AI recall
1/25
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
26 Terms
When we are trying to solve problems through planning, what are we trying to figure out? Select all that apply.
Question 1Answer
A.
In what order should we execute the actions we have selected.
B.
How are actions executed in the problem.
C.
Why actions should be executed in the problem.
D.
Select which actions we should execute.
E.
What actions exist in the problem.
Correct answers:
✅ A. Select which actions we should execute.
✅ C. In what order should we execute the actions we have selected.
What does PDDL stand for?
✅ Correct answer: Planning Domain Definition Language
Which of the following are components we will expect to find in a PDDL action? Select all that apply.
Question 3Answer
A.
The name of the action.
B.
The states that this action can be applied in.
C.
The effects of applying the action.
D.
The preconditions that need to hold true to execute the action.
E.
Parameters used for the action.
✅ Question 3: Components in a PDDL action
Correct answers:
✅ A. Parameters used for the action.
✅ C. The name of the action.
✅ D. The preconditions that need to hold true to execute the action.
✅ E. The effects of applying the action.
How do we enable the use of metrics and numbers in PDDL 2.1?
Question 1Select one or more:
A.
You add the fluents requirement in the problem file.
B.
You add the metrics requirement in the problem file.
C.
You add the fluents requirement in the domain file.
D.
You add the metrics requirement in the domain file.
E.
Trick question: none of these are correct.
✅ Question 1: Enabling metrics and numbers in PDDL 2.1
Correct answers:
metrics isn’t a real term, its metric
✅ C. You add the fluents requirement in the domain file
Which of the following terms can be applied to the condition of a PDDL 2.1 durative action? Select all that apply.
Question 2Answer
A.
'at start' that tracks facts that must be true at the start of the action
B.
'at end' that tracks facts that must be true at the end of the action
C.
'duration' that tracks how long the conditions must hold for
D.
'over all' that tracks facts that must be true throughout the complete duration of the action
✅ Question 2: Conditions in PDDL 2.1 durative actions
Correct answers:
✅ D. 'over all' — must hold during entire action
✅ A. 'at start' — must be true at action start
✅ B. 'at end' — must be true at end of action
What are domain-independent heuristics used in AI planners? Select all that apply.
Question 3Answer
A.
A heuristic that can be calculated irrespective of the information in the PDDL domain file.
B.
A heuristic calculated by analysing the structure of search space itself, rather than the PDDL facts.
C.
A heuristic that can solve any problem.
D.
A heuristic that can be calculated without using specific information from the PDDL problem file.
E.
A guaranteed admissible heuristic
✅ Question 3: Domain-independent heuristics in AI planners
Correct answers:
✅ B. A heuristic calculated by analysing the structure of search space itself, rather than the PDDL facts.
✔ This is true — many domain-independent heuristics (like h_ff, h_max, h_add) analyze relaxed planning graphs, not just static domain facts.
✅ D. A heuristic that can be calculated without using specific information from the PDDL problem file.
✔ Correct — they often work from general structure, ignoring problem-specific constants.
Why do AI Planners require the use of domain-independent heuristics? Select all that apply.
Question 4Answer
A.
A planner should be able to receive any valid PDDL domain/problem and solve it without a heuristic being provided.
B.
Planners do not analyse domain/problem files to create a bespoke heuristic.
C.
Users cannot enter a heuristic in the PDDL problem file.
D.
A planner does not need a heuristic to search effectively.
E.
Users cannot enter a heuristic into the PDDL domain file.
✅ Question 4: Why AI planners use domain-independent heuristics
Correct answers:
✅ A. Planners typically generate heuristics automatically
✅ B. PDDL does not allow user-defined heuristics in the domain file
✅ C. Nor in the problem file
✅ A. Planners should work on any domain/problem without needing a hand-coded heuristic
How might our certainty in a problem come into question? Select all that apply.
Question 1Answer
A.
The behaviour of other systems/processes may prove random and difficult to understand.
B.
The problem we're trying to solve might not be the one we want to be solving.
C.
Our actions might have unintended outcomes.
D.
We might not have all the relevant information about the current state that we need to act.
E.
There could be ethical implications we have not yet considered in the work.
✅ Question 1: How might our certainty in a problem come into question?
Correct answers:
✅ A. Random or complex system behavior introduces uncertainty.
✅ C. Actions may have unintended side effects.
✅ D. Incomplete knowledge about the current state increases uncertainty.
Which of the following situations are examples of a non-deterministic system?
Question 2Answer
A.
Playing a Fruit/Slot machine.
B.
Using a random number generator.
C.
Playing a game of Tic-Tac-Toe.
D.
Playing a game of Texas Hold'em Poker.
E.
Tossing a coin.
✅ Question 2: Non-deterministic systems
Correct answers:
✅ A. Fruit machine (random outcome)
✅ B. RNG (purely non-deterministic)
✅ D. Texas Hold'em (involves randomness and hidden info)
✅ E. Tossing a coin (random)
Which of the following situations are examples of a partially-observable system?
Question 3Answer
A.
Playing a game of Texas Hold'em Poker.
B.
Playing a game of Chess.
C.
Playing a game of Solitaire.
D.
Playing a game of Uno.
E.
Playing a game of Tic-Tac-Toe.
✅ Question 3: Partially-observable systems
Correct answers:
✅ A. Texas Hold’em — you can’t see other players’ cards
✅ D. Uno — hidden hands make it partially observable
Which of the following are important properties of a markov chain? Select all that apply.
Question 4Answer
A.
All states need transitions that go back into themselves.
B.
Transitions are given probabilities of possible success.
C.
We label all actions clearly.
D.
Transitions between states are only influenced by information in the current state.
E.
Probability distributions for state transitions hold and do not change.
✅ Question 4: Properties of a Markov Chain
Correct answers:
✅ B. Transitions are probabilistic
✅ D. Only current state affects next transition (Markov property)
✅ E. Transition probabilities don’t change (stationary)
Why are the reward values relevant when we're building policies with MDPs?
Question 5Select one or more:
A.
Rewards tell the agent if the previous action was the best decision to make.
B.
Reward values help give incentive to an agent to make the best decisions possible.
C.
Rewards are merely cosmetic and have no influence on decision making.
D.
Rewards tell us the exact long-term potential of a given state.
E.
Rewards help remind humans which actions are important.
✅ Question 5: Why are reward values relevant in MDPs?
Correct answers:
✅ A. Rewards help assess the quality of the action just taken
✅ B. Rewards provide incentive and guide behavior
Why would we use negative rewards when designing a MDP?
Question 6Select one or more:
A.
Negative rewards are used to make the AI feel bad about itself.
B.
Negative rewards incentivise an agent to devise an optimal solution that minimises the overall penalty.
C.
It doesn't matter if rewards are positive or negative.
D.
Negative rewards help remind us which actions are 'bad' actions.
E.
Negative rewards help clearly denote 'bad' areas of the state space we don't want to visit.
✅ Question 6: Why use negative rewards in MDPs?
Correct answers:
✅ B. Encourages minimizing bad outcomes
✅ D. Tags "bad" actions
✅ E. Tags "bad" areas in the environment
What is the purpose of reducing the discount factor γ to be less than 1 when calculating the Utility of a given state? Select all that apply.
Question 7Answer
A.
Ensure that future rewards are still relevant, but not as relevant as the most immediate reward.
B.
To make sure the Utility values don't converge too quickly.
C.
To punish the agent for making bad choices later on.
D.
Ensure that the most immediate reward we receive is considered the most relevant when updating the Utility.
E.
To help the Utility values develop a value more reflective of the potential of the current stat
✅ Question 7: Why set γ < 1 (discount factor)?
Correct answers:
✅ A. Immediate rewards are weighted more
✅ C. Future rewards still matter, but less than immediate ones
Clustering and regression are considered to be what kinds of machine learning, respectively?
Question 1Answer
a.
Unsupervised Learning and Supervised Learning
b.
Reinforcement Learning and Unsupervised Learning
c.
Supervised Learning and Unsupervised Learning
d.
Supervised Learning and Reinforcement Learning
e.
Supervised Learning and Supervised Learning
Correct Answer:
a. Unsupervised Learning and Supervised Learning
Consider the hypothetical scenario describe in part 3, in which an algorithm says 'no' to every input (x-ray) attempting to predict a rare disease. Check all that apply
Question 2Answer
a.
Sensitivity (or recall) will be very low due to very high proportion of False Negatives
b.
Sensitivity (or recall) will be very low due to very high proportion of False Positives
c.
F1 score will be pushed down due to low sensitivity
d.
Precision will be very low due to very high proportion of False Negatives
e.
F1 score will be pushed down due to low precision
f.
Precision will be very low due to very high proportion of False Positives
Correct Answers:
a. Sensitivity (or recall) will be very low due to very high proportion of False Negatives
c. F1 score will be pushed down due to low sensitivity
An algorithm predicts the area of a house. The true values are y1=10cm2,y2=15cm2,y3=12cm2,and y4=5cm2y1=10cm2,y2=15cm2,y3=12cm2,and y4=5cm2, whereas the predicted values are y^1=4cm2,y^2=15cm2,y^3=20cm2,and y^4=5cm2y^1=4cm2,y^2=15cm2,y^3=20cm2,and y^4=5cm2. The MAE, MSE, and RMSE are, respectivelly,
Question 3Answer
a.
3.5cm2,25cm2,5cm23.5cm2,25cm2,5cm2
b.
2.5cm2,16cm4,4cm22.5cm2,16cm4,4cm2
c.
3cm2,25cm2,5cm23cm2,25cm2,5cm2
d.
1cm2,20cm4,5cm21cm2,20cm4,5cm2
e.
3.5cm2,25cm4,5c
Correct Answer:
e. MAE = 3.5 cm², MSE = 25 cm⁴, RMSE = 5 cm²
Which of the following can be a sign that our model is overfitting?
Question 4Answer
a.
The training error is much lower than the validation error.
b.
The training error is negative
c.
The validation error is negative
d.
The training error is much higher than the validation error.
e.
The training error and validation error are the same.
a. The training error is much lower than the validation error.
Which of the following are alternative ways of writing the harmonic mean between non-negative x and y? We assume that if either of x or y are zero, their harmonic mean is also zero. Select all that apply,
Question 5Answer
a.
the geometric mean (of x and y) divided by the arithmetic mean (of x and y)
b.
the square of the geometric mean (of x and y) divided by the arithmetic mean (of x and y)
c.
xy/x+y
d.
2xy/x+y
b. (Geometric mean)² / Arithmetic mean
d.2xy/x+y
Harmonic mean is used in F1 score and rates (e.g. speed)It is always ≤ geometric mean ≤ arithmetic mean
Let x and y be non-negative real numbers. Define a-mean(x,y)=x+y2a-mean(x,y)=x+y2, g-mean(x,y)=xy−−√g-mean(x,y)=xy, h-mean(x,y)=2xyx+yh-mean(x,y)=2xyx+y. Which of the following is true? Hint: if you do not want to prove your results, try to run several examples to see what is going on. Note: we need to further define that h-mean(0,0)=0h-mean(0,0)=0 since it is otherwise undefined.
Question 6Answer
a.
h-mean(x,y)≤a-mean(x,y)≤g-mean(x,y)h-mean(x,y)≤a-mean(x,y)≤g-mean(x,y)
b.
h-mean(x,y)≤g-mean(x,y)≤a-mean(x,y)h-mean(x,y)≤g-mean(x,y)≤a-mean(x,y)
c.
g-mean(x,y)≤h-mean(x,y)≤(a-mean(x,y)g-mean(x,y)≤h-mean(x,y)≤(a-mean(x,y)
d.
a-mean(x,y)<h-mean(x,y)<g-mean(x,y)a-mean(x,y)<h-mean(x,y)<g-mean(x,y)
e.
a-mean(x,y)≤h-mean(x,y)≤g-mean(x,y)a-mean(x,y)≤h-mean(x,y)≤g-mean(x,y)
f.
g-mean(x,y)<h-mean(x,y)<a-mean(x,y)g-mean(x,y)<h-mean(x,y)<a-mean(x,y)
g.
h-mean(x,y)<g-mean(x,y)<a-mean(x,y)h-mean(x,y)<g-mean(x,y)<a-mean(x,y)
Correct Answer:
b. h-mean ≤ g-mean ≤ a-mean
Imagine you have 10 politicians (5 conservative and 5 labour) that voted for bills B1, B2, B3. Consider you want to create a decision tree. • I am not giving you notation on purpuse, as this is part of the problem! • How ‘impure’ is the original dataset of 10 politicians, i.e., what is its Gini index?
We have:
10 politicians total
5 conservatives → pC=5/10=0.5p_C = 5/10 = 0.5pC=5/10=0.5
5 labour → pL=5/10=0.5p_L = 5/10 = 0.5pL=5/10=0.5
So:
Gini=1−(0.52+0.52)=1−(0.25+0.25)=1−0.5=0.5\text{Gini} = 1 - (0.5^2 + 0.5^2) = 1 - (0.25 + 0.25) = 1 - 0.5 = \boxed{0.5}Gini=1−(0.52+0.52)=1−(0.25+0.25)=1−0.5=0.5
• Let us look into B1. Four Labour politicians voted in favour of it and one abstained. One conservative voted in favour, two against and two abstained. Answer the three questions below: 1. What is its Gini index of the set of politicians that voted in favour of B1? 2. What is its Gini index of the set of politicians that voted against B1? 3. What is its Gini index of the set of politicians that voted absent in B1?


• What is, therefore, the Gini-Split(B1)? • Note: You can think of it as a weighted mean of the gini impurite indexes of each of the outcomes, weighted by how many data points are in each of them.
Root = 10

• For B3, 4 Labour politicians voted in favour, 1 against, and all Consevatives abstained. 1. What is its Gini index of the set of politicians that voted in favour of B3? 2. What is its Gini index of the set of politicians that voted against B3? 3. What is its Gini index of the set of politicians that voted absent in B3? 4. What is, therefore, the Gini-Split(B3)?
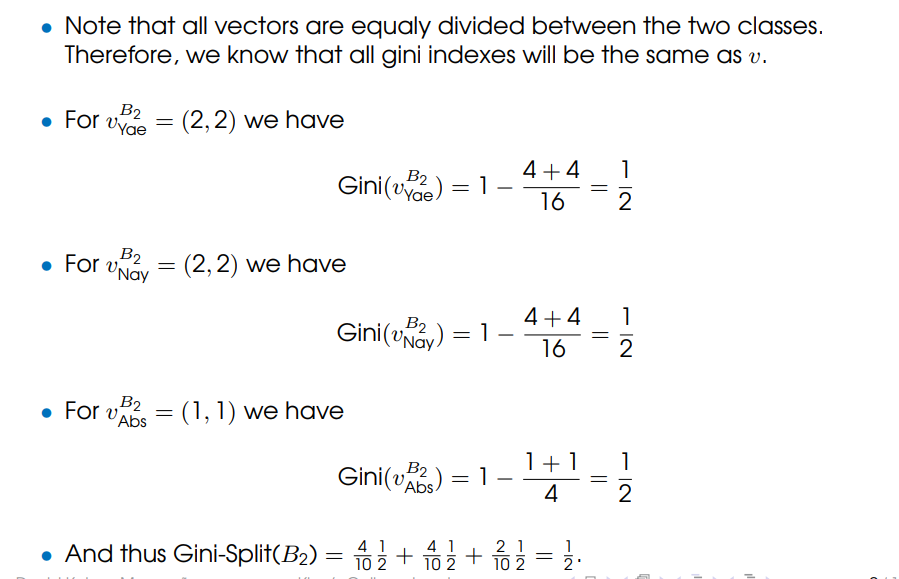
For B3, 4 Labour politicians voted in favour, 1 against, and all Consevatives abstained. 1. What is its Gini index of the set of politicians that voted in favour of B3? 2. What is its Gini index of the set of politicians that voted against B3? 3. What is its Gini index of the set of politicians that voted absent in B3? 4. What is, therefore, the Gini-Split(B3)?
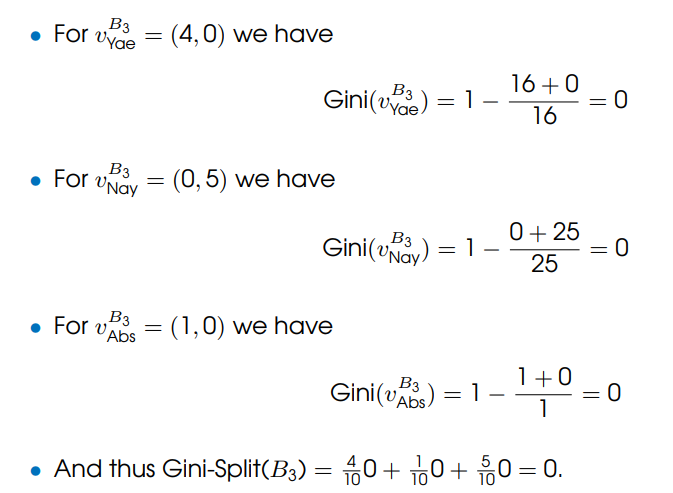
Student 1 suggests that the ϵ-greedy (with ϵ > 0) and UCB (with c > 0) methods are very similar in that in both, all actions are eventually sampled as many times as you want. More formally, for any number of samples you want, say, 100, there is a number of steps t0 for which, on average, you expect to have more than 100 samples of all actions after t0 steps are taken. (we don’t care about actually finding a t0 that works) • Student 2 disagrees and argues that only ϵ-greedy (with ϵ > 0) has that property. • Student 3, on the other hand, thinks that only UCB (with c > 0) has that property. • Which of the students is correct? Discuss. Note: in this question, we are looking to build some intuition. Do not worry about formal proofs.
At first sight, we could think that Student 3 is correct. That is because we can imagine that a ‘good’ action, as long as its estimate is high, would be picked forever even if its confidence interval shrinks to zero. • What we would be missing in this argument is that, from the exploration term (in particular, the term ln t), an action, when not selected, has its upper bound increased. • Moreover, this increase tends to infinity (since ln t → ∞ for t → ∞, as well as the square root). All the other terms for non-selected actions stay the same. Therefore, the bounds of non-selected actions keep on increasing when not picked, so they will eventually reach the upper bound of selected actions (which decreases if estimate Q doesn’t change – show that!). • Therefore, Student 1 is correct.