Exploring Data with Pandas: Intermediate
1/10
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
11 Terms
How to make first column of dataframe as row label?
by index_col = 0
f500 = pd.read_csv("f500.csv",index_col = 0)
How to name row label column?
df.index.name = Name of row label
E.g.: f500.index.name = "Company"
How to name column label column?
df.columns.name= Name of columns label
E.g.: f500.columns.name = "Metric"
How to select first value in third row?
df.iloc[2, 0]
How to select all the rows in first column using iloc?
first_column = f500.iloc[:, 0]
![<p>first_column = f500.iloc[:, 0]</p>](https://knowt-user-attachments.s3.amazonaws.com/4b5f111f-e179-4787-8fd2-e66568f186cf.png)
How to get null value of a column and get three column values based on that?
prev_rank_null = f500["previous_rank"].isnull()
null_prev_rank = f500[prev_rank_null][["company", "rank", "previous_rank"]]
print(null_prev_rank)
Note: We can use notnull() for the opposite operation.
What are the other operators we can use apart from ==, !=, >, <?
&, |, ~
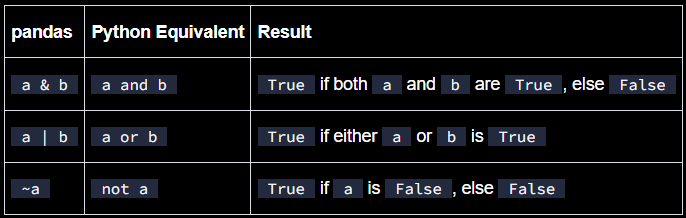
How to invert the boolean indexing?
df[~(df["A"] == X)]
~ will invert the original value. That means the operation is not equal to X.
How to sort dataframe based on a column name?
selected_rows = f500.loc[f500.loc[:, "country"] == "Japan"]
sorted_rows = selected_rows.sort_values("profits")
In the above example, the dataframe is sorted in ascending order by “profits” column. We can sort them in descending order by below syntax.
selected_rows = f500.loc[f500.loc[:, "country"] == "Japan"]
sorted_rows = selected_rows.sort_values("profits", ascending = False)
How to get unique values from a column?
f500.loc[:, "country"].unique()
How to get highest roa of each sector?
f500["roa"] = f500.loc[:, "profits"] / f500.loc[:, "assets"]
top_roa_by_sector = {}
sectors = f500.loc[:, "sector"].unique()
for s in sectors:
selected_companies = f500.loc[f500.loc[:, "sector"] == s]
sorted_companies = selected_companies.sort_values("roa", ascending = False)
top_roa_by_sector[s] = sorted_companies.iloc[0,0]