PSYC 317 CHAPTER 3 and 4
1/103
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
104 Terms
affective self-reports
involve participants' responses regarding how they feel such as depression, anxiety, stress, grief, and happiness
behavioral criterion
set of rules or standards to which a particular behavior must adhere in order to be considered acceptable.
behavioral self-reports
involve participants' reports of how they act, meaning many personality inventories ask participants to indicate how frequently they engage in certain behaviors.
cognitive self- report measures
measure what people think about something.
concurrent validity
- a form of criterion-related validity that reflects the extent to which a measure allows a researcher to distinguish between respondents at the time the measure is taken.
-the two measures (administering the measure to be validated and the measure of the behavioral criterion.) are administered at roughly the same time. The question is whether the measure being validated distinguishes successfully between people who score low versus high on the behavioral criterion at the PRESENT time. When scores on the measure are related to behaviors that they should be related to right now, the measure possesses concurrent validity.
- For example, we could videotape participants in an unstructured conversation with another person and record the number of times that the individual mentions his or her health to measure an individual's hypochondriasis
construct validity
-is assessed by seeing whether scores on a measure are related to other measures as they should be.
-refers to the degree or measurement accurately assesses the underlying theoretical construct it intends to measure. It involves evaluating the relationship between the test and other measures or constructs to determine if they align as expected.
-a measure should have CONVERGENT VALIDITY and
DISCRIMINANT VALDITY
convergent validity
-when two tests that are believed to measure closely related constructs do, in fact, correlate strongly.
-is a subtype of construct validity is a subtype of construct validity that tests whether constructs that are expected to be related are, in fact, related. It is demonstrated when a new measure is correlated with other measures that assess the same construct. In essence, it ensures that a test is measuring what it's supposed to measure by comparing it to other similar tests.
-Example: Intelligence tests: If a new intelligence test correlates highly with established intelligence tests, it demonstrates convergent validity
converging operations
-using several measurement approaches to measure a particular variable
-This also is known as "triangulation." •
- Often times psychologists will use different kinds of measures produce the same result.
correlation coefficients
-the measure of the degree of correlation between variables
-is a statistic that expresses the strength of the relationship between two measures on a scale from .00 (no relationship between the two measures) to 1.00 (a perfect relationship between the two measures). Correlation coefficients can be positive, indicating a direct relationship between the measures, or negative, indicating an inverse relationship.
criterion-related validity
-is the extent to which a measure allows a researcher to distinguish among respondents on the basis of some behavioral criterion
- For example, is the extent to which a measure allows a researcher to distinguish among respondents on the basis of some behavioral criterion?
-When examining criterion-related validity, researchers identify behavioral outcomes that the measure should be related to if the measure is valid. Finding that the measure does, in fact, correlate with behaviors in the way that it theoretically should supports the criterion-related validity of the measure. If the measure does not correlate with behavioral criteria as one would expect, either the measure lacks criterion-related validity or we were mistaken in our assumptions regarding the behaviors that the measure should predict. This point is important:
A test of criterion-related validity is useful only if we correctly identify a behavioral criterion that really should be related to the measure we are trying to validate.
-two primary kinds of criterion validity: concurrent validity and predictive validity.
Cronbach's alpha coefficient
-is an index of interitem reliability for a given test.
-Statistically, it is equivalent to the average of all split-half reliabilities for one test (but it's easier to compute)
-It's critical that psychological tests and other measures have solid Cronbach's α's - to the tune of .70 for research and closer to .90 for clinical purposes (a test used to help people).
-In other words, when Cronbach's alpha coefficient exceeds .70, we know that the items on the measure are systematically assessing the same construct and that less than 30% of the variance in people's scores on the scale is measurement error.
discriminant validity
-when two tests that do not measure closely related skills or types of knowledge do not correlate strongly (i.e., dissimilar ranking of students).
-assesses the extent to which measures of different constructs are distinct and not highly correlated. In essence, it ensures that a test or measure is not reflecting another related variable. Demonstrating this form of validity is crucial for ensuring that an instrument is measuring a specific construct, not something else.
-Example: Self- esteem vs. Intelligence: A questionnaire measuring self-esteem shouldn't highly correlate with an IQ test
error variance
variance due to factors unknown or uncontrollable by the experimenter
face validity
-is the extent to which a measurement procedure appears to measure what it is supposed to measure.
-technically is not a type of psychometric validity per se, though it is important in psychological testing.
-is never enough evidence to show that a scale is actually valid, but it's often a good start.
face-valid measures
- Just because a measure has face validity doesn't necessarily mean that it is actually valid.
-many measures that lack face validity are, in fact, valid.
- researchers sometimes want to disguise the purpose of their tests. If they think that respondents will hesitate to answer sensitive questions honestly, they may design instruments that lack face validity and thereby conceal the test's true intention.
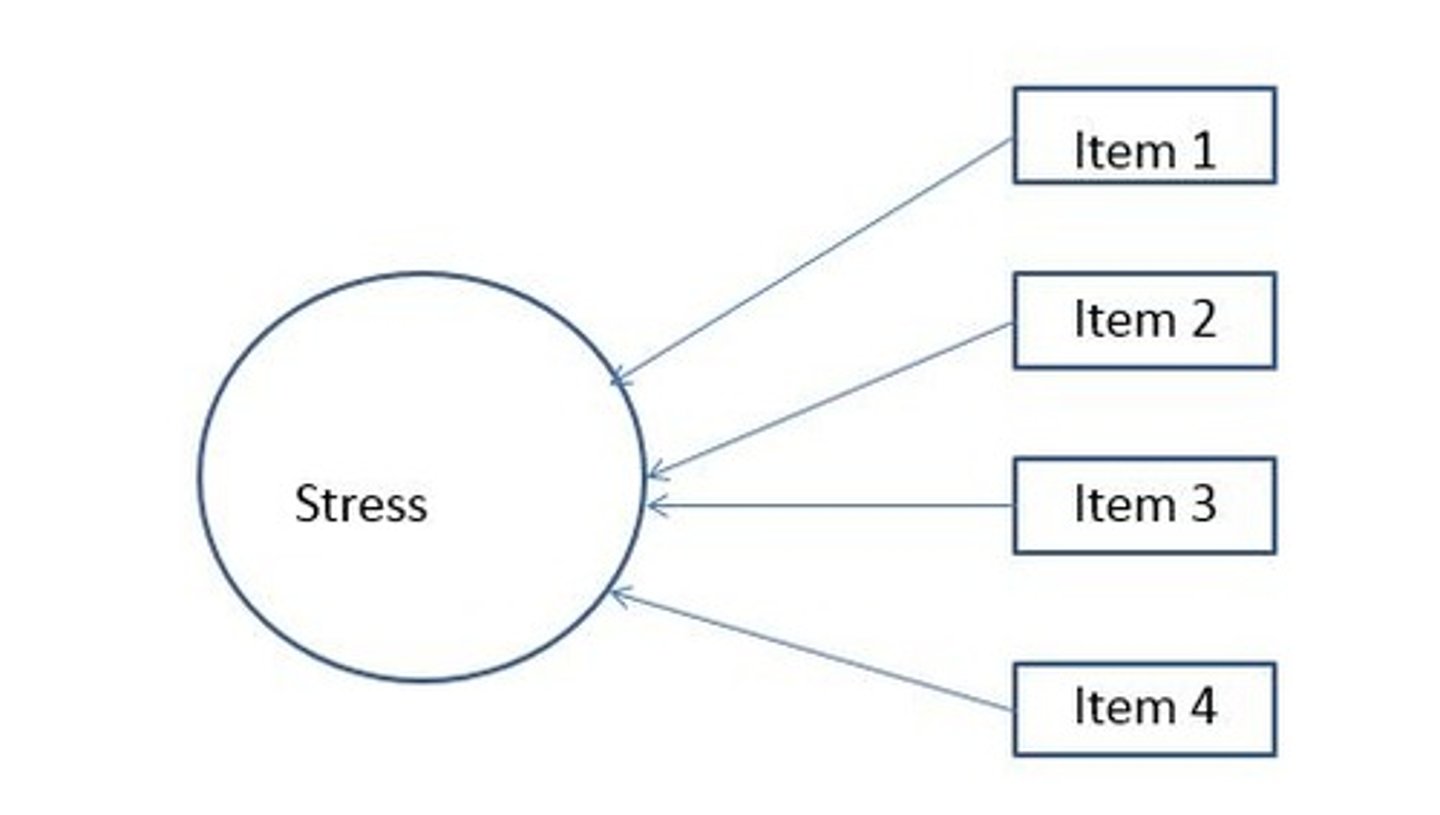
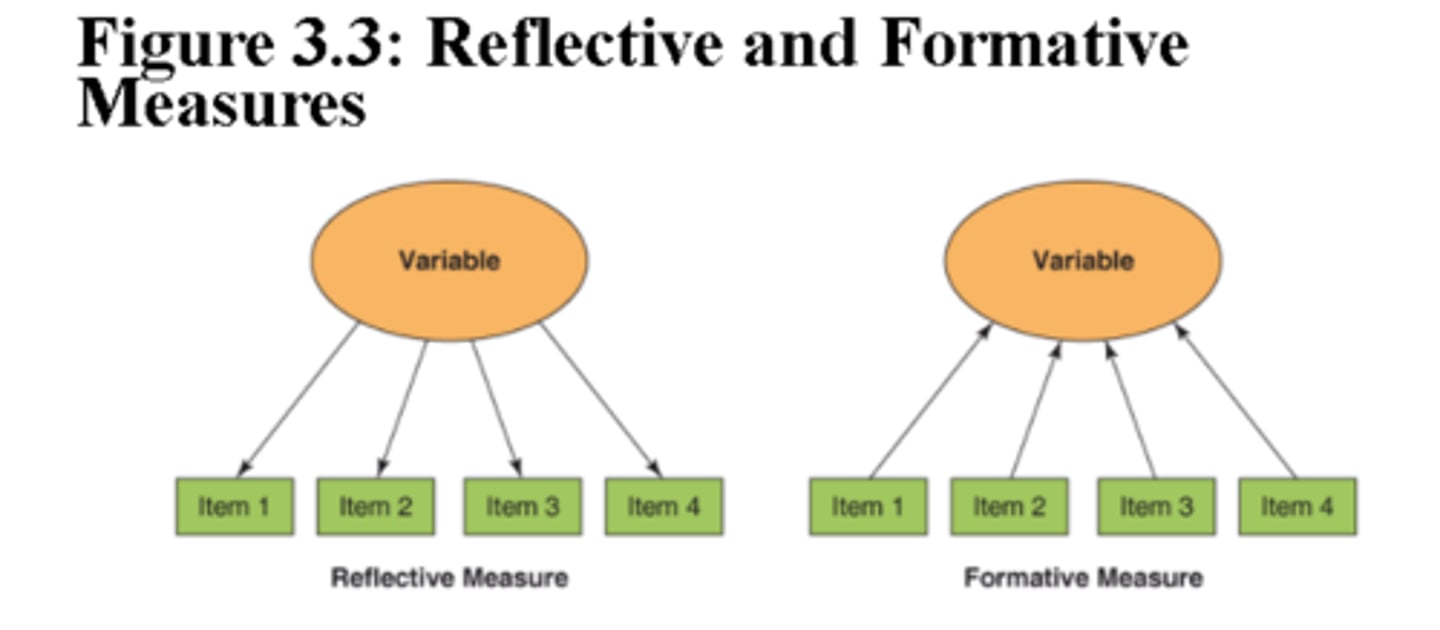
formative measurement
-interitem reliability is not a concern
-a multi-item measure for which the individual items are not assumed to measure a single underlying construct or latent variable and, as a result, the items are not necessarily correlated with each other.
-in the image: stress would be the variable.
hypothetical construct
entities that cannot be directly observed but are inferred on the basis of empirical evidence, such as intelligence, attraction, status, schema, self-concept, moral maturity, motivation, satiation, learning, self-efficacy, ego-threat, love, and so on. None of these entities can be observed directly, but they are hypothesized to exist on the basis of indirect evidence.
interitem reliability
-is the consistency of individuals 'responses on a set of related test items.
-we are trying to determine the degree to which responses to the items follow consistent patterns
-consistency among a set of items intended to assess the same construct
-EXAMPLE: . Personality inventories, for example, typically consist of several questions that are summed to provide a single score that reflects the respondent's extraversion, self-esteem, shyness, paranoia, or whatever. Similarly, on a scale used to measure depression, participants may be asked to rate themselves on several mood-related items—such as sad, unhappy, blue, and helpless—that are then added together to provide a single depression score.
interrater reliability
is the degree to which the observations of two independent raters or observers agree. This sometimes is called interjudge or interobserver reliability. Involves the consistency among two or more researchers who observe and record participants' behavior.
-Example: we want their ratings to be consistent. If one observer records that a participant nodded her head 15 times and another observer records 18 head nods, the difference between their observations represents measurement error and lowers the reliability of the observational measure.
interval scale
- It's a scale of measurement on which the spacing between values is known - that is, equal differences between the numbers reflect equal differences between participants, but there is no true zero point.
-Examples: Temperature on the Fahrenheit scale and Elevation of a location vis-à-vis Sea Level
item- total correlation
-for each question on a test is the correlation between one test item and the sum of all the other items in the test.
- In other words, the correlation between respondents scores on one item on a scale and the sum of their responses on the remaining items
-This is a type of interitem reliability.
measurement error
-factors that distort the true score
-is that component of an observed score that results from factors that distort the score, such that it is not the true score.
1.Transient States: a temporary, unstable state of the participant such as mood, health, level of fatigue, anxiety
2. Stable Attributes: enduring traits of the participant, such as illiteracy, paranoia, hostility
3. Situational Factors: characteristics of the researcher or the lab
4. Characteristics of the Measure: long, difficult or painful measures
5. Mistakes: as in mistakes made in recording a participant's score
multi-item measures
Multi-item measures for which all items are assumed to assess the same underlying construct are sometimes called reflective measures because scores on the individual items are assumed to reflect a single underlying, or latent, variable, such as social anxiety. However, some multi-item measures are formative rather than reflective, and when formative measures are used, interitem reliability is not a concern.
nominal scale
-Values of variables have different names, but no ordering of values is implied.
- NO MEANING
-For example, what form of class did you have for PSYC 101?Online Synchronous via Zoom = ROND
Online Asynchronous via Zoom = RONL
Hybrid Synchronous = RONB
Live on Campus = RINP
observed score
observed score = true score + measurement error
observational measure
involve the direct observation of behavior, in vivo, or via audio- or video-recordings.
ordinal scale
-Different values of a variable can be ranked according to some quantity (e.g., high, moderate, or low self-esteem).
- Often, we rank preferences this way, or some sort of performance. Example: students height
physiological measure
-use specialized equipment to measure some bodily function (with the ultimate goal of linking it with behavior).
- Involves the use of specialized equipment to measure heart rate, brain activity, hormonal changes, and other responses
EXAMPLES:
- Blood Pressure (sphygmomanometer)
- Body Temperature
- Salivary Cortisol levels
- Oxygen Saturation level
psychometrics
is a specialty devoted to the study and improvement of psychological tests and other measures.
ratio scale
-Similar to interval scale, but with a true zero point.
-For example:
How often you checked your phone before noon today?
The number of questions answered correctly on an exam?
How many texts you've sent today?
-Ratio scales provide the greatest amount of information and should be used whenever possible.
reflective measure
a multi-item measure for which all items are assumed to assess the same underlying construct or latent variable.
Reliability
-is the consistency or dependability of a measurement technique.
-When a measure is unreliable, then we cannot trust it is giving us accurate and meaningful data.
-Most estimates of the reliability of a measure are obtained by examining the correlation between two different measures of the same behavior sample.
How do researchers assess a measure's reliability?
-Through analysis of variability in a set of scores
-Distinguishing true scores from error variance
How is reliability expressed numerically?
-Reliability is the proportion of the total variance that is systematic variance associated with true scores
-No reliability = 0.00
-Perfect reliability = 1.00
response format
researchers sometimes use scale to refer to the way in which a participant indicates his or her answer on a questionnaire or in an interview. For example, researchers might say that they used a "true-false scale" or that participants rated their attitudes on a "5-point scale that ranged from strongly disagree to strongly agree." We will use the term response format to refer to this use of the word "scale".
scale
refer to a set of questions that all assess the same construct. Typically, using several questions to measure a construct—such as mood, self-esteem, attitudes toward a particular topic, or an evaluation of another person—provides a better measure than asking only a single question.
scales of measurement
whether a variable is measured at the nominal, ordinal, interval, or ratio level
Stevens' basic scales of measurement:
-Nominal
-Ordinal
-Interval
-Ratio
-The type of scale dictates the kinds of statistics you can use to analyze data.
self-report measure
-have a person answer questions about him or herself, by way of a questionnaire or interview.
- Cognitive -- thinking
- Affective -- feeling
- Behavioral -- acting
situational factors
-characteristics of the researcher or the lab can create measurement error. If the researcher is particularly friendly, a participant might try harder; if the researcher is stern and aloof, participants may be intimidated, angered, or unmotivated. Rough versus tender handling of experimental animals can change their behavior. Room temperature, lighting, noise, and crowding also can artificially affect participants' scores and introduce measurement error into their observed scores.
mistakes in reporting
actual mistakes in recording participants' responses can make the observed score different from the true score. If a researcher sneezes while counting the number of times a rat presses a bar, he may lose count; if a careless researcher writes 3s that look like 5s, the person entering the data into the computer may enter a participant's score incorrectly; a participant might write his or her answer to question 17 in the space provided for question 18. In each case, the observed score that is ultimately analyzed contains measurement error.
characteristics of the measurement
itself can create measurement error. For example, ambiguous questions create measurement error because they can be interpreted in more than one way. And measures that induce fatigue, such as tests that are too long, or fear, such as intrusive or painful physiological measures, also can affect observed scores.
split-half reliability
is the correlation between two halves of a test or questionnaire. This also is a type of interitem reliability.
stable attributes
of the participant can lead to measurement error. For example, paranoid or suspicious participants may purposefully distort their answers, and less intelligent participants may misunderstand certain questions and thus give answers that are not accurate.
systematic variance
the portion of the total variance in a set of scores that is related in an orderly, predictable fashion to the variables the researcher is investigating. If the participants' behavior varies in a systematic way as certain other variables change, the researcher has evidence that those variables are related to behavior. In other words, when some of the total variance in participants' behavior is found to be associated with certain variables in an orderly, systematic fashion, we can conclude that those variables are related to participants' behavior. The portion of the total variance in participants' behavior that is related systematically to the variables under investigation is the systematic variance.
test- retest reliability
-is the consistency of respondents 'scores on a measure, across time.
- It's sometimes also called "temporal stability."
-Note that it only makes sense to look at test-retest reliability of items that are not expected to change overtime!
total variance
in a set of experimental data can be broken into two parts: systematic variance (which reflects differences among the experimental conditions) and unsystematic, or error, variance (which reflects differences among participants within the experimental conditions).
Total variance = systematic variance + error variance
transient states
measurement error is affected by transient states of the participant. For example, a participant's mood, health, level of fatigue, and feelings of anxiety can all contribute to measurement error so that the observed score on some measure does not perfectly reflect the participant's true characteristics or reactions.
true score
the score that the participant would have obtained if the measure were perfect, and we were able to measure without error.
true score variance
reliability= true-score variance/ total variance
validity
-is the extent to which a measurement procedure actually measures what it is intended to measure.
- the accuracy of a measurement technique
-Can a measure be highly reliable but not valid?
Yes, a score may be consistent, but not correct.
-Example: hitting a dart at the same spot but not where it's supposed to be
Psychological researchers use roughly three different ways to measure variability in human behavior:
-Observational Measures
- Physiological and Neuroscientific Measures
- Self-Report Measures
When choosing a scale of measurement which one yields the least and most information?
Information Yielded
A nominal scale yields the least information. Interval and ratio scales yield the most information.
When choosing a scale of measurement which one has less and most powerful statistical tests available?
The statistical tests available for nominal and ordinal data(nonparametric) are less powerful than those available for interval and ratio data (parametric).
How to Increase the Reliability of Measures?
-Standardize administration of the measure: Test participants under the same conditions
-Clarify instructions and answer questions: Ensure participants understand the assessment
-Train your observers: Provide observers with thorough training and practice
-Minimize errors: in coding and data entry
What's a construct?
-A construct is a hypothetical entity that cannot be observed, directly, but is inferred on the basis of empirical evidence.
- A construct is just a concept; but it has been deliberately and consciously invented or adopted for a special scientific purpose
test bias
occurs when a particular measure is not equally valid for everyone taking it.
-The question is not whether various groups score differently on the test.
-Rather, test bias is present when the validity of a measures lowers for some groups than for others.
acquiescence
Some people show a tendency to agree with statements regardless of the content
checklist
are a measuring instrument on which a rater indicates whether (or not) particular behaviors have been observed.
classify
arrange (a group of people or things) in classes or categories according to shared qualities or characteristics.
computerized experience sampling methods
involves the use of smartphones or specialized, portable computers that are programmed to ask participants about their experiences during everyday life.
contrived observation
is the observation of behavior in settings that have been arranged specifically for observing and recording behavior.
diary methodology
a method of data collection in which participants keep a daily record of their behavior, thoughts, or feelings
disguised observation
Observing participants' behavior without their knowledge
duration
-is a measure of the amount of time that a particular reaction lasts from onset to conclusion.
-How long can you hold the reaction behavior?
experience sampling methods
Participants are asked to record information about their thoughts, emotions, or behaviors as the occur in everyday life.
free response format
(or open-ended item), the participant provides an unstructured response.
field notes
a researcher's narrative record of a participant's behavior
- probably are used more frequently and include a summary of behavior with no attempt to write down every detail of observable behavior
fixed-alternative response format
a response format in which participants answer a questionnaire or interview item by choosing one response from a set of possible alternatives; also called a multiple-choice response format
informed consent
involves informing research participants of the nature of the study and obtaining their explicit agreement to participate. Protects people's rights in two ways. First, informed consent prevents researchers from violating people's privacy by studying them without their knowledge. Second, it gives prospective research participants enough information about the nature of a study, including its potential risks, to make a reasoned decision about whether they want to participate.
interbehavior latency
the time that elapses between the occurrence of two behaviors
interview schedule
is the series of questions and response formats that guide the course of the interview/ basically a guide of what the interview will look like
knowledgeable informant
Researcher recruits someone who knows the individuals well to observe their behavior.
interview
participants respond verbally to a researcher's questions.
latency
-is the amount of time that elapses between a particular event and a behavior.
-how long something happens for you to react
- Reaction time and Task Completion are measures of latency.
multi-item scales
have sets of items that all assess the same constructure combined into a scale.
narrative record
is a full description of a participant's behavior as it occurs.
naturalistic observation
is observation of ongoing behavior as it occurs naturally, with no intrusion or intervention by the researcher
nay-saying
whereas others tend to express disagreement
Neuroimaging
techniques, such as fMRI and PET, that allow researchers to see images of the structure and activity of the brain
neuroscientific measure
a measure that assesses processes occurring in the brain or other parts of the nervous system; also called a psychophysiological measure
Can be classified into five general categories:
-measures of neural electrical activity
-neuroimaging
-measures of autonomic nervous system activity
-blood and saliva assays
-precise measurement of overt reactions.
observational definitions
to define unambiguously how a particular construct will be measured in a particular research setting
observational rating scales
used to measure the quality or intensity of a particular behavior.
Reliability of Observations is Increased by:
-Clear and precise operationalization of the behaviors of interest
-Trained raters should practice using the coding system
observational method
the technique whereby a researcher observes people and systematically records measurements or impressions of their behavior
Researchers who use observational methods must make the following decisions.
- Will observation occur in a natural or a contrived setting?
- Will participants know they are being observed?
- How will participants' behavior be recorded?
particpant observation
the researcher engages in the same activities as the people he or she is observing
psychophysiological measure
a measure that assesses processes occurring in the brain or other parts of the nervous system
questionaire
is a method of data collection in which respondents provide written answers to written questions
rate
a measure, quantity, or frequency, typically one measured against some other quantity or measure.
rating scale response format
a response format on which participants rate the intensity or frequency of their behaviors, thoughts, or feelings
reaction time
the time that elapses between the presentation of a stimulus and the participant's response (such as pressing a key).
reactivity
When participants act differently because they know they are being observed
response format
refers to the manner in which the respondent indicates his or her answer to the item
single-item measure
are intended to be analyzed by themselves
social desirability response bias
is the tendency for people to distort their responses in a manner that portrays them in a positive light
structured observation
method is one in which the observer records, times, or rates behavior on dimensions that have been decided upon in advance.
task completion time
the length of time it takes participants to solve a problem or complete a task
temporal measures
when and how long a behavior occurs
Latency and Duration
true-false response format
is a special case of the fixed-alternative format in which only two responses are available—"true" and "false."
undisguised observation
Participants have knowledge that they are being observed
unobtrusive measure
Measures that can be taken without participants knowing that they are being studied