Looks like no one added any tags here yet for you.
two types of independent variables
active IV
assigned IV
independent variable
the variable in an experiment that is manipulated or changed by the researcher to observe its effect on the dependent variable
dependent variable
variable that is being measured or tested in an experiment; its value depends on changes in the independent variable
relationship between internal and external validity
as internal increases, external decreases
as external increases, internal decreases
interval
-have ordered response categories, and the magnitude between each category choice is of an equal interval
-do not have an absolute zero
-ex. thermometers and standardized scores used to interpret performance on many standardized intelligence and achievement tests
nominal
-classify or categorize a client characteristic into nonordered, exhaustive, and mutually exclusive categories; that is, the categories cover all possible choices, cannot be ordered in a meaningful way, and do not overlap in any way
-no magnitudes, equivalent intervals, or absolute zero point, few mathematical operations can be performed on the results
-ex. “Which candidate did you vote for in the most recent election?” is an example of a nominal scale. For simplicity’s sake, assume there are only two candidates: A and B
ordinal
-display named categories, but these categorical choices also fall in an ordered sequence, so it is possible to conclude that clients in one category have more or less of some characteristic than clients in another category
-allow individuals to be ranked according to magnitude or some degree of quality or frequency
-ex. when running a race, the winner may beat the second-place finisher by one-tenth of a second, while the rest of the runners are seconds or minutes behind, but the race results are still reported as first, second, third, fourth, and so on
ratio
-names, orders, has equal intervals, and has an absolute zero point; thus, any mathematical operation can be applied to ratio data
-ex. the Kelvin scale of temperature and just about any physical measure (e.g., length, weight, time) or frequency tally (e.g., number of times a behavior was observed)
reliability
the overall consistency of a measure
validity
extent to which a concept, conclusion, or measurement is well-founded and likely corresponds accurately to the real world
content validity
expresses what a test measures and how well the content aligns with the accepted domain of behavior
construct validity
established by defining the construct being measured and gradually collecting information over time to demonstrate or confirm what the test measures
criterion-related validity
comparing scores on the test to scores on a selected criterion
test-retest reliability
the extent to which persons consistently respond to the same test, inventory, or questionnaire administered on more than one occasion
cronbach’s alpha
a measure of internal consistency, that is, how closely related a set of items are as a group
alternative forms test reliability
a measure of the consistency and freedom from error of a test, as indicated by a correlation coefficient obtained from responses to two or more alternate forms of the test
split half reliablity
-divides the questions into two halves, either by an odd-even method or by some other strategy
-each half of the items is treated as a separate test, and the total scores of these two half-tests for each participant are correlated together. With this method, the two halves are assumed to be parallel (i.e., the two halves have equal true scores and equal error variances)
standard deviation
a quantity calculated to indicate the extent of deviation for a group as a whole
kurtosis
-describe the degree to which scores cluster in the tails or the peak of a frequency distribution
-measures central tendency
standardized scores (z-scores, etc)
-are raw scores that have been mathematically transformed to have a designated mean and standard deviation
-ex. z-scores, T-scores, IQ, Stanines, Percentiles, Quartiles
standard error of measurement
estimates how repeated measures of a person on the same instrument tend to be distributed around his or her “true” score
classical test theory
assumes that each person has a true score, T, that would be obtained if there were no errors in measurement
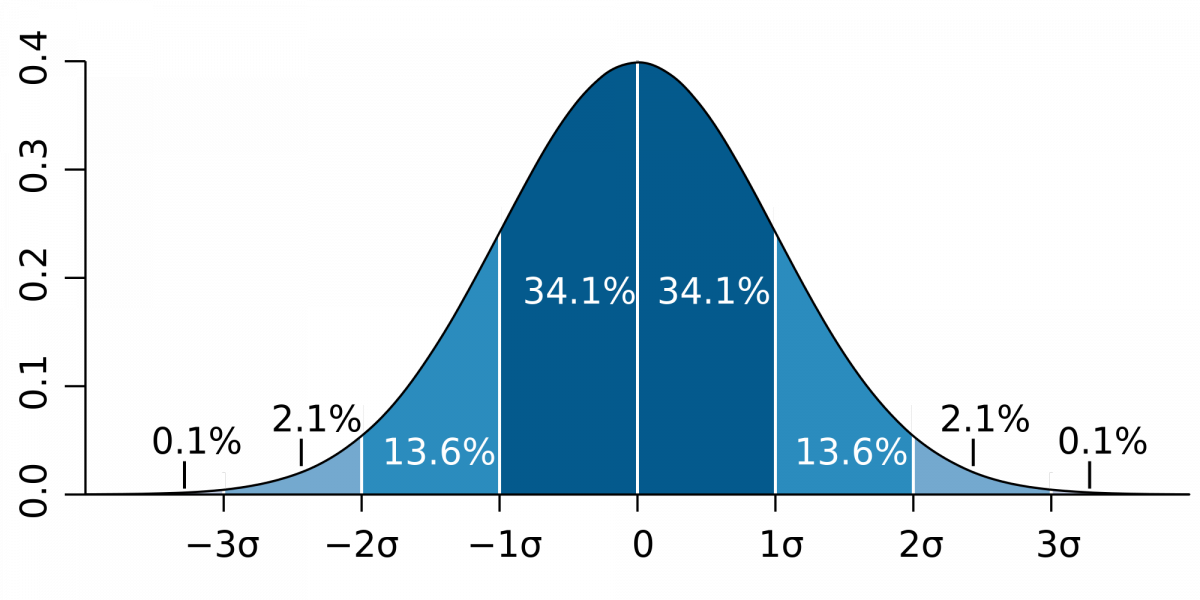
normal bell curve
must be symmetrical
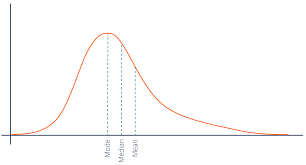
positive skew
a type of distribution in which most values are clustered around the left tail of the distribution while the right tail of the distribution is longer
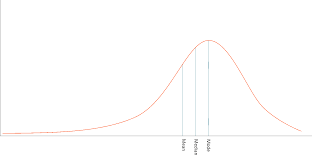
negative skew
a type of distribution in which more values are concentrated on the right side (tail) of the distribution graph while the left tail of the distribution graph is longer
platykurtic
-a statistical distribution in which the excess kurtosis value is negative
-thinner tails than a normal distribution will, resulting in fewer extreme positive or negative events.
mesokurtic
-a statistical term used to describe the outlier characteristic of a probability distribution in which extreme events (or data that are rare) is close to zero
-similar extreme value character as a normal distribution
FERPA
a federal law that affords parents the right to have access to their children’s education records, the right to seek to have the records amended, and the right to have some control over the disclosure of personally identifiable information from the education record
type I error
incorrect rejection of an accurate null hypothesis
false positive
type II error
not rejecting the null hypothesis when it's actually false
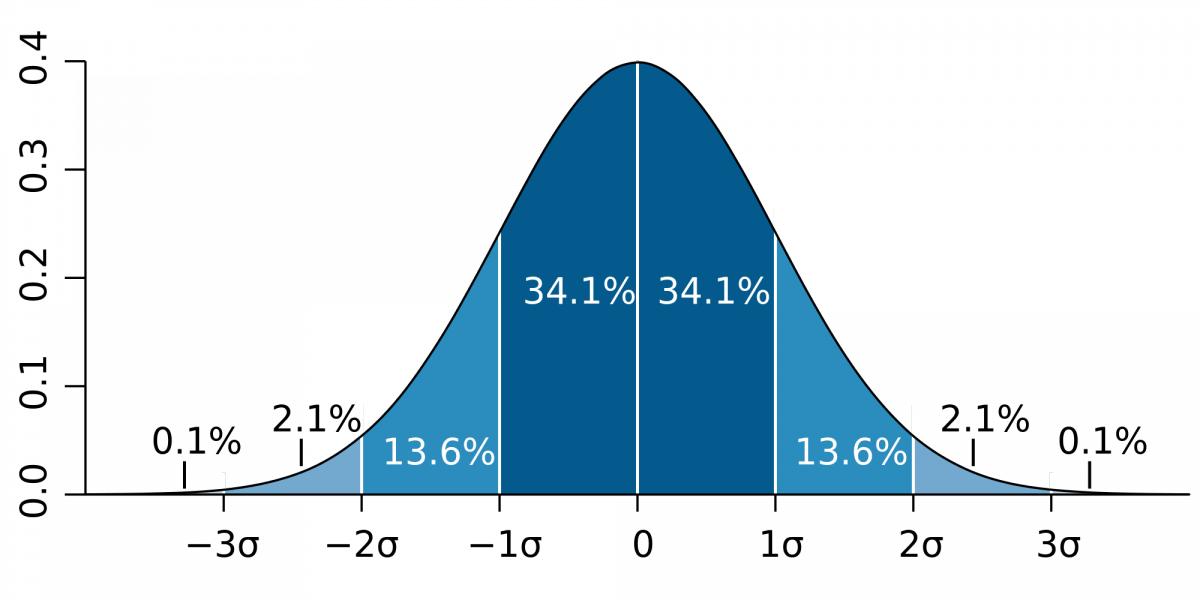
%s of standard deviation in normal bell curve
Approximately 68% of the observations fall within σ of µ
Approximately 95% of the observations fall within 2σ of µ
Approximately 99.7% of the observations fall within 3σ of µ
interrater reliability
two raters or judges evaluate the same individual, event, or situation and give a score
results are reported as kappa coefficient, kappa, G coefficient
concurrent validity
determines how comparable one measure is to another measure that measures the same thing
ex. comparing a psychologist’s diagnosis of depression to scores on a depression to scores on a depression inventory
discriminate validity
determines the degree to which a measure does not measure what it is not supposed to measure
relationship between reliability and validity
you can have reliability without validity
you cannot have validity without reliability
internal validity
is the IV the only possible explanation of the results of the DV?
threats to internal validity
extraneous variables
confounding variables
external validity
replication
the extent to which findings from any one study apply in other settings, at other times, with different participants
target population
the larger population to which we want to generalize the findings
sampling
a smaller version of the target population
representative sampling
same distribution of characteristics as in the population
biased samples
occurs when a sample over-represents or under-represents some segment of the population
forms of non-probability sampling
convenience sampling
snowball sampling
probability sampling
random selection
simple random sample
assigning numbers to participants
systematic random sample
researcher selects every n’th name
stratified random sample
population is divided into subpopulations called strata and random samples are drawn from each strata
cross-sectional designs
one or more samples are obtained at a single point in time
successive independent samples design
different samples complete the survey over time
longitudinal design
sample people surveyed over time to examine changes in individuals
experimental research
attempts to establish causality by making objective observations of a phenomenon
phenomena are publicly observable behaviors, or may be inferred (such as intelligence via test scores)
types of experiments
true
quasi
true experiments
used to establish cause and effect relationships
quasi-experiements
attempts to establish a cause-and-effect relationship by using criteria other than randomization
advantages to experimental research
establish causality
can manipulate one or more variables
useful, can suggest solutions to problems
disadvantages to experimental research
hard to generalize
time consuming
not suitable for studying humans
independent groups design (between subjects design)
different participants are assigned only once to each level of the IV
uses random assignment
threats to internal validity: subject loss, demand characteristics, experimenter effects
ways to maintain internal validity
placebo-control group
double-blind experiment
repeated measures designs (within subjects design)
same subjects assessed over a number of different treatments
adv: requires fewer subjects, more efficient
threats to internal validity: order effects (practice, fatigue), regression towards the mean
case study designs
an intensive description and analysis of a single individual (n=1)
may include multiple individuals (multiple cases) that are added to one another to create a combine analysis and discussion
adv: a change to study rare phenomena, can generate new ideas or hypotheses
disadv: observer bias, problems generalizing from a single individual
ABAB designs
baseline (A) and tx (B) stages are alternated to determine if treatment is effective
researchers conclude that there is a causal effect of tx when behaviors revert back to baseline when the tx is discontinued
multiple basline designs
a type of ABAB designs with multiple baseline
baselines can be across participants, behaviors, or situations
null hypothesis testing
used to determine if differences between groups are greater than the differences we would expect from chance alone
assumption that the IV had no effect
if we find a significant difference (p =/< .05) we can reject the null and accept the research hypothesis
when we reject the null hypothesis, we are saying that 5% of the time, this result could be found by change alone (when p=.05)
confidence intervals
identify a range of values in which we can expect a population value to fall within a specified level of confidence
t-tests
compares the group means and determines if they are dignificantly different
p-value and alpha
the maximum amount of chance a researcher is willing to take that they will reject a null hypothesis that is true (type I error)
one-way ANOVA
used when there are 2 or more levels of the IV
compares the group means and determines if they are significantly different
effect size
calculated with a D-ration and is reported in standard deviation units
small: 0.2
med: 0.5
large: 0.8
statistical significance
a measure of probability that a result is due to chance
regression towards the mean
participants with extreme scores on any measure at one point in time will, probably have less extreme scores the next time they are tested
repeated measures ANOVA
used when all members of a random sample are measured under a number of different conditions
estimates error variation
complex (factorial) designs
two or more independent variables (factors) are studied simultaneousmly
mixed designs
specific type of complex designs that has both between-subjects and within-subjects factors
ceiling effects
occur when participants’ performance reaches a maximum in one or more conditions of an experiment
floor effects
performance reaches a minimum in one or more conditions of an experiment
risk/benefit ratio
subjective evaluation of the risks and benefits of a research project to determine whether the research project should be carried out
minimal risk
considered to be the same level of risk one encounters in everyday life
informed consent
should always be obtained and is absolutely essential when participants are exposed to the possibility of more than minimal risk
deception
occurs when researchers withhold information or intentionally misinform participants about the research
the research must debrief the participants afterwards
never be used to get people to participate
CIPP
context evaluation (needs assessment in counseling)
input evaluation (identifies resources and constraints)
process evaluation (deal with the effectiveness of everyday operations)
product evaluation (“summative evaluation”, the bottom line)
nominal group technique
facilitates decision making in a group formed simply to address a dingle, broad question
delphi technique
facilitates decision making concerning identification of program problems
focus group interview
information gathering technique that finds out how the group members perceive and feel about a topic
accountability
service, ethical, legal, coverage, efficiency, fiscal, impact
Gutman
cumulative scales
Hawthorne
discovered that an experimental effect that threaten internal validity
Likert
summated rating scales
Pearson
product moment coefficient of correlation for linear, interval data
Rosenthal
discovered that an experimental effect in which some characteristic or behavior of the experimenter influence the subjects behavior
Solomon
research design with three or four groups
Spearman
coefficient of correlation for rank-ordered date
Stephenson
Q methodology
Thurstone
equal-appearing interval scales
Turkey
post-hoc multiple comparison