biochem - week 3/4
1/44
Earn XP
Description and Tags
DNA replication
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
45 Terms
genome
The entire set of DNA present in a cell is called the genome
Prokaryotes:
the genome consists of circular DNA
The DNA is concentrated in a specific region on the cytoplasm called the nucleoid, which is not enclosed by a membrane
e.g. bacteria
Eukaryotes:
The genome is mainly composed of linear DNA. However, mitochondria and chloroplasts present in eukaryotes contain circular DNA
The linear DNA is packaged in a membrane-enclosed nucleus
e.g. animals, plants and fungi
chromosomes
Eukaryotic DNA is packaged into a set of chromosomes
Each chromosome contains a single double-stranded DNA with packaging proteins
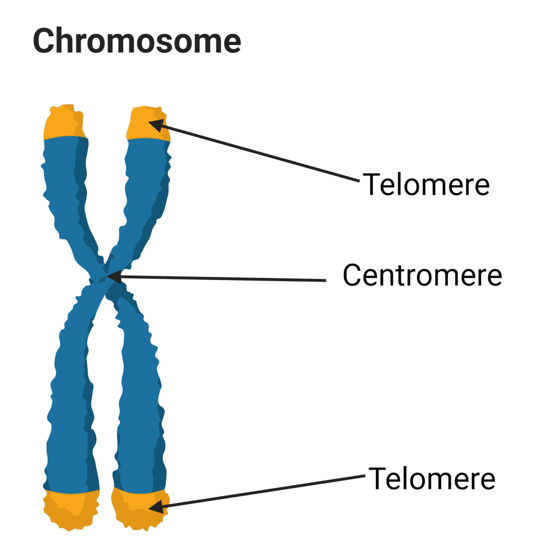
The linear chromosomes contain centromeres and telomeres
Centromeres: important for cell division
Telomeres: DNA sections located at the ends of the chromosomes
Plants and animals, including humans, have linear chromosomes arranged in pairs within the nucleus
The only exception in humans is reproductive cells, which only contain one copy of each chromosome
Humans possess 23 pairs of chromosomes (altogether 46 chromosomes)
Autosomes (22 pairs similar in males and females) and the sex chromosome
Karyotype: a complete set of chromosomes present in an individual
Used to identify the changes in the number and structure of chromosomes
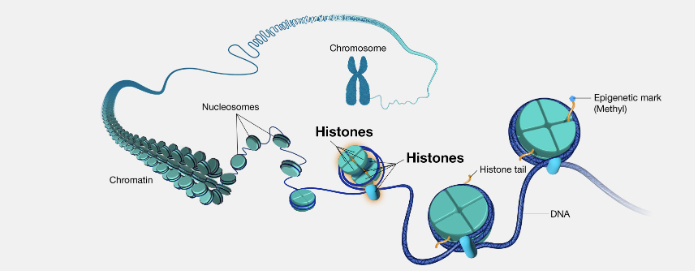
chromatin and nucleosomes
The first level of compaction occurs when the DNA molecule is wrapped around histone proteins, and the resulting DNA-protein complex is known as chromatin
Histones are small, positively charged proteins
Therefore, forms strong interactions with the negatively charged DNA molecule
Unfolded chromatin appears as beads on a string in electron micrographs
The repeating units (beads) present in chromatin are called nucleosomes
Each nucleosome consists of the DNA wrapped 1.7 times around 8 histone proteins
The coiling of nucleosomes further shortens the length of the DNA molecule to a 30 nm chromatin fibre
The next level of compaction occurs during mitosis (a phase of cell division), forming chromosomes
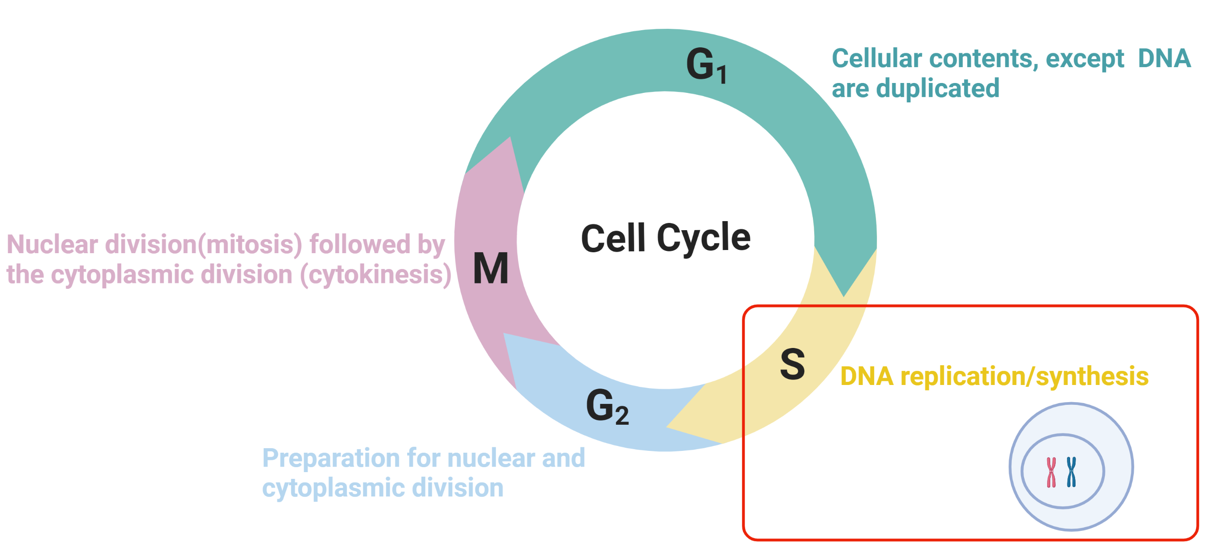
DNA replication and cell cycle
accurate replication of genomic DNA is essential to the lives of all cells and organisms
each time a cell divides, its entire genome must be duplicated
complex enzymatic mechanisms are associated with copying the large DNA molecule
DNA replication occurs in the S phase of the cell cycle
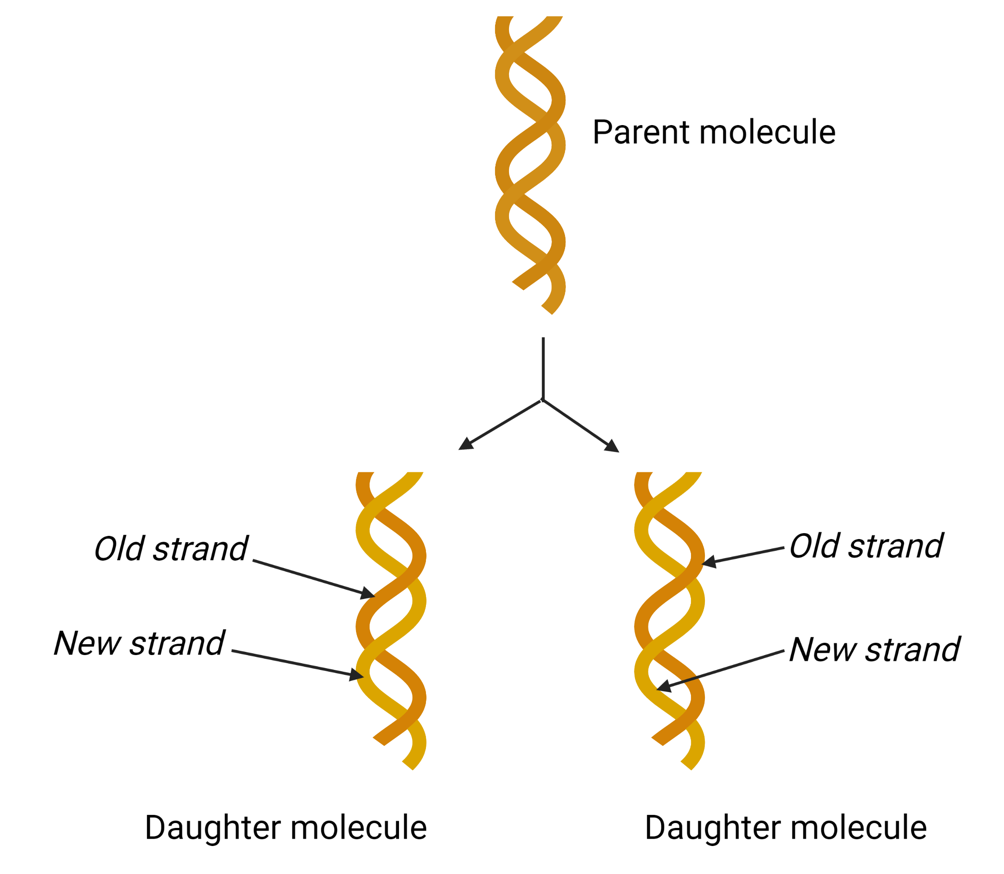
DNA replication is semiconservative
Each parental single strand is a template for the synthesis of a new complementary daughter strand
Therefore, in each newly synthesised DNA molecule, one strand is derived from the parent DNA molecule, while the other is a newly synthesised daughter strand
initiation of DNA replication
DNA replication starts at specific base sequences, known as the origin of replication
The enzyme DNA helicase binds to the origin of replication and unwinds the parent double helix by breaking bonds between complementary base pairs creating the replication fork
Replication forks are Y-shaped regions within the DNA where active replication occurs. These replication forks begin at a single site within the DNA and proceed bidirectionally
The unwinding exposes single-stranded templates for the new synthesis
Single-stranded DNA binding proteins (SSB) prevent the reformation of bonds between two parent strands before replication begins by binding to the exposed regions of the strands
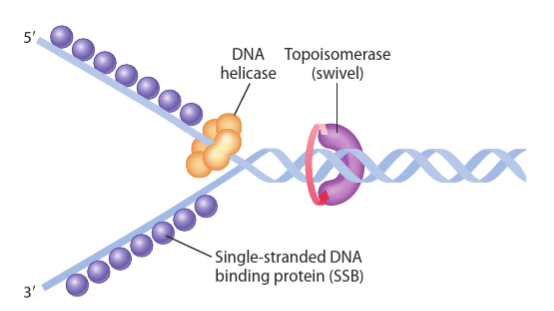
Pre-replication complex
Pre replication complex consists of several proteins
Origin recognition complex (ORC) binds to the origin of replication
Minichromosome maintenance protein (MCM) contains DNA helicase, which unwinds the DNA double helix
Helicase loaders mediate the binding of MCM to the ORC
Role of DNA Polymerase in DNA replication
DNA polymerases are a group of enzymes that are essential for DNA replication
Two types of DNA polymerases are used in eukaryotic DNA replication
the DNA polymerase adds new nucleotides to the growing daughter chain
One end of the DNA molecule is named 5’ (five prime), and the other is 3’ (three prime). This originated from the number of carbon atoms in deoxyribose sugar that bond with the phosphate group
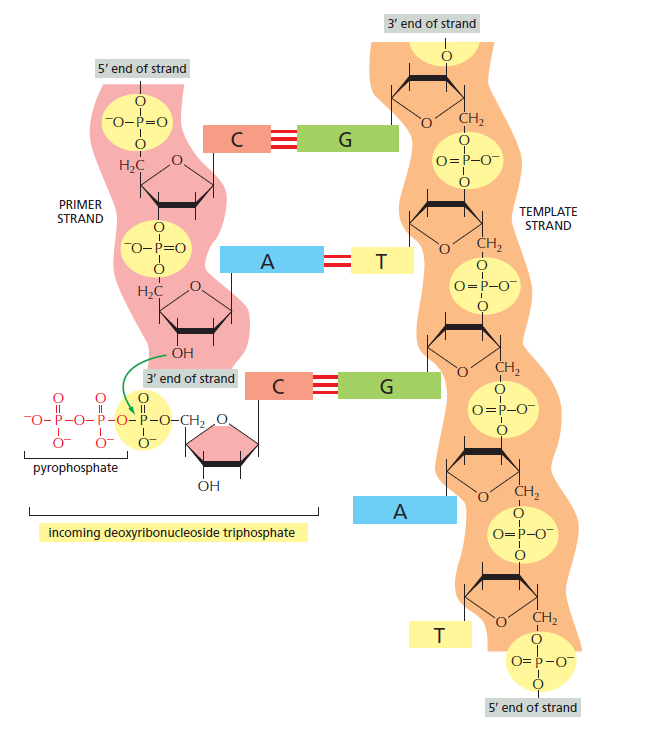
all polymerases synthesise DNA only in the 5’ to 3’ direction. So, new nucleotides can only be added to the 3’ end of the new strand
the parent strand is copied from 3’ to 5’, and the daughter strand is synthesised from 5’ to 3’
the DNA polymerase determines which deoxyribonucleotides among A, C, G and T will be added to the daughter strand depending on the base on the template DNA. A pairs with T, and G pairs with C
DNA polymerase can add a new deoxyribonucleotide only to a preformed strand that is already bonded to the template. Thus, a small RNA primer segment is added to the DNA
DNA polymerase adds the first nucleotide to the 3’ end of the RNA primer
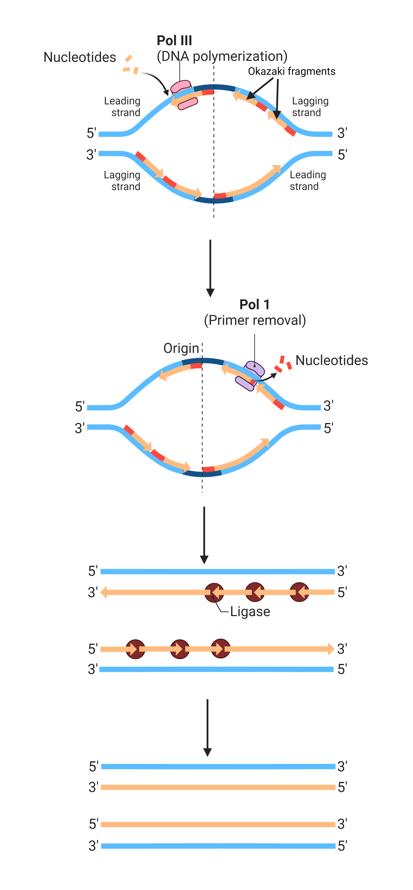
leading and lagging strand
As the two strands of double-helical DNA run in opposite (antiparallel) directions, one new strand is synthesised in the 5’ to 3’ direction. In contrast, the other is synthesised in the 3’ to 5’ direction.
As DNA polymerase can only synthesise DNA in a 5’ to 3’ direction, only one strand of DNA is synthesised continuously, and the other is formed from short, discontinuous fragments of DNA called Okazaki fragments
Okazaki fragments are joined by DNA ligase to form a continuous strand
The continuously synthesised strand is called the leading strand, and the discontinuously synthesised strand (from Okazaki fragments) is called the lagging strand
The leading strand is synthesised in the direction of the replication fork movement, while the lagging strand is synthesised backward to the direction of movement of the replication fork
RNA primers (3-10 nucleotides) serve as the starting point for Okazaki fragments, as DNA polymerase can only add nucleotides to the end of an existing chain. Then, DNA polymerase III add nucleotides to the RNA primer, creating Okazaki fragments
In addition to the polymerase activity, DNA polymerase I has an exonuclease activity (can hydrolyse DNA/RNA), which is used in proofreading and removal of RNA primers
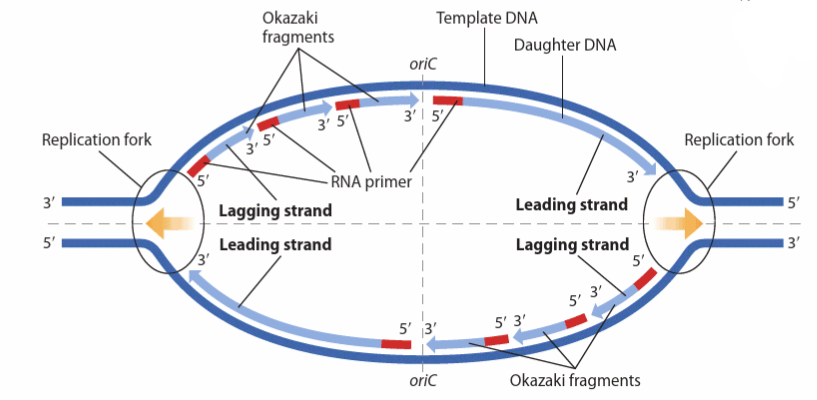
Replication bubble
Replication initiates simultaneously at multiple times (multiple origins of replication) within the DNA
Replication proceeds away from the origin bidirectionally creating replication bubbles
These replication bubbles expand as replication proceeds and eventually fuse with adjacent bubbles to form a continuous strand
The Central Dogma
DNA provides the info needed to construct the proteins necessary for the cell to perform all of its functions
To do this, DNA is “read” into an mRNA molecule, and the mRNA then provides the code to form a protein. This flow of inherited info in cells from DNA to mRNA to protein is described by the central dogma
The two main stages of info flow are transcription and translation. Transcription is the process that allows copying of DNA to mRNA, and translation is the process of encoding a protein from the mRNA
Transcription is a relatively straightforward process, with one nucleotide being added to the mRNA strand for every complementary nucleotide read in the DNA strand. On the other hand, translation is a more complex process, with one amino acid being added to the protein sequence for groups of 3 mRNA nucleotides
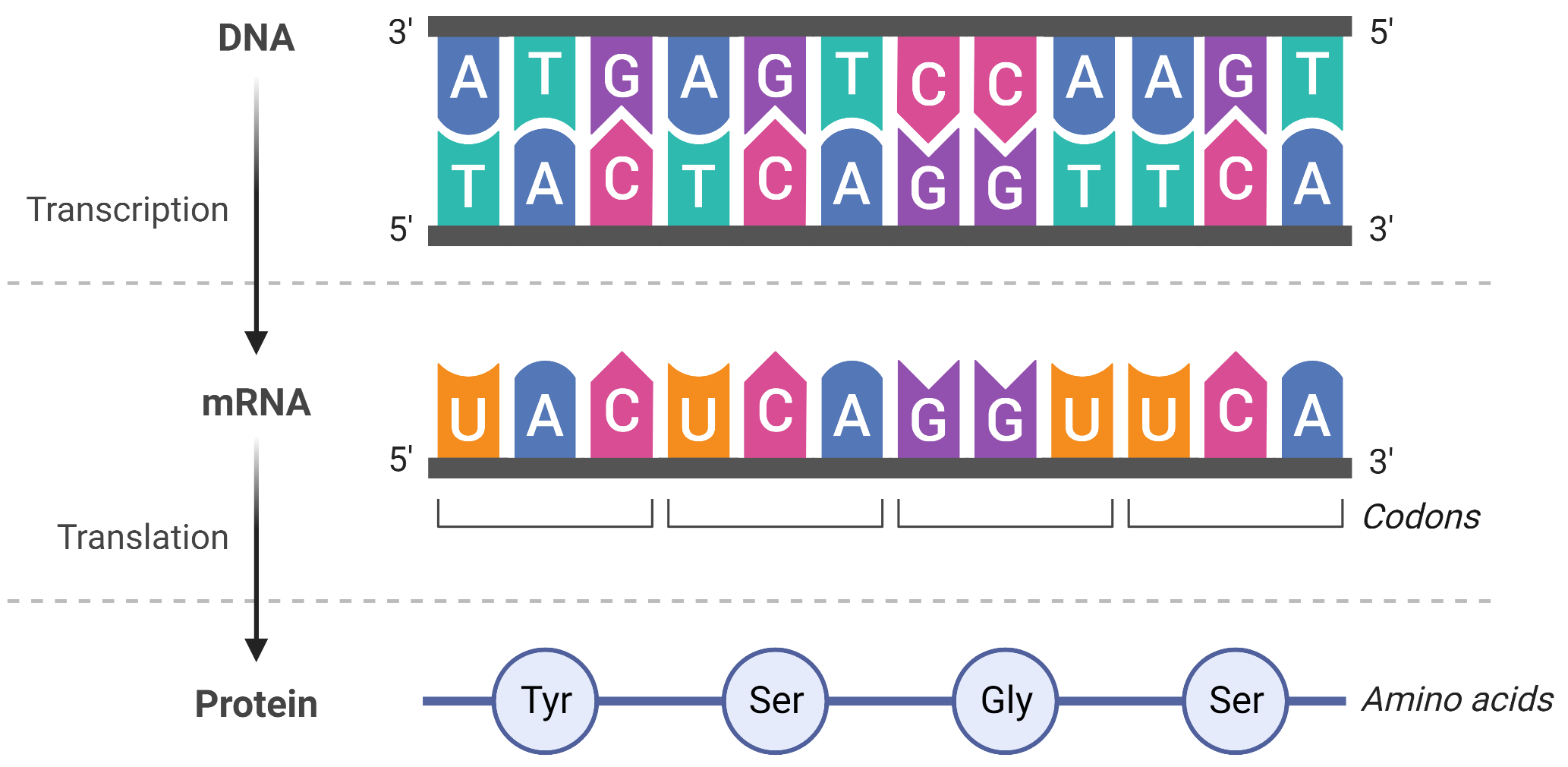
Transcription
the process of copying a DNA sequence from a gene into an mRNA sequence as the first step of creating a protein. In both prokaryotes and eukaryotes, transcription occurs in 3 main stages: (1) Initiation, (2) Elongation and (3) Termination
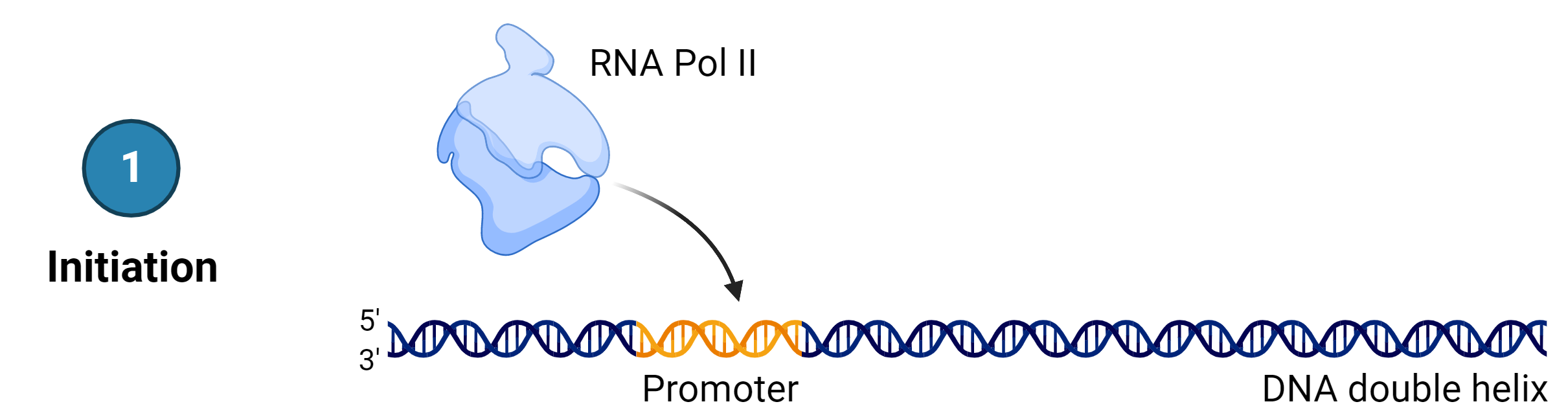
Stage 1: Initiation
Transcription requires the DNA double helix to partially unwind in the region of mRNA synthesis, i.e. only the gene unwinds.
The region of unwinding is called a transcription bubble. The process starts at the promoters that, in most cases, exist upstream from the transcriptional start point.
Several transcription factors and RNA polymerase II bind to the DNA sequence, forming the transcription initiation complex. RNA polymerase II unwinds the DNA double helix, and the RNA synthesis begins at the transcription start site on the template strand
Stage 2: Elongation
Transcription proceeds from one of two DNA strands called the template strand (or the non-coding strand)
The mRNA is copied off this strand by complementary base-pairing, and therefore, the mRNA product is complementary to the template strand.
The sequence of nucleotides in the mRNA synthesised is almost identical to the other DNA strand called the non-template strand (or the coding strand), with the exception that mRNA contains a uracil (U) in place of the thymine (T) found in DNA.
During elongation, RNA polymerase moves along the DNA template strand, joining complementary RNA nucleotides to the 3’ end of the growing RNA transcript like DNA replication, with the difference that an RNA strand is being synthesised that does not remain bound to the DNA template.
As elongation proceeds, the DNA is continuously unwound ahead of the core enzyme and rewound behind it

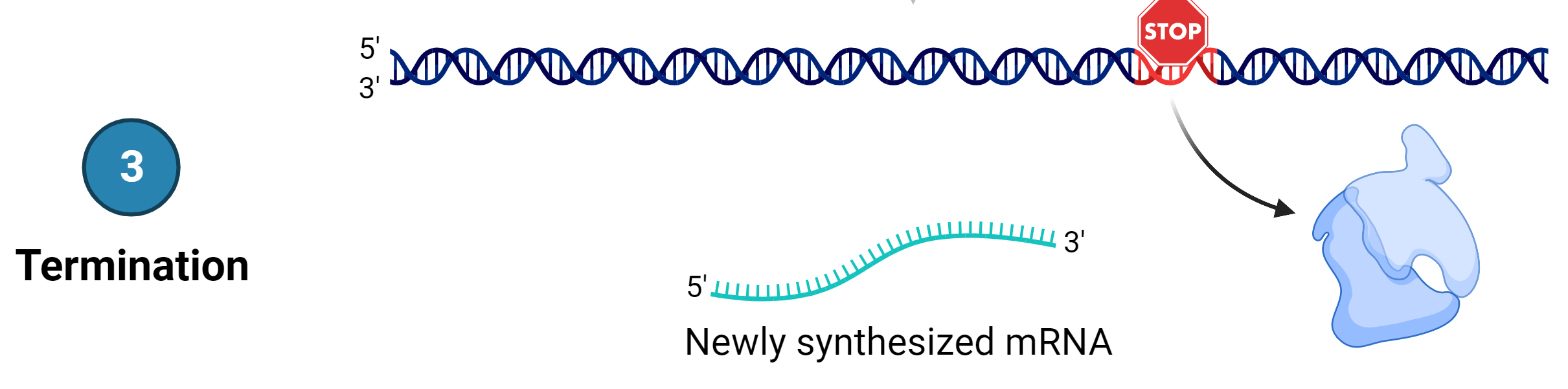
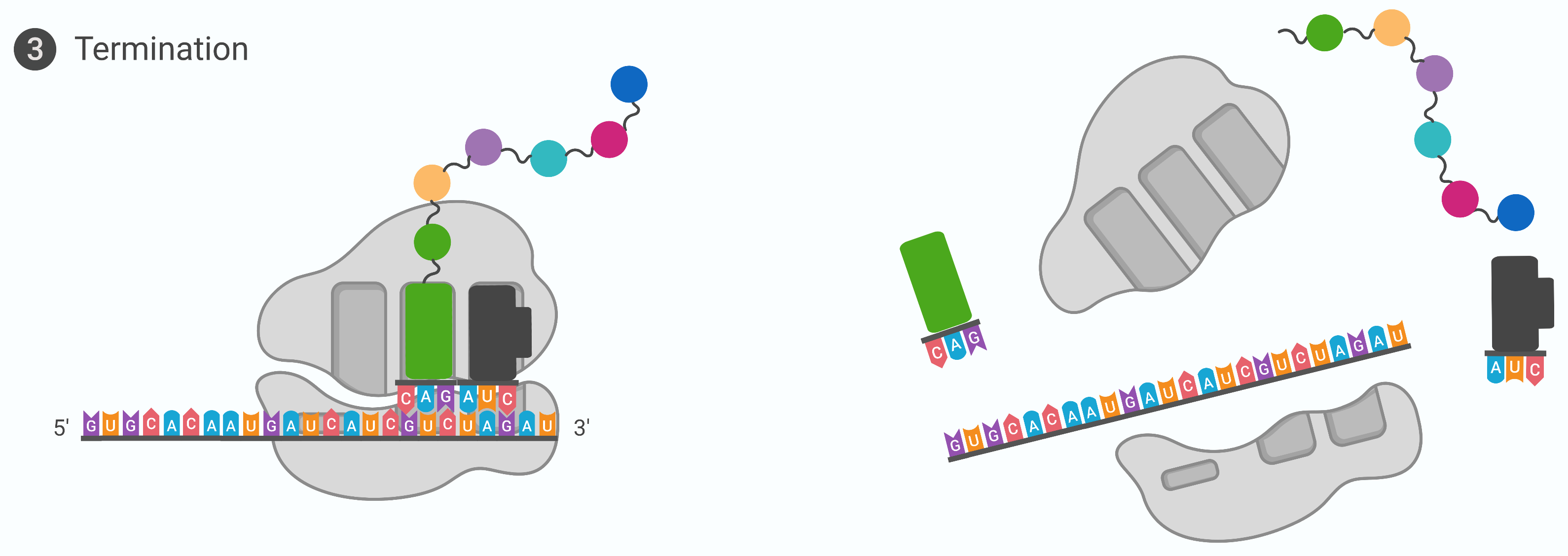
Stage 3: Termination
Once a gene is transcribed, the RNA polymerase dissociates from the DNA template and releases the newly made mRNA. On termination, the process of transcription is complete
eukaryotic mRNA processing
In a prokaryotic cell (e.g., bacteria and archea), which lacks a membrane-bound nucleus, transcription occurs in the cytoplasm of the cell. The mRNA produced by transcription is immediately translated without additional processing.
In a eukaryotic cell, transcription occurs in the nucleus of the cell, and the mRNA transcript must be processed and then transported to the cytoplasm for translation
The newly transcribed eukaryotic mRNA must undergo several processing steps before it can be transferred from the nucleus to the cytoplasm and translated into a protein. The mRNA transcript undergoes 3 main processing steps: (1) addition of 5’ cap, (2) intron splicing and (3) addition of a 3’ poly A tail
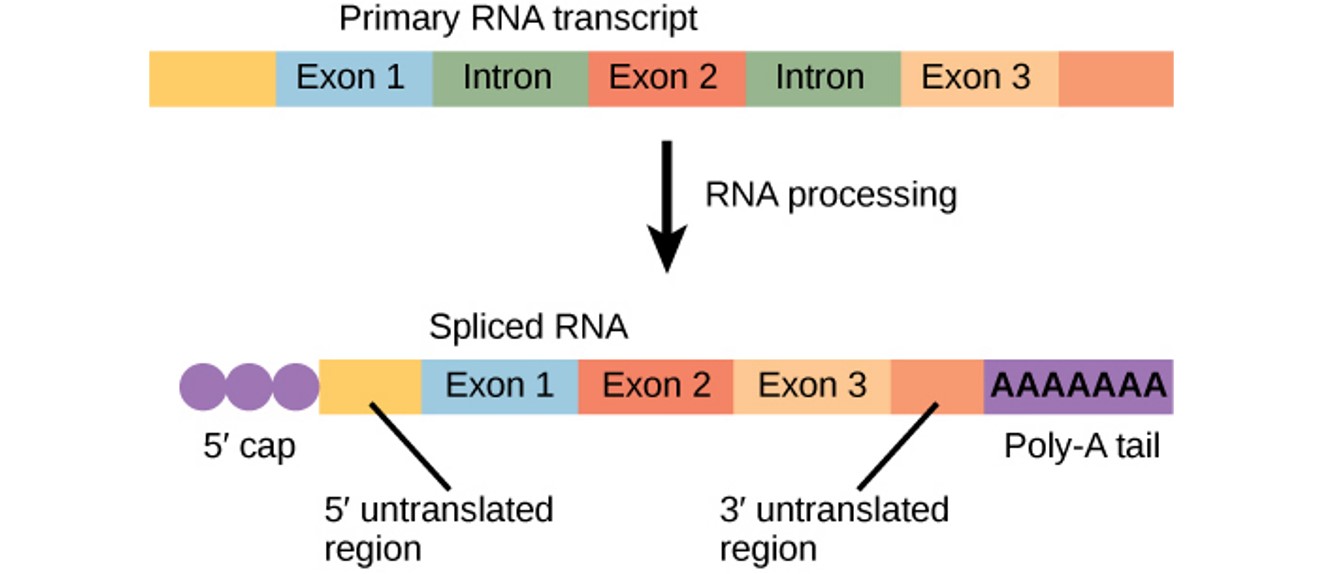
addition of a 5’ cap
addition of a modified guanine nucleotide to the 5’ end of the growing mRNA transcript occurs while the pre-mRNA is still being synthesised
Significance: to prevent degradation of mRNA, to facilitate export of mRNA from nucleus to cytoplasm and to help initiate translation by ribosomes
addition of a 3’ poly A tail
Once elongation is complete, a string of 50-200 adenine nucleotides, called the poly A tail, is added to the 3’ end
Significance: to protect pre-mRNA from degradation and to facilitate the export of mRNA from the nucleus to the cytosol
intron splicing
Eukaryotic genes are composed of protein-coding sequences called exons and intervening sequences called introns
Introns are removed from the pre-mRNA before protein synthesis so that the exons join together to code for the correct amino acids
The process of removing introns and joining the exons in the correct order is called splicing. Introns are removed and degraded while the pre-mRNA is still in the nucleus
Significance: to create an mRNA with a continuous coding sequence to code for correct amino acids
translation
the process of transferring the genetic info from the mature mRNA sequence into a chain of amino acids
tRNA - component of translation
Non-coding form of RNA that translates the language of mRNA into the language of proteins. The tRNA molecule folds into a cloverleaf structure and serves as an adaptor molecule. The molecule has two features: (i) the amino acid binding site at its 3’ end and (ii) the anticodon site.
The amino acid binding site helps the tRNA molecule carry a specific amino acid. Each tRNA molecule is linked to its correct amino acid by one of a group of enzymes called aminoacyl tRNA synthetases. At least one type of aminoacyl tRNA synthetase exists for each of the 20 amino acids.
The anticodon site is a trinucleotide tRNA sequence that is complementary to the mRNA codon. The anticodon site recognises the mRNA codon (trinucleotide sequence) that defines the order of amino acids in a protein. Codon and anticodon bind during the process of DNA translation
Of the 64 possible mRNA codons - or triplet combinations of A, U, G and C - 3 specify the termination of protein synthesis and 61 specify the addition of amino acids to the polypeptide chain. Of these 61, only 1 codon (AUG) encodes the initiation of translation
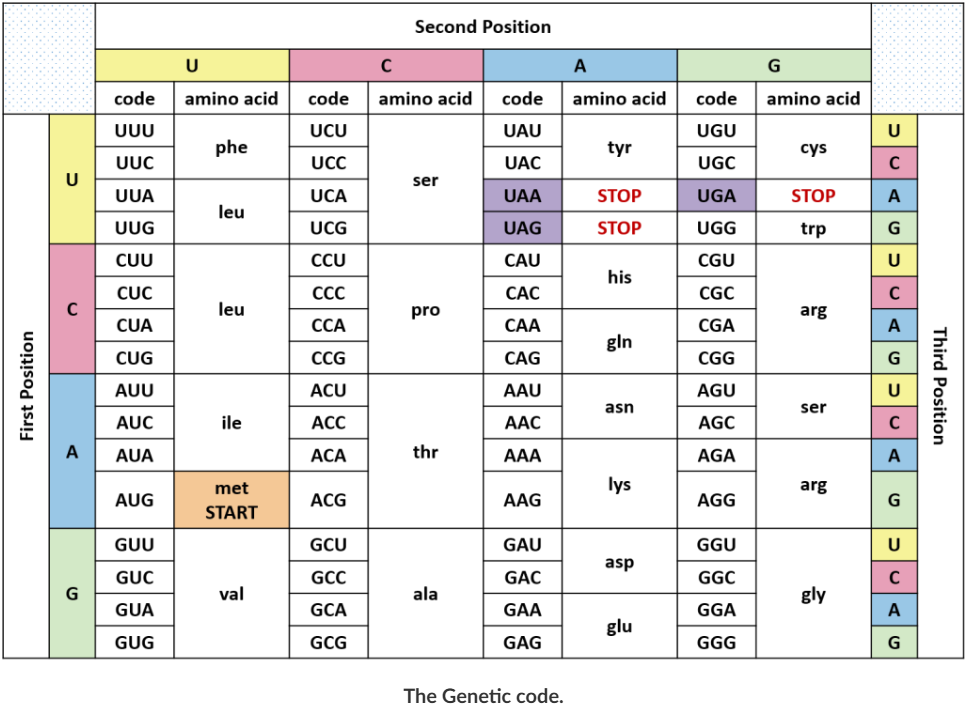
ribosomes - component of translation
The tRNAs bind and transfer amino acids to the ribosomes during the process of translation. They exist in the cytosol of prokaryotes and the cytosol and rER of eukaryotes
ribosomes dissociate into large and small subunits when they are not synthesising proteins and reassociate during the initiation of translation
these ribosomes are molecular machines that take an mRNA sequence, “read” the codons and produce a polypeptide chain from the amino acids carried by the tRNA that bind to the mRNA template
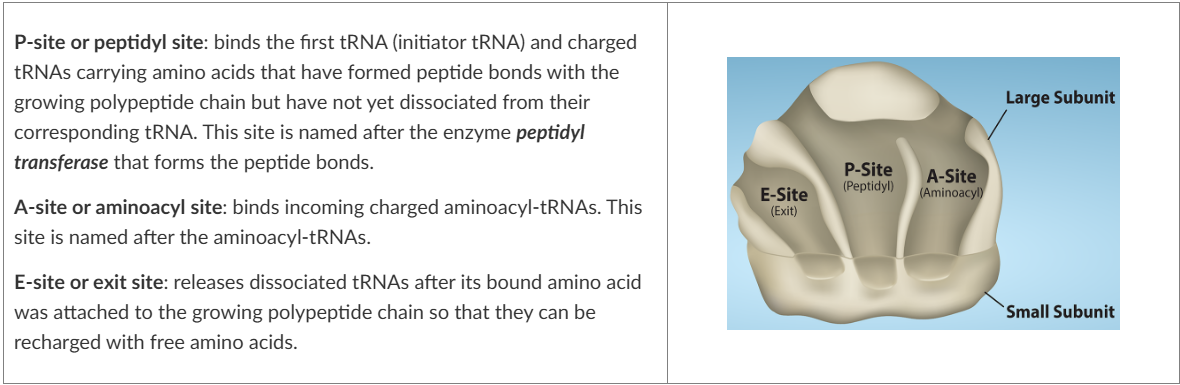
the small subunit is responsible for binding the mRNA template, whereas the large subunit sequentially binds tRNAs. Ribosomes have 3 binding sites for tRNAs (see image)
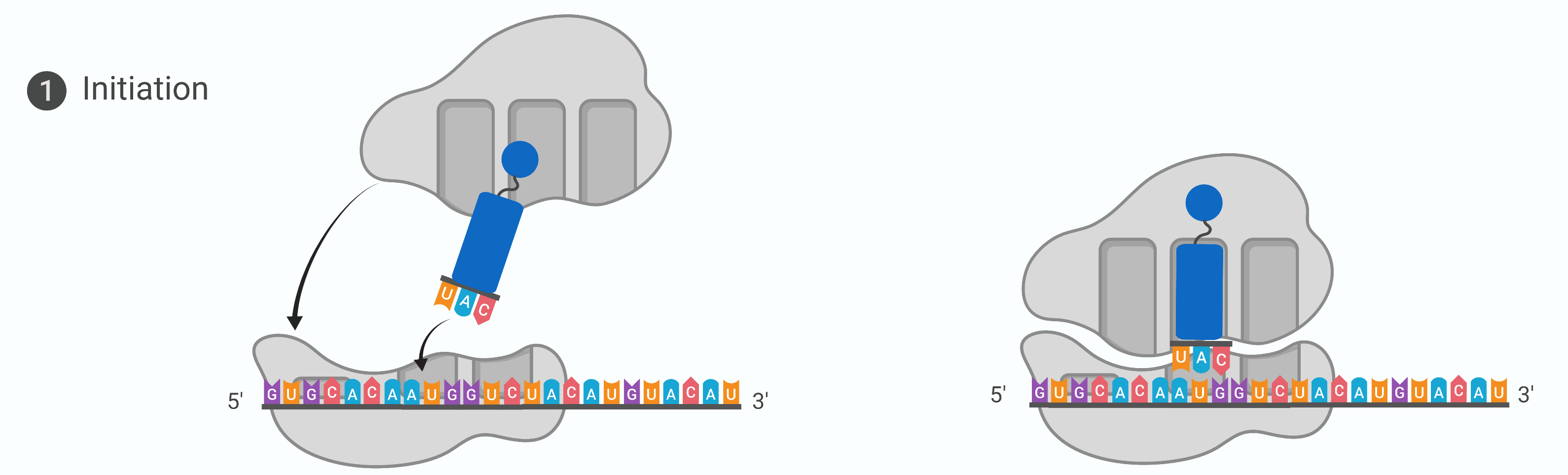
Stage 1: Initiation (process of translation)
protein synthesis begins with the formation of an initiation complex. The first tRNA, or the initiator tRNA, always carries methionine and binds to the small ribosomal subunit
together this complex binds to the mRNA interacts with the start codon AUG. The large ribosomal subunit joins the complex at the start codon and the initiation complex is complete
Stage 2: Elongation (translation)
At the start of elongation, the initiator tRNA carrying methionine occupies the P-site. A tRNA with another amino acid that is complementary to the next codon binds to the A-site
The enzyme peptidyl transferase catalyses the formation of a peptide bond between the two amino acids. The tRNA that occupies the E-site no longer has an amino acid bound to it and leaves the ribosome
Elongation proceeds with charged tRNAs sequentially entering via the A-site and leaving the ribosome via the E-site as each new amino acid is added to the growing polypeptide chain at the P-site
movement of a tRNA from A-site to P-site to E-site is induced by conformational changes that advance the ribosome by 3 bases (reading frame) in the 3’ end of the mRNA. This process by which the ribosome slides down the mRNA so a new cycle of elongation can begin is called translocation
The elongation factors provide the energy for each step along the ribosome via GTP hydrolysis. GTP energy is required both for the binding of a new-aminoacyl-tRNA to the A-site and for its translocation to the P-site after formation of the peptide bond
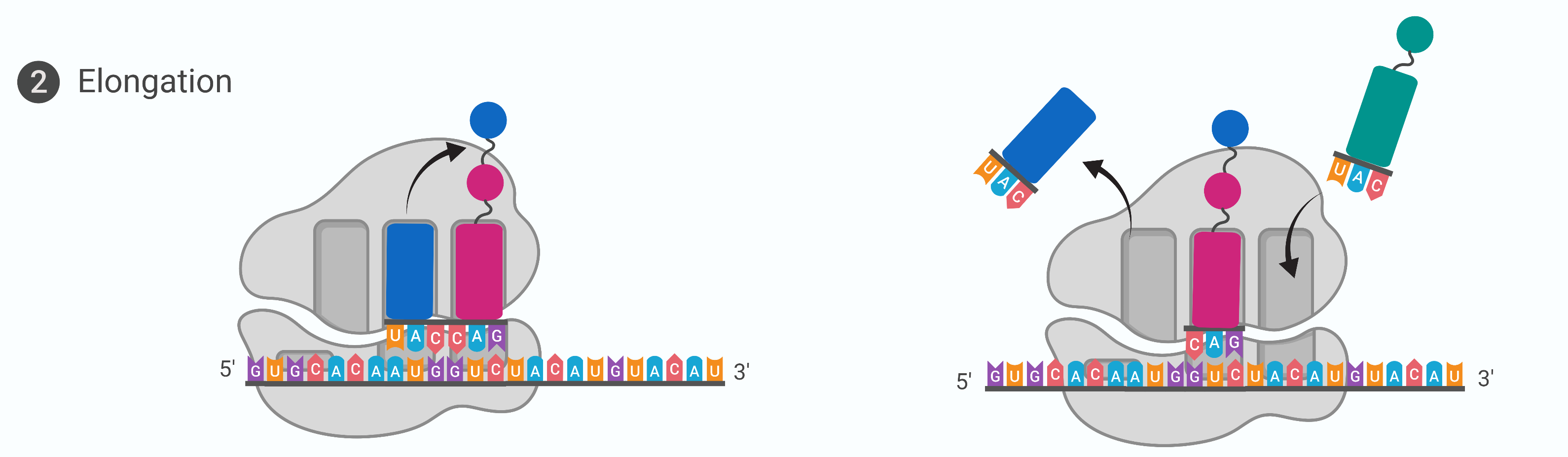
Stage 3: Termination (translation)
The elongation of the growing polypeptide is terminated when one of the 3 stop codons, UAA, UAG or UGA at the 3’ end of the mRNA enters the A-site of the ribosome
These stop codons are recognised by protein release factors that resemble tRNAs. The release factor initiates the hydrolysis of the last amino acid in the polypeptide chain. These reaction forces the P-site amino acid chain to detach from the tRNA, and the new synthesised polypeptide is released
The polypeptide undergoes further processing and folding in the Golgi apparatus to form a finished protein. The small and large ribosomal subunits dissociate from the mRNA and each other; they are almost immediately into another translation initiation complex. The mRNA is degraded so the nucleotides can be reused in another transcription reaction
mutations
the changes in the sequence of nucleotides on a DNA molecule the occur apart from the genetic recombination
causes of mutations:
mutations can occur due to errors during DNA replication (spontaneous mutation) or due to physical damage to the DNA (induced or non-spontaneous mutation)
nature of mutations:
can occur during the DNA replication that precedes meiosis. This can be transmitted to the next generation of individuals and is called germline mutation
can also occur during DNA replication before a mitotic cell division. This type of mutation affects only cells that descend from an altered cell and cannot be passed to the next gen of individuals. This is called somatic mutation
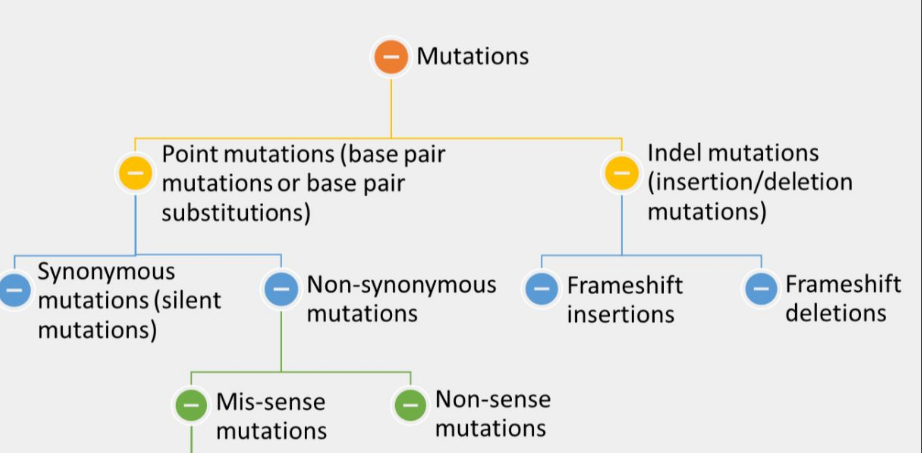
types of mutations
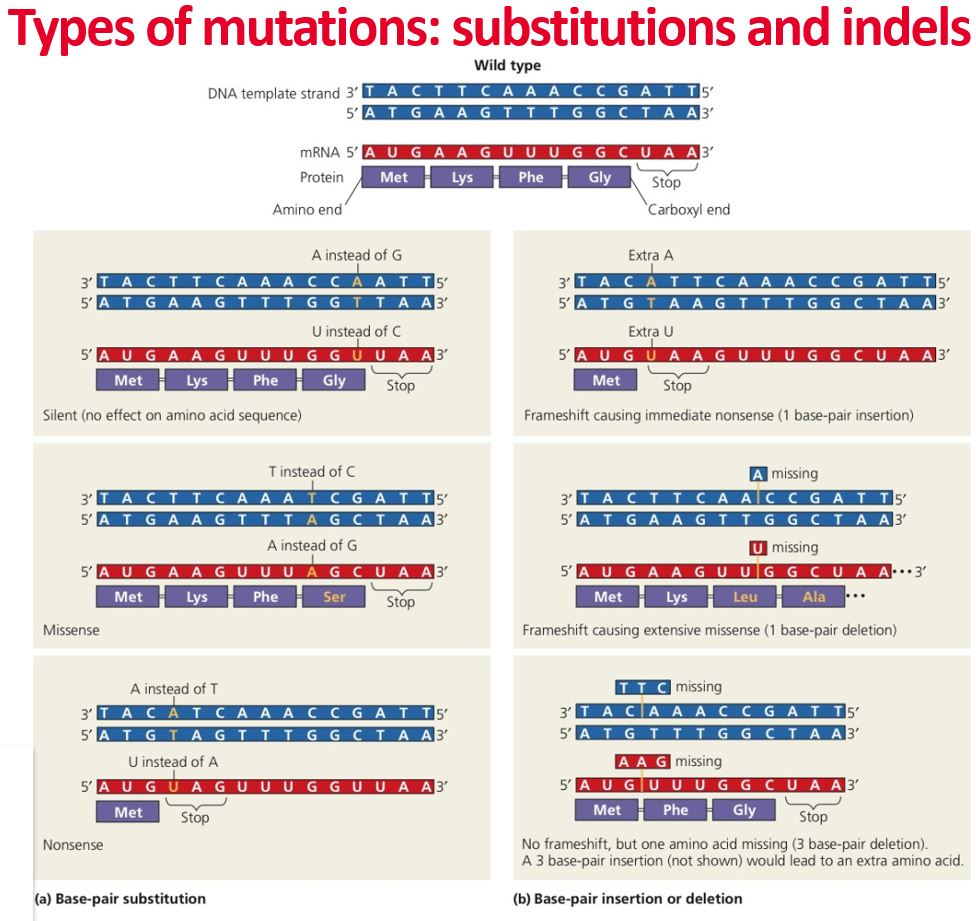
one way of grouping is to determine what type of N-base is changed by this mutation, thus transition mutation and transversion mutation
Other ways are whether they remove, alter or add the nucleotides (substitutions and indel mutations) or alter the functions (loss of function mutation is often referred to as recessive mutation and gain of function often referred to as dominant mutation) or late the structure of the DNA (point mutation and indel mutation)
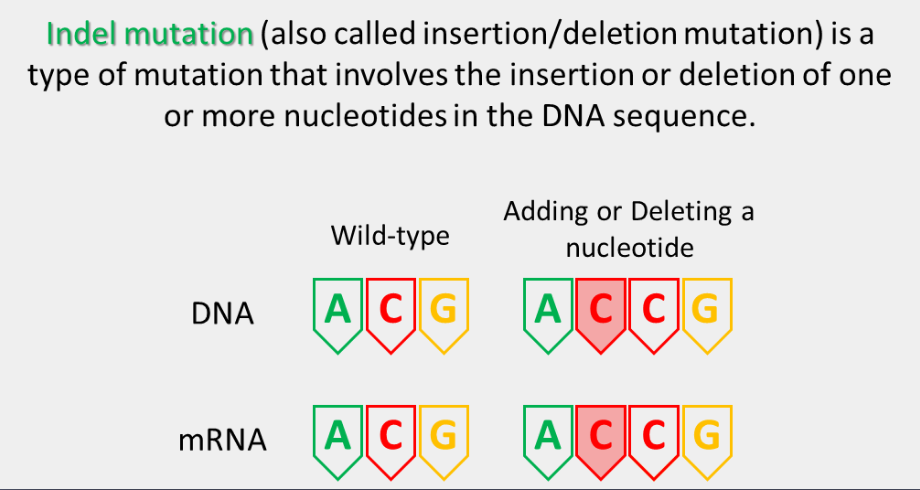
The structural changes that remove (deletion mutation) or add (insertion mutation) the nucleotides (indel mutations) can be further grouped as frameshift mutations and non-frameshift mutations
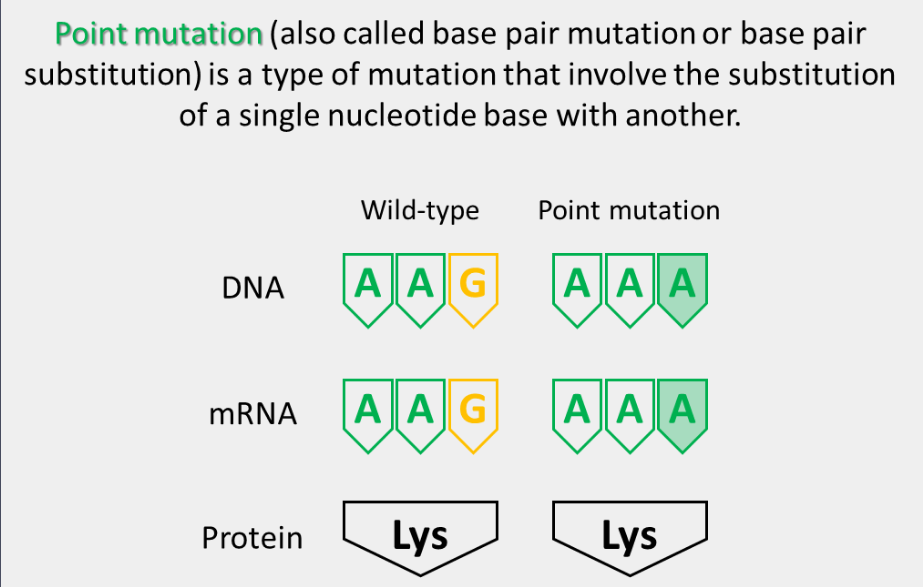
point mutation
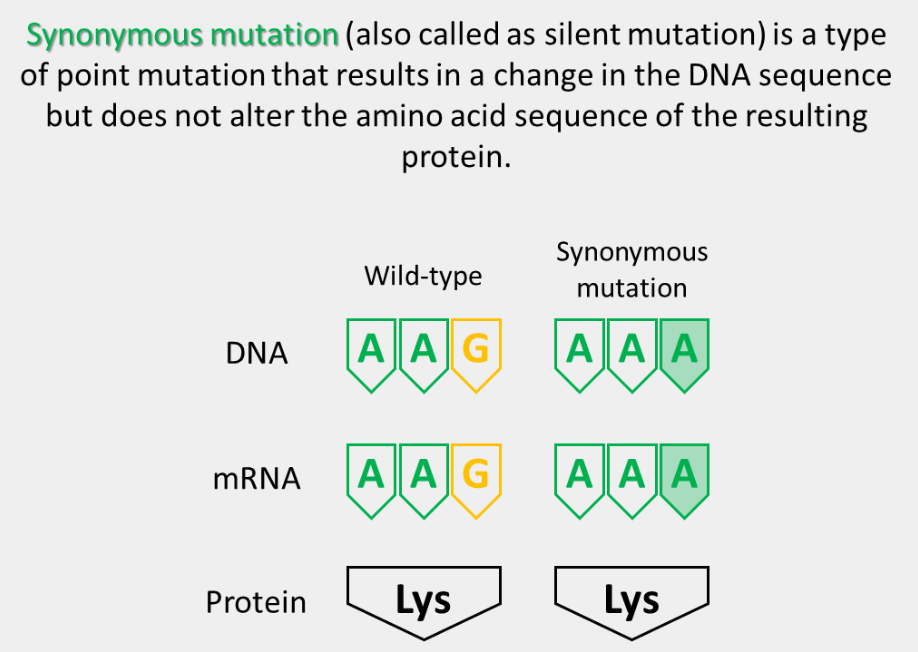
synonymous mutation
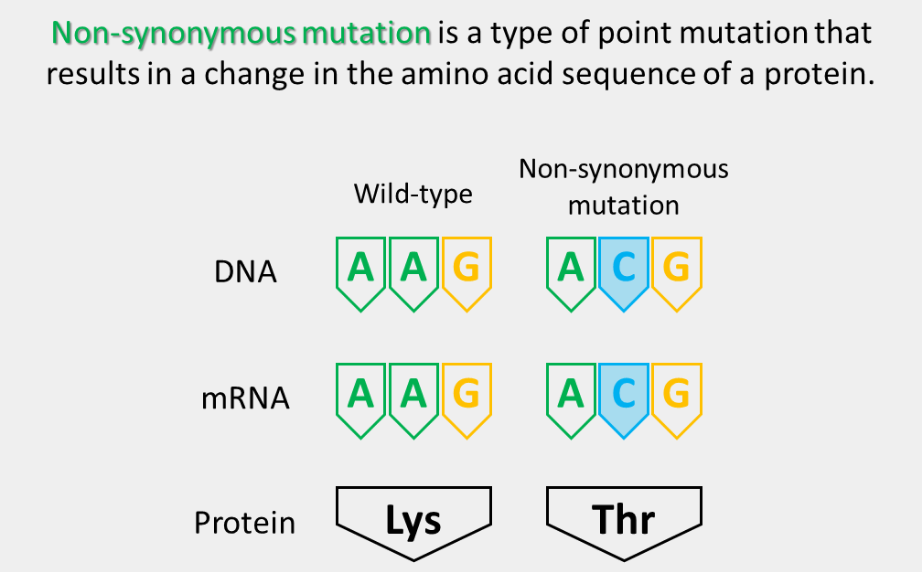
non-synonymous mutation
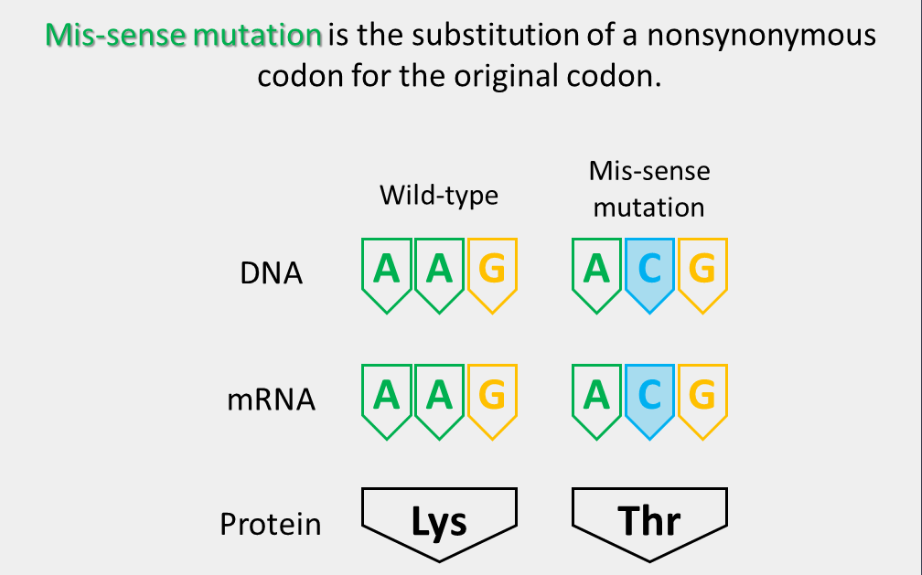
mis-sense mutation
conservative missense mutation

nonconservative missense mutation
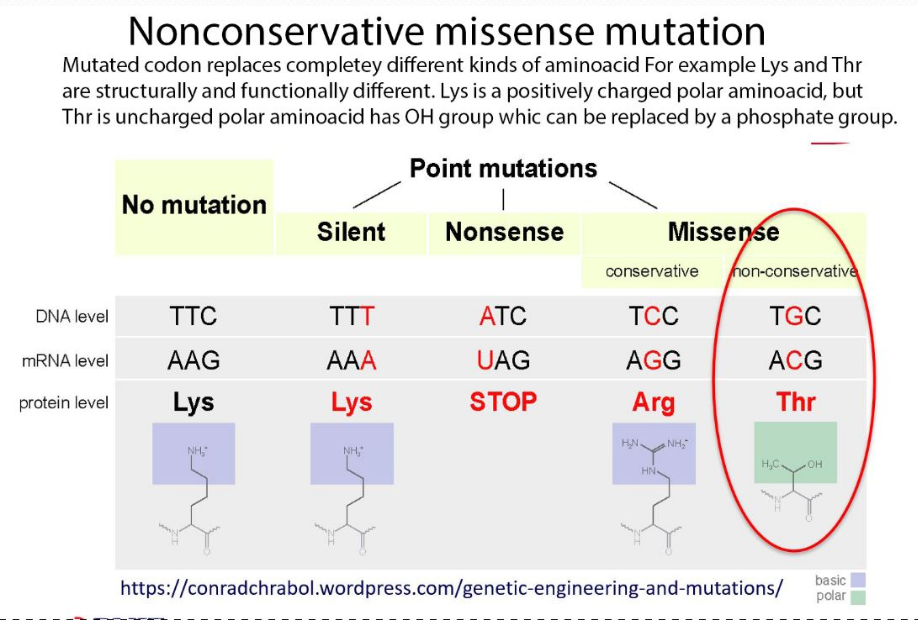
summary of missense mutations
The substitution of a nonsynonymous codon for the original codon. These can either be a conservative missense mutation or a nonconservative missense mutation
conservative missense mutation alters the codon that replaces the amino acid with a function and shape similar to the amino acid being replaced. Although a conservative missense mutation may result in loss of function, it may only be minor due to similar amino acids being replaced
nonconservative missense mutation alters the codon that replaces the entirely different kinds of amino acids and causes a change in the structure and function of the protein, which can have various effects, depending on the importance of the affected amino acid for the protein’s regular activity
non-sense mutation

summary of non-synonymous mutations
Mis-sense and non-sense mutations together make up the non-synonymous mutations. While mis-sense mutations alter the amino acids in a protein (further altering their structure and function), nonsense mutations cause the termination of protein synthesis.
summary of point mutations
Point mutations can result in various effects on the genetic information encoded by the DNA, depending on the specific location and type of mutation.
Point mutations can have various effects on the normal functioning of an organism, ranging from no effect to severe phenotypic consequences such as genetic disorders or increased risk of disease.
indel mutation
frameshift insertion
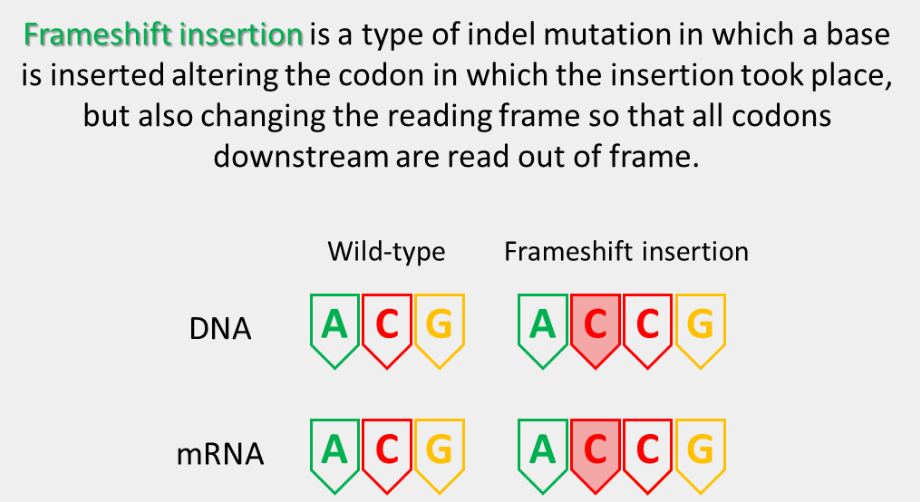
frameshift deletion
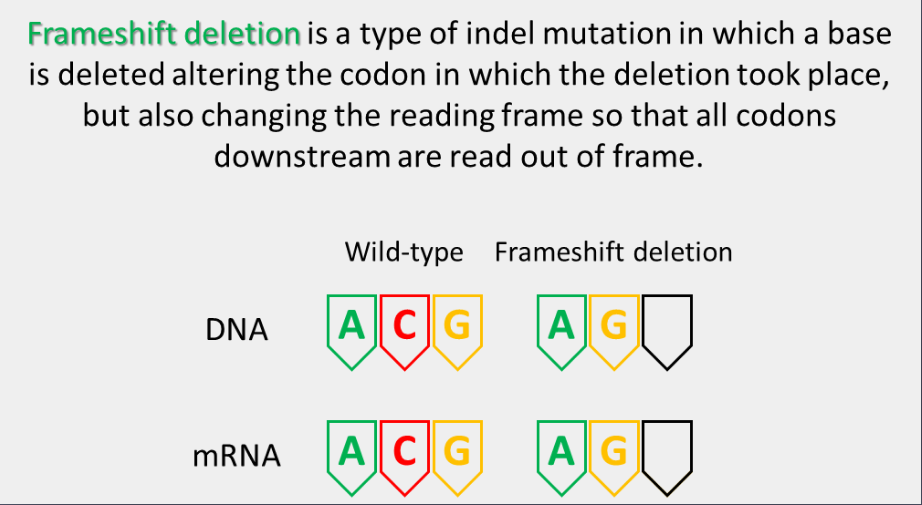
spontaneous mutation
results from errors in DNA replication
induced mutation (non-spontaneous mutation)
caused by mutagens such as X-rays, UV rays or alkyating agents
summary of types of mutations
favourable mutations
a genetic change that provides an advantage to the organism, allowing it to better survive and reproduce in its environment
Note: Mutations can be favourable, deleterious, or neutral. Let's look at some examples - remember, there are many, though!
neural mutations
has no significant effect on an organism’s fitness
these mutations may occur in non-coding regions of DNA, or they may occur in a coding region of DNA, but they result in a silent change in the protein sequence that does not affect its function
These mutations may accumulate over time in a population without affecting the overall fitness of the individuals carrying them