L13 - Natural Language Processing 1: Text Vectorisation
1/14
Earn XP
Description and Tags
Flashcards based on the DAT255 Deep Learning Lecture 13 - Natural Language Processing 1: Text Vectorisation
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
15 Terms
What is the primary function of Natural Language Processing (NLP)?
NLP's primary function is to enable computers to understand and process human language, which is critical because the majority of human knowledge is stored in textual form. Think of it as teaching a computer to read and comprehend like a human, so it can access and utilize the vast amount of information available in text.
Name three NLP tasks?
NLP tasks include text classification (e.g., categorizing emails as spam or not spam), content filtering (e.g., detecting inappropriate content), sentiment analysis (determining the emotional tone of text), translation (converting text from one language to another), and summarization (creating concise summaries of longer texts). Imagine NLP as a versatile toolbox, where each tool helps in understanding and manipulating text for various purposes.
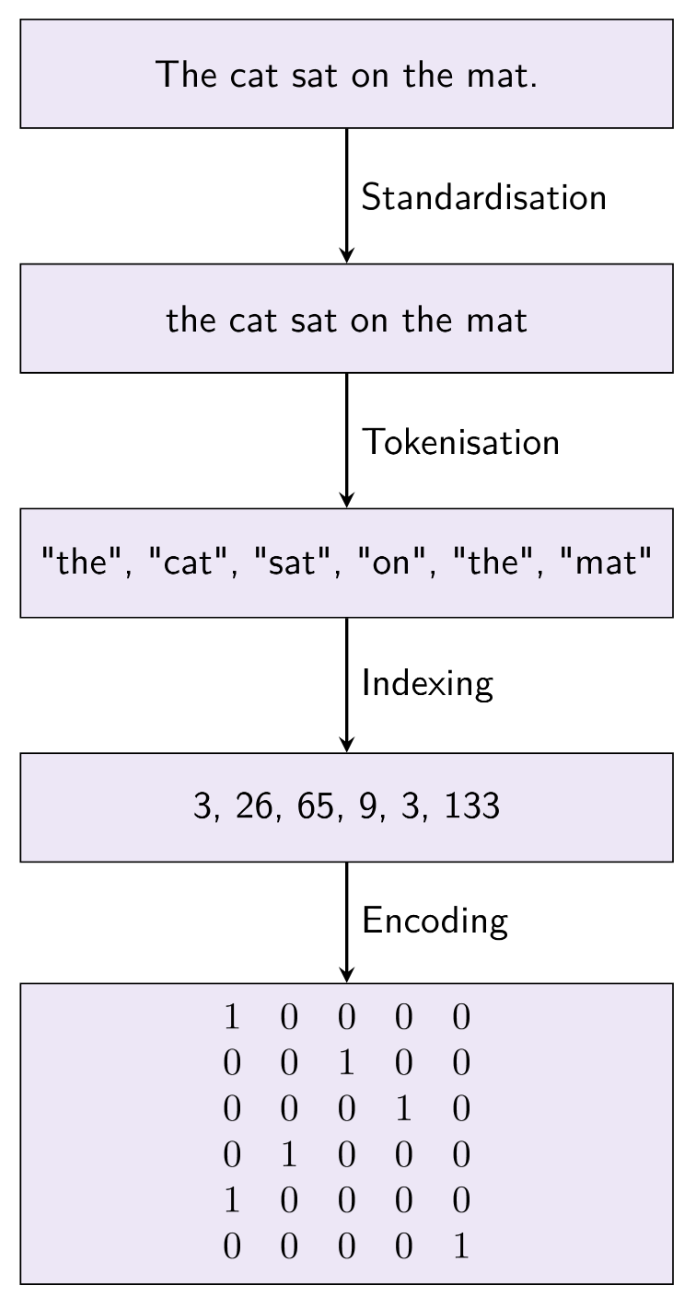
What are the four steps in a typical text vectorization approach?
The four steps in a typical text vectorization approach are:
1. Standardization (e.g., converting text to lowercase),
2. Tokenization (splitting text into individual words or tokens),
3. Indexing (assigning a unique index to each token), and
4. Encoding (converting tokens into numerical vectors). Envision this process as preparing ingredients for a recipe: each step ensures that the text is properly formatted and ready for the machine learning model.These steps help transform raw text into a structured format suitable for analysis in natural language processing.
What is the purpose of the keras.layers.TextVectorization layer?
The keras.layers.TextVectorization layer is used to perform text processing steps such as standardization and splitting. → A preprocessing layer that maps text features to integer sequences.
It acts like a preprocessing pipeline that transforms raw text into a format suitable for machine learning models, similar to how a food processor prepares raw vegetables for cooking.
What is the function of the adapt() method in the keras.layers.TextVectorization layer?
The adapt() method in the keras.layers.TextVectorization layer automatically builds the vocabulary from the provided data. It scans the dataset to identify unique tokens and assign them indices, much like a librarian catalogs and organizes books in a library.
What is the purpose of the mask token (index 0) in text vectorization?
The mask token (index 0) in text vectorization is used to pad sequences, ensuring that all sequences have the same length. This is essential for processing variable-length text data in machine learning models, similar to how a pastry chef ensures all cakes have the same height by adding extra batter.
What is the purpose of N-grams in NLP?
N-grams in NLP capture the relationships between adjacent words in a text, helping to understand context and improve model performance. Think of N-grams as looking at words in context, rather than in isolation, to better understand the meaning, similar to how a detective looks at clues in a crime scene to understand the bigger picture.
What are bigrams?
Bigrams are pairs of words used to extend vocabulary and capture relationships between words. They provide more context than individual words, helping the model understand phrases and common expressions, much like understanding common phrases in a language helps someone converse more fluently.
What is the purpose of word embeddings?
Word embeddings convert words into numerical vectors that capture semantic relationships, allowing models to understand similarities and differences between words. Visualize word embeddings as a map where words with similar meanings are located closer to each other, enabling the model to perform analogies and understand context.
What is the benefit of using embedding layers?
Embedding layers are similar to one-hot encoding followed by a linear Dense layer, allowing words to be represented in a continuous vector space. This approach is more efficient and captures semantic relationships better than one-hot encoding, like upgrading from a black-and-white photo to a high-definition color image.
What are two methods to measure token similarity in embedding space?
Two methods to measure token similarity in embedding space are Euclidean (L2) norm distance and cosine similarity. These methods quantify how similar or different words are based on their vector representations, like measuring the distance between cities on a map to determine how close they are.
Why is cosine similarity often preferred over Euclidean similarity in word embeddings?
Cosine similarity is often preferred over Euclidean similarity in word embeddings because word embeddings are affected by word frequency, and cosine similarity is less sensitive to vector lengths. This makes cosine similarity more robust in capturing semantic similarity, regardless of how often a word appears, similar to normalizing grades in a class to account for different levels of difficulty in exams.
What is lemmatization?
Lemmatization is the process of collapsing words to their base form (lemma) to simplify the vocabulary. For example, the lemma of 'running,' 'ran,' and 'runs' is 'run.' This helps in reducing the complexity of the vocabulary, similar to organizing a messy closet by grouping similar items together.
What is a modern approach to text tokenization?
A modern approach to text tokenization involves splitting words into individual characters and recombining them into common subwords, based on substring frequencies in data. This approach can handle rare or out-of-vocabulary words and is particularly useful for languages with complex morphology, like breaking down a complex Lego structure into smaller, reusable components.
Why are pretrained embeddings and models useful in NLP?
Pretrained embeddings and models are useful in NLP because they can be fine-tuned for specific tasks, leveraging general knowledge learned from large datasets. This saves time and resources by using pre-existing knowledge, similar to a student using a well-written textbook as a foundation for learning a new subject.