H5 - Batch Processing
1/27
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
28 Terms
Data processing system types (h4-h6)
Services (online systems)
Service waits for request or instruction from a client to arrive
When request is received service tries to handle it as quickly as possible and sends response back
Response time usually primary measure of performance of a service
Availability often also important
Batch processing systems (offline systems)
Take a large amount of input data, run a job to process it and produce output data
Jobs often take a while (minutes/hours/days)
Often scheduled to run periodically
Primary performance measure is usually throughput
Time it takes to crunch through an input dataset of a certain size
Stream processing systems (near-real-time systems)
Between online and offline/batch processing
Stream processor consumes inputs and produces outputs (rather than responding to events)
A stream job however operates on events shortly after they happen versus batch job operates on fixed set of input data
Allows stream processing systems to have lower latency than equivalent batch systems
Compute intensive vs data intensive
figuur(en)
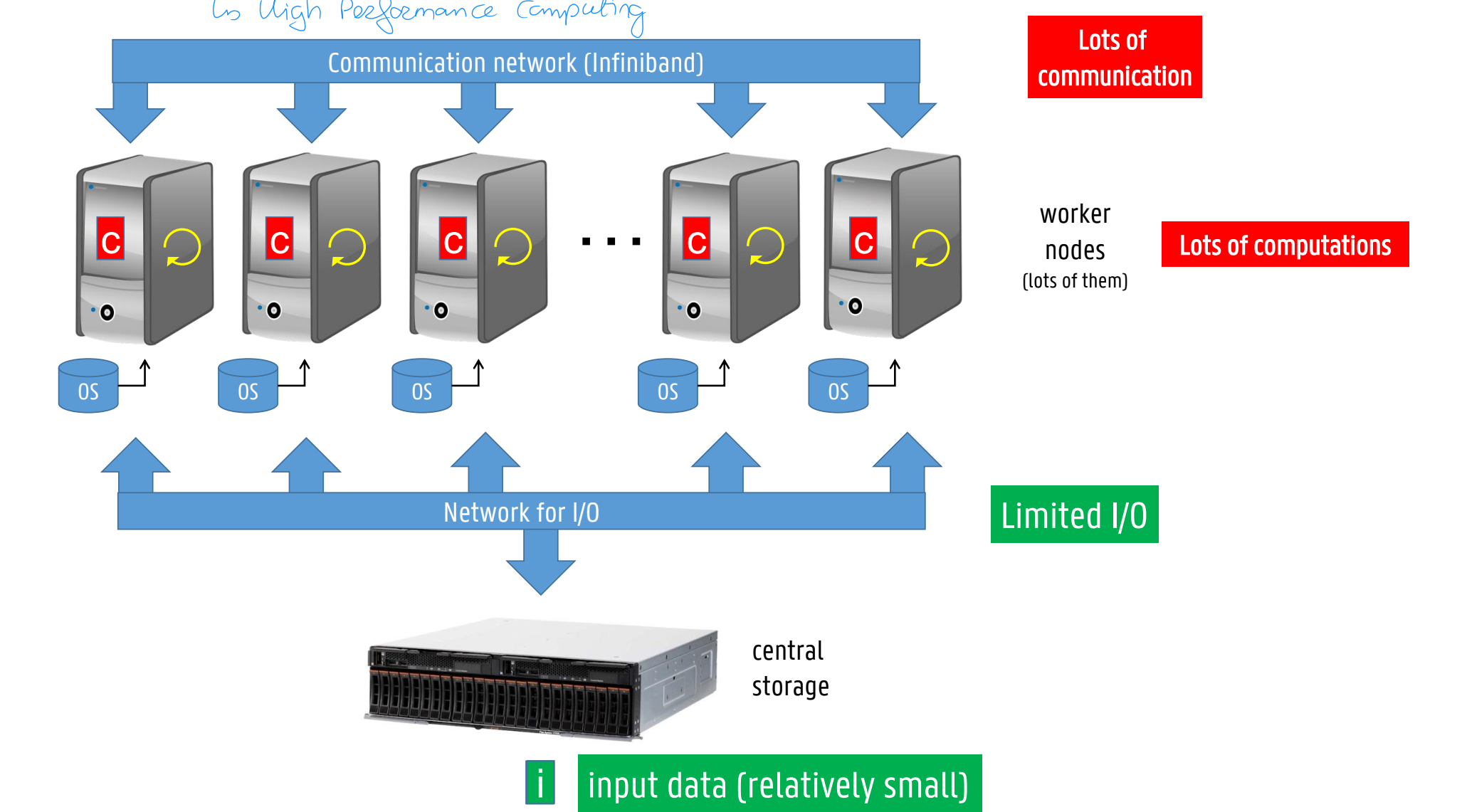
Compute-intensive tasks (traditional HPC = high performance computing)
Input data is relatively small
Data is usually kept in-memory during job execution
Many computations need to be performed per data-element
Runtime is limited by compute or interconnection network capacity
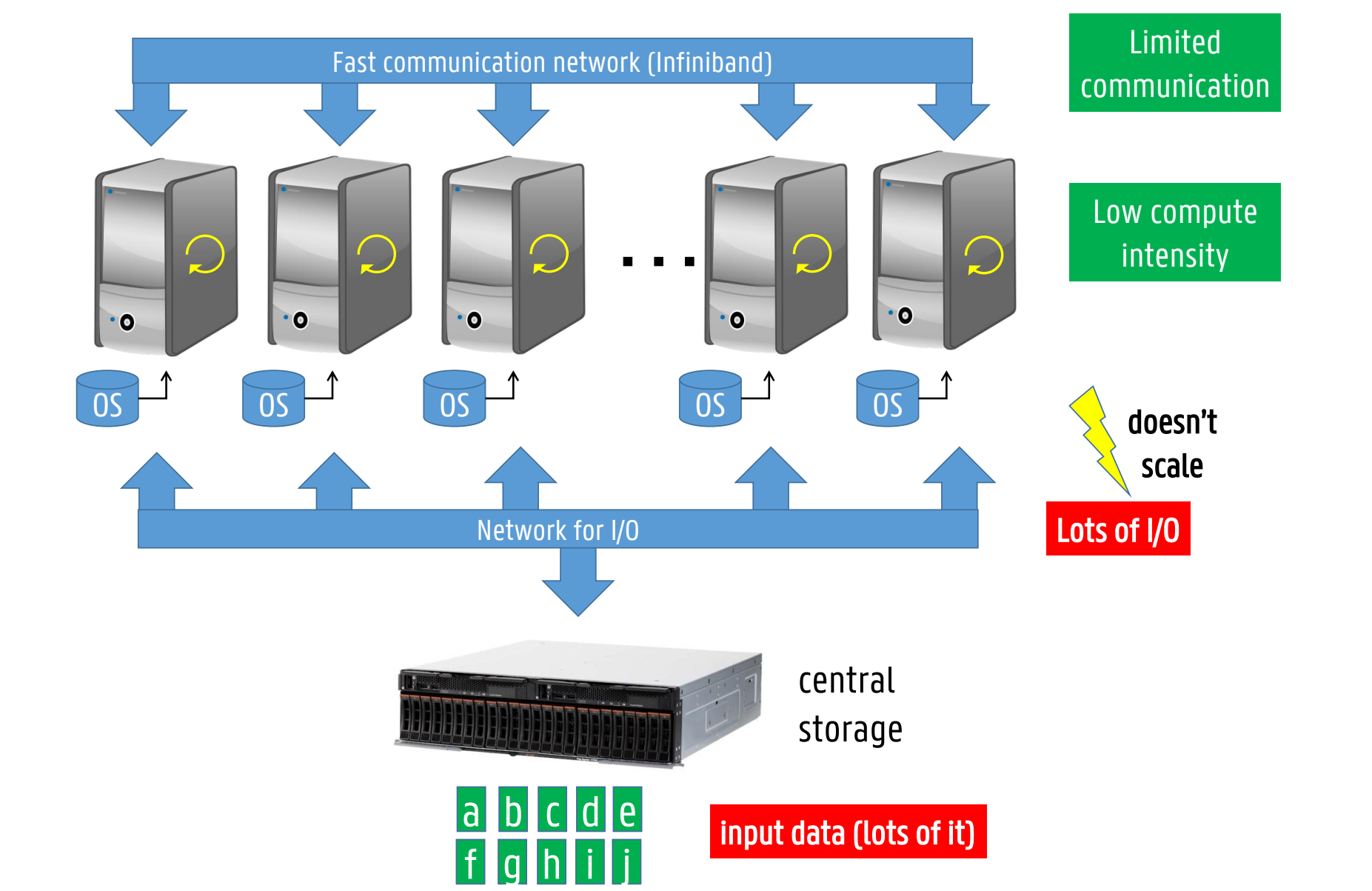
Data-intensive tasks (“big data”)
Input data is (very) large
Data is usually not kept in-memory during job execution
Few computations need to be performed per data-element
Runtime is limited by data transfer
Apache hadoop
algemeen
Apache Hadoop
Open-source framework written in Java
Distributed storage and processing of very large data sets (Big Data)
Scales from single server to thousands of nodes
Framework consists of a number of modules
Hadoop Common – shared libraries and utilities
Hadoop Distributed File System (HDFS) - distributed file system for storage
Hadoop YARN – resource manager
Hadoop MapReduce – programming model
assume failures are common
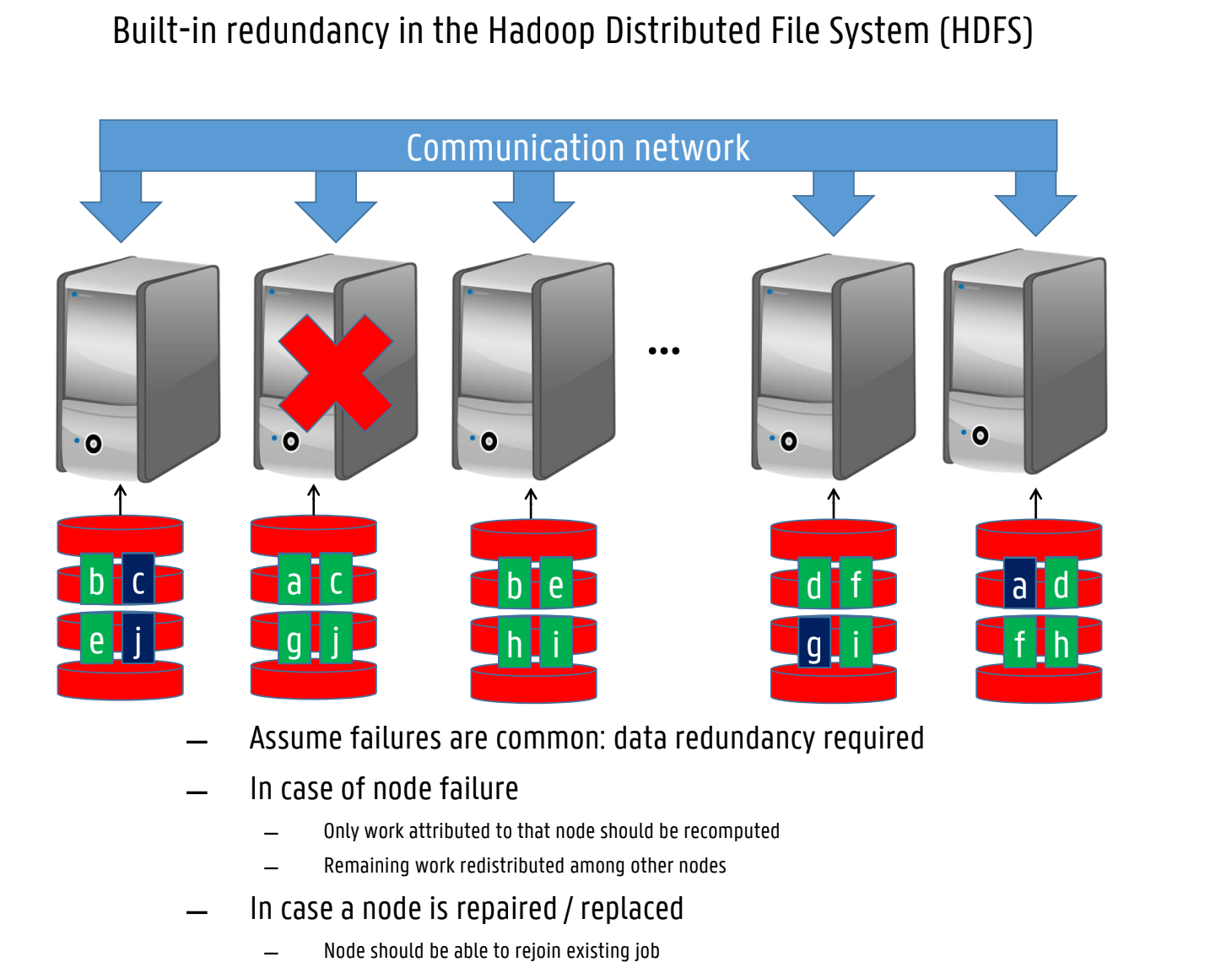
main ideas behind hadoop (6)
ezelsbrug
DD SO PFL HD
MAIN IDEAS BEHIND HADOOP
Data-driven philosophy
Growing evidence that having more data and simple models outperforms complex features/algorithms with less data
Scale out instead of up
Prefer a larger number of low-end workstations over a smaller number of high-end workstations (for big-data problems)
Buying low-end workstations (“desktop-like machines”) is 4-12x as cost efficient as buying high-end workstations (“high-memory machines with a high number of CPUs / cores”)
Idea is also valid for network interconnects
E.g. Infiniband versus “commodity” Gigabit Ethernet
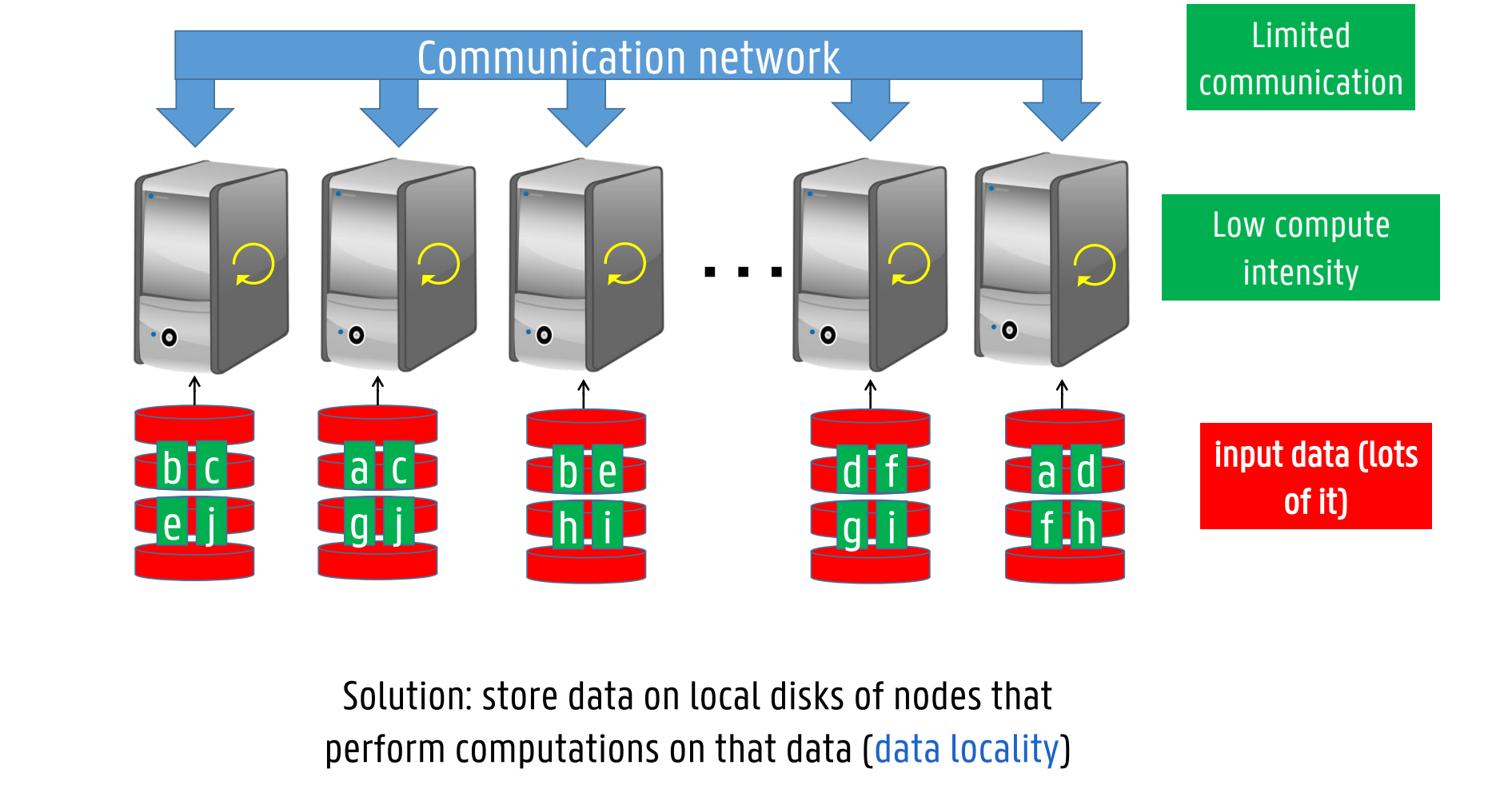
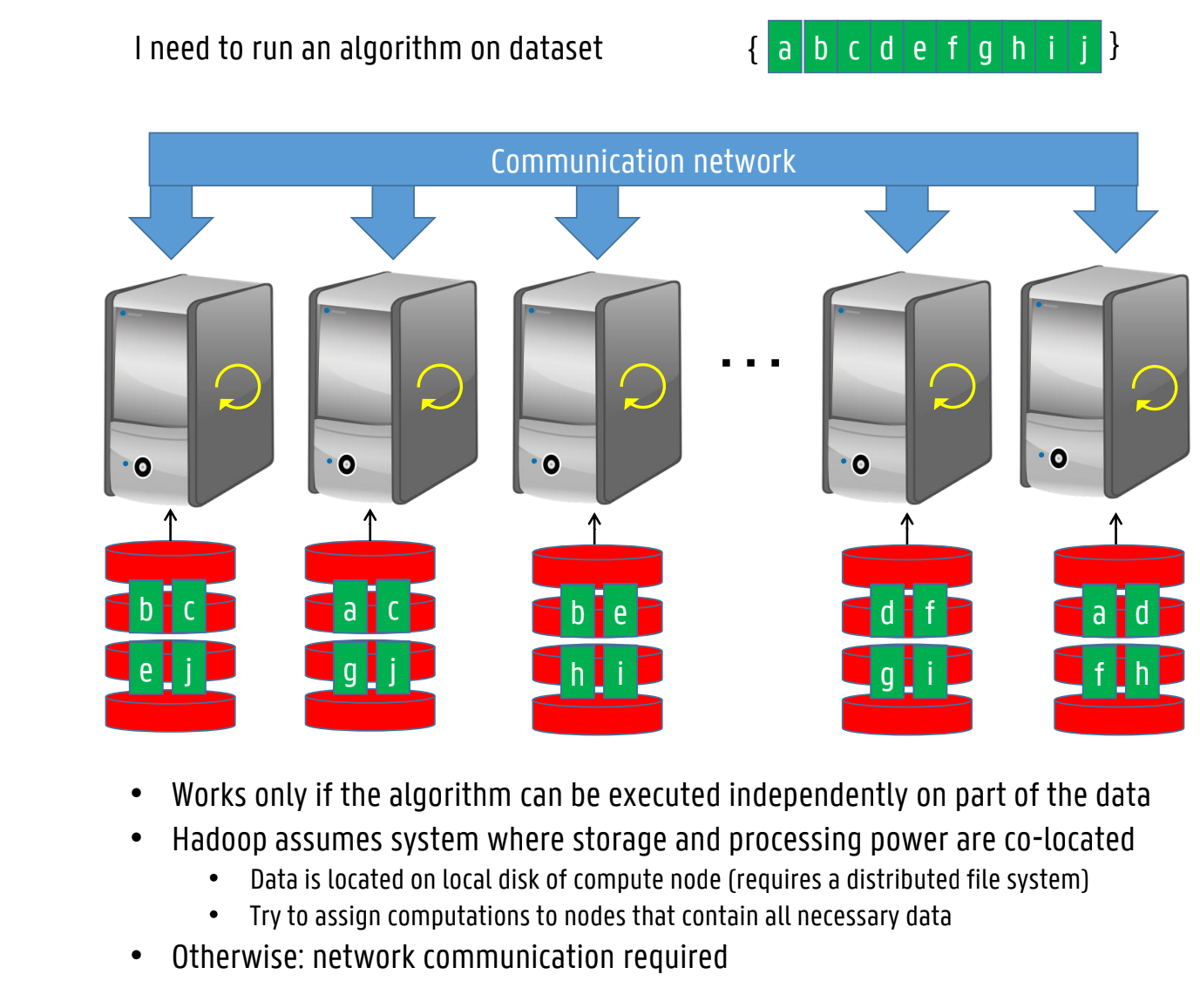
Move processing to where the data resides
assume failures are common
acces data lineary - avoid random access (veel sneller)
Hide system level details from dev
Parallel programming is difficult
Code runs in unpredictable order
Race conditions, deadlocks, etc.
Main idea is to be able to program the “what” (i.e. functionality of the code) and hide the “how” (i.e. low-level details)

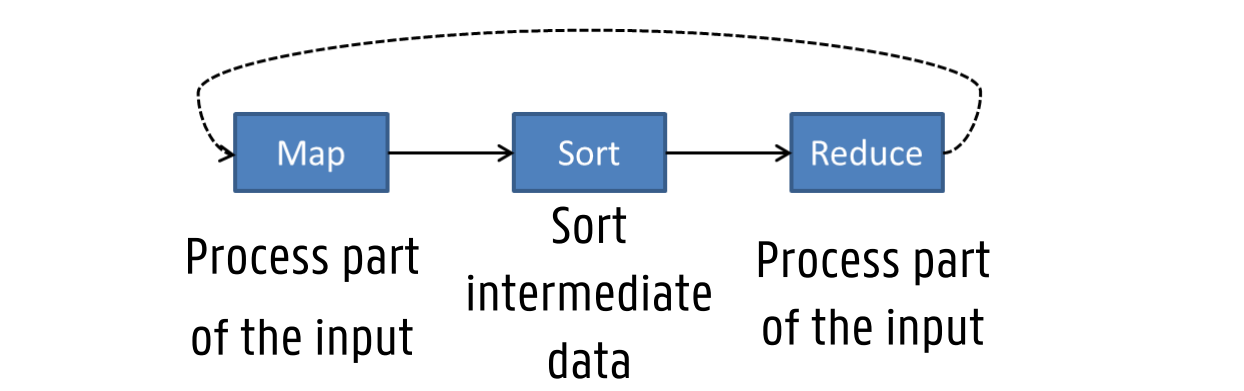
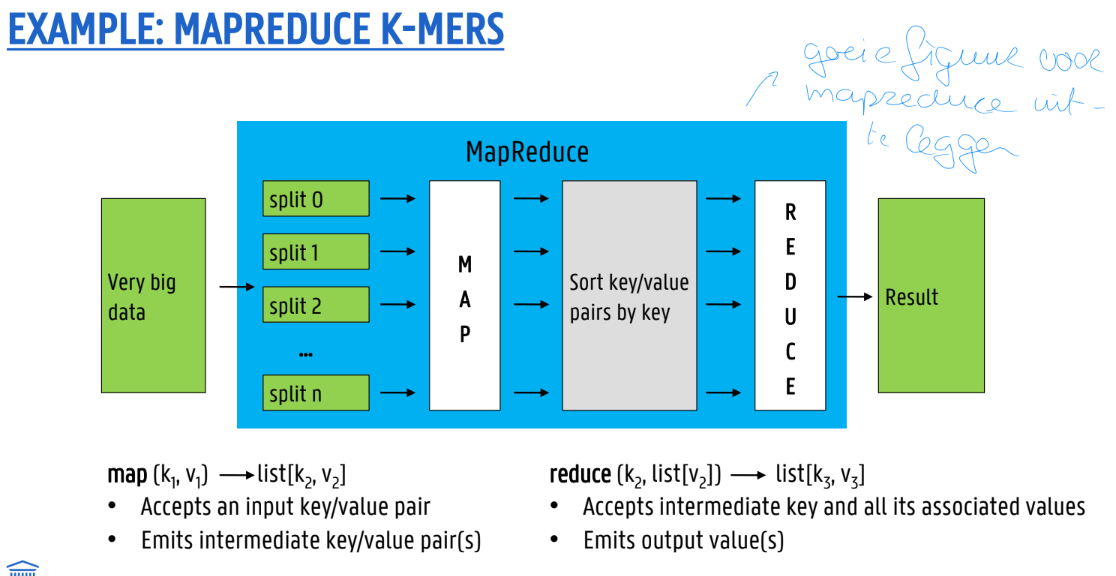
Mapreduce basics
→ figuur
MapReduce programming model (algorithm published in 2004)
Divide & conquer strategy
Divide: partition dataset into smaller, independent chunks to be processed in parallel ( = “map”)
Conquer: combine, merge or otherwise aggregate the results from the previous step (= “reduce”)
Mappers and reducers
Map task processes a subset of input <key, value> pairs and puts out intermediate pairs
Reduce task processes a subset of the intermediate pairs
Map function operates on a single input pair and outputs a list of intermediate pairs
Reduce function operates on a single key and all of its values and outputs a list of resulting <key, value> pairs
Sorts intermediate keys between map and reduce phase
Input files not modified, output files created sequentially
File reads and writes on distributed filesystem
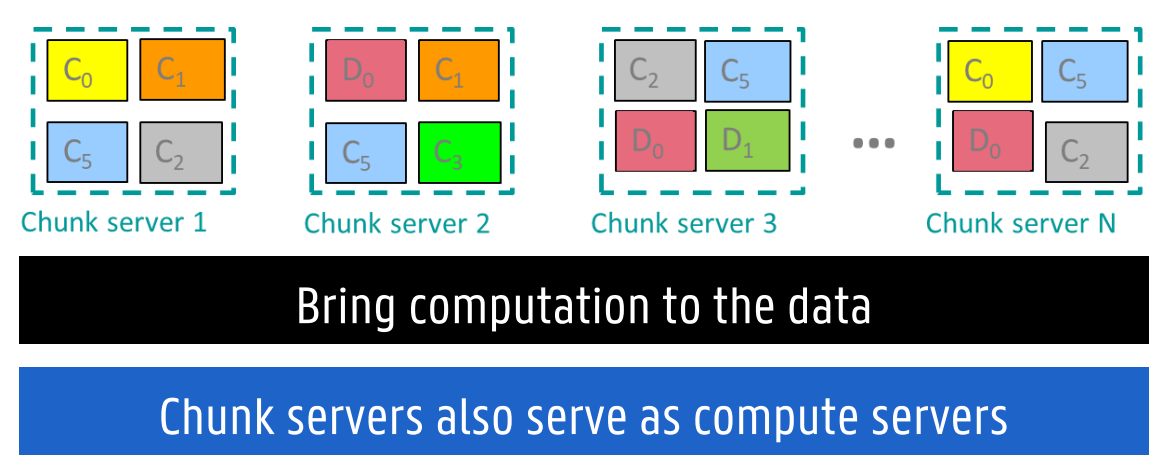
Mapreduce: Distributed file system: HDFS
wat
Hadoop’s implementation: Hadoop Distributed File System, open-source implementation of Google File System (GFS)
HDFS is based on shared-nothing principle: commodity hardware connected by conventional datacentre network
Daemon process running on each machine, exposing a network service that allows other nodes to access files stored on that machine
Central server (NameNode) keeps track of which file blocks are stored on which machine
Conceptually creates one big filesystem that can use space on disks of all machines running daemons
To handle machine and disk failures, file blocks are replicated on multiple machines
Some HDFS deployments scale to tens of thousands of machines, combining petabytes of storage
Mapreduce: Distributed file system: HDFS
werking
figuur
Typical usage pattern
Huge files (100s of GB to TBs)
Data rarely updated in place
Reads and appends are common
Chunk servers
File is split into chunks
Typically, each chunk is 16-64MB
Each chunk replicated (usually 2x or 3x)
Try to keep replicas in different racks
Master node
A.k.a. NameNode in Hadoop’s HDFS
Stores metadata about where files are stored
May be replicated
Client library for file access
Talks to master to find chunk servers
Connects directly to chunk servers to access data
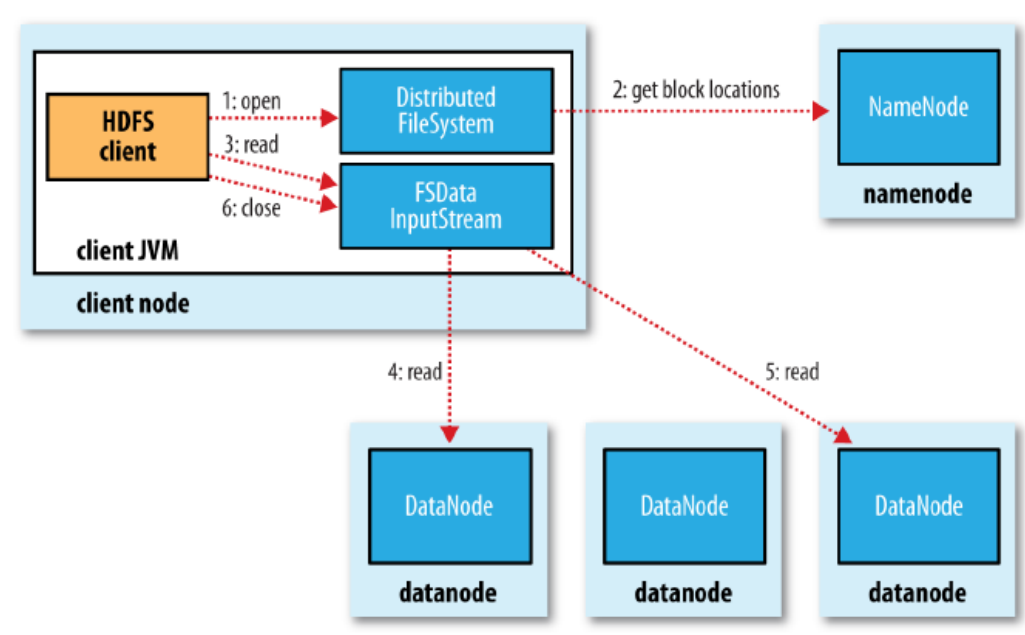
Mapreduce: Distributed file system: HDFS (EX)
client reading data
figuur!
Client opens file
NameNode knows location / addresses of blocks in the file
Datanodes sorted according to proximity to client
Client receives an inputstream object which abstracts reading data from HDFS datanodes
Mapreduce: Distributed file system: HDFS (EX)
client writing data
figuur!
Client creates file by calling create
NameNode makes a record of new file
Client receives an outputstream object abstracting block placement
Data is automatically replicated (default replication level is three)

Mapreduce: Distributed file system HDFS (EX)
Data flow
figuur!
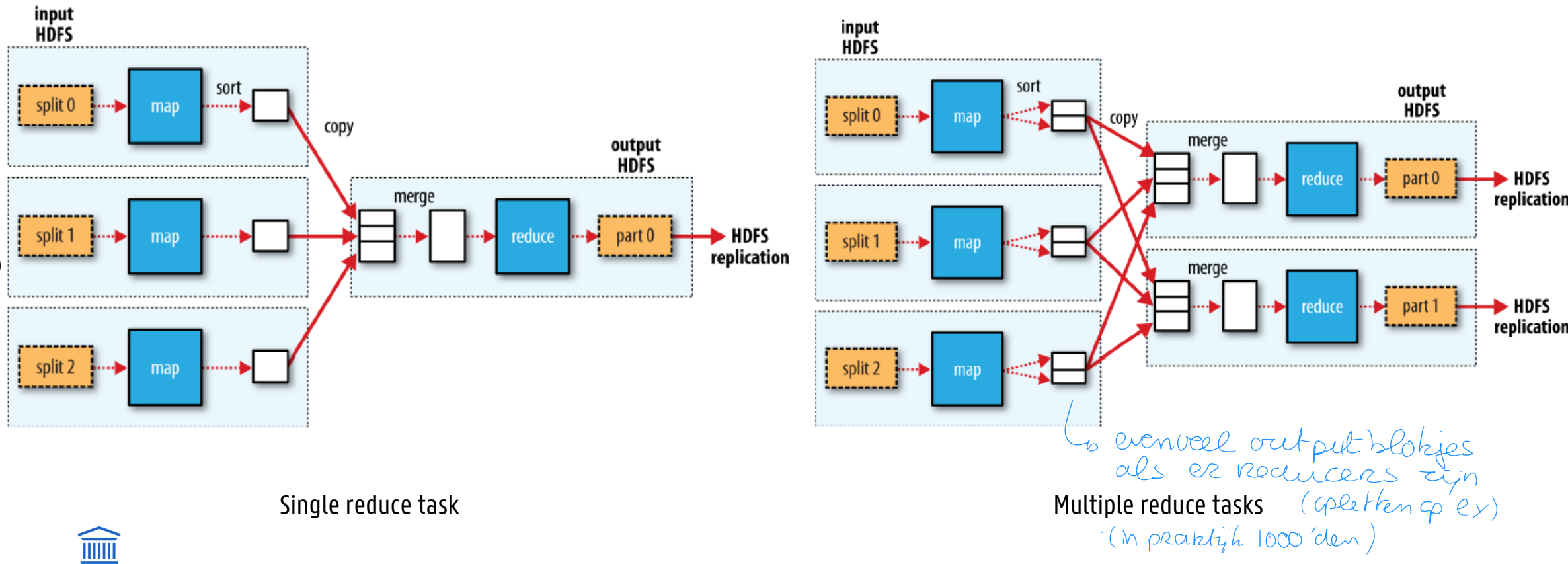
Mapreduce
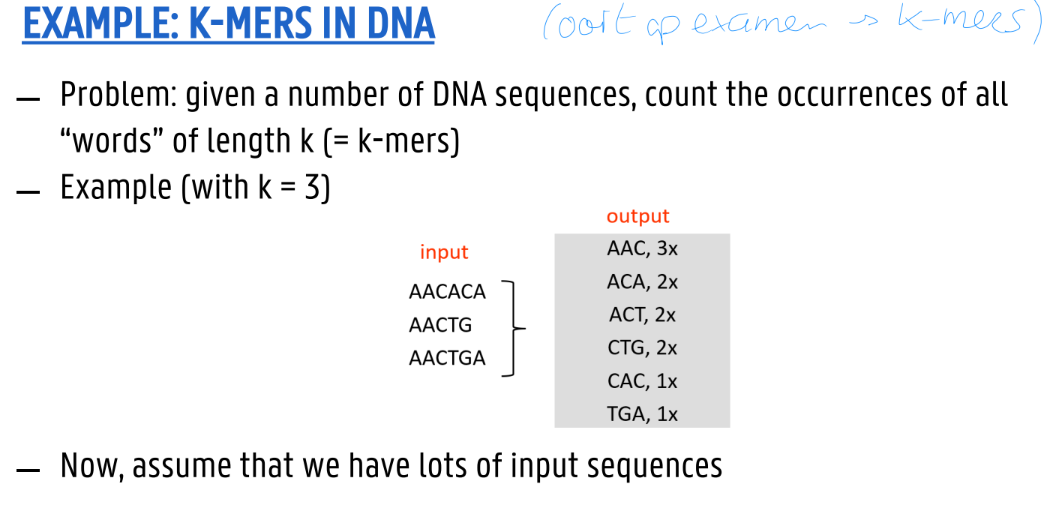
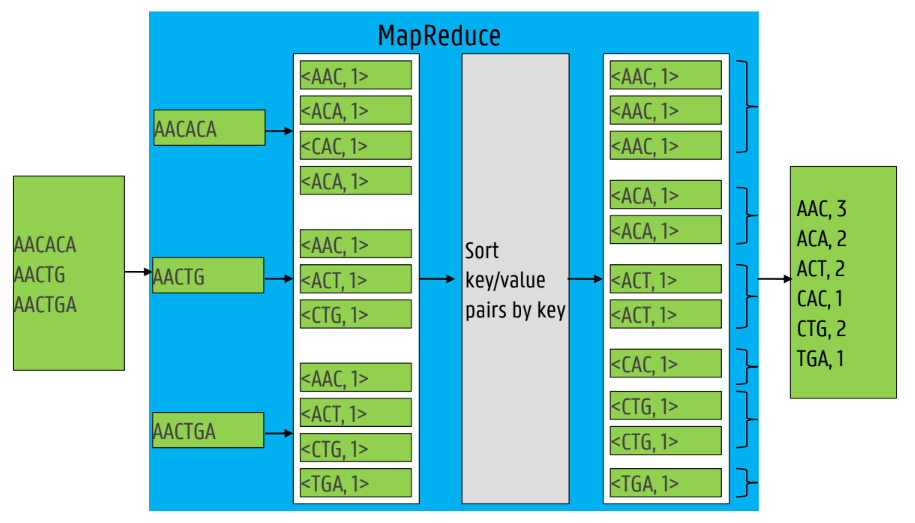
fixed steps + examples
figuur!
Five MapReduce steps
Sequentially read (a lot of) data
Map: extract key, values you care about
Group by key: sort and shuffle
Reduce: aggregate, summarize, filter or transform
Write result
MapReduce environment takes care of
Partitioning the input data
Scheduling the program’s execution across a set of machines
Performing the shuffle / group-by-key step
Handling machine failures
Managing required inter-machine communication
Mapreduce
workflow
coordination: master (figuur)
Workflow
Previous example showed need for two MapReduce passes
Very common for MapReduce jobs to be chained together into workflows so output of job becomes input to next job
Coordination: master
Master node takes care of coordination
Task status: idle, in-progress, completed
Idle tasks get scheduled as workers become available
When map task completes, it sends master: location and sizes of its R intermediate files, one for each reducer
Master pushes info to reducers
Master pings workers periodically to detect failures
Distributed implementation should produce same output as a non-faulty sequential execution

Mapreduce
distributed processing parallelism
overzicht figuur
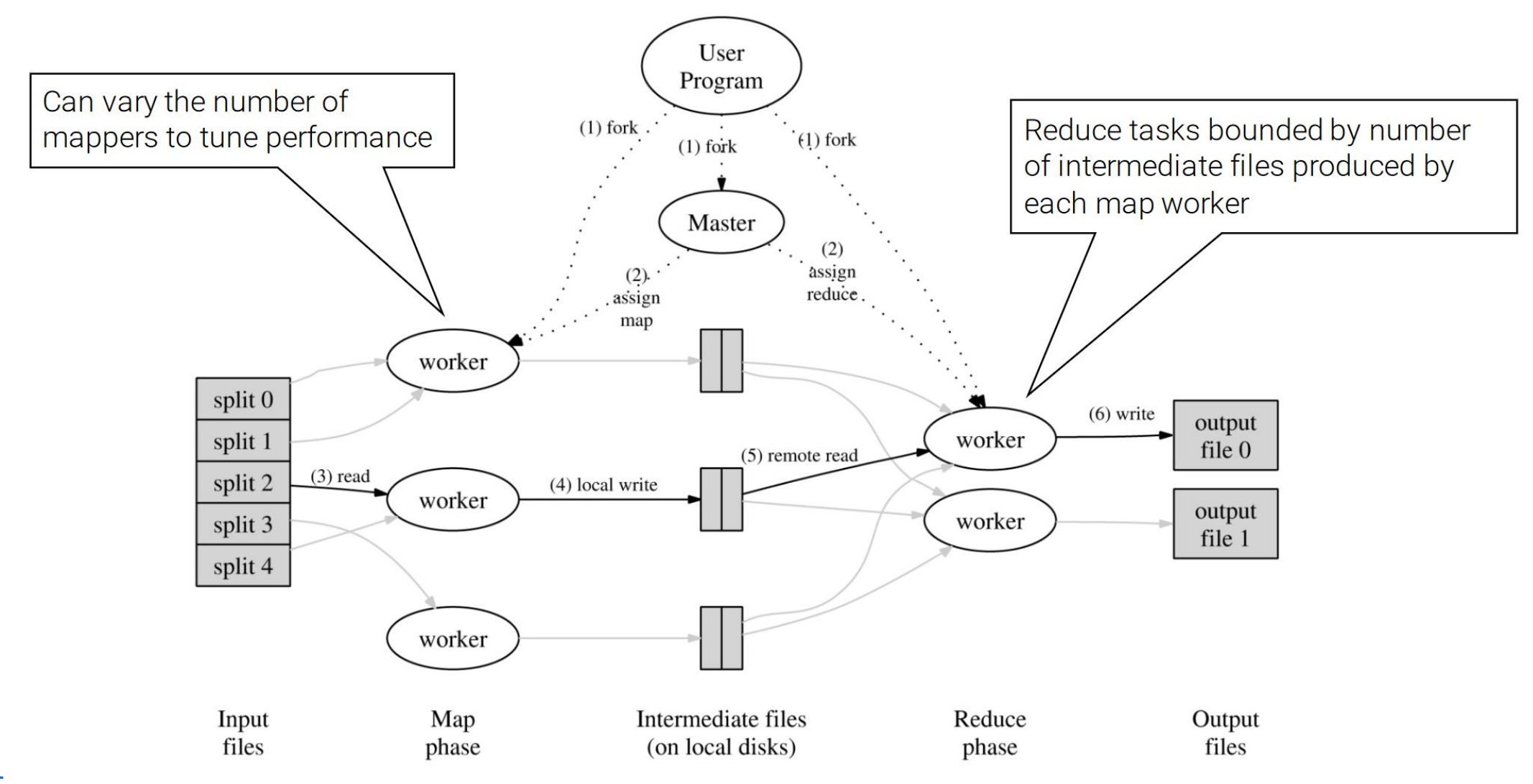
Mapreduce
how many map and reduce jobs
M map tasks, R reduce tasks
Rule of a thumb
Make M much larger than the number of nodes in the cluster
One DFS chunk per map is common
Improves dynamic load balancing and speeds up recovery from worker failures
Usually, R is smaller than M
Because output is spread across R files
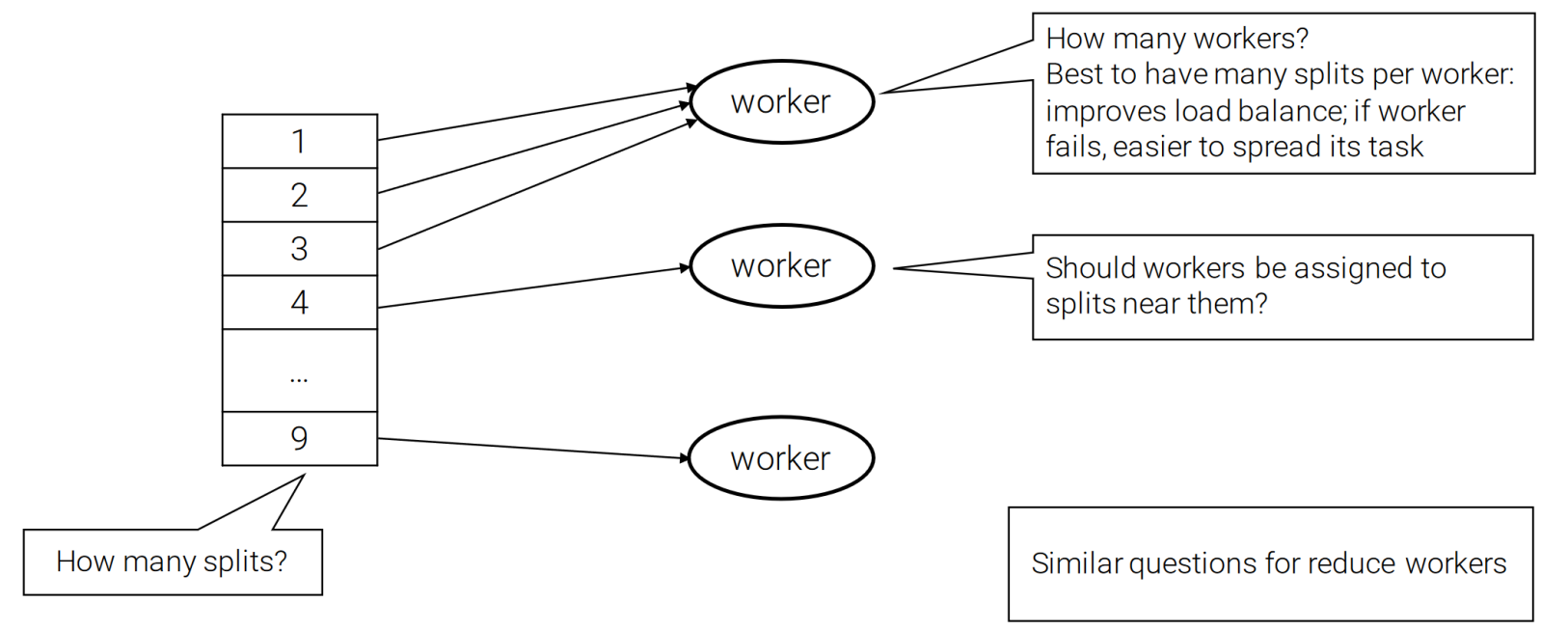
Mapreduce
voor en nadelen
Advantages
Model easy to use, hides details of parallelization and fault recovery
Many problems can be expressed in the MapReduce framework
Scales to thousands of machines
Disadvantages
1-input, 2-stage data flow is rigid, hard to adapt to other scenarios
Custom code is needed for even the most common operations e.g. filtering
Untransparent nature of map/reduce functions impedes optimization
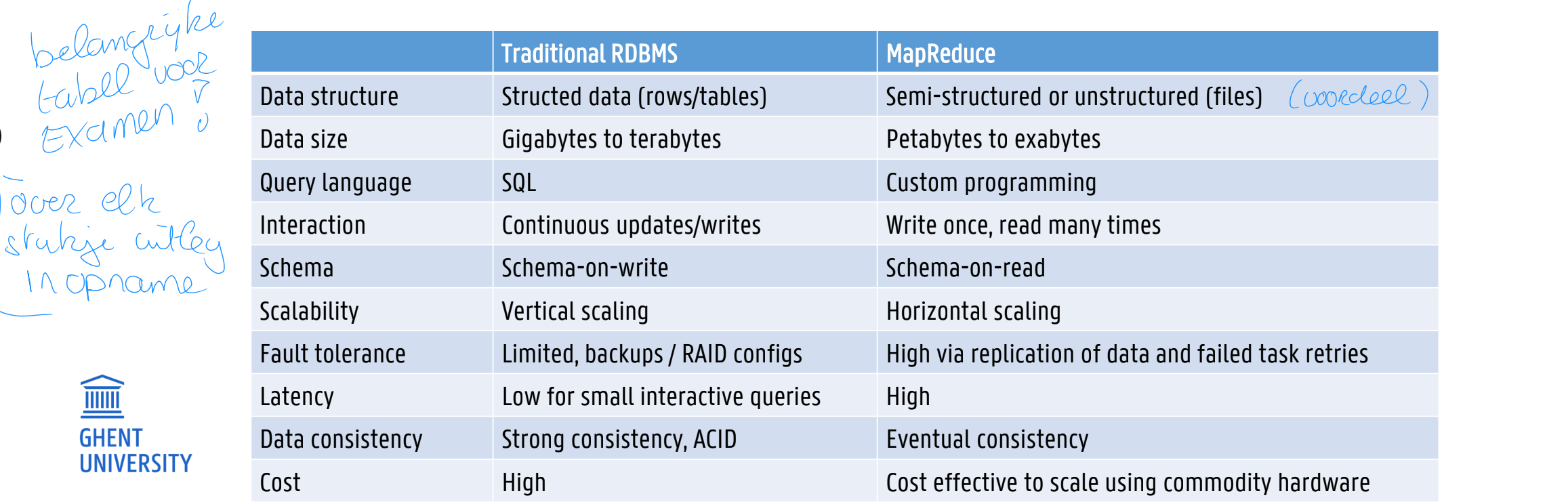
RDBMs vs Hadoop mapreduce (EX)
MapReduce suits applications where data is written once and read many times, whereas relational DBs are good for datasets that are continually updated
RDBMs handle structured data (defined format), Hadoop works well on unstructured or semi-structured data → designed to interpret data at processing time
Relational data often normalized to retain integrity and remove redundancy. For Hadoop, normalization poses problems because it makes reading a record a non-local operation (requiring joins).
Mapreduce advanced features
backup tasks
Problem: slow workers (so-called stragglers) significantly lengthen the job completion time
Other jobs on machine
Bad disks
Generic issues
Solution: spawn backup copies of tasks
Whichever one finishes first “wins”
Effect
Dramatically shortens job completion time, but must be able to eliminate redundant results
Increases load on cluster
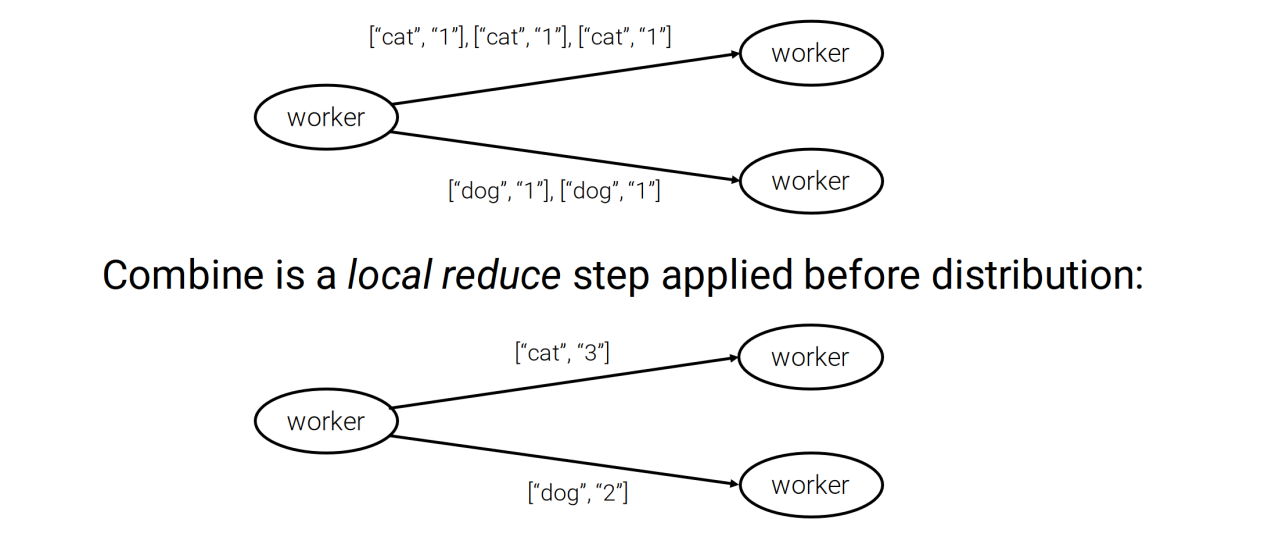
Mapreduce advanced features
Combiners
Often a Map task will produce many pairs of form (k,v1), (k,v2), ... for same key k
E.g., popular words in word count example
Save network time by pre-aggregating values in mapper
Combine(k, list(v1)) → v2
Combiner is usually the same as reduce function, but running after map task on map worker
Mapreduce advanced features
Custom partition function
Want to control how keys get partitioned over reducers
Inputs to map tasks are created by contiguous splits of input file
Reduce task requires records with same intermediate key end up at same worker
System uses a default partition function
hash(key) mod R, with R = number of reducers
Sometimes useful to override hash function
E.g., hash(hostname(URL)) mod R ensures URLs from a host end up in same output file
URLs (keys) like www.ugent.be and www.ugent.be/ea/nl would end up at different reducers
Mapreduce advanced features
The need for joins
mapreduce joins and secondary sort (figuur)
THE NEED FOR JOINS
In many datasets common for one record to have an association with another record
Denormalization can reduce need for joins
In a DB, executing query involving small number of records, DB will use an index to quickly locate records of interest
If query involves joins → may require multiple index lookups
Issue: MapReduce has no concept of indexes
When MapReduce job is given set of files as input → reads entire content of those files
In DB terms: full table scan
Very expensive if you only want to read a small number of records
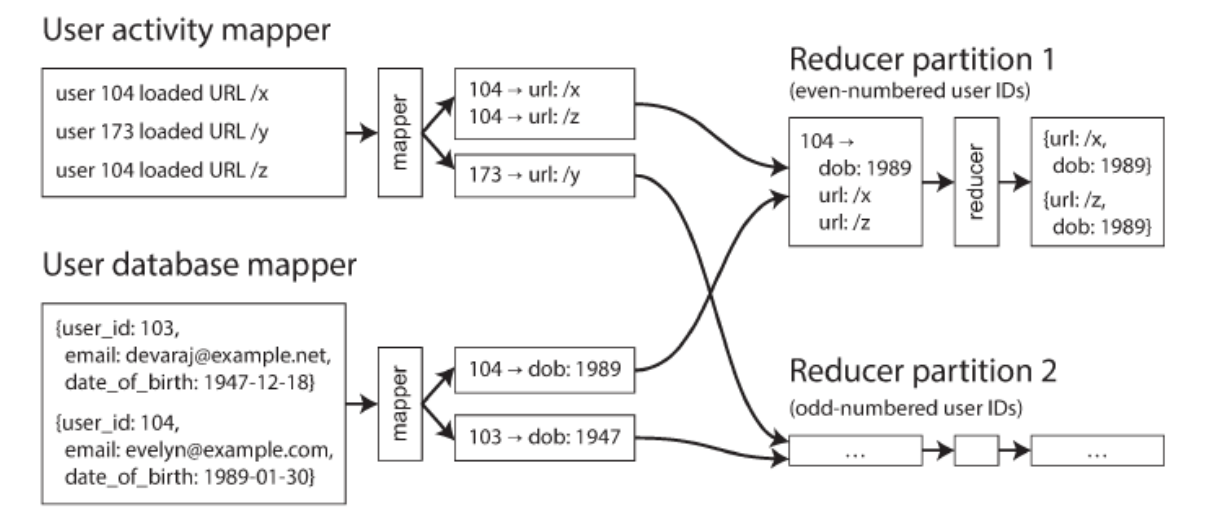
MAP-REDUCE JOINS AND SECONDARY SORT
Purpose of mapper is to extract a key and value from each input record
MapReduce framework partitions mapper output by key and sorts key-value pairs
Reducer performs actual join: called once for every user ID and thanks to secondary sort, first value is date-of-birth
Known as sort-merge joins
Mapper output sorted by key
Reducers merge together sorted lists
Apache Hive
Data warehouse software built on top of Hadoop
Declarative SQL-like interface to analyse data stored on Hadoop HDFS, Amazon S3
Hive QL, very similar to SQL (SELECT, JOIN, GROUP BY, etc.)
Querying from Hive shell, Web UI, applications
Queries broken down into MapReduce jobs and executed across a Hadoop cluster (note: can also use Spark for processing)
Best used for batch jobs over large sets of immutable data (e.g. log processing, analytics, creation of reports)
High latency
Read-based, inappropriate for transaction processing (OLTP)
Originated at Facebook
2013: need to analyse 500.000.000 logs per day, 75k queries
Used at Netflix, Amazon Elastic MapReduce, etc.
Apache Pig
Pig Latin procedural scripting language to create programs that run on Apache Hadoop
Data model: nested bags of items -> (‘key1', 222, {('value1'),('value2')})
Provides relational operators JOIN, GROUP BY, etc.
Compiler produces sequences of MapReduce programs (or Spark)
Compared to Hive
Quite similar, Pig focusses on programming, Hive focusses on declarative SQL-like language
Both Pig and Hive operate on top of Hadoop MapReduce and HDFS
Both have an easier learning curve than MapReduce and can do things in much less code
Pig: focus on data engineers/programmers, Hive: focus on analysts and SQL-knowledgeable users
Originated @Yahoo! around 2006
Apache Spark
algemeen (RDD?)
figuur
MapReduce issue = linear dataflow structure
Read → Process → Write
Reload data from stable storage on each iteration
Spark aims for in-memory processing, dealing with out-of-memory can be an issue
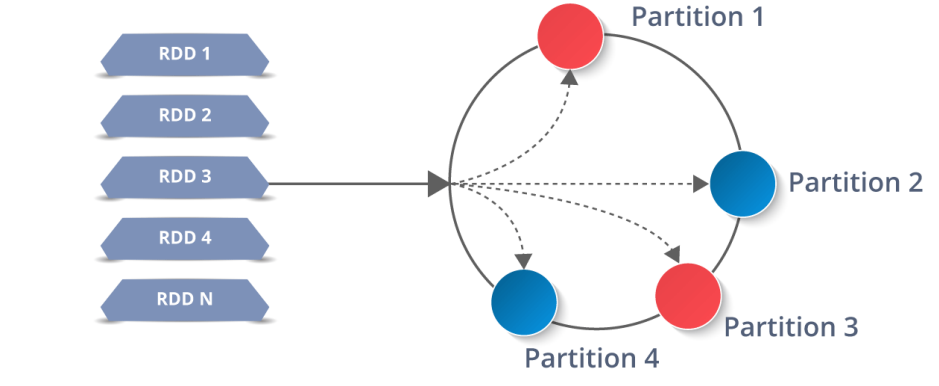
Apache Spark → concept of Resilient Distributed Dataset (RDD)
Resilient: if data in memory is lost, it can be recreated
Distributed: stored in memory across the cluster
Dataset: coming from file(s) or created programmatically
Spark facilitates implementation of
Iterative algorithms (e.g. machine learning)
Interactive / explorative data analysis
Machine learning
Apache Spark
pillars
figuur
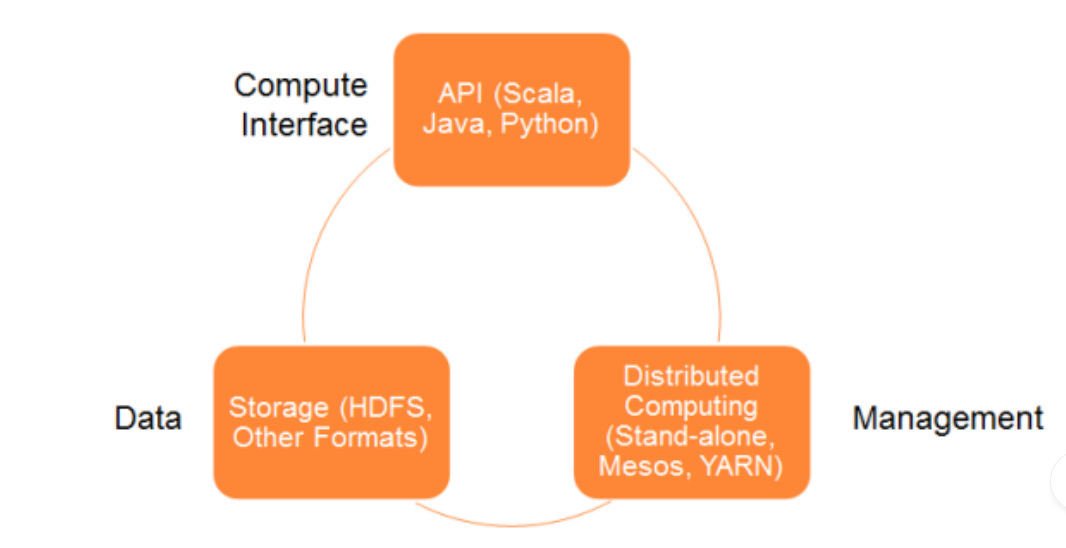
Computing API
Scala (native), Java, Python, R, SQL
Resource management
Stand-alone, YARN, Mesos and Kubernetes
Data Storage
HDFS (or Cassandra, S3, HBase, etc.)
Sparkinteraction
Spark Shell: interactive shell
SparkContext = main entry point to the Spark API
sc handle in Spark Shell
Spark Applications: for large scale data processing
Apache Spark: RDD
two types (figuur)
elements
addtitional functionality
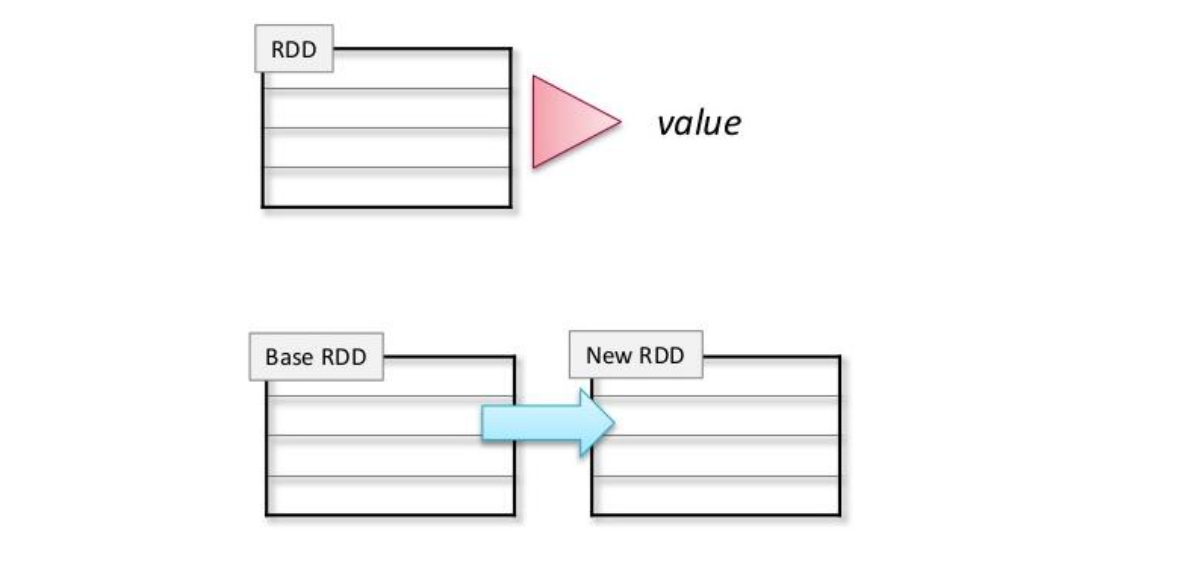
Two types
Actions – returning values
Count
Transformations – define new RDDs based on current one
Filter
Map
Reduce
RDDs can hold any type of element
Primitive types: integers, characters, bools, strings, etc.
Sequence types: lists, arrays, tuples, etc.
Scala/Java serializable objects
Mixed types
Some types of RDDs have additional functionality
Double RDDs: consisting of numeric data, offering e.g. variance, stdev methods
Pair RDDs: RDDs consisting of key-value pairs
For use with map-reduce algorithms
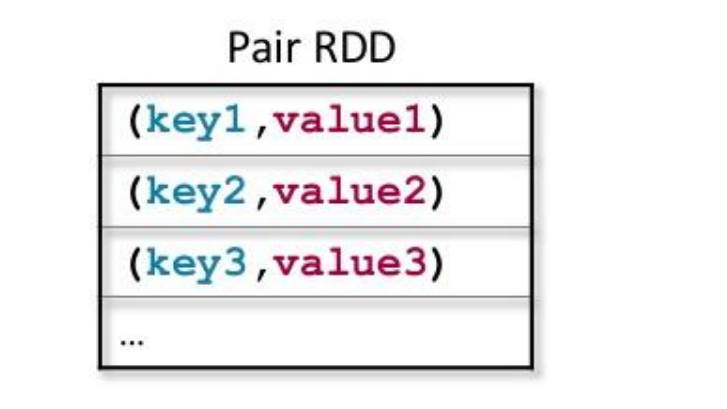
Apache Spark: RDD
newer features
RDD was the first and fundamental data structure of Spark
Low-level
DataFrame API (Spark >=v1.3)
Allows processing structured data
Data organised into named columns (e.g. relational database)
Why DataFrame over RDD?
Memory savings (binary format stored)
Optimized query execution
Dataset API (Spark >= v1.6)
Builds further on DataFrame API
Provides type safety and an object-oriented programming interface
More high-level expressions and queries available
Apache zeppelin
Apache project allowing rapid Spark script construction and visualisation of results
Web-based notebook for interactive data analysis
Currently Zeppelin supports Scala (Spark), Python (Spark), SparkSQL, Hive and more
Spark vs Hadoop mapreduce (EX)
On-disk versus in-memory processing (Hadoop vs Spark)
RAM access 10-100 times faster than disk-based access
Memory in the cluster will need to be at least as large as the amount of data to process
Memory cost >> disk cost
Fault-tolerance
In Hadoop MapReduce: intermediate files can be used as checkpoints
In Spark: recomputing RDD for the failed partition (RDDs have lineage information)
Type of jobs
For one-pass Big Data jobs MapReduce may be the better choice
For iterative jobs Spark is the better choice
Spark offers strongly reduced coding volume compared to MapReduce
Spark has streaming capabilities via Spark Streaming (see streaming section)
Spark maturity (2014 released but initiated in 2009) < MapReduce maturity (2006) (both are considered mature)
Ideally used symbiotic
Hadoop for distributed file system and processing of large immutable datasets (e.g. Extract Transform Load)
Spark for real-time in-memory processing of datasets that require it