CI : Topic 1 - Computer Architecture Cartes | Quizlet
1/48
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
49 Terms
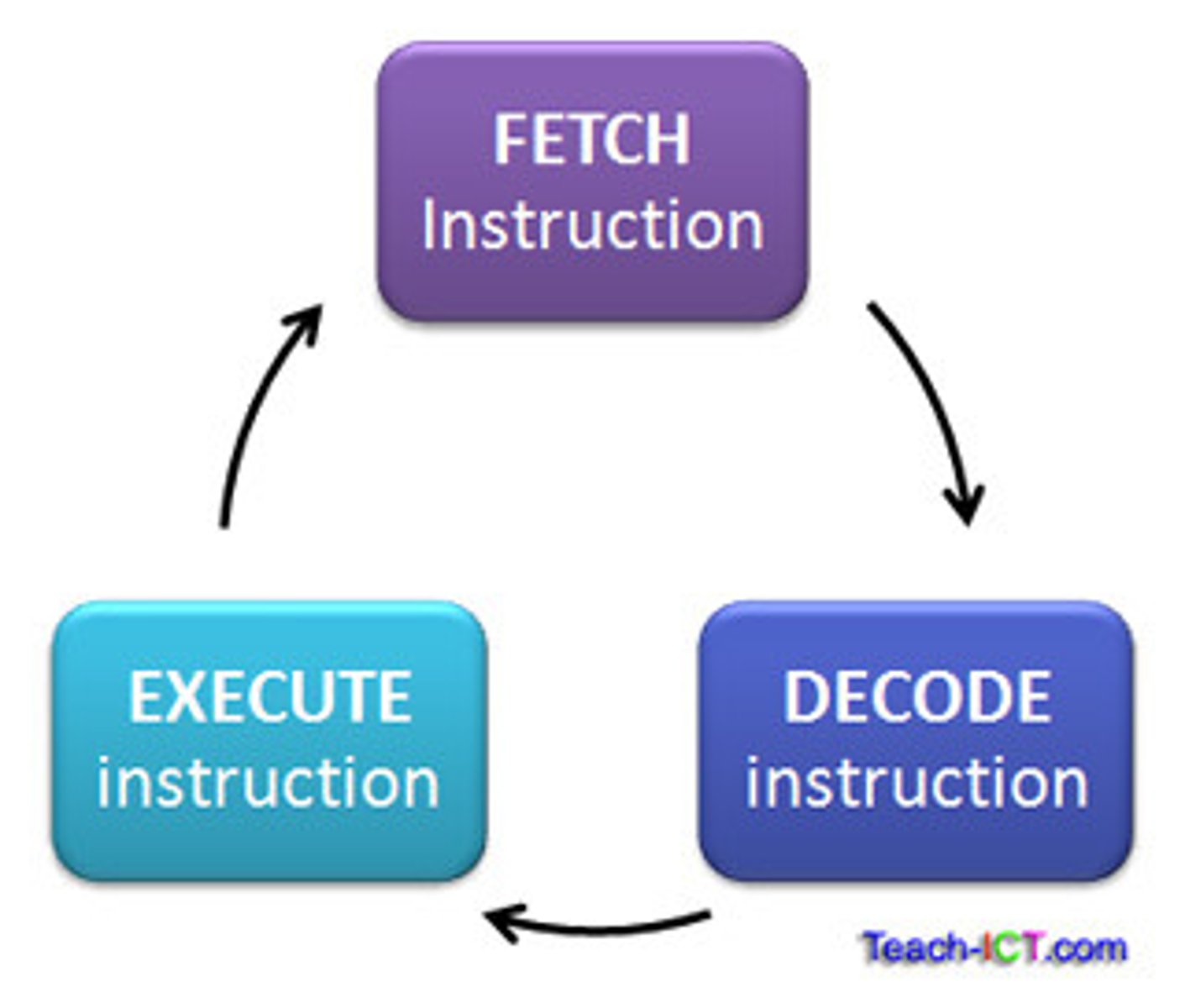
Control unit (CPU)
- manager of the CPU
- reads inst. from memory, interprets
→Fetches inst.
→Decodes
→Plans reading + writing of data
→Controls order of execution
→Controls ops performed by ALU
- 2 registers
→Instruction register: stores copy of current inst.
→Program counter: points to next inst.
- not very efficient
Word
- group of bits processed by the CPU as a single unit (16, 32, or 64 bits)
- word size → max amount of data CPU can handle in 1 op
- lager word size → faster, more powerful system
Latency
- time it takes for data to travel from source to dest (ms or ns)
- lower latency = faster response time
- affected by physical distance, hardware delays, speed of comm links
→→low latency for short, frequent accesses
Bandwidth
- max amount of data that can be transferred in a given time (mbps, gbps)
- higher = more data to flow simultaneously → better performance
- limited by hardware capabilities
→→high bandwidth for large sequential reads/writes
Why do we need caches?
- Memory Access Is Slow: Fetching data from RAM takes longer than processing it in the CPU
- Act as a bridge between the fast CPU and slower RAM, reducing latency
- Faster access to cached data improves overall CPU performance
Average Memory Access Time (AMAT)
= hit time + miss rate * miss penalty
- hit time: time to access the current cache level (e.g., L1, L2)
- miss rate: % of memory accesses resulting in a cache miss
- miss penalty: extra time to fetch data from the next level or main memory
→ smaller = better perf
Main Memory (RAM)
- primary mem, active programs + data temporarily stored for
quick access
→ Volatility: data lost when power off
→ Speed: faster than HDD/SSD, slower than cache
→ Capacity: consumer syst. : 8,16,32GBs, servers 256+
- organised in hierarchical structure → efficient data storage, access, retrieval
Difference RAM ROM?
RAM: read/write used for temp data
ROM (read only mem): non volatile, used for perm. storage
RAM hierarchy
1. Cell: millions of tiny cells (0 or 1), transistor & capacitor, periodic refreshment to maintain charge(DynamicRAM)
2. Row & Col: cells grouped in R&Cs for addressing
3. Bank: collection of R&Cs, mult banks → simult. access → higher efficiency
4. DRAM Chip: banks (4-16)
5. Rank
6. Channel: connects mem controller to DIMMs
7. Memory Controller: manages comms between RAM & CPU, add. translation, R/C selection, refresh cycles
8. DIMM (Dual Inline Memory module): physical RAM stick, mult ranks and DRAM chips, plugs into motherboard → syst. memory, 2 sides: front rank=o, back rank =1
Types of RAM
Dynamic RAM (DRAM) - main mem, stores data in capacitors: periodic refreshing
Static RAM (SRAM) - flipflops to store data, no need refreshing, faster, more expensive
DDR memory
Double Data Rate: transfers data twice per clock cycle (rising and falling edges)
Higher transfer speeds → better multitasking, gaming & AI workloads
Bandwidth (Bytes/s) = MT/s * bus width
Bus width
Refers to how much data can be transferred in one clock cycle (e.g., 64 bits = 8 bytes)
Wider bus widths → more data to move per cycle
Bandwidth formula
(GBs) = Clock speed (Ghz) x Channels x Bus Width bytes x DataRate (DDR multiplier)
HDD
Hard Disk Drive: mechanical moving parts, higher latency, cheaper, good for large data storage
SSD
Solid State Drive: flash mem, no moving parts, faster lower latency, better perf for RA/critical tasks, more expensive
Main Mem vs Secondary Storage
- Speed: 1 much faster
- Cost: 1 more expensive but faster so 2 better for longterm storage
- Use cases: 1 temp storage → for active data and progs
2 persistent storage → for files, OSs & large datasets
- Random vs sequential access: 1 better for sequential(eg videos)
main.asm
main:
//code
li $v0, 10
syscall
Virtual memory
- creates the illusion of more mem by using part of the storage (HDD/SSD) as temp mem
- the OS manages the virtual address space, mapping it to RAM
- allows progs to run even if RAM size exceeded
- enables larger apps to run
- isolation between progs --> better security and stability
How does the virtual memory handle overflow?
- RAM full --> the OS moves inactive data from RAM to HDD/SSD -->. SWAPPING
- data access much slower
- swapping prevents crashes + keeps ative progs running smoothly
3 CPU sections
- Front-End: fetches and decodes instructions. has to be quick
- Execution Engine: performs calculations. has to be efficient
- Memory Subsystem: moves data efficiently. has to keep up w data demand
if any are slow, the entire CPU slows down
CPU
Central Processing Unit
- main part of the comp where instructions are processed and executed
- coordinates and controls all components of the comp
- now comps have more than 1 → better speed
3 parts : Control Unit, ALU, Registers
CPU Clock
- 1 step = cycle
- it determines how many cycles/sec
- speed = Frequency (Hz)
- 1GHz = 1 billion cycles/sec
- higher freq. more cycles but more power & heat → they have speed limits
CPU time (s)
(instruction count * CPI) / frequency
FLOPS & INTOPS
Floating-Point/Integer ops per sec
- measure a computer's performance in processing specific types of operations
- neural networks rely on float. ops (eg. matrix *s)
- Formula : num of ops/ CPU time (s)
- max theoretical OPS = freq cores ops per cycle
Core
- independent PU inside the CPU that executes inst
- each core has its own ALU, registers etc.
- mdrn CPUs have mult cores → work on tasks simultaneously
Sockets
- physical CPUs on the motherboard
- systems can have mult, each multicore CPU
- more sockets = more cores → greater
parallelism
- used for tasks requiring massive computational power: AI
training, scientific simulations, data centers
- comms between sockets → delay comp to cores on same CPU
- too many → pwr consum., heat, size → impractical
- diminishing results → inefficient
Memory hierarchy
+ speed, - capacity→ - speed, ++ capacity
→ Registers (fastest, smallest)
→ Cache (level 1, 2, sometimes 3)
→ RAM (main mem)
→ Secondary storage (HDD, SSD)
Cache
- small high speed memory, close to or inside CPU
- store freq used data/inst → reduce need to access slower main mem (RAM)
- 3 levels
Cache hit
- when the CPU finds the stored data in the cache
- faster access (based on cache mem)
Cache miss
- when requested data is not found in cache
- slower access (based on latency of off-chip mem)
How to reduce AMAT?
optimizing cache size, latency and miss rate
AMAT
Average Memory Access Time
= HitTime + (MissRate * MissPenalty)
ISA
Instruction Set Archi
- bridge between HW & SW, defining comms
- instruction level
- remains constant--> SW longevity + compatibility
Ex: MIPS, x86, ARM, RISC-V
What makes a good ISA?
- Programmability: ease to express progs efficiently
- Performance/Implementability: ease to design high-perf implementations + low power + low cost
- Compatibility: ease to maintain as languages/progs/techs evolve
CISC
Complex Instruction Set Computer
- each inst executes mult low level ops
- smaller prog size
BUT complex inst decoding, ++size of CU, ++logic delays
- code smaller but more complicated
RISC
Reduced Instruction Set Computer
- mem cost dropped --> execution speed
- 1 inst/cycle --> better efficiency + pipelining
- eg MIPS: simpler design outperforms CISC
- code larger but simpler
ISA vs Assembly
ISA: defines instructions, data types... modes the hardware understands
Assembly: human readable representation of the ISA instructions
GPU
Graphics Processing Unit
- adds dedicated cores for parallel tasks
- contrary to CPU, many simple cores
- GPU data parallelism: mult small cores perform the same operation on many pieces of data in parallel eg: img pixels
- CPU task parallelism: mult cores perform diff tasks simultaneously eg: 1 OS 2 Code 3 video...
Von Neumann model
- stored program computer: instruction + data in the same memory
- modern computers
Components:
1. CPU
2. Memory
3. Input/Output (I/O)
Memory
Stores instructions and data
I/O
Interfaces with the outside world
Alternative architectures to the VN model?
- Harvard: separate instruction/data memory; in embedded systems
- Quantum Computing: qubits, superposition, entanglement; in cryptography, quantum sims
- Neuromorphic: mimics our brain's structure; in pattern recognition, robotics
Registers (CPU)
- small, fast memory
- temporarily store data, instructions, addresses
- faster data access than main mem (RAM)
- efficiency
ALU (CPU)
Arithmetic and Logic Unit
- where all mathematical calculations are carried out
- +, -, x, ÷, >, >= , =, <>, AND, OR, NOT
- "Accumulator" → register that stores the result of the current calc
How does the ALU work?
- inputs: 2 arguments (operands)*
- operation selector: control signal to determine the operation (OpCode)**
- output: result of the op
*some ALUs have mult inputs to perform operations in parallel (like in GPUs)
2 ipt.:simple, efficient
**uses adders for int additions + logic gates for complex ops
FPUs → for float. , the CPU determines which unit to used based on instruction type
Solution to inefficiency of the CU?
Pipelining : overlapping diff instruction stages (eg. fetch, decode, execute) to work simultaneously
→ better resource utilisation
- the higher the num of inst., the more efficient it is
! hazards
Cycle Per Instruction (CPI)
- avg num of cycles per inst.
- diff inst. (eg. + vs *), diff cycles
- pipeline stalls/hazard penalties increase CPI
- pipeline tries to reduce CPI close to 1, never perf bc of stalls
- lower CPI → better perf, fewer cycles/inst
- higher → takes longer to execute 1 inst
Parallelism
- mult cores → work on tasks simultaneously
- dividing tasks into smaller parts and distributing them across cores
- not all tasks can be fully parallelized (some parts have to be run in a seq.)
- multi-core CPUs, GPUs, and distributed systems rely on parallelism
En cours (38)
Vous avez commencé à étudier ces termes. Continuez le bel effort !