map and create an RDD and 2nd bottom most then free up the memory of the previous one
It will go one record at a time applies what it needs, frees up memory of previous one, then go to the next one
Once loaded it frees up the memory once the action is completed and go thru the same process again if the action is called again

spark depends heavily on the concepts of
functional programming
functions are the fundamental unit of programming
fnctions have input and output only
no state or side effects
in functional programming in spark, we pass ___ as input to other functions
functions
Map is a function (transformation); transformations are functions
rdd.map() we pass functions into map
we don’t have to create spark context because
it does it for us if we want to write a spark application we have to create a spark context
execution mode determines
which mode spark will use
2 forms of execution mode
local
cluster