machine learning fundamentals
1/18
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
19 Terms
ml
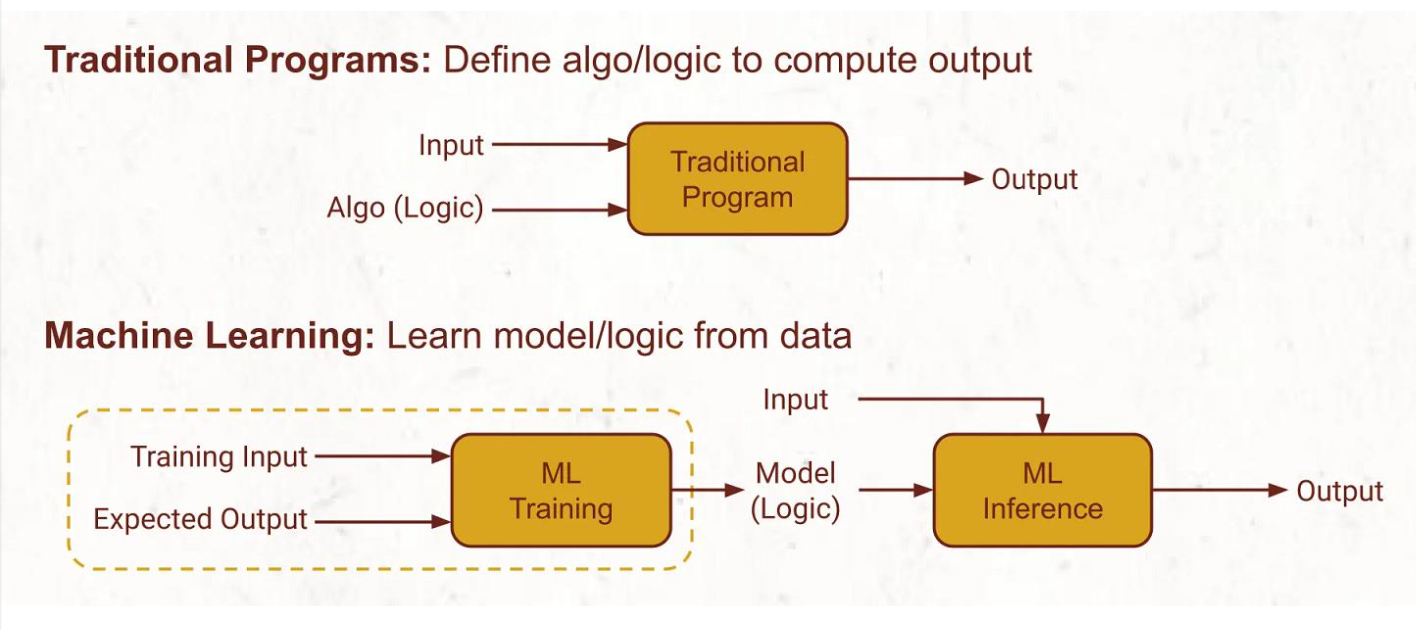
trad programs: define algo/logic to compute output
ml: learn model/logic from data
ml = study of also that: improve their performance P at some task T with experience E
well defined learning task = given by <P, T, E>

why use ML? + applications
-human expertise doesn’t exist (navigating Mars)
-humans x explain their expertise (speech recognition )
-models must be customised (personalised medicine)
-models = based on huge amts of data (genomics)
applications:
recognising patterns
generating patterns
recognising anomalies
prediction


data sets + features
data set
= set of data grouped into a collection with which developers can work to meet their goals. In a dataset, rows represent the no of data points + column = features of data set
features of dataset = most critical aspect- based on the features of each available data point, is there any possibility of deploying models to find output to predict the features of any nee data point that may b added to data set
data
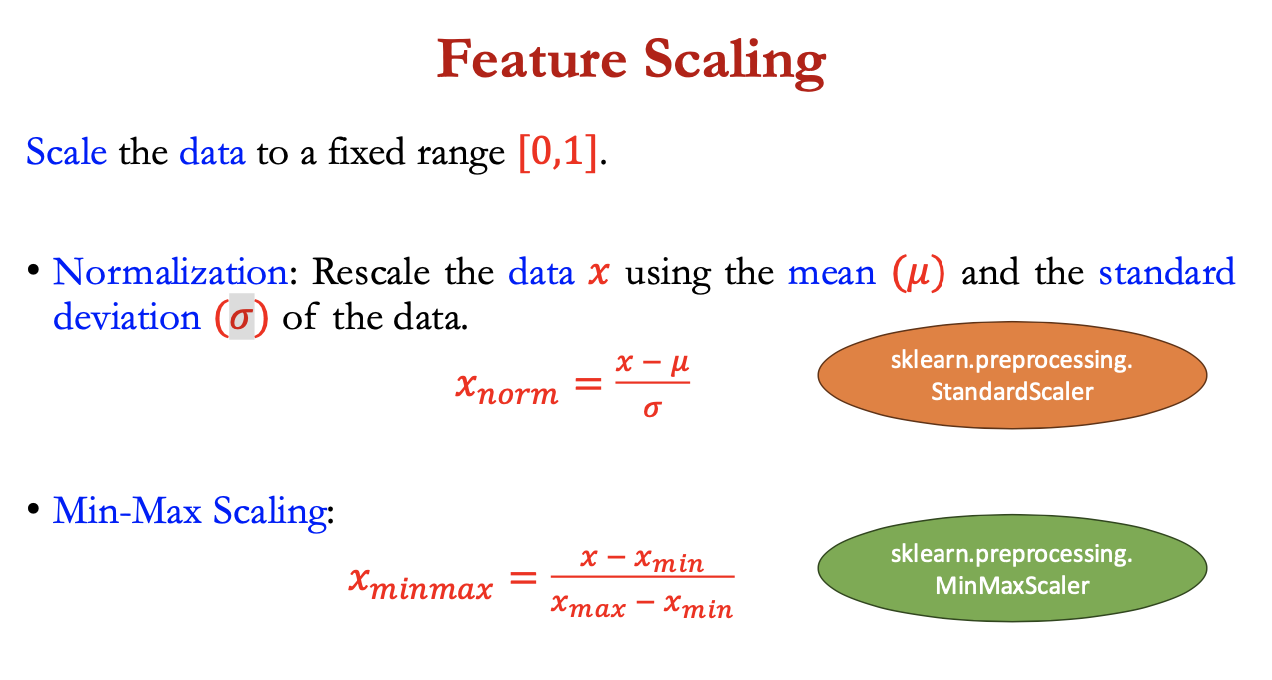
feature scaling
= scale data to a fixed range [0,1]
normalisation = rescale data x using the mean 𝜇 + the s.d. 𝜎 of the data
= (x- 𝜇) / 𝜎
min max scaling: (x - xmin) / (xmax - xmin)
types of data:
numerical (quantitive): continuous, discrete
categorical (qualitative): ordinal, nominal
the task T
tasks = usually described in terms of how the machine learning should process and example: 𝑥 ∈ R𝑛 where each entry xi = a feature
classification: learn f: Rn → {1,…,k}
y=f(x): assigns input to the category with output y
example: object recognition
regression: learn f: Rn → R
example: weather prediction, real estate price prediction

the experience E
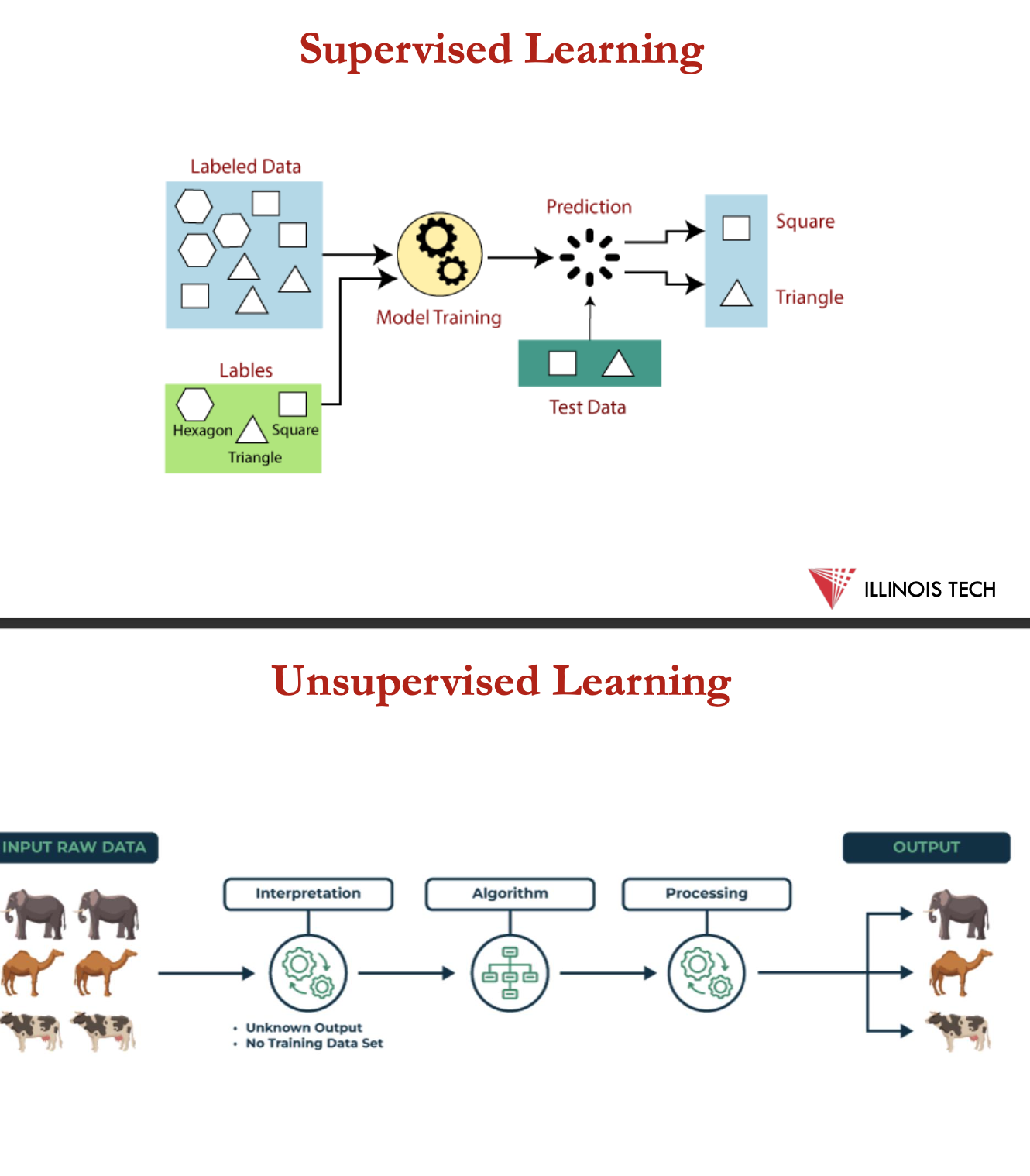
supervised learning:
experience is a labelled dataset (or datapoints)
each data point has a label or target
unsupervised learning:
experience = unlabelled data set
clustering, learning probability distribution, demonising etc.
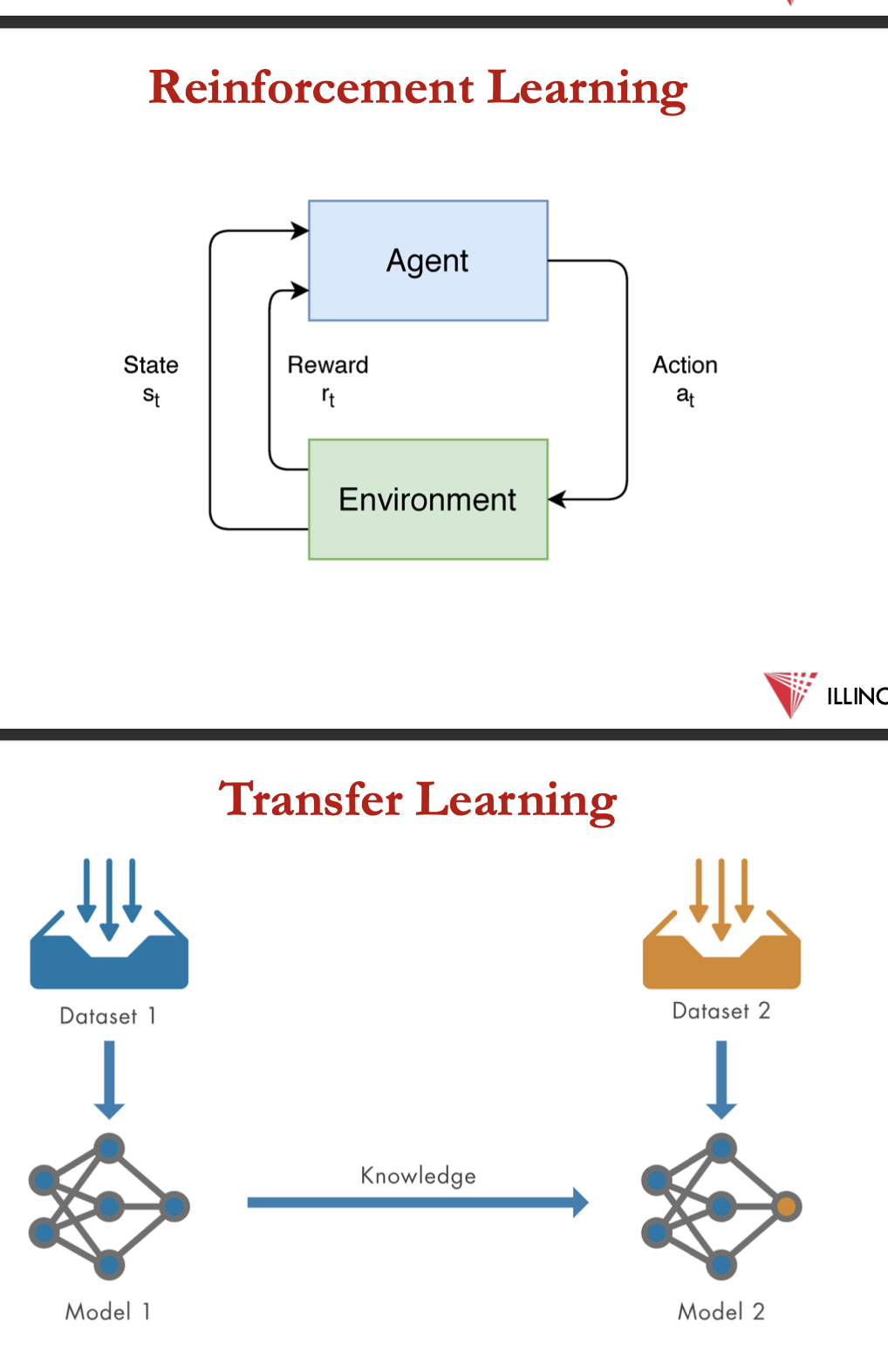
reinforcement learning:
experience is the interaction with an environment
types of learning
supervised learning
given (x1, y1), (x2, y2), … (xn, yn)
learn a function f(x) to predict y given x
y is real-valued == regression
y is categorical == classification
the performance measure P
accuracy = proportion of examples for which the model produces the correct output
error rate: proportion of examples for which the model produces an incorrect output
loss function: quantifies the difference between the predicted outputs of a ml also + the actual target vals
generalisation: ability to perform well on previously unobserved data e.g. evaluate performance using test set
learning process
X = input space, Y = output space
given samples {(x,y)}n1, and a loss function L
find a hypothesis h ∈ 𝐻 that minimises ∑𝑖=1,...𝑛 𝐿(h(𝒙𝑖), 𝑦𝑖).
0-1 loss: 𝐿(h(𝒙), 𝑦) = 1, h(x) ≠ 𝑦,otherwise 𝐿(h(𝒙),𝑦) =0
L2 loss: 𝐿(h(𝒙), 𝑦) = (h(x) - y)²
hinge loss: 𝐿(h(𝒙), 𝑦) = max{0, 1 - yh (x)}
exponential loss: 𝐿(h(𝒙), 𝑦) = e -yh(x)
no free lunch theorem
argues that, w.o. having substantive info abt modelling problem, x single model that’ll always do better than any other model
goal of mlresearch isn’t to seek a universal learning algorithm or the absolute best learning algorithm
the theorem underscores that every algorithm relies on certain assumptions abt data + success of algorithm depends on how well these assumptions align w true nature of the problem
since x also is universally superior = crucial to eval = compare diff algorithms on the specific dataset at hand
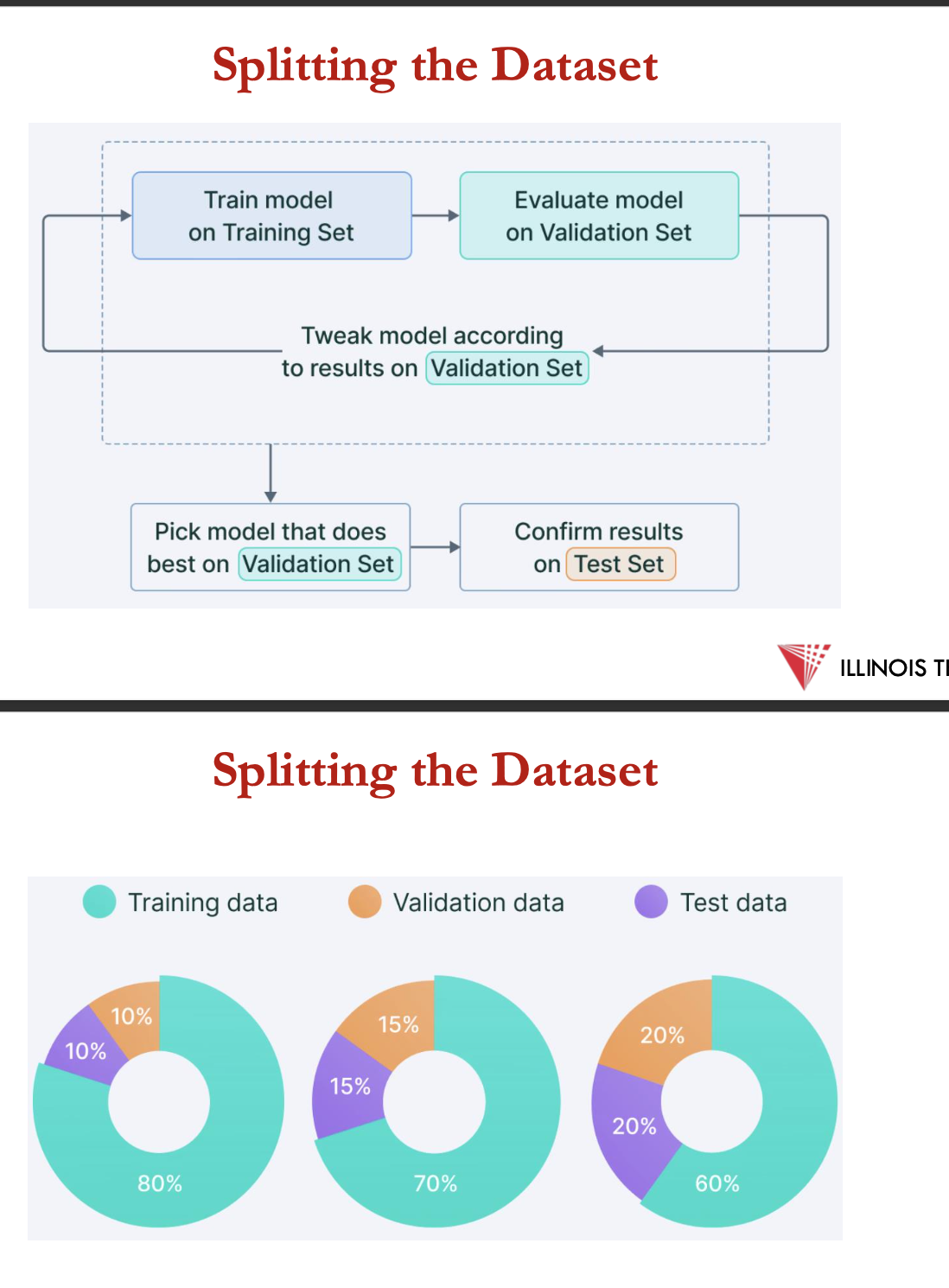
splitting the data set
training set = subset of data used to train a machine learning model
test set= the subset of data used to evaluate the performance of a trained ml model on unseen examples, simulating real-world data
validation set= intermediary subset of data used during the model development process to fine-tune hyper parameters
independent + identically distributed assumptions:
examples in each data set = independent from each other
training + testing set = identically distributed i.e. drawn from the same prob distribution as eachother
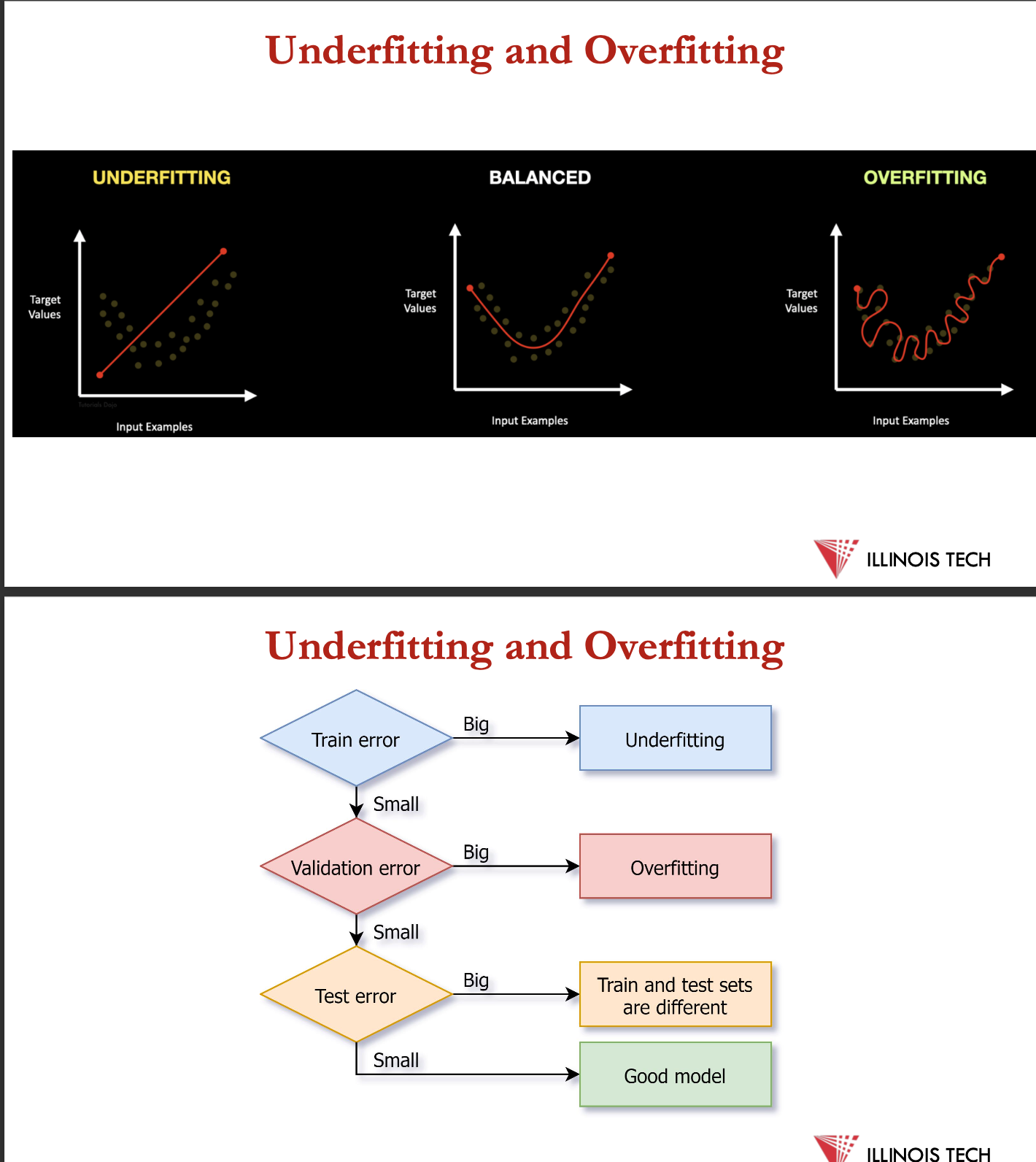
underfitting + overfitting
underfitting occurs when model = too simple to capture underlying patterns in the training data = poor performance on both training + test sets
model isn’t complex enough to learn the relationships within the data
overfitting = model learns the training data too well, incl. its noise + random fluctuations leading to poor performance on new, unseen data
model = overly complex + memorises the training set instead of learning the underlying patterns
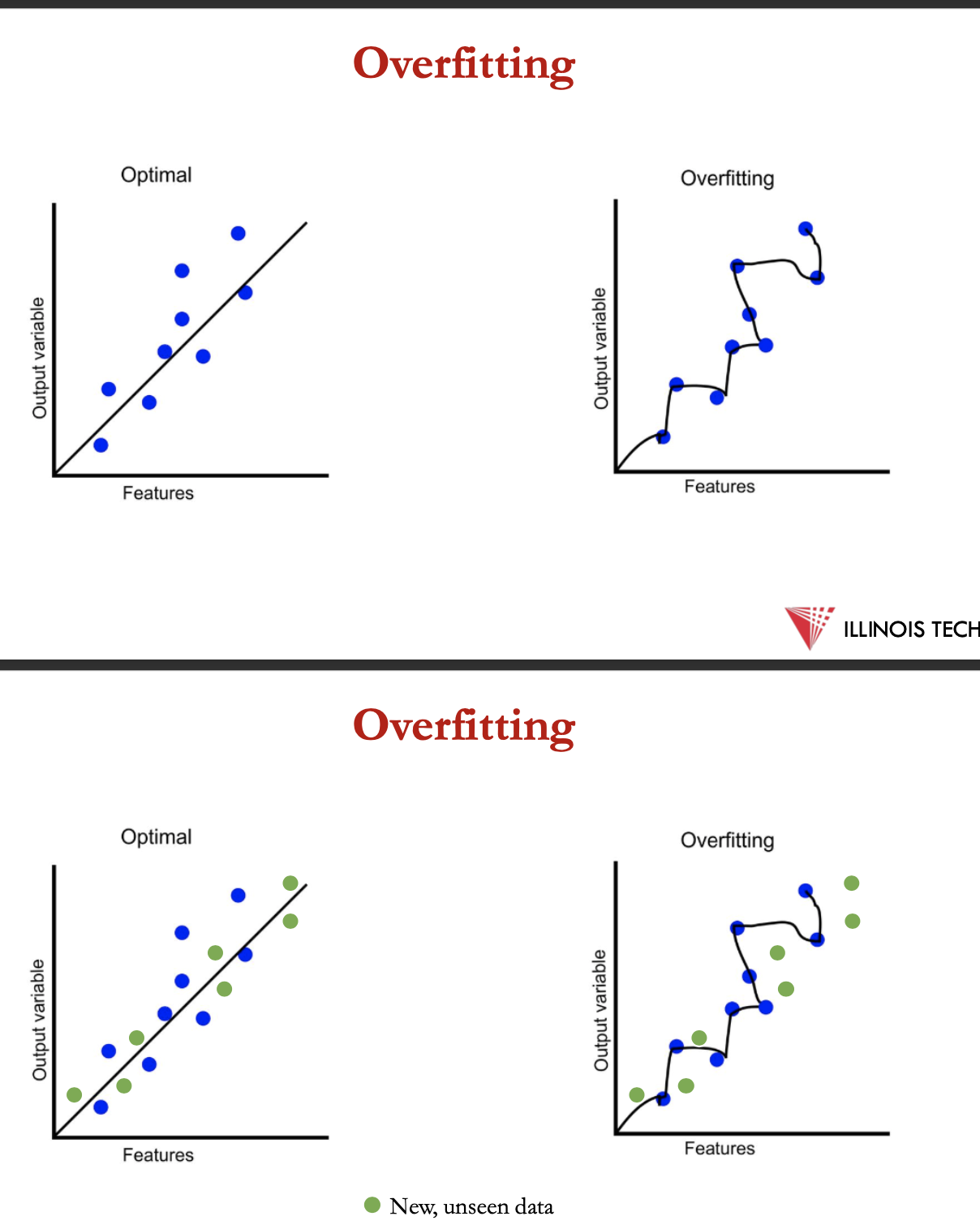
overfitting
a hypothesis in ml is the model’s presumption regarding the connection between input features + the output
consider hypothesis h and its
error rate over training data: error train(h)
true error rate over all data: error true(h)
hypothesis h overfits the training data is there’s an alternative hypothesis h’ that:
error train(h) < error train(h’)
error train(h) > error train(h’)
resolving under + overfitting
underfitting:
↑ model complexity
using diff ml algorithm
↑ amt of training data
ensemble methods to combine multiple models to create better outputs
feature engineering for cresting new model features from the existing ones that may be ↑ relevant to the learning task
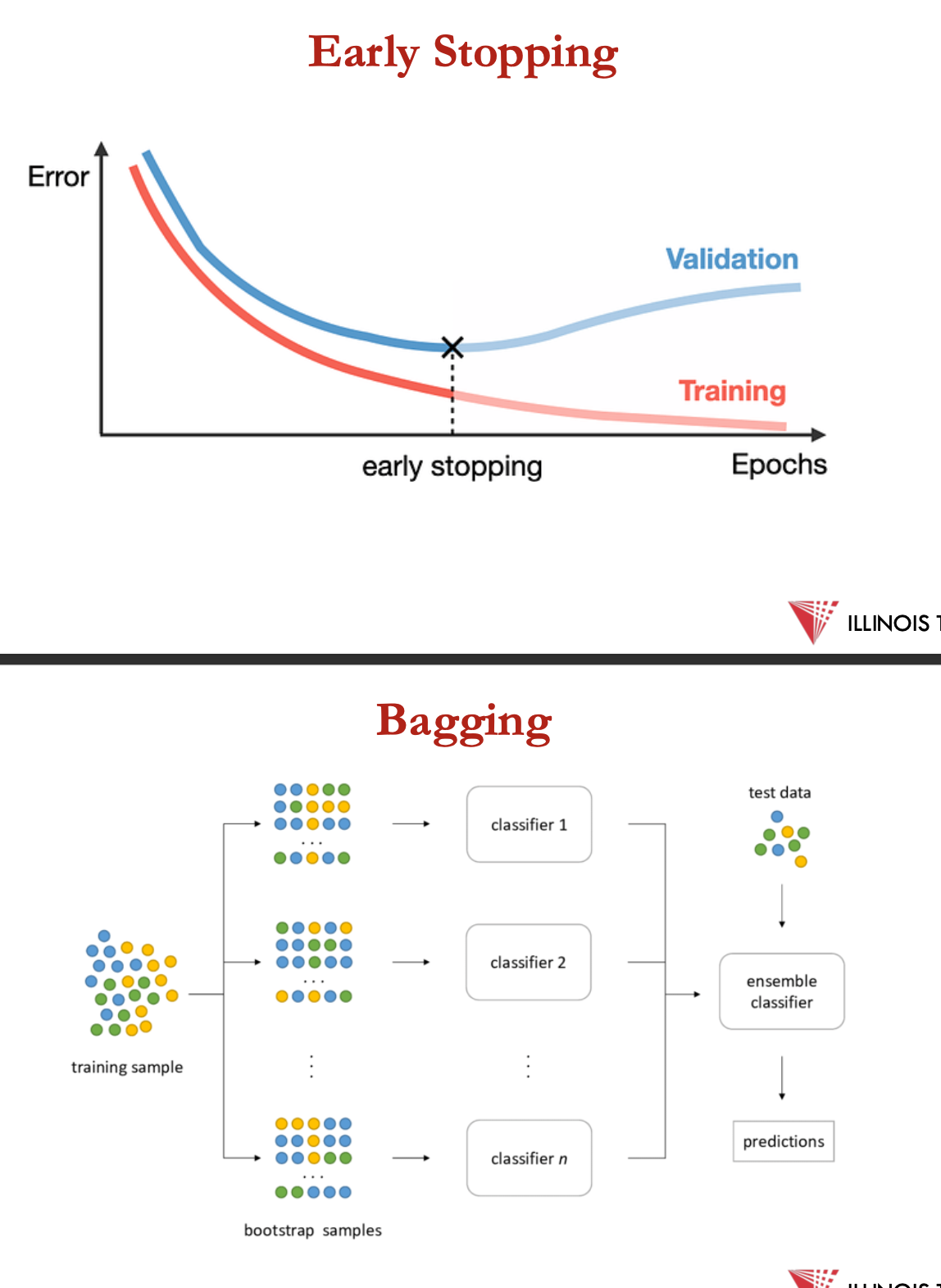
overfitting:
cross validation: technique for evaluating ml models by training several ML models on subsets of the available input data + evaluating them on another subset of the data
regularisation: technique where a penalty term = added to loss function, discouraging model from assigning too much importance to individual features
early stopping: stopping training when a monitored metric has stopped improving
bagging: learning multiple models in parallel + applying majority voting to choose the final candidate model

cross validation
k-fold cross validation:
divide data into k folds
train on k-1 folds, use the 4th fold to measure error
repeat k times: use avg error to measure generalisation accuracy
statistically valid + gives good accuracy estimates
leave one out cross validation (LOOCV):
k fold cross validation with k=N, where N= no of data points
quite accurate but expensive as need to build N models
parametric learning
parametric learning algos make strong assumptions abt form of the mapping function between the input features + output
e.g. logistic regression, linear regression, perceptron, naive bayes, neural network
benefits of such models:
easier to understand + interpret results
v fast to learn from data
don’t require as much training data
can work well even if they do x fit data perfectly
but, by pre-emptively choosing a functional form, these methods = highly constrained to those specified form
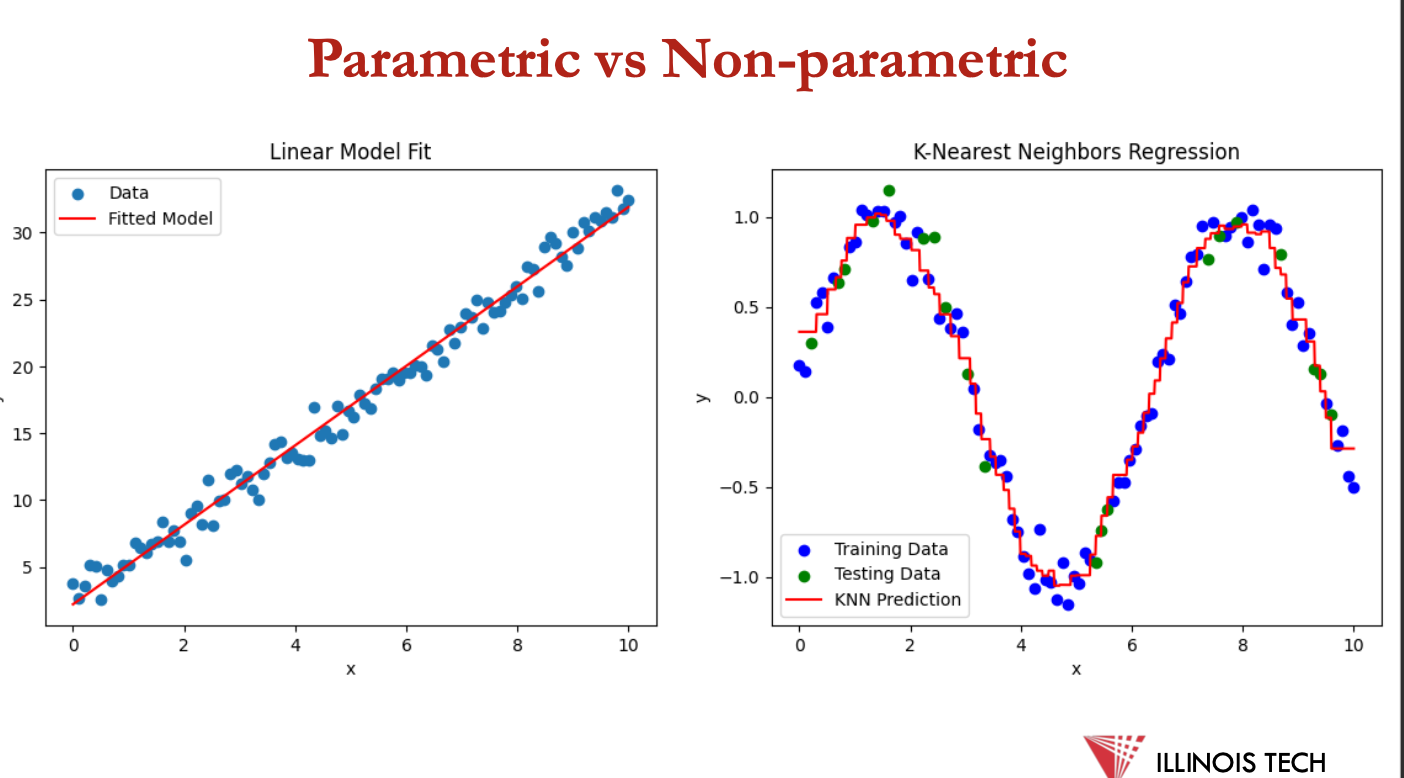
non parametric learning
non parametric learning algos dont make assumptions about the form of the mapping function between the input features + output
for example, SVM, k-NN, k-means, decision tree
benefits include:
being capable of fitting a large no of functional forms
but there are x assumptions abt the underlying function +
can result in higher performance models for prediction
but,: requires a lot more training data, takes longer to train + prone to overfitting
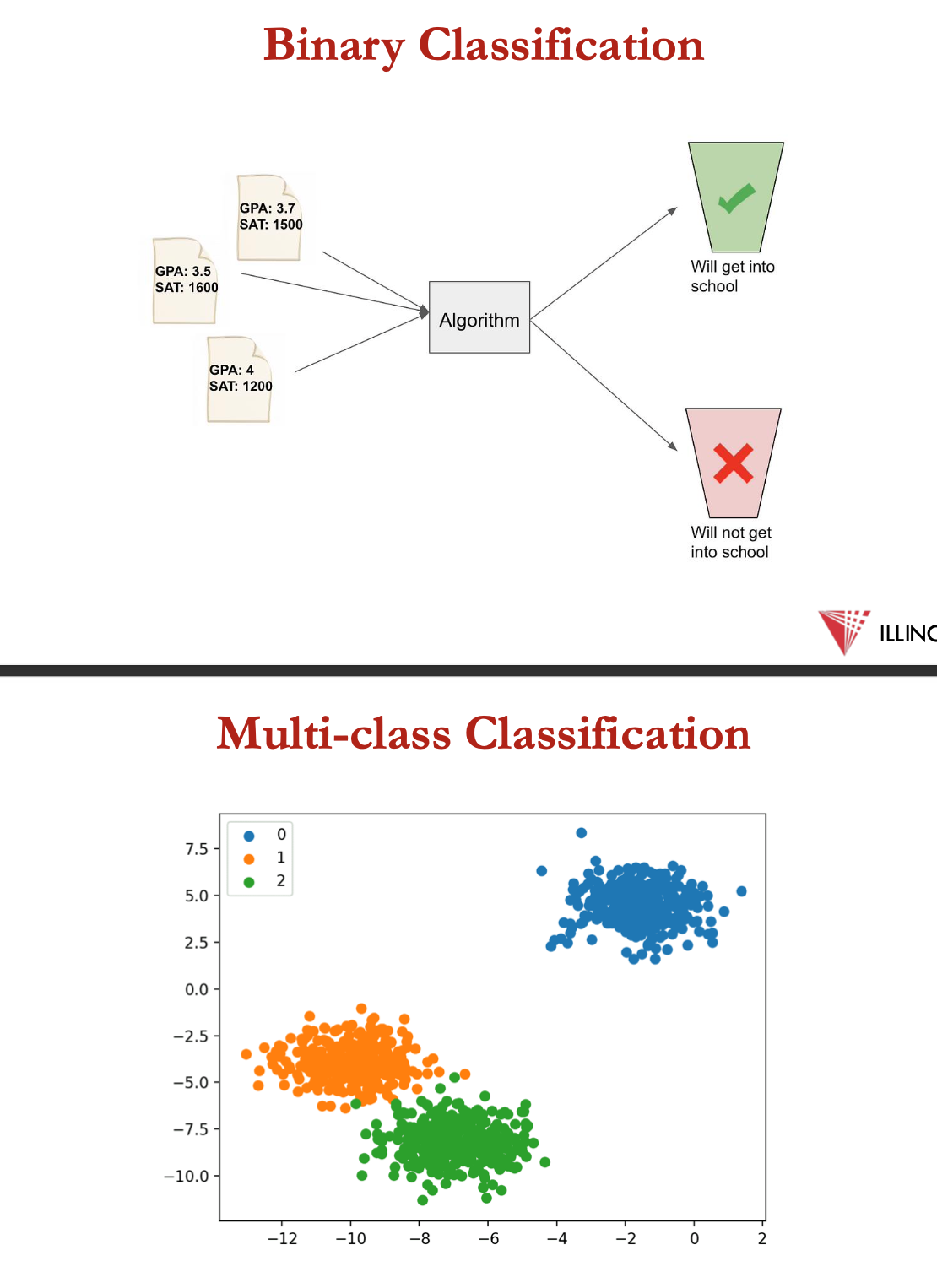
classification
predictive modelling problem where a class label = predicted for a given example of input data
types of classification problems:
binary classification
multi-class classification
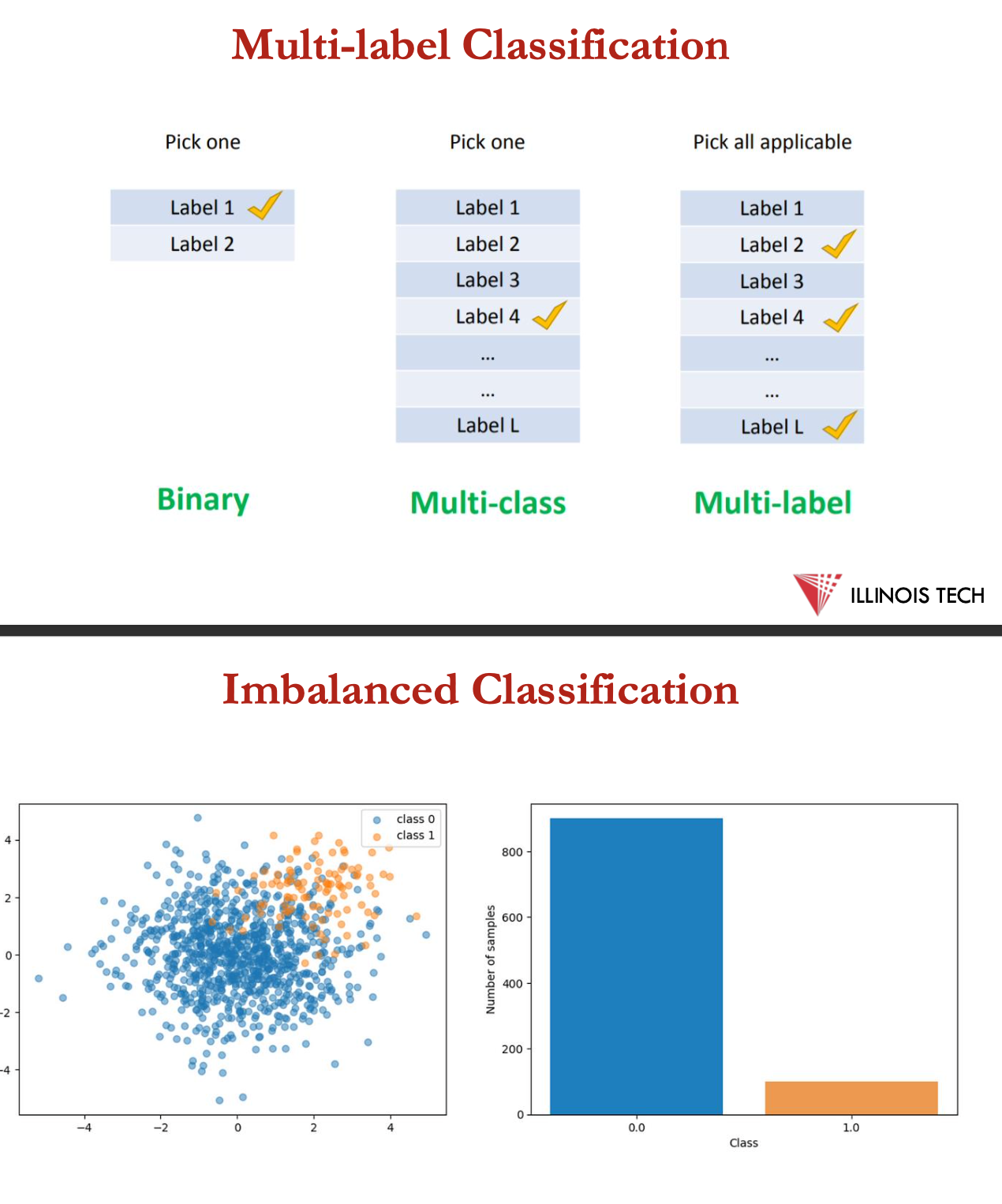
multi-label classification
imbalanced classification
classification applications
Medical diagnosis
oFeatures: age, gender, history, symptoms, test results. oLabel: disease.
• Email spam detection
oFeatures: sender-domain, length, images, keywords. oLabel: spam or not-spam.
• Credit card fraud detection
oFeatures: user, location, item, price. oLabel: fraud or legitimate.