Building Secure and Trustworthy Systems
1/167
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
168 Terms
Why care about hacking incidents (companies)
Costs the business money, reputation, and trust of customers.
Publicly known hacking incidents
Typically are business-to-customer (B2C)
Business-to-business incidents
Often less publicly known, and implies more damage
The CIA (acronym)
Confidentiality, Integrity, Availability
Confidentiality (CIA)
Ensures that sensitive information is accessible only to authorized entities.
Confidentiality key techniques
Encryption, Access Control, Data Classification
Integrity (CIA)
Ensures that data is untampered and accurate
Techniques to ensure integrity
Hashing, Checksums, data validation mechanisms
Availability (CIA)
Ensures that information and resources are accessible to authorized users when needed
Key techniques to ensure availability
Backup systems, redundancy, protection against DOS attacks etc
AAA acronym
Authentication, Authorization, Access Control (Accounting)
Authentication (AAA)
The process of verifying the identity of an entity (user, device, system)
What does authentication include (AAA)
It can include passwords, MFA, biometrics, and security tokens
Authorization (AAA)
Determines what authenticated users are allowed to do within a system based on their roles/permissions
What can authorization be managed by (AAA)
Access control models, such as RBAC (role-based access control)
Access Control (Accounting)
Controlling access of system entities (on behalf of subjects) to objects based on an access control policy (so-called Security Policy)
Encryption
Process of converting readable data (plaintext) into an unreadable format (cipher text) to protect it from unauthorized access
Encryption types
Symmetric, Asymmetric, Hashing
Symmetric encryption
Uses the same key for encryption and decryption (eg AES)
Why use Symmetric Encryption
Fast encryption and decryption, as it uses the same key for both
Allows high-speed data processing, therefore suitable for apps requiring rapid data processing
Has low computational overhead compared to to asymmetric encryption
When to use Symmetric Encryption
Data’s at rest: encrypting data while it’s not in use, such as encrypting files on a storage device
Data’s in transit: encrypting data as it’s transmitted over a network, such as HTTPS encryption
Speed-sensitive apps: when high-speed encryption is necessary, such as video conferencing or online gaming
Two main types of symmetric encryption
Block (AES)
Stream (RC4)
Asymmetric Encryption
Uses a public-private key pair, where one encrypts and the other decrypts
Why use asymmetric encryption
High-security standards: ensures that even if unauthorized entities gain access to public key, they cant access encrypted data (as they don’t have the private key
**important! establish a secure connection to exchange cryptographic keys!
When to use asymmetric encryption
Digital signatures: authenticating the sender of a message
Secure communication: encrypting data for secure communication over the internet, such as email or IM
Hashing
Process of converting data into fixed-length strings of characters, which cannot be reversed
Why use hashing
Gives more secure and adjustable method of data retrieval
Is quicker than searching lists/arrays
Hashing, unlike other data structures, doesnt define speed- a balance between time/space must be maintained while hashing.
When to use hashing
Password verification, compiler operation, data structures
Other examples of encryption
HTTPS, SSL/TLS, VPN, email encryption like PGP
Malware
Short for malicious software- refers to software intentionally designed to cause harm, exploit, or damage computers, networks, or data
Types of Malware
Viruses: worms, trojans, ransomware, spyware
Phishing: social engineering attacks aimed at stealing sensitive info by tricking users through fake emails, websites, or messages
Zero-day exploits: attacks that take advantage of software vulnerabilities before the vendor can release a patch
Penetration Testing
Process of simulating attacks on a system to identify vulnerabilities before malicious actors can exploit them
Approaches to pen testing
Ethical hacking: authorized attempts to bypass system security to help improve defenses
Red team vs blue team: red teams simulate attacks, while blue team focuses on defense
Purple teams: a combined approach of red and blue
Zero trust architecture
Security model that assumes no one can be trusted by default, regardless of whether theyre inside/outside the network. This means that every request must be both authenticated, and authorised
Micro-segmentation
Dividing network into smaller zones to apply stricter access controls and limit lateral movement by attackers
Secure and Trustworthy System
A computing system that is designed, implemented, and operated w/ strong protections to ensure the confidentiality, integrity, availability (CIA), and privacy of the data and operations it handles, while also being reliable and resilient against potential threats or attacks.
Such a system establishes and maintains user trust by guaranteeing it functions as intended and remains safe from unauthorized interference.
Key Aspects of a Secure and Trustworthy System tm
Confidentiality, Integrity, Availability (CIA), Authentication, Authorization, Accountability and Auditing (AAA), Privacy, Resilience, Trustworthiness, Non-repudiation, all dependent on the functional correctness of the system
Performance-centric design approach
Main interest: increasing speed
Unintended byproduct: security was neglected, as all “performance upgrades” could act as security vulnerabilities
Conventional approach to security
Isolation is key to building secure systems. The basic idea is to protect secrets so that they can’t be accessed across a trust boundary. The assumption is that we know what the trust boundaries are, and we can control access. To do this, they apply privilege separation (mechanism)
Attack Surface
Refers to landscape of vulnerability, where the attacker comes from, and how to (eventually) deal with that.
Is info leakage possible even under safe software?
Yes, there can be hardware vulnerabilities! Architectural and misc-architectural features leak information on the state of program’s execution. It can also leave artifacts that can be exploited as a vulnerability
Historical misconception regarding computer security…?
Adding more abstraction = more secure systems! Typical layers of abstraction: physics → hardware → system software → applications. An ideal abstraction allows each layer to treat the layer below as a black box with well-defined behavior
Issue with more abstraction?
Implementation of these abstractions have artifacts and side effects
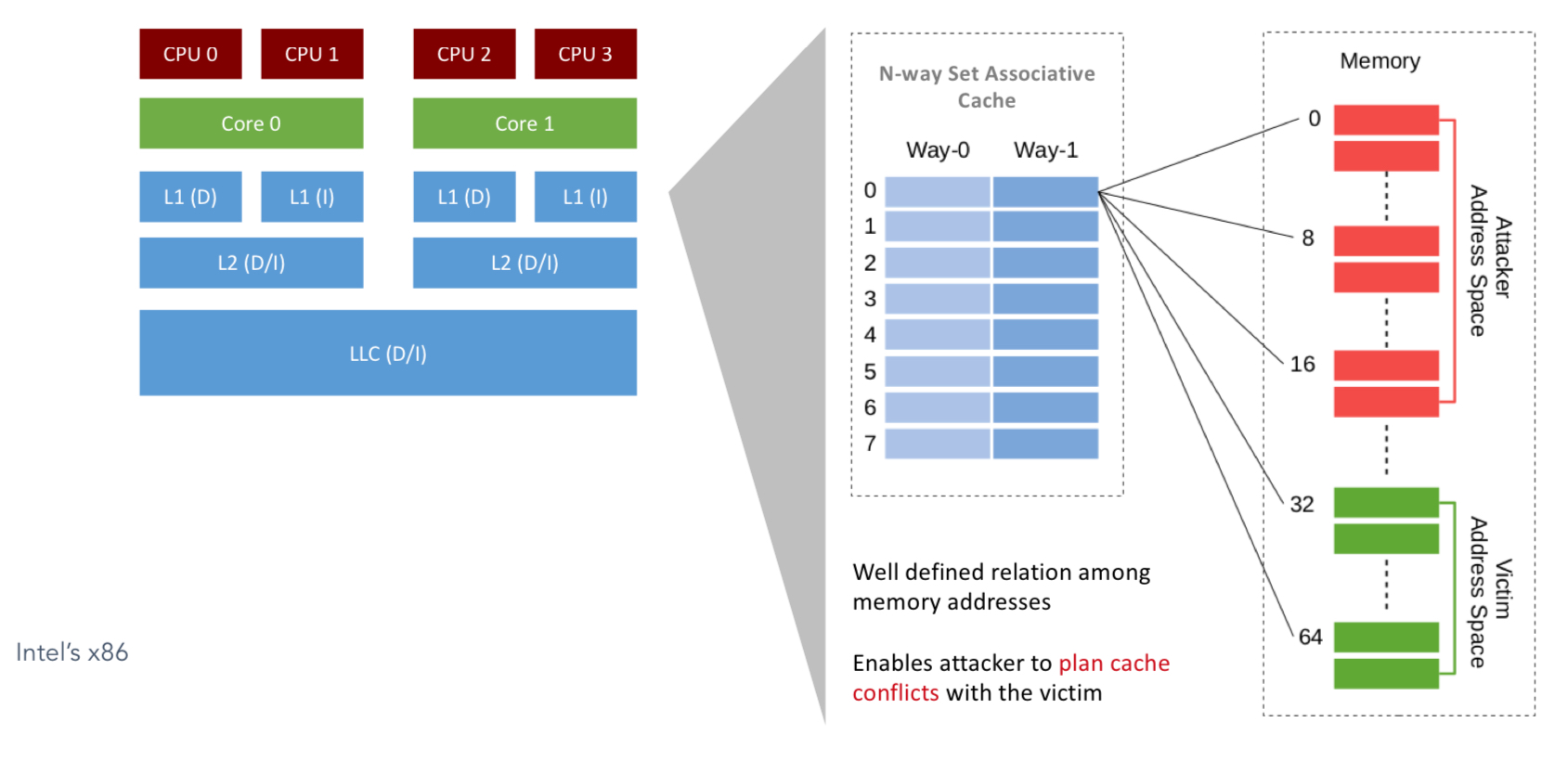
Attack Surface — A Typical Architecture
Layers: Application → OS → Hypervisor → ISA → Microarchitecture → RTL → Gates → Physical
Attack Surface — Functional (Computational) Aspect

Attack Surface — Functional (Storage) Aspect
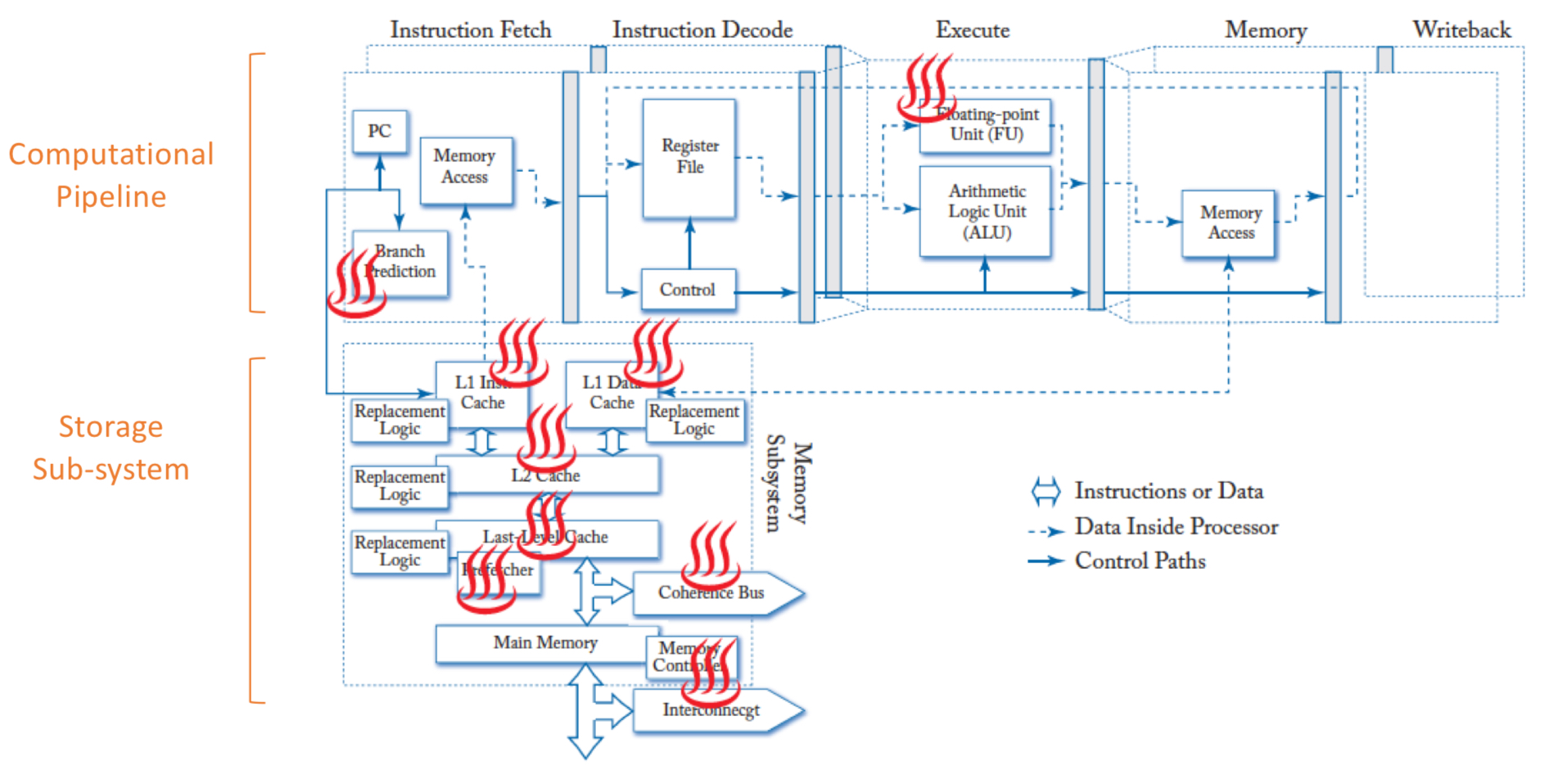
Attack Surface — Threat Level on Functional Aspects
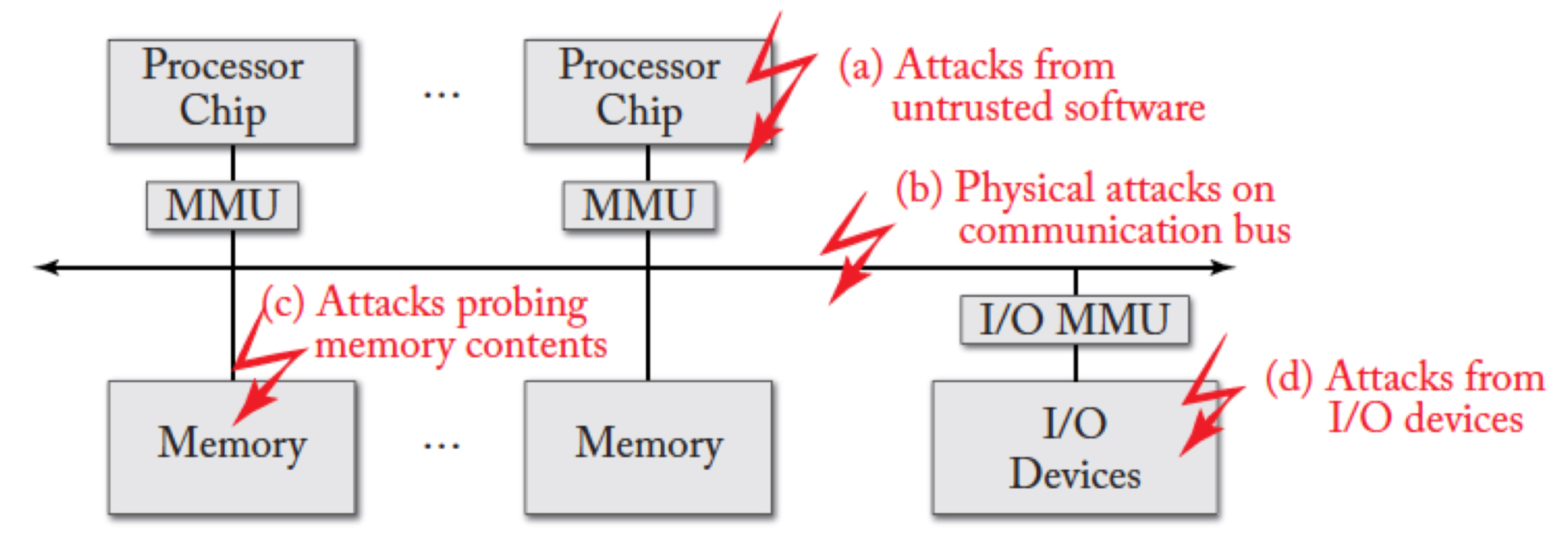
Attack Surface — Physical (Fabrication) Aspect
A) Attacks from untrusted software
B) Physical attacks on communication bus
C) Attacks probing memory contents
D) Attacks from I/O devices
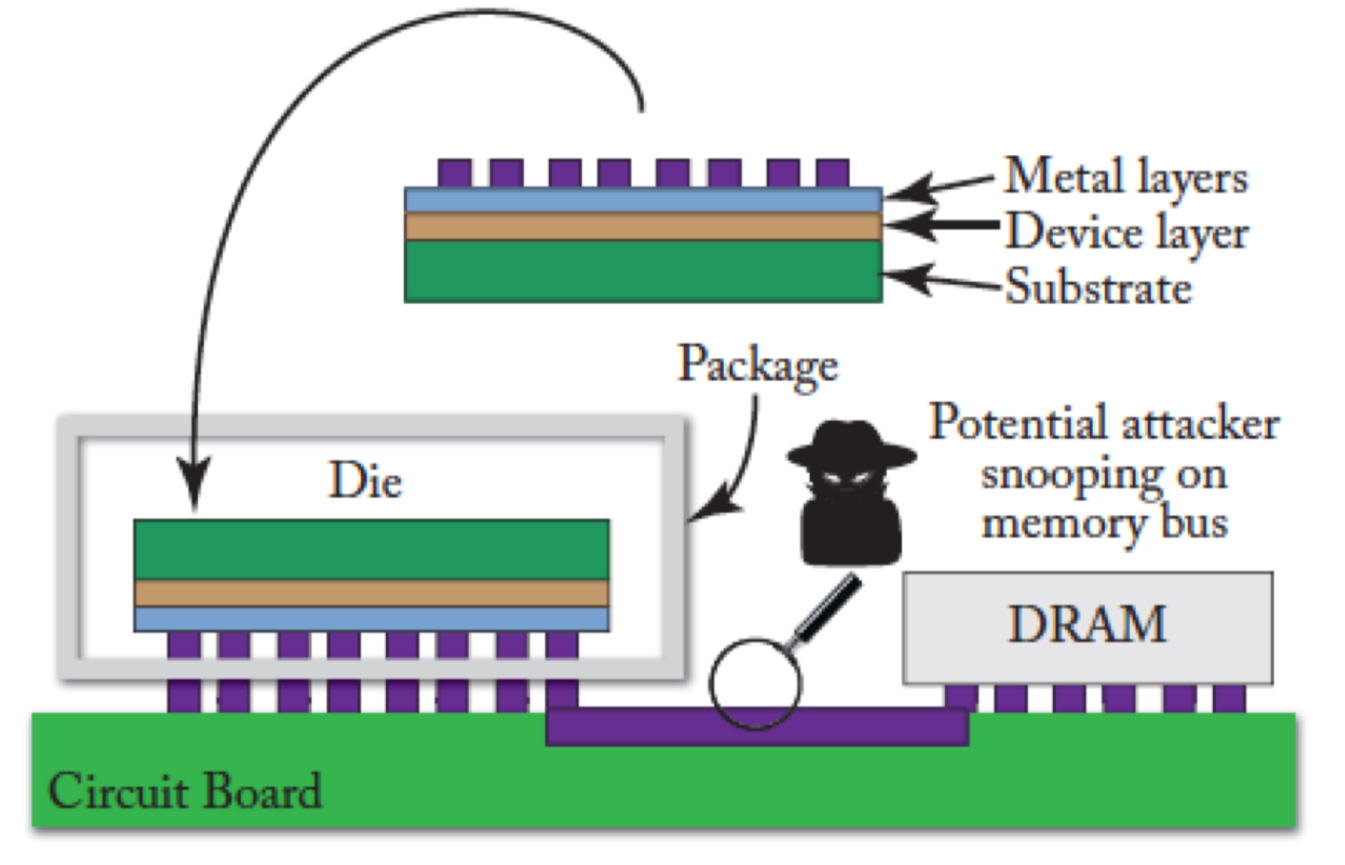
Attack Surface — Physical (Fabrication) Aspect
Attack Surface — System Software Aspect

RISC
Reduced instruction set architecture. A type of CPU design philosophy to improve performance, by reducing the cycles per instruction while increasing the number of instructions per program

CISC
Complex instruction set architecture. A CPU design philosophy to improve performance, by reducing the number of instructions per program while increasing the number of cycles per instruction

RISC Vs CISC differences
CISC emphasizes on hardware, while RISC on software
Control unit used: CISC uses a hardwired and micro programmed control unit, while RISC uses a hardwired control unit
Code size: CISC’s small, RISC’s large
Execution time required for an instruction: CISC; more than one clock cycle, RISC; a single clock cycle
Use of pipeline: CISC’s difficult while RISC is easy
Decoding instructions: CISC’s difficult, while RISC’s simple
Instruction format: CISC’s variable while RISC’s fixed
Examples: of CISC; VAX, System/360, etc.. RISC; power architecture, SPARC, etc..

Common characteristics of RISC
Small (and simple) instruction set,
Single-cycle execution,
Load/store architecture,
Large no. of registers/Large Register set,
Efficient pipelining,
Simple Addressing Modes,
Compiler Optimisation,
Reduced instruction complexity (No Microcode),
High instruction throughput,
Uniform instruction formats
For RISC, a small and simple instruction set means…
Fewer instructions: RISC CPUs have a reduced number of instructions, often numbering in the hundreds
Fixed instruction length: most instructions are of the same size, typically one word (32 bits), which simplifies instruction decoding and speeds up execution
Simple operations: each instruction performs a simple operation (such as arithmetic, logic, or memory access) that can typically be executed in a single clock cycle
For RISC, single-cycle execution means…
Fast execution: each instruction in a RISC processor is designed to execute in a single clock cycle, which leads to faster processing
Simple control logic: the uniformity of instruction timing simplifies the control unit of the CPU, reducing the complexity and improving speed
For RISC, load/store architecture means…
Memory access via Load/Store instructions: only load and store instructions can access memory. All other instructions operate only on registers
Load: moves data from memory to a register
Store: moves data from a register to memory
Faster operations: by limiting memory access to load/store instructions, the CPU spends more time operating on data in registers, which are faster to access than memory
For RISC, large no. of registers mean…
Register-based operations: RISC CPUs typically have a large number of general-purpose registers, allowing more data to be stored directly in the CPU and reducing the need to access slower main memory
Register-to-Register Operations: most arithmetic and logic operations occur between registers, which reduces the memory access bottleneck and speeds up computation
For RISC, pipelining means…
High Performance: RISC architecture’s designed for efficient pipelining
A technique that allows multiple instructions to be processed simultaneously at different stages (fetch, decode, execute, etc)
Uniform instruction Execution: as RISC instructions have uniform execution times, pipelining is easier to implement and is highly efficient
For RISC, simple addressing modes mean…
Few addressing modes: RISC processors use a limited set of addressing modes (ways to reference memory locations). This helps keep the instruction set simple, and efficient
Common modes: Typical RISC addressing modes include immediate, register direct, and base + offset
For RISC, compiler optimization means…
Dependence on Compiler(: RISC architecture relies heavily on optimizing compilers to generate efficient code. The simpler instructions of RISC are more predictable and easier for compilers to optimize for performance)
Instruction scheduling(: compilers are responsible for instruction scheduling, ensuring that instructions are ordered in a way that maximizes pipelining efficiency and minimizes pipeline stalls)
For RISC, reduced instruction complexity means…
No Microcode: unlike CISC, which may use microcode to break down complex instructions into simpler internal operations, RISC executes simple instructions directly in hardware
No special-purpose instructions: RISC avoids complex, specialized instructions, focusing instead on providing a core set of fast, frequently used operations
For RISC, high instruction throughput means…
Optimized for Speed: the combo of small, fast, instruction set, pipelining, and load/store architecture enables RISC processors to execute a large no. of instructions per second
Parallelism: the streamlined instruction execution allows for high degrees of instruction-level parallelism
Regarding RISC, simple instruction formats mean…
Uniform Format: RISC instructions generally have a uniform format, which reduces that complexity of decoding instructions. E.g. most instructions use a fixed 32-bit length in many RISC architecture
Ease of decoding: simple, uniform instruction formats make it easier for the processor to decode instructions quickly and efficiently
Examples of RISC architecture
ARM: widely used in mobile devices and embedded systems
MIPS: Used in networking equipment, game consoles, and embedded systems
SPARC: Dev’ed by Sun Microsystems, used in enterprise servers
PowerPC: Used in embedded systems and earlier Apple Computers
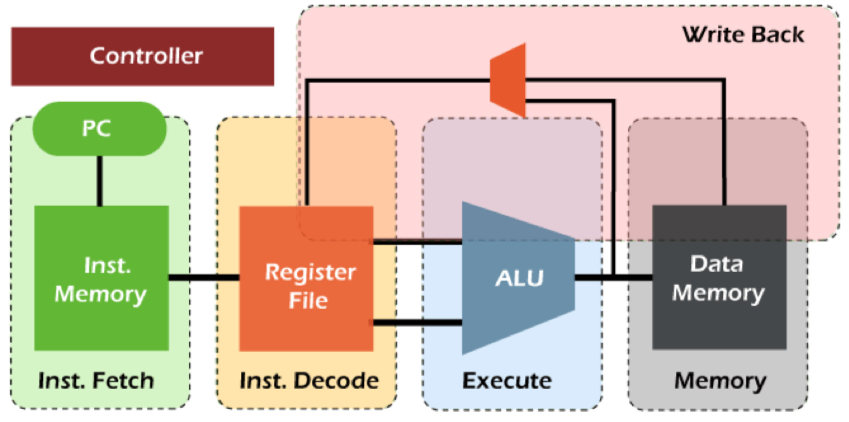
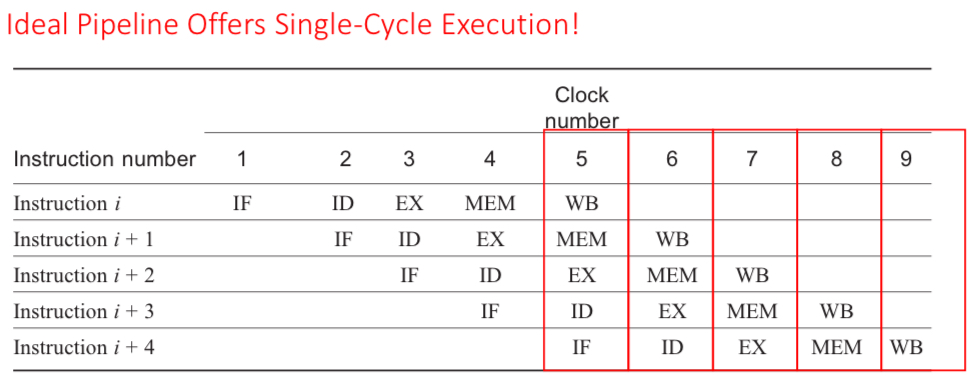
IF
Instruction Fetch: send the program counter (PC) to memory and fetch the current instruction from memory. Update the PC to the next sequential PC by adding to the PC
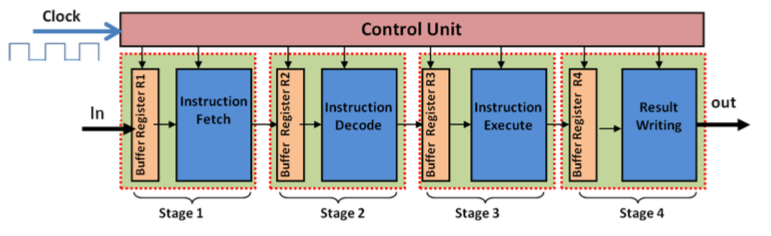
ID
Instruction Decode: Decode the instruction and read the registers corresponding to register source specifiers from register file

EX/IE
Execution (or Instruction Execute): ALU operates on the operands prepared in the prior cycle, performing functions depending on the instruction type
MEM
Memory Access (MEM): For LOAD, the memory does a read using the effective address computed in the previous cycle. For STORE, the memory writes the data from the second register read from the register file using the effective address
WB/RW
Write Back (or Result Writing): Write the result into the register file, whether it comes from the memory system (for a load) or from the ALU (for an ALU instruction)

Pipeline hazards can lead to..
Vulnerabilities
CPI
Cycles per instruction
When it’s RISC architecture, assume CPI is…
1
Avg instruction exec time formula
Clock cycle x Average CPI
Computational Pipeline
PC → IF (Instruction Memory) → ID (Register File) → EXE (ALU) → MEM (Data Memory) → WB (Write Back) → ID (Register File)
Ideal Pipeline Offers…
Single-Cycle Execution

Example for unpipelined processor
NS Clock cycle: 1
Cycles for ALU operations (occur 40% of time) and branches (occur 20% of time): 4
Cycles for memory operations (occur 40% of time): 5
Pipelining adds overhead: 0.2 ns
1 ns x [ 40% x 4 + 20% x 4 + 40% x 5 ] = 4.4 ns

Example for pipelining and unpipelined processor (pipelined ver):
NS Clock cycle: 1
Cycles for ALU operations (occur 40% of time) and branches (occur 20% of time): 4
Cycles for memory operations (occur 40% of time): 5
Pipelining adds overhead: 0.2 ns
1.2 ns (since pipelining, all cycles become 1)
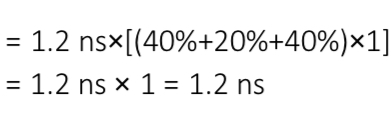
Calculating Speedup from Pipelining
Avg Instr. Time Unpipelined / Avg Instr. Time Pipelined
Pipelining Hazards
Structural Hazards, Data Hazards, Control Hazards
Structural Hazards
Arise from resource conflicts
Hardware cannot support all possible combinations of instructions simultaneously in overlapped execution
Data Hazards
Arise when instructions depend on results of previous instructions (data dependencies) in a way that is exposed by overlapping of instructions in the pipeline. It’s more about the content of the registers rather than accessing.

Control Hazards occur from…
branches and instructions that change Program Counter (PC)
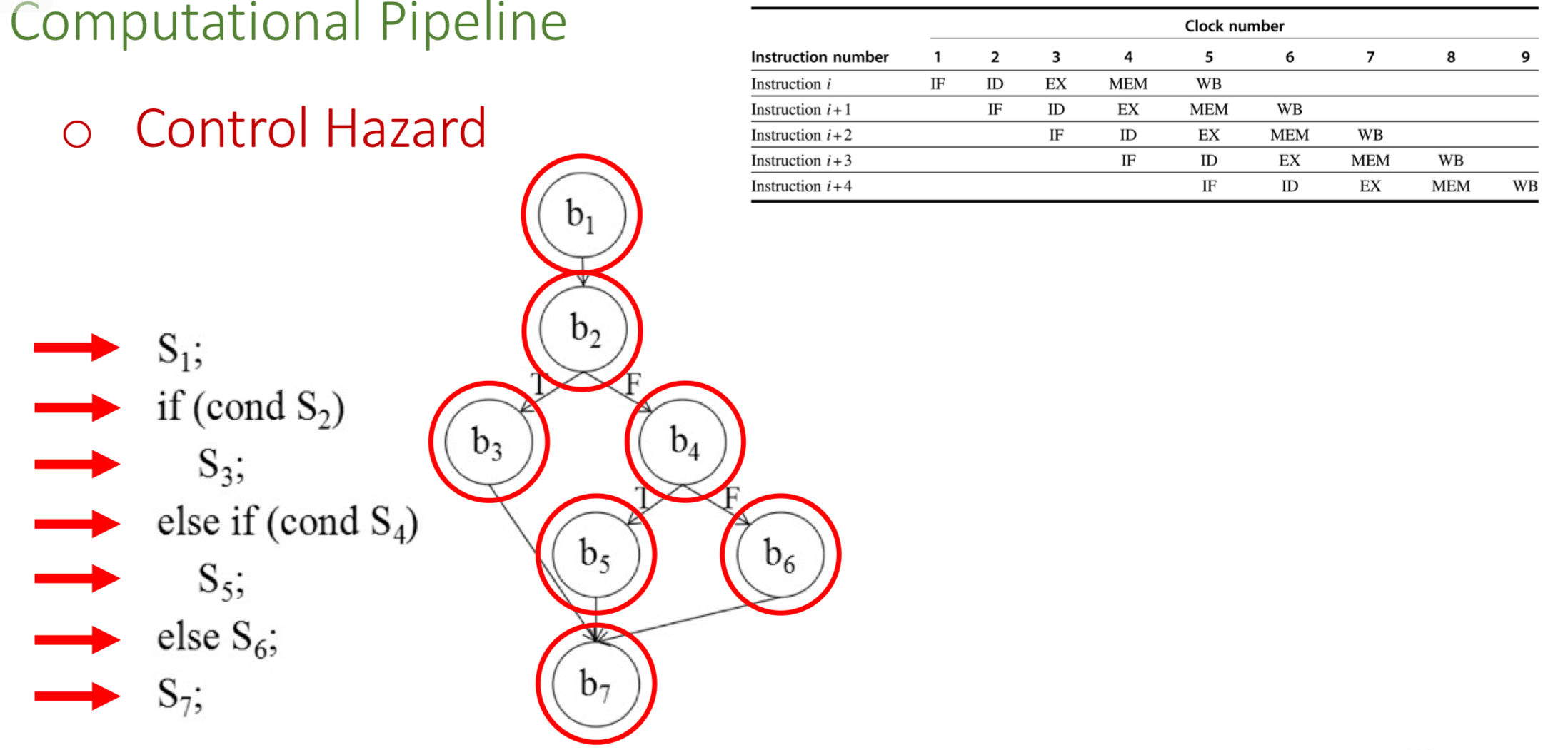
Hazards
A side-effect of pipelining- pipelining alters sequence of program execution. Occurs due to a lack of sufficient resources
Functionally incorrect
When pipelining goes wrong and the program uses a junk value from a register as the originally intended value isn’t available yet so it grabs whatever
Safest solution when functionally incorrect
Stalling
Other solutions (besides stalling) for functionally incorrect pipelining
Static or dynamic prediction
Pipelining has special registers where you can…
Write and read during a cycle
Is XOR affected?
No, as everything after XOR will have access to the data
How to resolve data hazard?
Using stall: waiting results to be done
Or forwarding: allows to pass on results during a pipeline
What does a dotted line represent
Forwarding- propagates results to next cycle
Pipelining Forward principle
Results by subsequent instruction can only be used when the precedent instruction produces them
What does the forwarding hardware do if it detects that the previous ALU operation has written the register corresponding to a source for the current ALU operation?
The control logic selects the forwarded result as the ALU input rather than the value already read from the register file.
Pipeline stalls
Basically a NOP (no-operation instruction)— becomes a necessity to avoid hazards.
What happens when an instruction is stalled
All instructions issued later than the stalled instruction are also stalled! Instructions issued earlier than the stalled instruction, and hence further along in the pipeline, must continue
Which is greater- performance losses or data hazards?
Performance losses
What happens to the PC if a branch is executed?
May or may not change the PC to something or their than its current value plus 4 (if it does, instructions already fetched are useless operations) (an adversary may deliberately cause an unwanted instruction fetch)
Critical Path
Longest possible path in your code
Taken Branch
When a branch changes the PC to its target address. If it falls through, it is not taken
Branch Delay
Is the delay in updating the PC if instruction i is a taken branch, then the PC is not changed until the end of ID (instr. decode)