Writing PyTorch Code for Binary Classification
1/7
Earn XP
Description and Tags
Breast Cancer Dataset
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No study sessions yet.
8 Terms
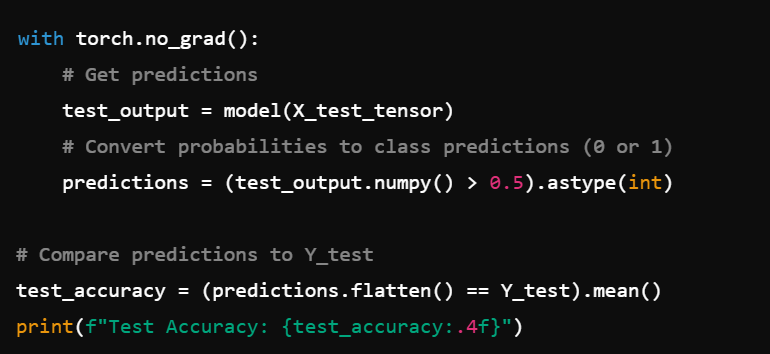
You have a NumPy dataset for breast cancer classification and want to create training and test sets. You also need to ensure the data types are float32 for PyTorch. How do you do it?
We load the breast cancer dataset, convert X and Y to float32 (because PyTorch expects floating-point data), and then split into train/test sets using train_test_split.
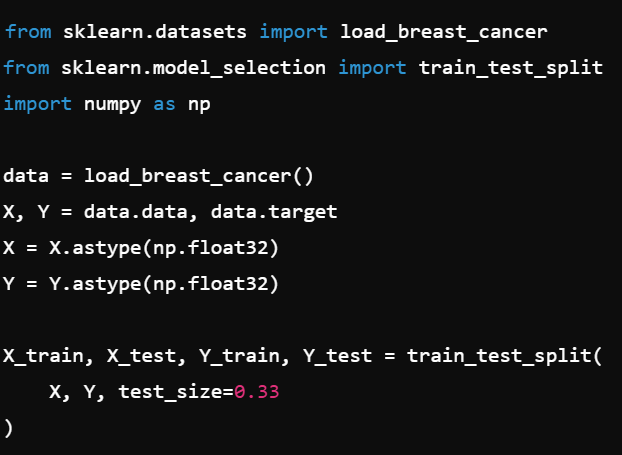
You want your neural network to process scaled data for better performance. How do you standardize the training set and then apply the same transformation to the test set?
fit_transform learns the scaling parameters (mean, std) from the training data, while transform applies the same parameters to the test data without re-fitting.
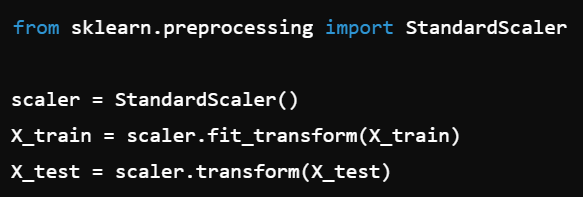
You need to define a simple feed-forward network to output a probability for binary classification. Which PyTorch modules do you use?
We use nn.Linear for a single-layer perceptron. The output is 1 node because it’s a binary classification task, and nn.Sigmoid squashes the output to a probability (0-1).
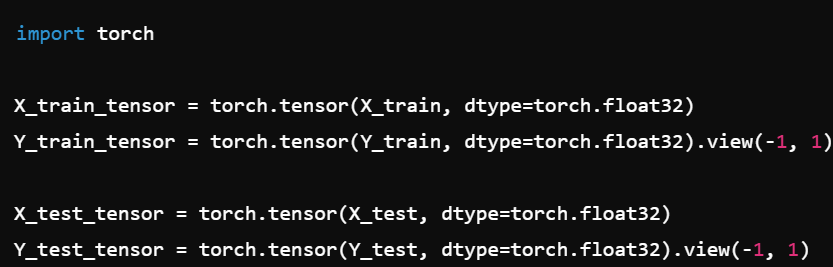
You have NumPy arrays for your features and labels, but PyTorch requires tensors for training. How do you convert them properly for a binary classification task?
We convert arrays to tensors using
torch.tensor().We use
.view(-1, 1)on labels to match the model’s expected shape (one column per sample).
You want to set up a loss function and an optimizer for binary cross-entropy classification using PyTorch. Which ones should you choose and how?
nn.BCELossis the standard for binary classification tasks.optim.Adamis a commonly used optimizer for many neural network tasks because it adapts the learning rate for each parameter.

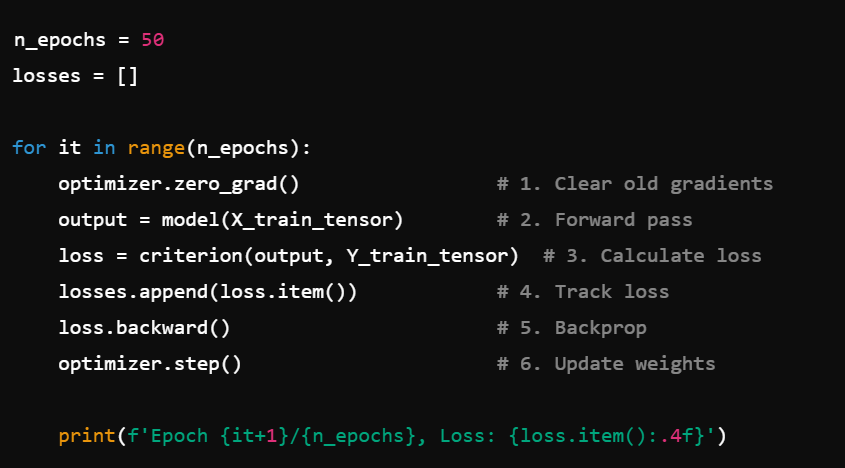
You need to write a training loop for 50 epochs that prints out the loss at each iteration. Which steps must occur inside each epoch?
optimizer.zero_grad(): Clear any accumulated gradients from previous steps.Forward pass: Get predictions from the model.
Calculate loss: Compare predictions to true labels.
loss.backward(): Calculate gradients for all parameters.optimizer.step(): Update the model parameters based on the gradients.Print/Save: Keep track of the loss to monitor performance.
You suspect your model might be overfitting after 50 epochs. How can you monitor or reduce overfitting in your current setup?
Monitor:
Compare training loss vs. test loss after each epoch.
Use metrics such as accuracy on both training and test sets.
Reduce:
Implement regularization (e.g., add a dropout layer).
Use early stopping (stop training when test loss stops improving).
Collect more data or perform data augmentation if possible.
Explanation:
Monitoring train/test performance reveals whether the model memorizes the training set at the expense of test accuracy (overfitting). Techniques like dropout, early stopping, or additional data often help.
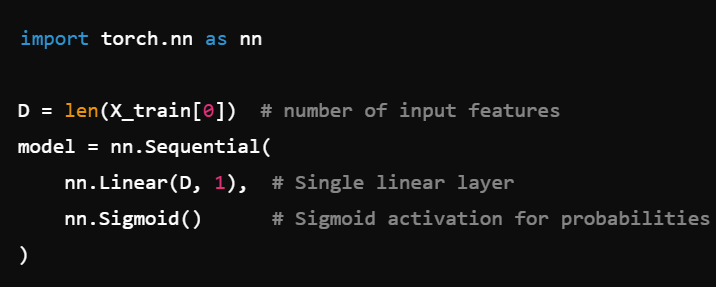
After training, how would you evaluate your model on the test set to get an accuracy score?
with torch.no_grad():disables gradient computation (faster inference).We threshold the output at 0.5 to get 0/1 predictions.
Then we compute the fraction of correct labels for accuracy.