Perceiving Objects and Scenes- week 9
1/30
Earn XP
Description and Tags
MBB1
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
31 Terms
The problem
Perception seems effortless but it is much harder than it seems.
One way to appreciate the difficulties in perceiving objects and scenes is to try to get a computer to do it.
It turns out that computers are worse at recognising objects than humans…
…and fail in very unpredictable ways.
State of the art
Currently, the state-of-the-art computer object recognition systems use artificial neural networks.
Athalye et al. (2018) investigated what sort of images these object recognition systems would misclassify.
Based on what they discovered, they then designed images that would fool these systems
Amazingly, TensorFlow’s InceptionV3 classifier thought that this was an image of a rifle!
Seemingly bizarre misclassifications such as this are unsettling and fairly common.
In fact, you don’t have to use specially-generated images to fool an image classifier.
Misclassifications commonly occur with natural images if they are presented at unexpected orientations (Alcon, 2019)
State of the art - with unusual angles
In the previous example, common objects presented at unusual angles were often misclassified.
This shows how hard it is to build an effective image classifier…
…and demonstrates that scene and object perception is quite difficult!
Difficulty 1: The Stimulus On the Retina is Ambiguous
All these lines form the same retinal image.
Thus, this 1D retinal image is ambiguous
Similarly, 2D retinal images are also ambiguous in that multiple stimuli can give rise to the same 2D retinal image
Difficulty 2: Objects Can Be Partially Occluded or Blurred
In the above photo, can you see my glasses that are partially occluded by the book?
Most likely a machine would have difficulty recognising my glasses because they are partially occluded
Difficulty 3: Objects look different in different poses and from different viewpoints
Machines find it hard to recognise objects when they appear in unexpected poses or are viewed from unexpected angles.
How Do Humans Succeed?
How do humans solve these problems and successfully perceive objects and scenes?
Although a complete explanation of this is beyond the scope of this lecture, we can make some progress towards this goal.
We start by discussing two competing schools of thought:
Structuralism
Gestaltism
Structuralism
Structuralism was proposed by Edward Titchener, based on his studies under Wilhelm Wundt.
Structuralism distinguishes between sensations and perceptions
Sensations: elementary processes occur in response to stimulation
Perceptions: Conscious awareness of objects and scenes
Structuralism claims that sensations combine to form perceptions.
In other words, according to Structuralism, conscious awareness is the sum of these elementary sensations....
…and contains nothing that was not already present in these elementary sensations.
Gestaltism
Gestaltism directly contradicts Structuralism.
The Gestaltists claim that conscious awareness is more than the sum of the elementary sensations.
In other words, conscious awareness can have a characteristics not present in any of the elementary sensations.
What evidence is there for this claim?
Evidence for Gestaltism
There are two main pieces of evidence that support the claim that conscious awareness can be more than the sum of the elementary sensations
These two pieces of evidence are:
Apparent motion
Illusory contours
Apparent Motion
In apparent motion an observer sees two stationary dots flashed in succession.
Although each of the dots is stationary, the observer perceives motion
In other words, the conscious awareness has a character (i.e. motion) not present in the elementary sensations (because they were both stationary).
The conscious percept of motion was constructed and was not present in the elementary sensations.
The physical stimulus itself is not moving
Illusory Contours
Illusory contours are a second example of where the conscious awareness has a characteristic not present in the elementary sensations.
Illusory contours are seen in locations where there are no physical contours.
The conscious awareness of the illusory contour is constructed – there is no physical contour at these locations.
Gestalt Principles of Grouping - intro
According to Gestaltism, humans are able to perceive objects and scenes because of perceptual organisation.
In other words, humans are able to make sense of a visual image because they can perceptually organise it into the constituent objects.
How do they do this?
Grouping and Segregation
Perceptual organisation is achieved by the processes of grouping and segregation.
Grouping is the process by which parts of an image are perceptually bound together to form a perceptual whole (e.g. the perception of an object)
Segregation is the process by which parts of a scene are perceptually separated to form separate wholes (e.g. the perception of separate objects).
Together, grouping and segregation allow a scene to perceptually organised into its constituent objects thereby allowing observers to make sense of the scene
Gestalt Principles of Grouping
Grouping is governed by 5 key principles.
The more of these principles that apply, the more likely components of an image will be grouped together to form a perceptual object.
Original Gestalt principles
Good continuation
Prägnanz
Similarity
Proximity
Common fate
Two additional ones (added later)
Common region
Uniform connectedness
Good Continuation
Remember we mentioned that occlusions can make object recognition difficult.
The principle of good continuation can help.
Aligned (or nearly aligned) contours are grouped together to form a single object.
This is why contour A is grouped with contour B, instead of with contours C or

Prägnanz
Literally German for “Good figure”.
Also known as “principle of good figure” or “principle of simplicity”
Essentially, groupings occur to make the resultant figure as simple as possible.
In the figure to the right you see a panda, not a collection of unconnected splotches.

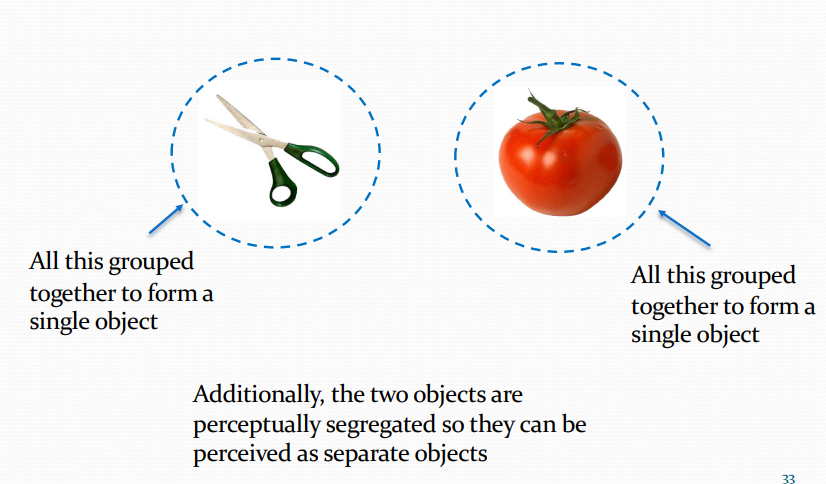
Similarity
The more similar objects are, the more likely they will be grouped together.
In a), all the dots are the same colour so it is unclear whether things are organised vertically or horizontally.
In b), colour similarity groups the dots into columns
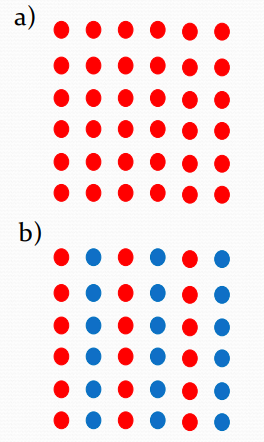
Proximity
The closer the dots are, the more likely they are to be grouped together.
In b), grouping by proximity forms horizontal rows.

Common Fate
Things that are moving in the same way are grouped together

Common region
Elements that are within the same region of space tend to group together (Palmer, 1992)

Uniform Connectedness
Connected regions with the same visual characteristics (e.g. colour) tend to group together (Palmer & Rock, 1994)
Segregation
It is not enough to group components of an image together to form an object, you also need to segregate the different objects in the scene from each other…
…and also segregate the objects from the background.
If you did not do this, you would perceive the entire image as just as single object
which would be very confusing
Much of the perceptual segregation literature has focused on figure-ground segregation.
The reason for this is that objects are normally perceived as “figures” and the background is typically perceived as the “ground”.
Consequently, if you can identify what the figure is, you can typically identify the objects.
But how does a person determine what is “figure” and what is “ground”?
Figural Properties
Regions of the image are more likely to be seen as figure if:
They are in front of the rest of the image
They are at the bottom of the image
They are convex
They are recognisable.
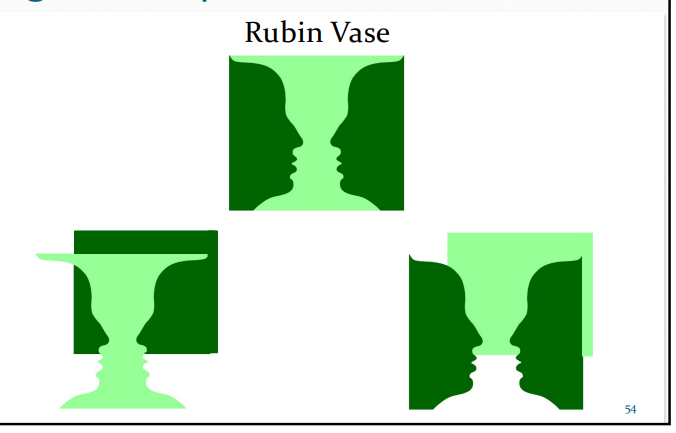
Figural Properties - Rubin vase
is ambiguous – it can be perceived as either a vase or two faces.
It is therefore not clear what the figure is – two faces or one vase.
If the vase is brought in front of the image it is then seen as the figure.
If the two faces are brought in front of the image, they are then seen as the figure.
This shows that depth ordering affects figure perception.
Take home message: Regions of an image in front of the rest of the image tend to be seen as figures (i.e. they are seen as objects)
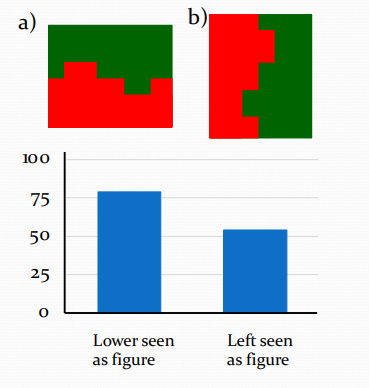
Figural Properties - at the bottom of the image
Most people perceive image (a) as a red object in front of a green background.
This is because lower areas are more likely to be seen as figures (i.e. are more likely to be perceived as objects)
However, there is no left-right bias.
Consequently, image (b) is ambiguous.
It is not clear which side is the figure and which side is the ground
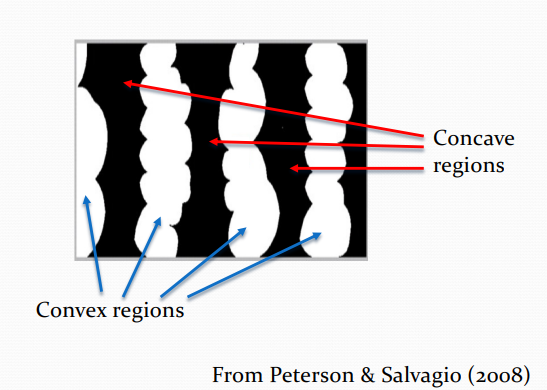
Figural Properties - Convexity
Peterson & Salvagio (2008) showed that if you see a single border, there is a slight tendency to perceive the convex region as figure.
However, if you see multiple convex regions, each with the same colour, you are more likely to perceive those regions as figure.
Take home message: Convex regions are assumed to be figures (i.e. objects)
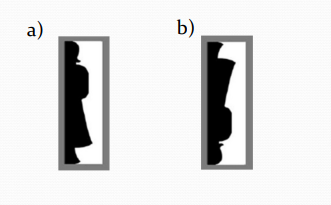
Experience
People also used past experience to segregate overlapping objects
What letters do you see below?
You use your knowledge of letters to segregate these two letters into separate objects
As a) is in a familiar orientation it is easier to segregate it from the background than in b)
Once you have seen the Dalmatian you cannot “unsee” it. (seen in an image which isn’t included)
That knowledge even survives when the image is flipped left to right
Gist Perception
When scenes are flashed rapidly in front of an observer, she may not be able to identify all the objects in the scene.
Nevertheless, she get an overall impression of what the scene is about.
For example, she might think that the image shows “a crowded cafe”
That “overall impression” is what is known as the “gist” of the scene. 68 6
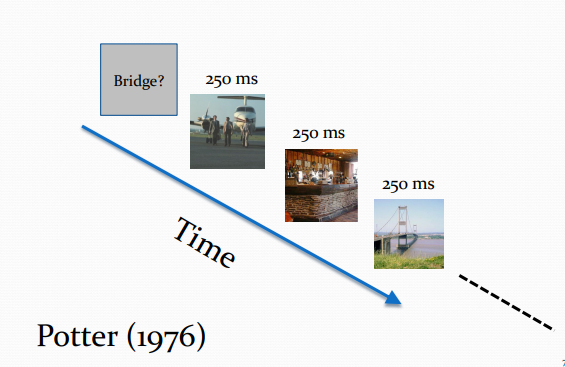
Gist perception- Potter experiment
Potter (1976) studied gist perception using the following paradigm.
In each trial, the observer was cued with a particular scene description.
Then she saw 16 randomly chosen scenes, each for 250 ms.
Then she was asked if any of the scenes fitted the description.
Observers were at near 100% accuracy.
This showed that observers can rapidly perceive a scene’s gist
Gist perception - Fei-Fei investigation
investigated what the minimum scene exposure time is needed to perceive a scene’s gist.
Observers were presented with just a single scene, followed by a mask
Observers were then asked to describe what they had seen
Fei-Fei et al reported that the longer the stimulus presentation time, the more detailed and accurate the description
People could start to perceive aspects of the scene at about 27 ms, but the perceptions were not very detailed
