Nasals and Liquids CGSC433 exam 3
1/103
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
104 Terms
what's the source of sound for nasals
voicing
how is the sound for nasals generated at the source filtered by the vocal tract?
the filter-vocal tract configuration is more complex than for vowels, with not only tubes that are acoustically coupled but also with tubes that branch
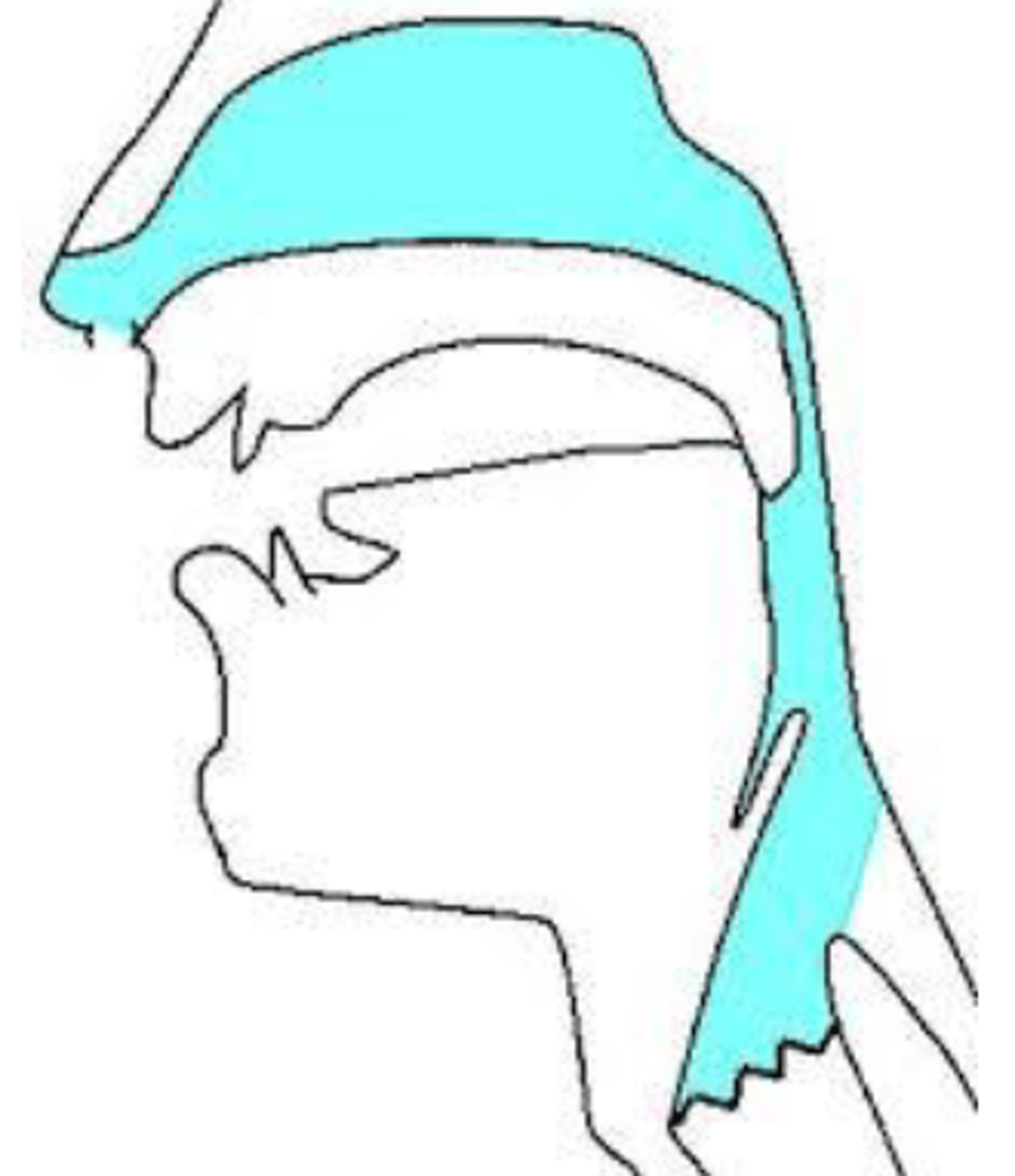
for nasals the velum is
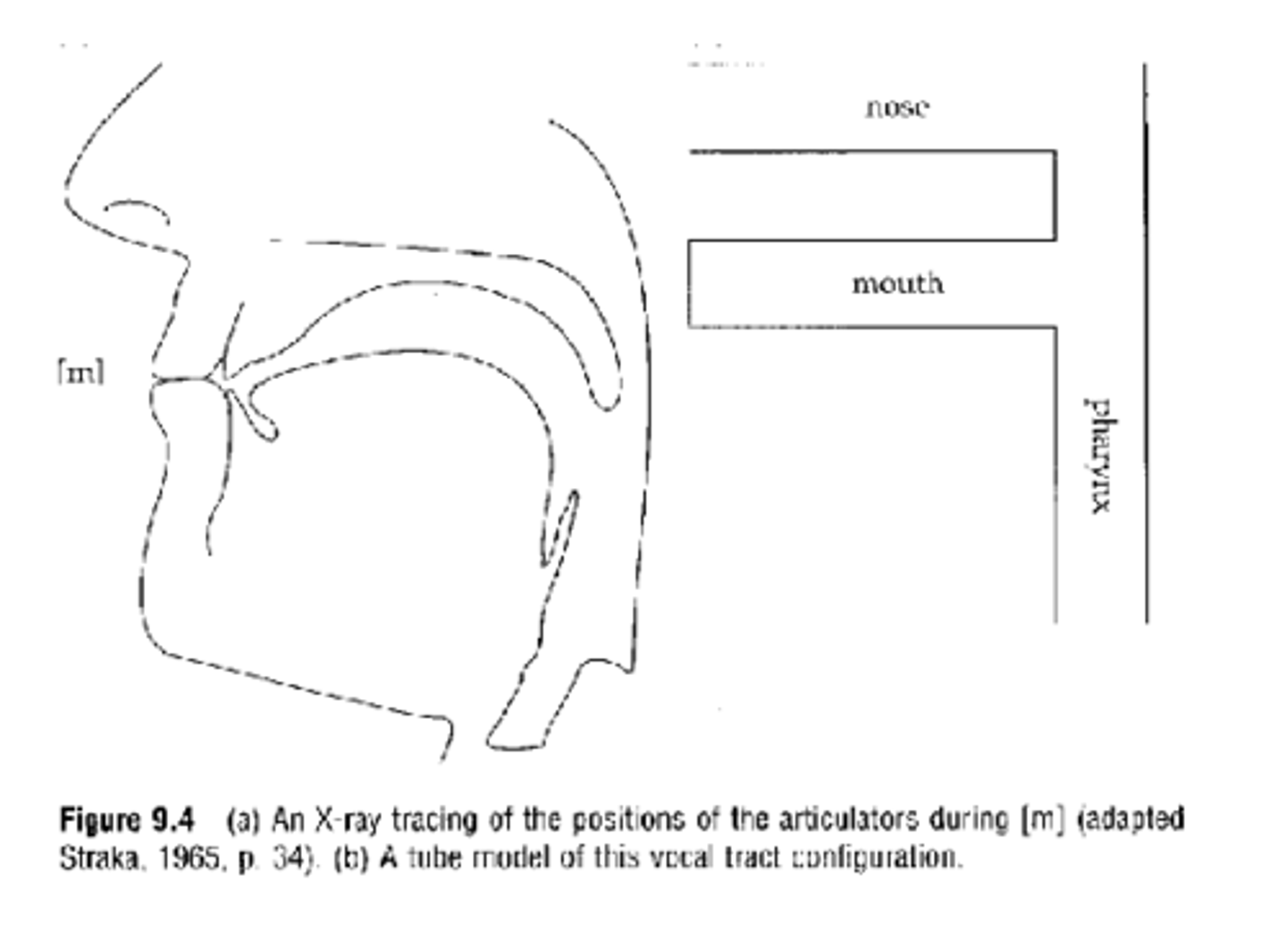
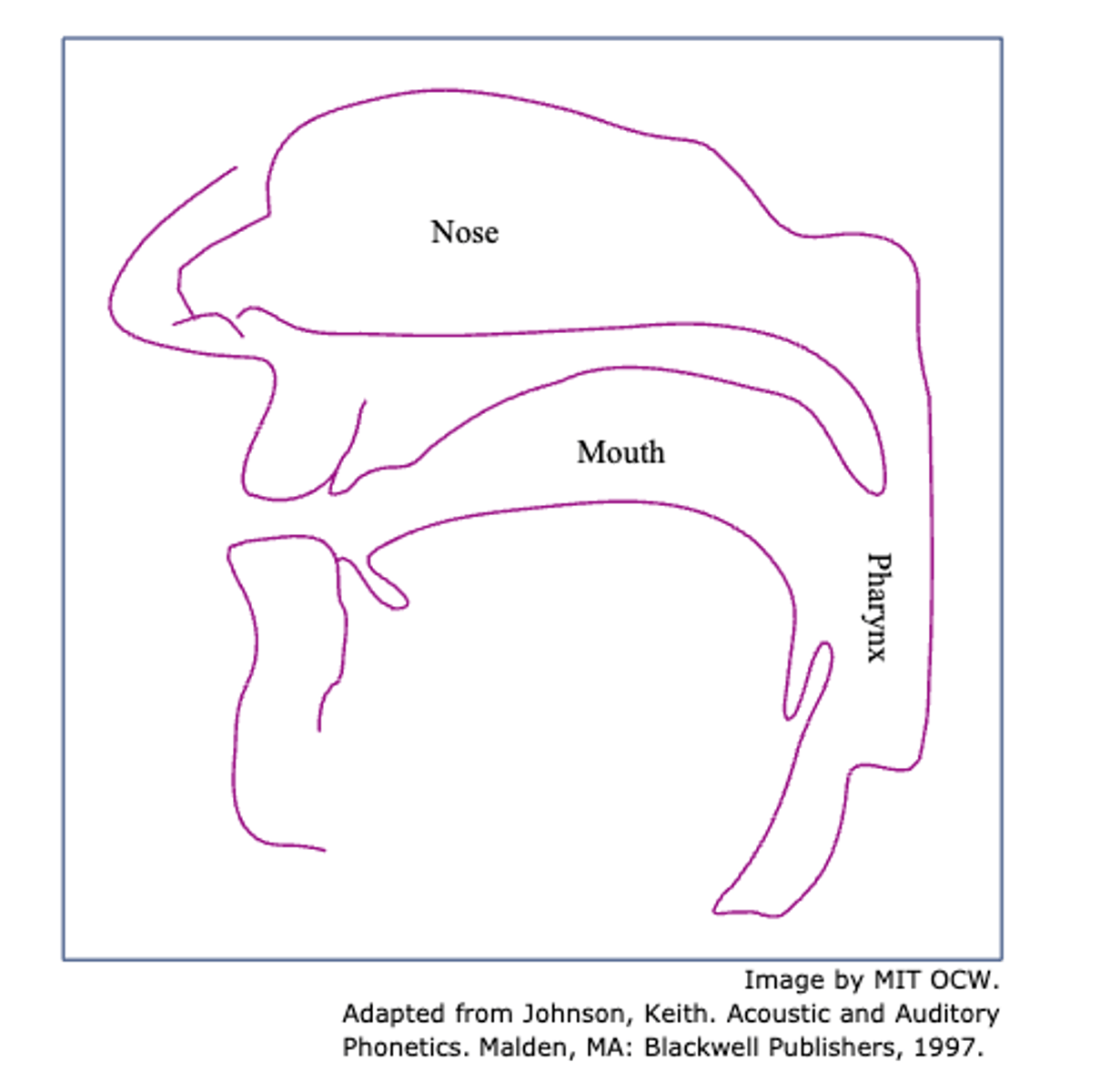
lowered which creates an open pathway from pharynx to nasal passages which allows air to flow from lungs out through nostrils
nasal consonants: mouth cavity is
closed off by a complete constriction in the vocal tract either at the lips, alveolar ridge, velum, etc.
nasalized vowels
both mouth and nasal cavities are open to the outside
uvular nasal [ɴ] can be modeled as a
single tube closed at the glottis and open at the nostrils
with the uvular nasal [ɴ] the oral cavity is
blocked off by closure produced by the uvula and tongue body
resonances for nasals have
lower frequencies and are closer together (about 800 Hz apart) than for a neutral vowel like schwa
nasal resonances are
weaker- peaks are lower in amplitude due to damping
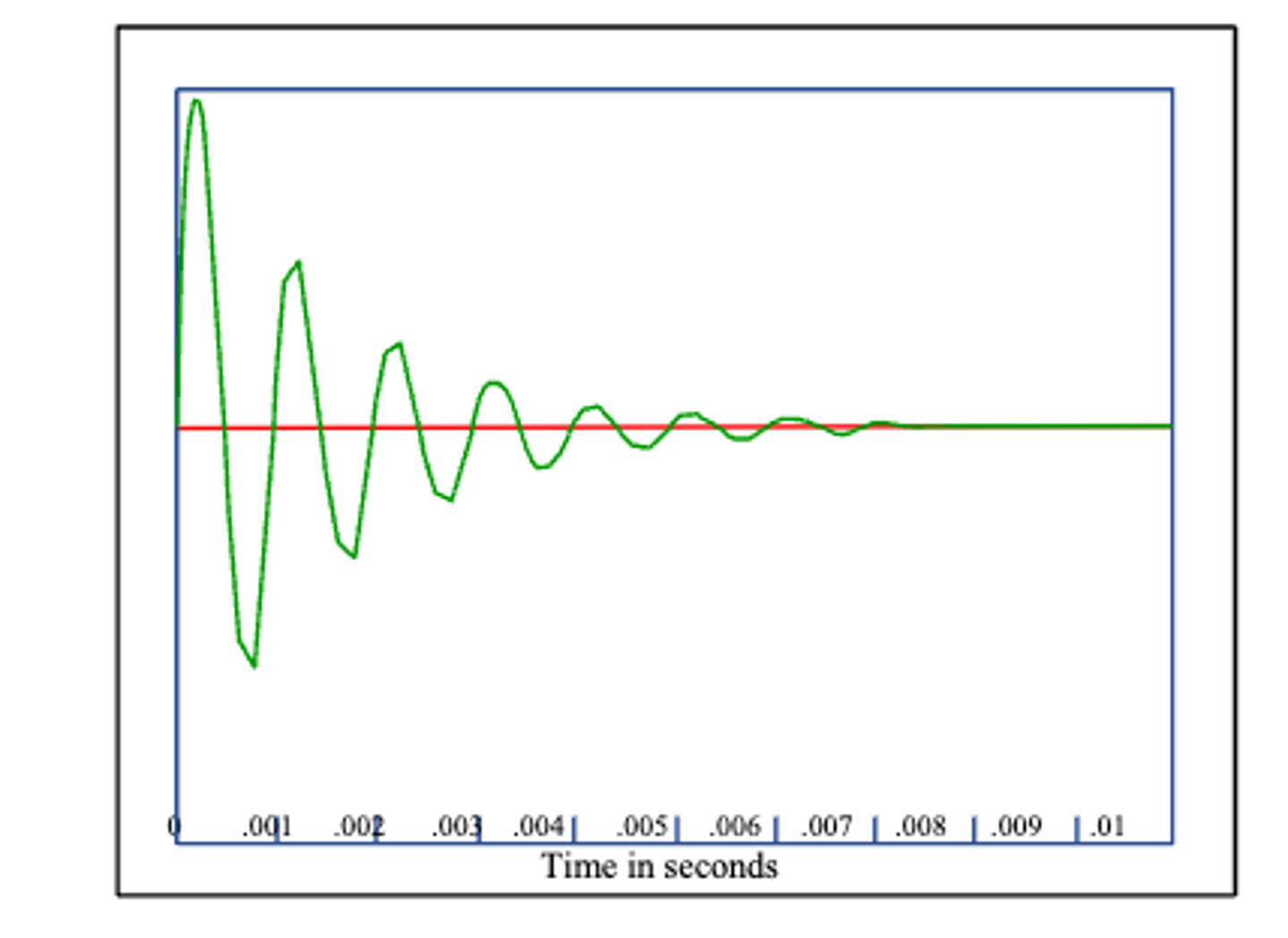
when an input of energy sets a body vibrating the resulting vibrations
die out as energy is dissipated through friction, transmission of energy to surrounding air, etc.- wave is damped
damped wave
all speech sounds are
damped somewhat
standing waves in the vocal tract are damped due to
friction, radiation losses to the outside air, absorption of energy by the elastic vocal tract walls, etc.
the walls of the vocal tract are
soft and absorb some of the sound energy produced by the glottis
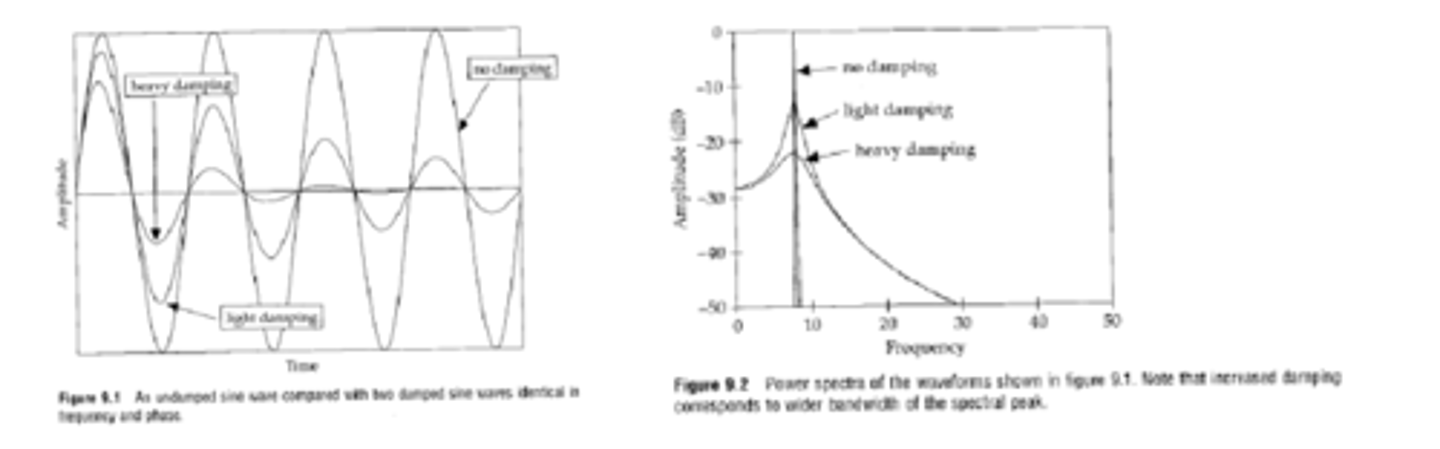
greater surface area results in
more damping and broader formant bandwidths
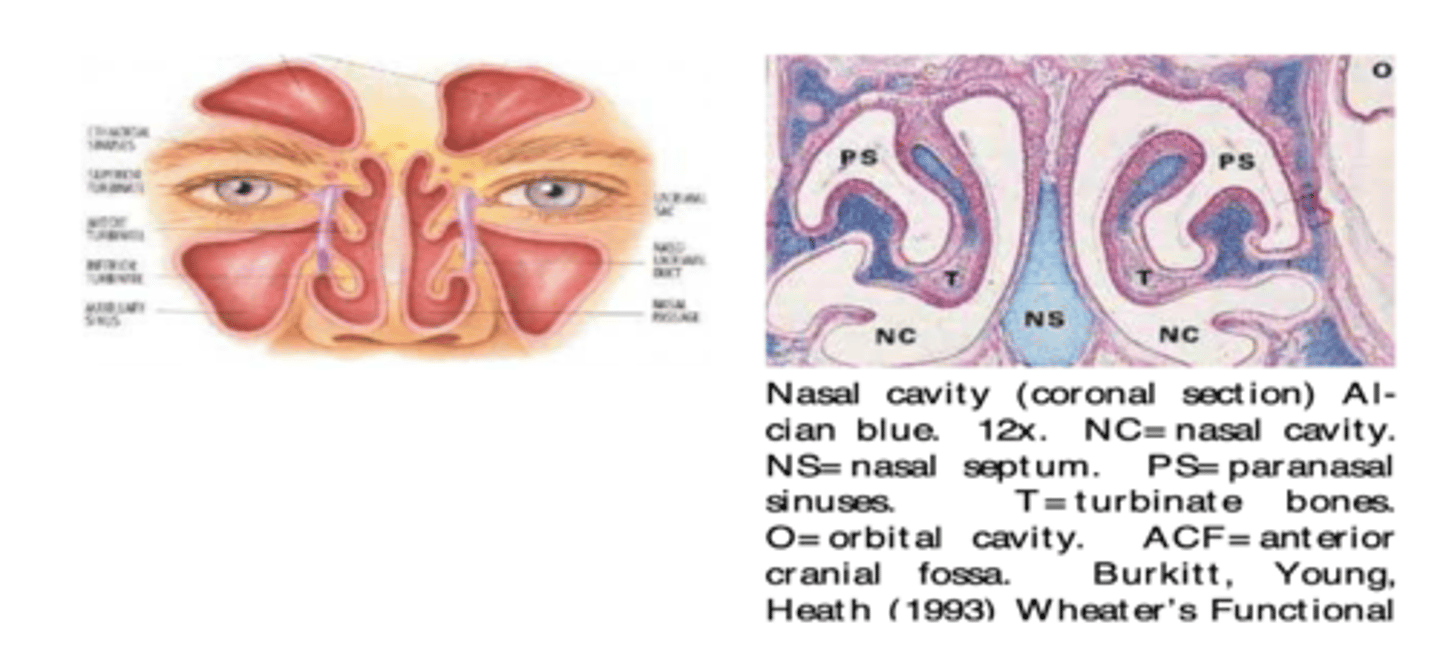
nasals have more damping because
the pharynx, nasal cavity, and oral cavity are all involved, nasal passages have small side cavities which further increases surface area and hence damping
illustrations of nasal cavities
damping
increases spectral bandwidth- widens the span of the peaks
since energy distribution is over a wider range of frequency
spectral peaks are also lower in amplitude
nasal consonants made with an
oral constriction further forward than the uvula add a side cavity- the oral cavity onto the pharyngeal nasal tube
the further front the constriction
the longer the side cavity
the side cavity is a
tube open at one end
the side cavity doesn't open to
the atmosphere at the mouth end so the resonating frequency components are not transmitted out of the vocal tract. Instead they're absorbed by the side cavity
frequencies that are absorbed in the side cavity are called
anti-resonances and anti-formants because they are cancelled out, so they show up in the spectrum as valleys rather than peaks
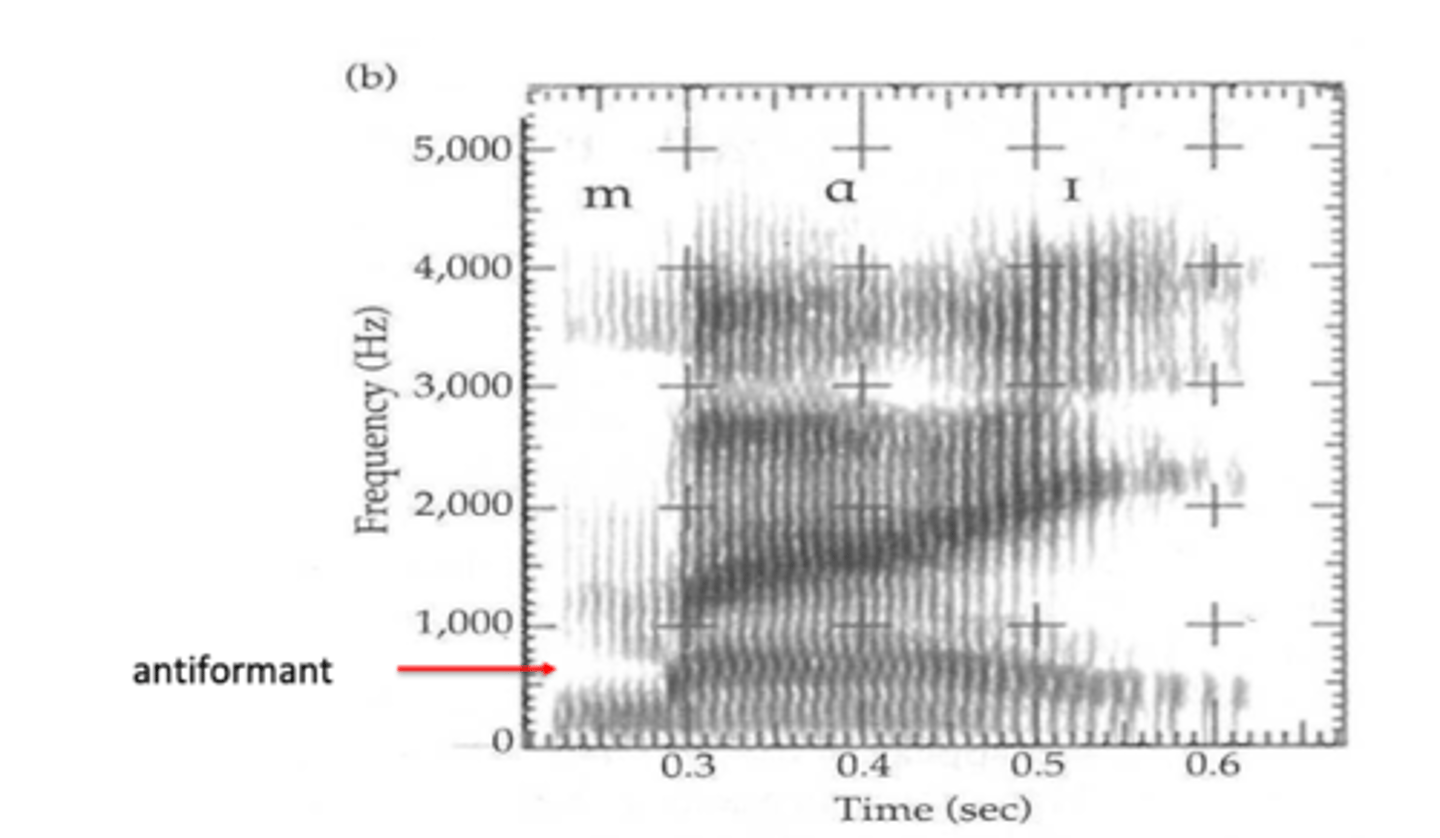
the further forward the place of articulation
the lower the anti-formants are
nasal murmurs
don't provide strong cues to place of articulation on their own
listeners can only distinguish between the nasal murmurs in [m] and [n]
72% of the time
transitions provide
the best cue for place of articulation especially transition from nasal to following vowel
95% of nasals are identified correctly when presented with
first 10 ms of the following vowel
nasalized vowels involve
a complex vocal tract configuration
the coupled nasal cavity contributed
both formants and anti-formants which combine with the formants of the oral tract
the net acoustic effect of velum lowering depends on
the formant frequencies in the corresponding oral vowels and as a result it is difficult to give a general acoustic characterization of nasalization on vowels
nasal vowels are
less distinct from each other than oral vowels both in terms of confusability and similarity judgements
the greater confusability is reflected in the fact that
in languages with contrastive vowel nasalization, the nasal vowel inventory is always the same or smaller than the oral vowel inventory, never larger
-pin-pen and him-hem are
homophonous
pit-pet
contrast
vowels are substantially
nasalized before nasals in English
nasalization
reduces the distinctiveness of F1 contrasts
oral [ɪ]-[ ɛ] are
sufficiently distinct
addition of the lowest nasal formant in combination with broad bandwidth F1 can create
a broad, low frequency prominence- can make height of vowels harder to distinguish
due to increasing formants and anti-formants and acoustic consequences of nasal vowels
they are much more difficult to model and predict than for oral vowels
what's the source of sound for laterals
voicing
how is the sound for laterals generated at the source filtered by the vocal tract?
with not only tubes that are acoustically coupled with one another end to end, but also with tubes that branch
lateral articulation
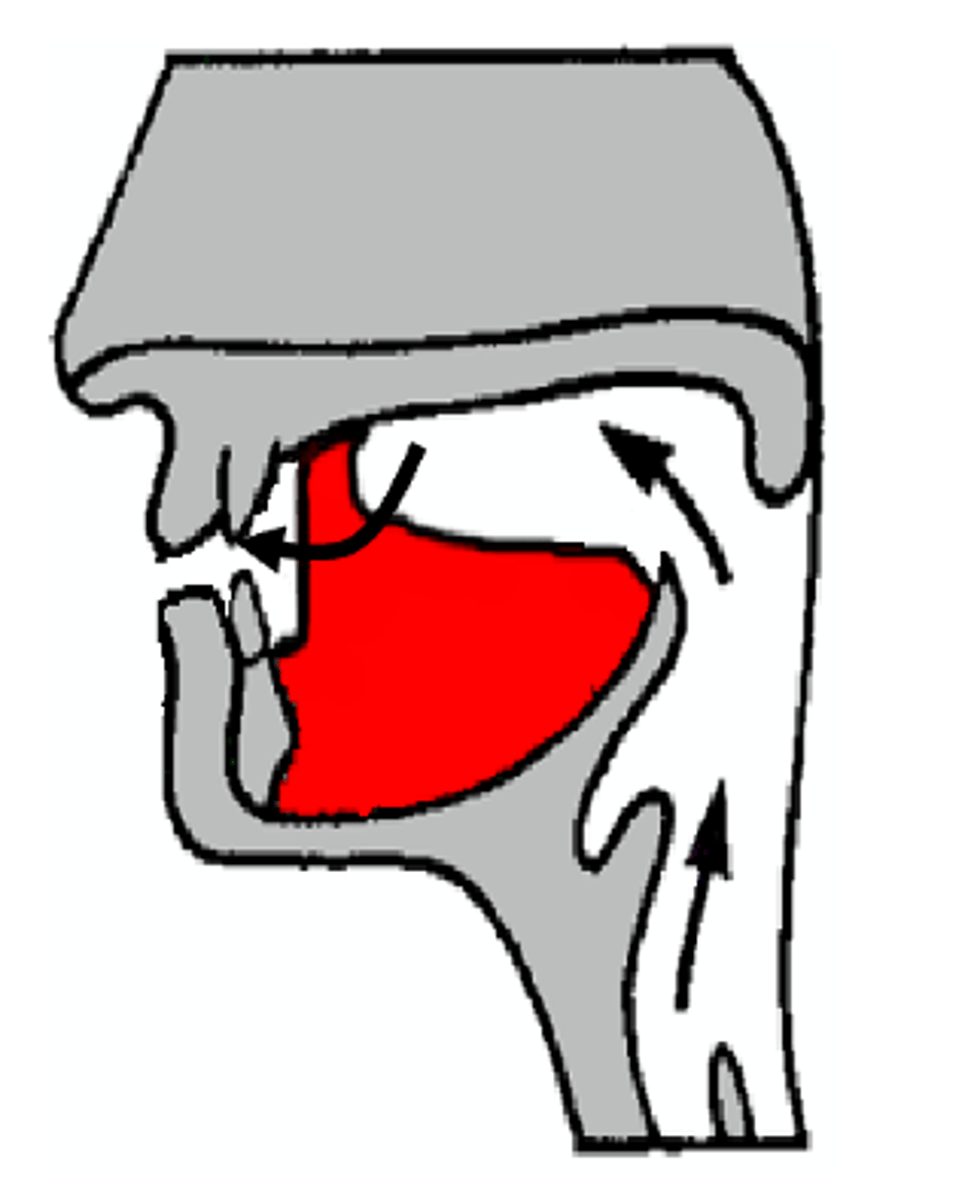
laterals look
somewhat like nasals in a spectrogram too
like nasals the laterals formants are
broader and less intense than vowels
unlike nasals the laterals formants are
further apart (more vowel-like)
laterals are usually
more intense than nasals
laterals have less
surface area=less damping
the break between vowels are laterals is
less clear
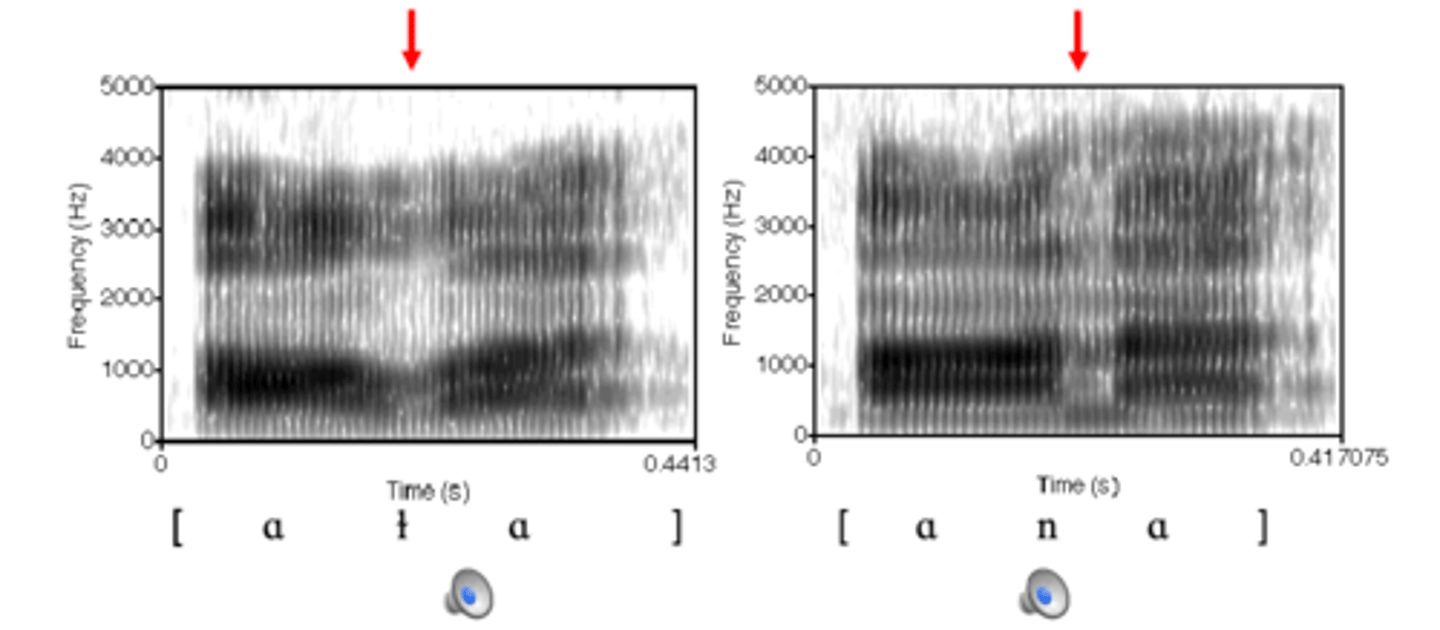
laterals like nasals have
a "side" cavity that introduces an anti-formant in the output spectrum
the "side" cavity is
the pocket of air on top of the tongue
the main cavity
curves around one or both sides of the tongue
main cavity
tube closed at glottis, open at mouth
"side" cavity
also closed at one end (place of constriction), open at the other (pharynx)
rhotics are
much more complex
there are many different kinds of
rhotics and there is no clear way of unifying them phonetically which makes it incredibly difficult to model
trills, taps, bunched/retroflex [ɹ] show
very different aocustic/articulatory characteristics
Lindblom (1985)'s model of rhotic parameter relations
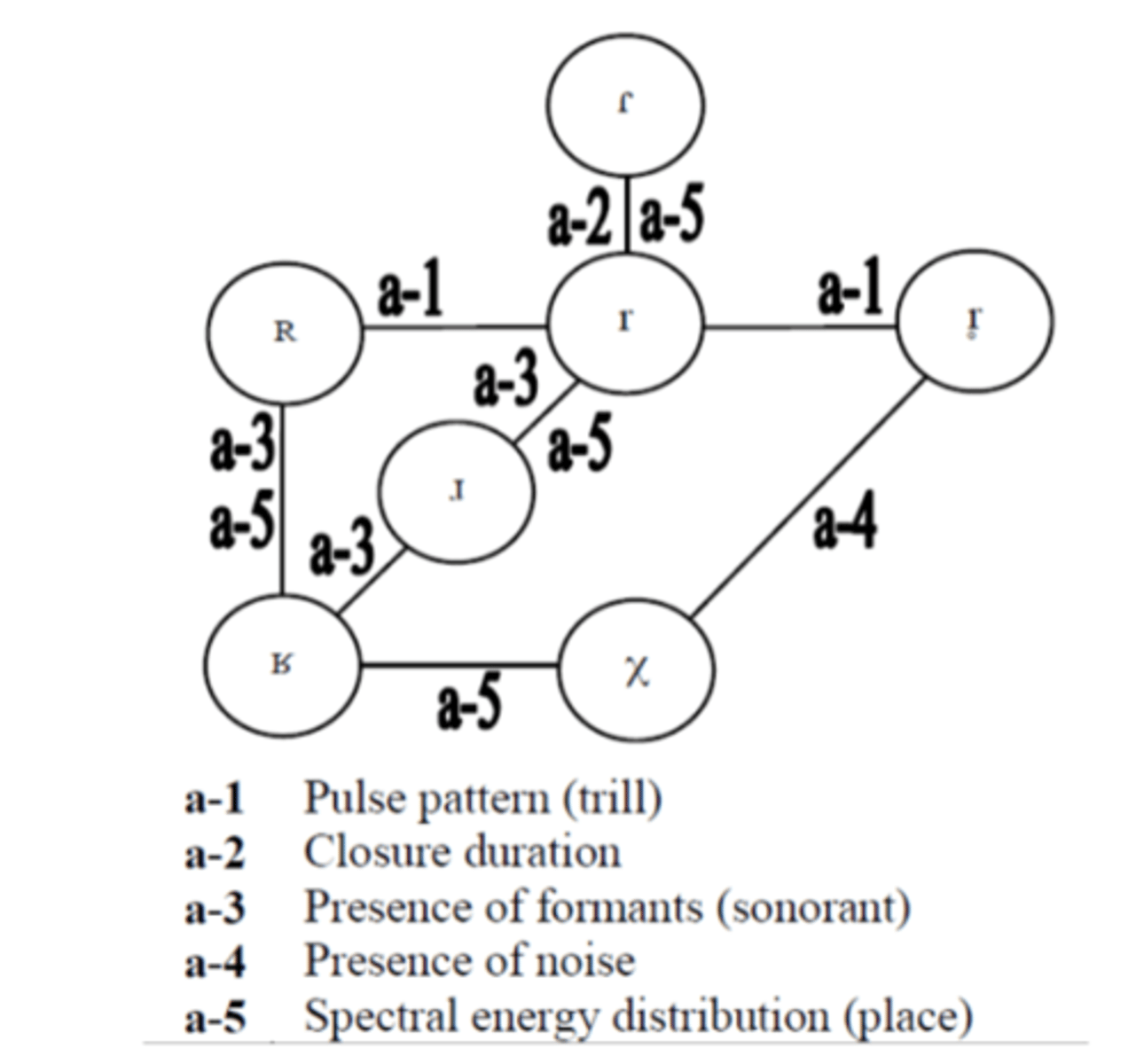
[ɹ] typically combines three different approximant constrictions
alveolar/post-alveolar (retroflex), lip rounding (labialization), and pharyngeal constriction (pharyngealization)
english speakers make the [ɹ] constriction in two different ways
tongue bunching and tongue curling (retroflex)
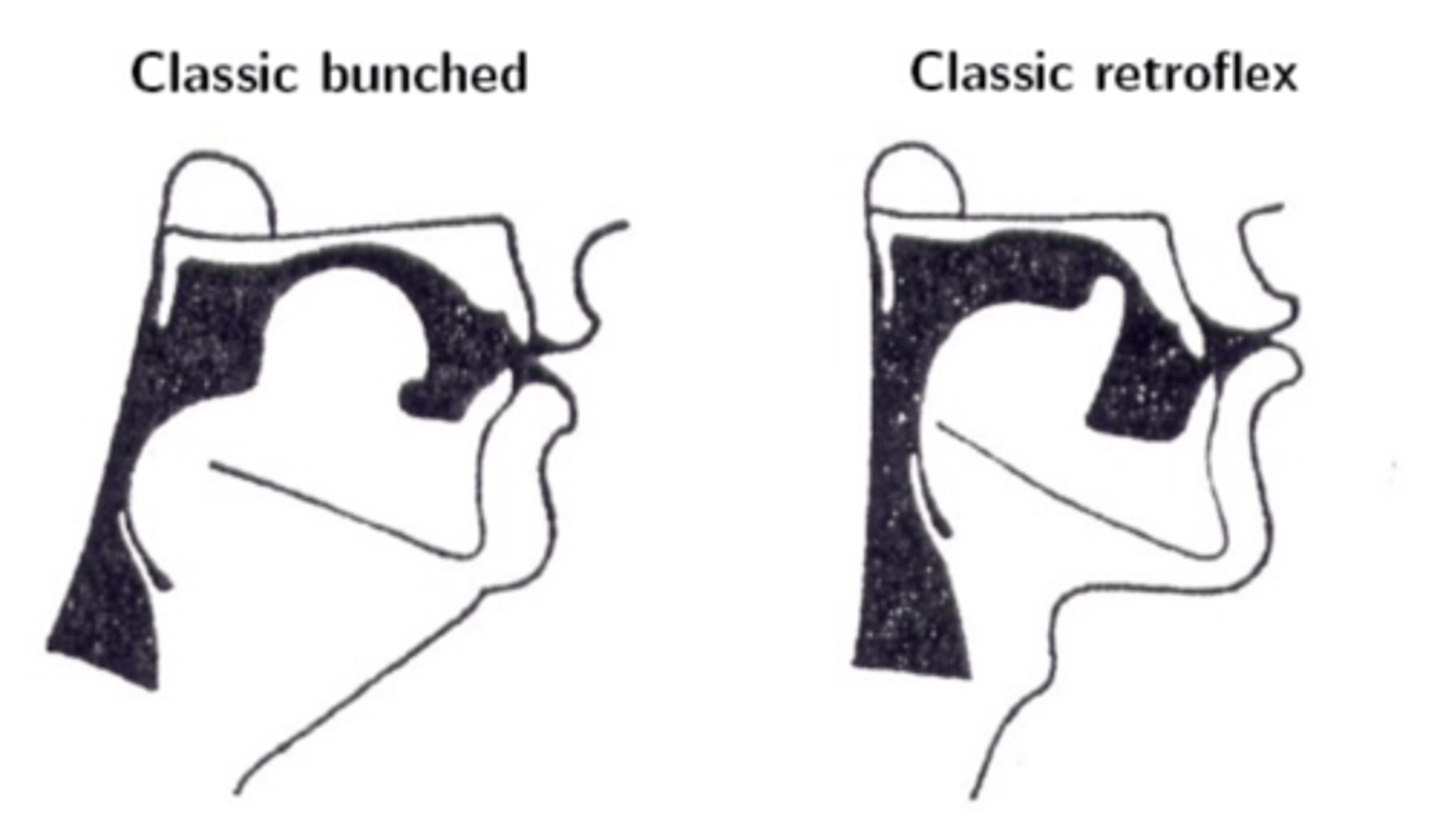
how are [l] and [ɹ] primarily distinguished?
F3
[r] has a
much lower F3 than [l]
![<p>much lower F3 than [l]</p>](https://knowt-user-attachments.s3.amazonaws.com/2e421b04-194d-422a-84cd-b5af9ba1d48e.png)
[l] usually has a
lower F2 in English
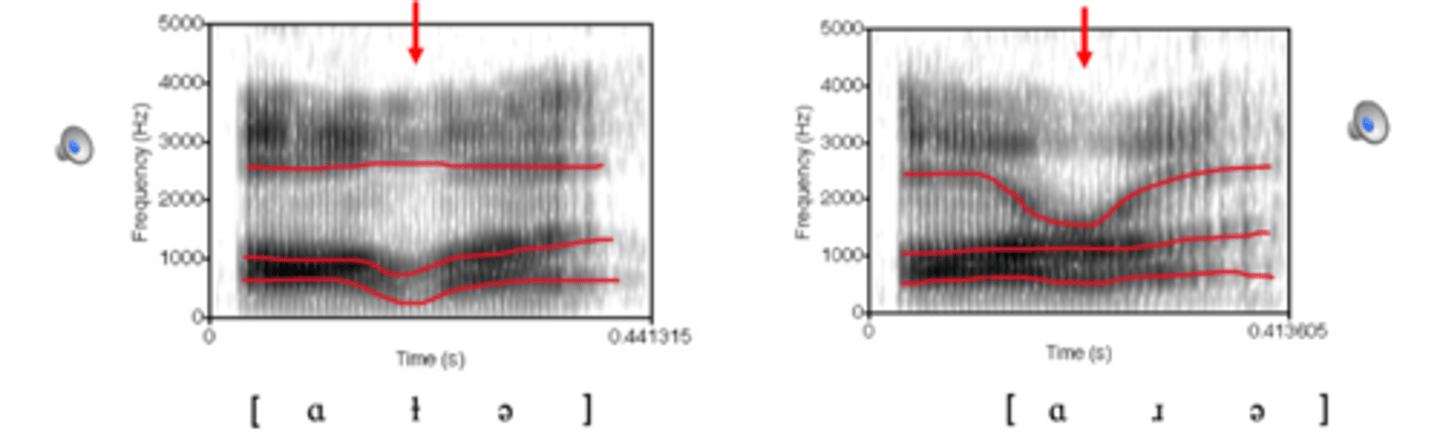
nasals and laterals are
less intense than vowels
nasals and laterals can be modeled as
a tube model with a branching side cavity
we can model both main tube and side tube as
tubes open at one end producing formants and antiformants
resonant frequencies of the side cavity become
antiformants and are viewed as valleys, instead of peaks in the spectrum
the further forward the constriction in the oral cavity
the lower the antiformants
nasalized vowels are much more
complex due to both nasal and oral cavities being open to outside air, and coupling of formants/antiformants
rhotics are difficult to model because
of their varied articulations
important characteristic of English [ɹ] is
lowered F3 in part due to lip rounding
many things affect the suprasegmental properties of segments such as F0, duration, intensity/amplitude/loudness) including
prosody, position in word or utterance, local context, and intrinsic properties of vowels or consonants
interaction between stress and vowels is
highly language specific
languages with little to no vowel reduction
Spanish and French
languages with phonetic reduction
English
languages with neutralization
Russian
hyperarticulation localized to
stressed syllables- greater range/velocity of articulatory movements
articulatory consequences of hyperarticulation
greater range of movement, greater movement of velocity, greater duration of movement, resistance to coarticulation
absence of consistent phonetic correlates of stress also means
stress is a perceptual phenomenon
factors that influence duration
intrinsic properties of gestures, lengths contrasts, local context, prosodic structure
universally lower vowels are
longer than higher vowels
universally labial stops are
longer than coronals or dorsals
language specific- fricatives are
usually longer than stops
geminate consonants are
roughly twice the duration of single consonants
languages that have geminate consonants are
Italian, Japanese, Finnish, and Arabic
long vowels usually differ from
short ones in quality as well in Hungarian
universally vowels are shortest before
labials
almost universally vowels are shorter before
voiceless consonants than voiced
vowels are shorter before
stops than before fricatives
the greater the number of syllables in a word
the shorter each vowel is
the last vowel in a word is
the longest
vowels in stressed syllable are
longer than in unstressed syllables in many languages
vowels and consonants are longer
at the end of phrase than within phrase
gestures are slowed down near
phrase boundaries
F0 is often higher for
vowels in stressed syllabes
higher F0 in segments at
beginning of phrase
if a language distinguishes tone
massively effects F0 of segments
high vowels>
low vowels
voiceless stops and fricatives >
voiced stops and fricatives