Lecture 18 - Machine Learning I
1/10
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
11 Terms
Machine Learning
A branch of artificial intelligence (under data-driven models) where the system can improve itself based on experience (large inputs of data, training it on that data)
Rather than taking data and a model to produce an output (like traditionally modelling), it will take data and outputs/results as inputs to produce a model (by picking a model)
Uses of Machine Learning
Machine learning is very flexible and has many applications:
Algorithms are self-adaptive and self-customisable to individual users (more personalised experiences)
Able to explore larger databases using data mining to make data-connections
Can perform human-like tasks
Can perform detailed and complicated operations with high accuracy and a focus on prediction
Why Use Machine Learning?
They are used now because:
Using them is actually possible now with our very computationally strong computers
We have access to lots of data
Increasing industry support with development of much better algorithms
Drawbacks of Machine Learning
However, there are still some limitations:
Require extremely large amounts of data that it’ll need to train on for a long time
Sometimes the data can also be too difficult to interpret
There can be human biases within the machine learning model based on the data
Supervised Algorithms
Uses training data that has labels based on some sort of desired output. It is essentially telling the machine that there is an answer or solution that it should be looking for.
They’re able to optimise performance base don experience or similar data and even predict unforseen events based on our experience
Unsupervised Algorithms
Using training data that don’t have labels or some sort of desired output. It is essentially giving the machien the entire dataset and seeing whether it can come up with a solution or answer by itself without our input
It can find unknown patterns within the data and are great at when we don’t have an answer/solution/label ourselves. So, they can use raw data with minimal intervention.
Steps for (any) Machine Learning Model
Get a dataset
Perform any necessary cleaning
Visualise the data to see if we can spot any patterns and relationships to see if ML is even needed
Choose the algorithm
Based on our wants, goals, and restraints for the dataset (simple vs. complicated, accurate vs. interpretable, black/white/grey box?, etc)
Typically, we’d just try one out and to see how it goes and compare it with another one
Train and test the algorithm
Understanding the data is limited, so, we need to subdivide the whole dataset into a training and testing set
Here, overfitting can become an issue
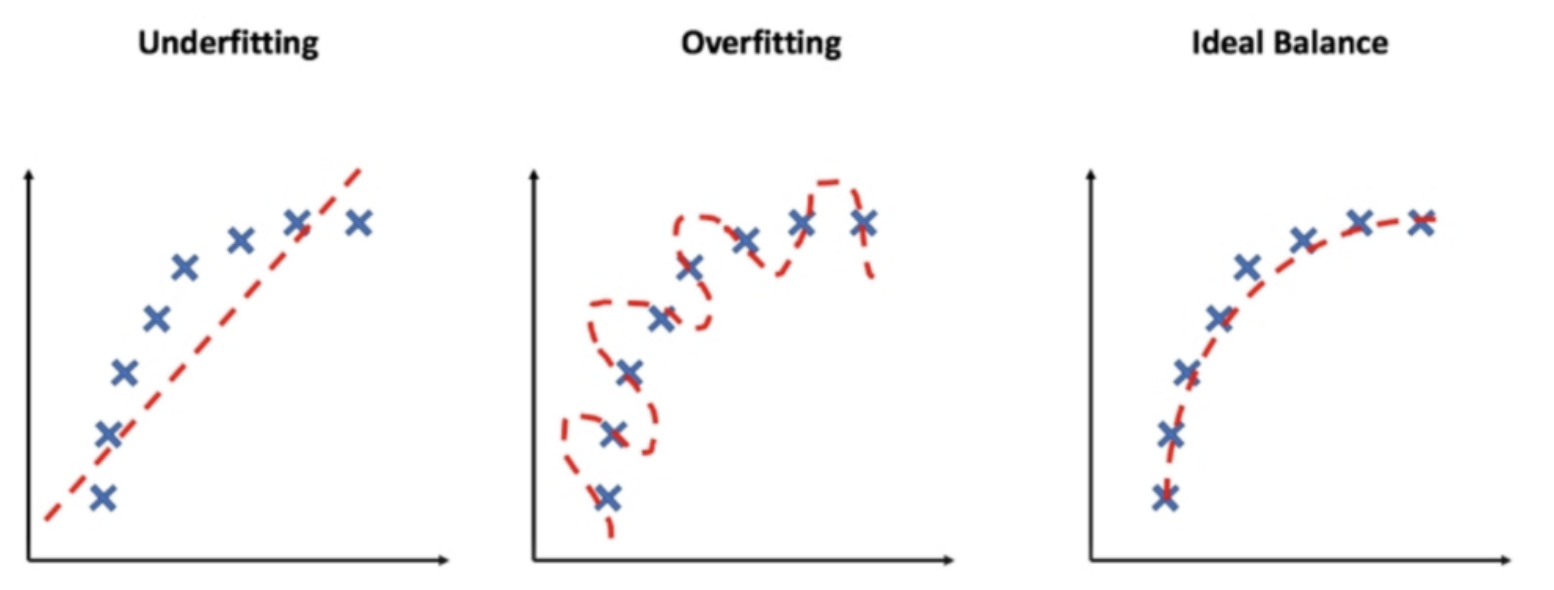
Overfitting
When the machine learning model is overtrained on the dataset and has too much specificity (lacks generality). In the end, this leads to poor predictions
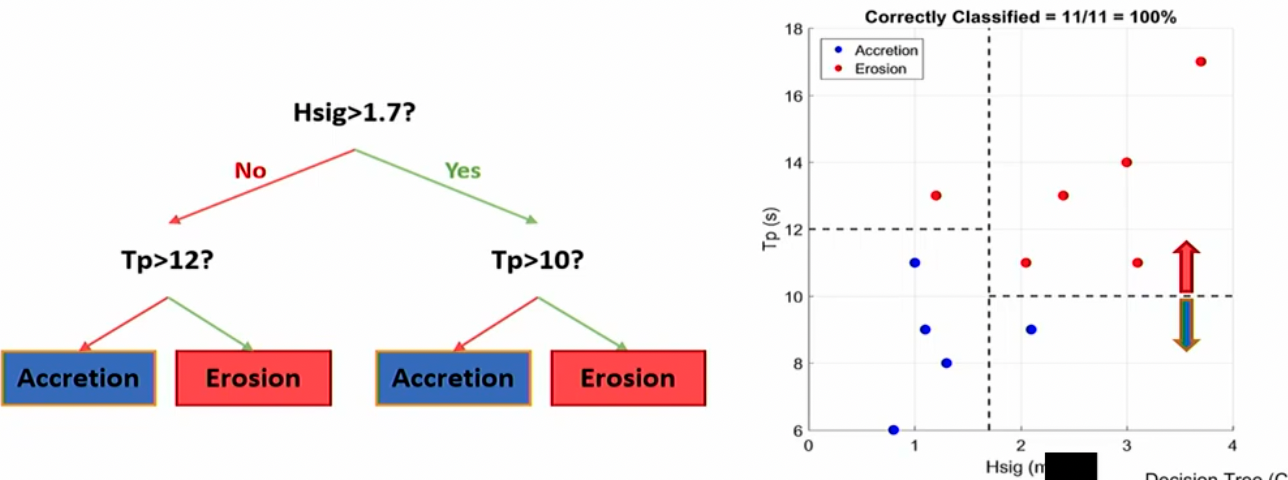
Decision Trees
A classification and regression tree where it aims to split the data into homogenous (similar looking) subsets by creating rules that can be followed for making future predictions
It can be used for classification (predicting discrete variables) or regression (predicting continuous values)
Random Forest
A collection of different decision trees. In real life, a final decision is typically made together by the input of many different groups and stakeholders that bring their own knowledge, inputs, and values.
It is typically done in more complex and complicated decision making
Pros & Cons of Decision Trees/Random Forests
Pros:
Easy to setup and intuitive to understand
Efficient and accurate
Cons:
Can be computationally heavy and prone to overfit
There are more efficient & accurate algorithms
Decision trees are simple but random forests are complciated