2 Computer Vision: 1 Fundamentals of Computer Vision
1/14
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
15 Terms
[computer vision]
where systems are designed to perceive the world visually, through camera, images, and video
built on the analysis and manipulation of numeric pixel values in images.
Machine learning models are trained using a large volume of images to enable common computer vision scenarios, such as image classification, object detection, automated image tagging, optical character recognition, and others
While you can create your own machine learning models for computer vision, the Azure AI Vision service provides many pretrained capabilities that you can use to analyze images,
including generating a descriptive caption, extracting relevant tags, identifying objects, and others.
images as pixels arrays
[Images and Processing]
to a computer, an image is an array of numeric pixel values
image’s resolution: (i.e. 7×7) he rows and columns that a image consists of
each pixel has a value between 0 (black) and 255 (white)
with values between these bounds representeing shades of gray
two dimensional image
x and y; represented by rows and columns
most images are multidimensional and consist of three layers (channels) that represent red. green, and blue (RGB) color hues
three different sets of the picture (WK)
using filters to process images
[Images and Processing]
a filter is defined by one or more arrays of pixel values, valled pixel kernels
I.e. you can define a filter with a 3×3 kernel
the kernel is convolved across the image (calculating a weighted sum for each 3×3 path of pixels and assigning the result to a new image)
apply the filter kernel to the top left patch of the image, mulitplying each picel value by the corresponding weight value in the kernel and adding the result
the result becomes he first value in a new array.then we move the filter kernel along one [ixel to the right and repeat the operation
again, the result is added to the new array which now contains two values
the process is repeated until the filter has been convolved across the entire image
some of the values might be outside of the 0 to 25 pixel value range , so the values are adesuted to fit into that ranfe
becaus of the shape of the filter, the outside edg of pixels isnt calculated, so a padding value (usually 0) is applied
the resulting array represents a new image in which the filter has transformed to the original image
because the filter is convolved acoss the image, this kind of image manipulation is often referred to as convolutional filtering
the filter used in this ex is a particular type of filter called a laplace filter that highlights the edges on objects in an image
there are many otherkinds of filters that you can use to create blurring, sharpening, color inversion, and other effects
[ML for Computer Vision]
the goal of computer vision is often to extract meaning (or at least actionable insighs from images wich requires the creation of machine learning models that are trained to recognize features based on large volumes of existing images
CNNs
[ML for Computer Vision]
convolutional neural networks
one of the most common learning model architectures for computer vision
atype of deep learning architecture
uses filters to extract numeric feature maps from images
then feed the feature values into a deep learning model to generate a label prediction
(i.e. w/ image classification)
label represents the main subject of the image (i.e. fruit)
you might train a CNN model with images of diffrerent kinds of fruit so that the label that is predicted is the type of fruit in a given image
during a training process for a CNN, filter kernels are initially defined using randomly generated weight values (feature maps)
then, the model’s predictions are evaluated against knownlabel values, and the filter weights are adjusted to improve accuracy
eventually, the trained fruit image classification model uses the filter weights that best extract features that help identify different kinds of fruits
*softmax
the training process repeats over multiple epochs until an optimal set of weights has been learned
transformer
[ML for Computer Vision]
CNNs have been at the core of computer vision solutions for many years
object detection models combine CNN feature extraction layers with the identification of regions of interest in images to locate multiple clases of object in the same image
transformers
in the AI discipline of NLP, this neural network architecture has enabled the development of sophisticated models for language
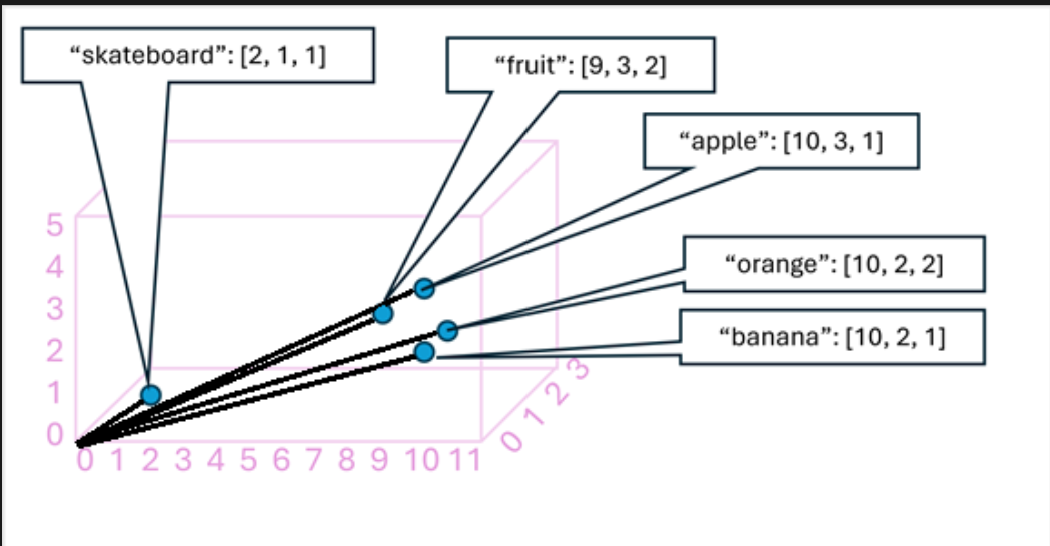
work by processing huge volumes of data, and encoding language tokens (representing individual words or phrases) as vector-based embeddings (arrays of numeric values)
think of embeddings as representin a set of dimensions that each represent some semantic attribute of the token
the embeddings are reated such that are commonly used in the same context define vectors that are more closely ligned than unrelated words
tokens that are semantically similar are encoded in similar directions, creating a semantic language model tha makes it possible to build sophisticated NLP solutions for text analysis, translation, language generation. and other tasks
the example shows a 3D vectors but, in reality, encoders in transformer networks create vectors with many more dimensions, defining complex semantic relationships between tokens based on linear algebraic calculations
multi-modal models
[ML for Computer Vision]
transformers successfully being a way to build langauge models led to, “can we do the same effectively for image data?“
multi-moda models
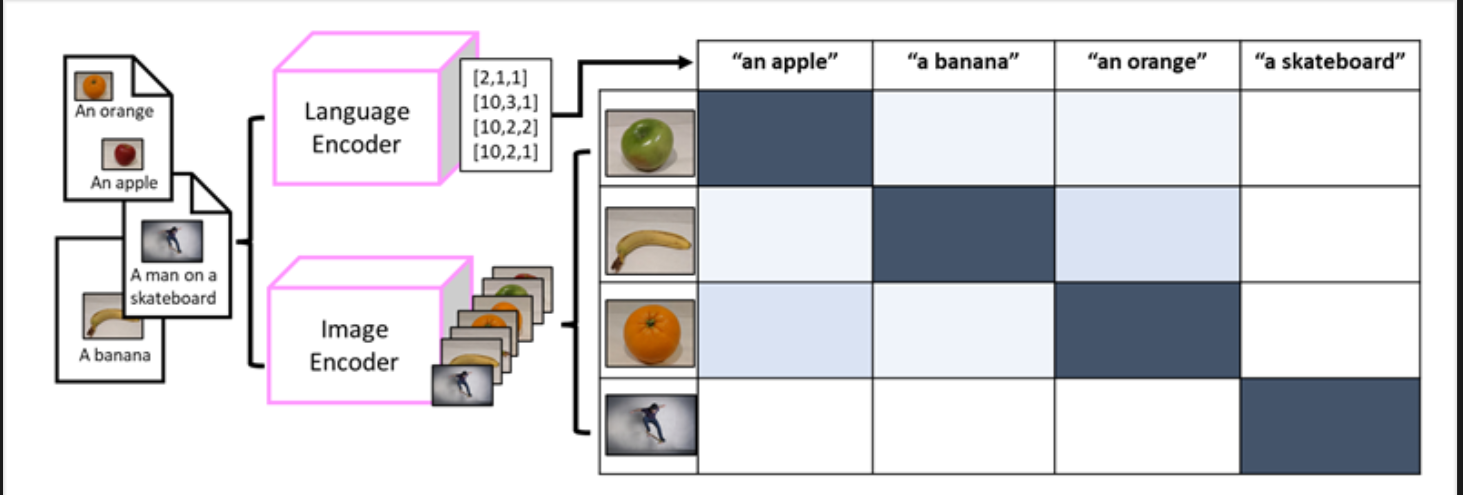
MMM → the model is trained using a large volume of captioned images, with no fixed labels
an image encoder extracts features from images based on pixel values and combines them with text embeddings created by a language encoder
Microsoft Florence
just a model (an example of a foundational model)
a pre-trained general odl on which you can build multiple adaptive models for specialist tasks
you can use it as a foundation model for adaptive models that perform
image classification
object detection
captioning
& tagging
trained with huge volumes of captioned images from the internet
includes both a language encode and an image encoder
multi-modals like Florence are at the cutting edge of computer vision and AI in general, and are expected to drive advances in the kinds of solution that make AI possible
[Azure AI Vision]
provides prebuilt and customizable vision models that are based on the Florence foundation model and provide various powerful capabilities
you can create sophisticated computer vision solutions quickly and easily; taking advantage of the off-the-shelf functionality for many common computer vision scenarios
while retaining the ability to create custom models using your own images
Azure Resources for AI Vision
[Azure AI Vision]
Azure AI Vision
Azure AI services
Analyzing images with the Azure AI Vision service
[Azure AI Vision]
After you've created a suitable resource in your subscription, you can submit images to the Azure AI Vision service to perform a wide range of analytical tasks
Optical character recognition (OCR) - extracting text from images.
Generating captions and descriptions of images.
Detection of thousands of common objects in images.
Tagging visual features in images
OCR
[Azure AI Vision]
Azure AI Vision can use [] capabilities to detect text in images.
(i.e.) consider the following image of a nutrition label on a product in a grocery store
The Azure AI Vision service can analyze this image and extract the following text:
Nutrition Facts Amount Per ServingServing size:1 bar (40g)Serving Per Package: 4Total Fat 13gSaturated Fat 1.5gAmount Per ServingTrans Fat 0gcalories 190Cholesterol 0mgories from Fat 110Sodium 20mgntDaily Values are based onVitamin A 50calorie diet
![<ul><li><p>Azure AI Vision can use [] <span>capabilities to detect text in images. </span></p></li><li><p><span>(i.e.) consider the following image of a nutrition label on a product in a grocery store</span></p><ul><li><p>The Azure AI Vision service can analyze this image and extract the following text:</p></li><li><p><code>Nutrition Facts Amount Per Serving</code></p><p><code>Serving size:1 bar (40g)</code></p><p><code>Serving Per Package: 4</code></p><p><code>Total Fat 13g</code></p><p><code>Saturated Fat 1.5g</code></p><p><code>Amount Per Serving</code></p><p><code>Trans Fat 0g</code></p><p><code>calories 190</code></p><p><code>Cholesterol 0mg</code></p><p><code>ories from Fat 110</code></p><p><code>Sodium 20mg</code></p><p><code>ntDaily Values are based on</code></p><p><code>Vitamin A 50</code></p><p><code>calorie diet</code></p></li><li><p><br></p></li></ul></li></ul><p></p>](https://knowt-user-attachments.s3.amazonaws.com/8232c17f-5601-48fd-aec8-ec101b3d2d00.png)
describing images with captions & etecting common objects in an image
[Azure AI Vision]
Azure AI Vision has the ability to analyze an image, evaluate the objects that are detected, and generate a human-readable phrase or sentence that can describe what was detected in the image.
(i.e.) consider the following image:
Azure AI Vision returns the following caption for this image:
A man jumping on a skateboard
Azure AI Vision can identify thousands of common objects in images.
(i.e.) when used to detect objects in the skateboarder image discussed previously, Azure AI Vision returns the following predictions:
Skateboard (90.40%)
Person (95.5%)
the predictions include a confidence score that indicates the probability the model has calculated for the predicted objects.
Azure AI Vision also returns bounding box coordinates that indicate the top, left, width, and height of the object detected.

tagging visual features
[Azure AI Vision]
Azure AI Vision can suggest tags for an image based on its contents.
these tags can be associated with the image as metadata that summarizes attributes of the image and can be useful if you want to index an image along with a set of key terms that might be used to search for images with specific attributes or contents.
(i.e.) the tags returned for the skateboarder image (with associated confidence scores) include:
sport (99.60%)
person (99.56%)
footwear (98.05%)
skating (96.27%)
boardsport (95.58%)
skateboarding equipment (94.43%)
clothing (94.02%)
wall (93.81%)
skateboarding (93.78%)
skateboarder (93.25%)
individual sports (92.80%)
street stunts (90.81%)
balance (90.81%)
jumping (89.87%)
sports equipment (88.61%)
extreme sport (88.35%)
kickflip (88.18%)
stunt (87.27%)
skateboard (86.87%)
stunt performer (85.83%)
knee (85.30%)
sports (85.24%)
longboard (84.61%)
longboarding (84.45%)
riding (73.37%)
skate (67.27%)
air (64.83%)
young (63.29%)
outdoor (61.39%)
trining custom models; Image Classfication; Object Detection
[Azure AI Vision]
If the built-in models provided by Azure AI Vision don't meet your needs, you can use the service to train a custom model for image classification or object detection.
Azure AI Vision builds custom models on the pre-trained foundation model, meaning that you can train sophisticated models by using relatively few training images.
An image classification model is used to predict the category, or class of an image. For example, you could train a model to determine which type of fruit is shown in an image, like this:
Object detection models detect and classify objects in an image, returning bounding box coordinates to locate each object. In addition to the built-in object detection capabilities in Azure AI Vision, you can train a custom object detection model with your own images.
(i.e.) you could use photographs of fruit to train a model that detects multiple fruits in an image,
