CHAPTER 9: DESIGN A WEB CRAWLER
1/20
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
21 Terms
Web crawler purposes
Search engine indexing
Web archiving
Web mining
Web monitoring
Basic steps of web crawler
Download web pages for given list of URLS
Extra URLs from web pages
Repeat
Requirement questions
What is the purpose
How many pages per month
What content types? HTML or PDF, etc
Should we store HTML contents
Characteristics of good web crawler
Scalable, parallelization
Robust to handle bad HTML, unresponsive server, crashes, etc
Polite: not make too many request to a server
Extensible: easy to support new features
Estimation
Pages to crawl per second
Storage needed: page size x page craw per second x years of storage
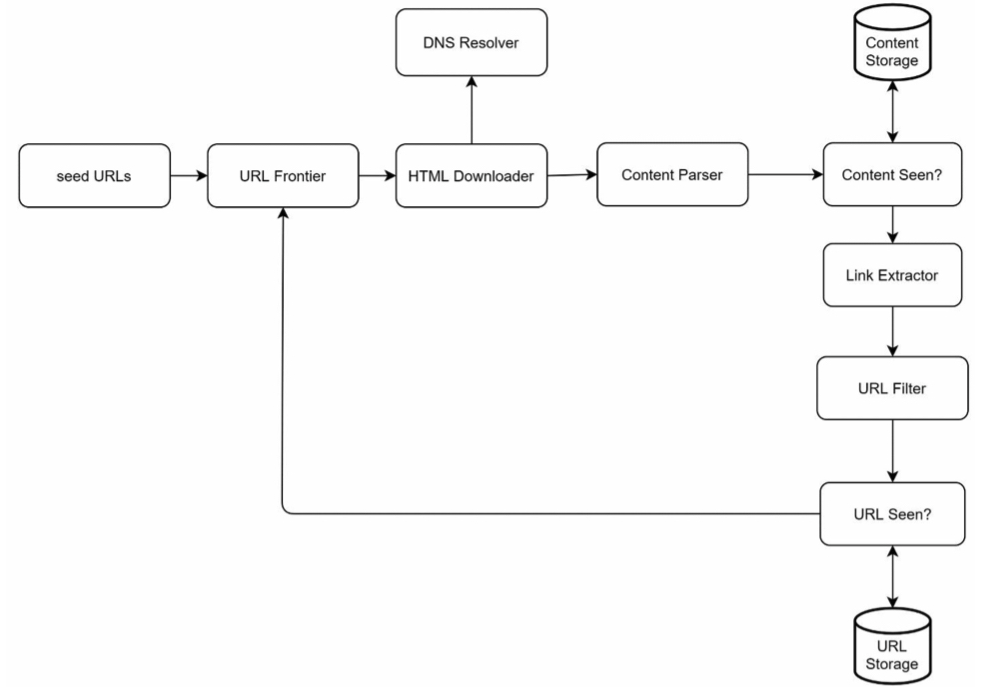
Diagram components
Seed URLs
URL frontier
DNS resolver
HTML downloader
Content parser
Content storage
URL extractor
URL filter
URL storage
What makes good seed URL
Popular websites by countries or topics
Why we need a content parser
Validate web page format
Reduce storage space
What does URL extractor do
Get URL from content
Convert relative URL to absolute ones
What does URL filter do?
Exclude certain content types
Exclude error links
Exclude blacklisted sites
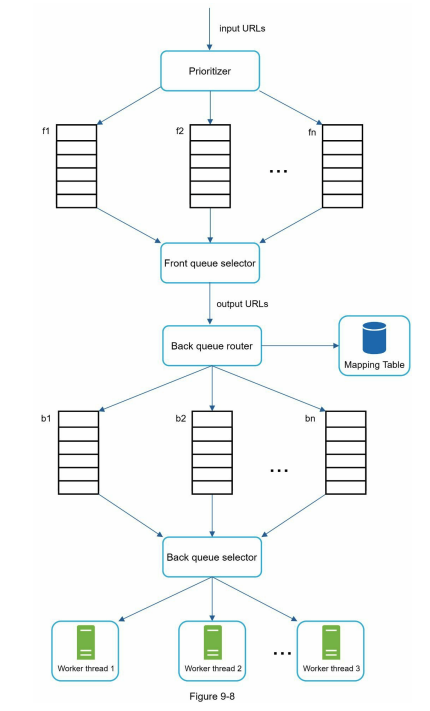
Requirements of URL frontier
Prioritize more important URLs
Rate limit requests to each domain
URL frontier components
Prioritizer: compute prioritization of URL
Front queue each with different priority
Front queue selector: choose a queue to process with bias towards high priority
Mapping table: map domain to queue
Back queue router: enqueue URL to corresponding queue based on domain
Back queue: contains URL from list of domains
Back queue router: router queue to workers
When to recrawl pages
Based on historical update frequency
Based on importance
How does storage for URL queue work
Storage in disk because it won’t all fit in memory
Write to memory buffer first and bulk write to disk
Bulk fetch from disk to memory for data to dequeue
What is Robots.txt
Robots exclusion protocol
Specifies what pages crawlers are allowed to download
How to speed up HTML downloading
Scale up downloader
Cache DNS records
Deploy downloader closer to website hosts
Specify max wait time
How to make the system more robust
Have multiple downloaders
Save craw states and data snapshot
Exception handling to prevent crash
Data validation
Where to add more modules such as download PNG files?
After content parser
How to check if web page is duplicate?
Check hash
What is spider trap
A webpage that causes crawler in an infinite loop. For example, infinite deep directory structure
Wrap up talking points
Server side render SPAs
Filter out spam webpages
Increase database availability
Collect analytics