Interview - System Design
1/123
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
124 Terms
What is vertical scaling?
Vertical scaling means adding more resources to a single machine (CPU, RAM, storage).
Pros
Simple to implement — no distribution or sharding logic needed.
Cons:
Hardware ceiling
single point of failure.
What is a db connection pool, and what are its pros and cons?
A connection pool is a cache of open database connections that can be reused by requests instead of opening/closing new ones each time.
Pros: reduces connection overhead, improves latency, caps concurrent connections to protect the DB, smooths performance under load.
Cons: misconfigured pool can cause waits (too small) or overload DB (too large); idle connections may waste resources if not timed out.
What is horizontal scaling?
Horizontal scaling means adding more machines to handle load.
Pros:
Improves capacity and resilience
Cons:
Distributed state and no clock
Load balancing
What is ACID?
Typically for Relational databases
Atomicity, Consistency, Isolation, Durability
Atomicity: Ensures that all parts of a transaction are completed; if one part fails, the entire transaction fails and the database state is left unchanged.
Consistency: Guarantees that a transaction will bring the database from one valid state to another, maintaining database integrity.
Isolation: Ensures that multiple transactions occurring at the same time do not impact each other's execution.
Durability: Once a transaction is committed, it will remain so, even in the event of a system failure.

What is BASE?
Typically for NoSQL:
Basic Availability
The database appears to work most of the time.
Soft-state
Stores don't have to be write-consistent, nor do different replicas have to be mutually consistent all the time.
Eventual consistency
Stores exhibit consistency at some later point (e.g., lazily at read time).
What are 2 main reasons to use relational database?
Relational DBs are best when strong consistency and relationships matter.
They support complex queries (joins, aggregations) and enforce schema constraints.They can now handle unstructured data in the form of JSONB.
They excel in transactional workloads where data integrity is critical (e.g., banking, inventory).
Trade-off: harder to scale horizontally compared to NoSQL.
What are 2 main reasons to use NoSQL database?
NoSQL is best when you need largely unstructured data or high write throughput.
(High read throughput on relational can be supported by read replicas)
Supports unstructured/semi-structured data and large-scale horizontal partitioning.
Often chosen for event streams, analytics, or web-scale apps.
Trade-off: weaker guarantees (eventual consistency, limited query flexibility).
What are the 5 steps to solving a problem in a system design interview?
Functional requirements ( First 2 mins ):
What are the main actions the users will be allowed to make
Non Functional requirements
Scale, latency, consistency, availability
API Design
Core entities - Eg. user, file, image, tweet
API or dataflow - Write out endpoints or flow
High level design
Server
Database
ObjectStore
Performance
Discuss bottlenecks and solutions
Reliability
Discuss points of failure and solutions
What is replication? What are the two modes?
Replication makes copies of data across multiple machines.
Two main modes: synchronous (safe but slower) and asynchronous (faster but may lag).
Pros: high availability, durability, and read scaling.
Cons: Needs a failover mechanism or consensus to avoid conflicts.
What is strong consistency?
Strong consistency: after a successful write, all subsequent reads return that value. "Read after write consistency"
In distributed systems, this means a client can query any node and get the latest data.
Guarantees correctness but may increase latency during replication.
Weaker models (eventual consistency, causal) relax this guarantee.
What is eventual consistency?
A model for database consistency in which updates to the database will propagate through the system so that all data copies will be consistent eventually.
What is availability?
In terms of system design, this is usually a tradeoff with consistency. If availability > consistency, it means it’s more important that users are able to read some data, than if that data is exactly consistent with the most recent write to the data.
In the context of a database cluster, it refers to the ability to always respond to queries ( read or write ) irrespective of nodes going down.
What is partition tolerance
Partition tolerance means a system keeps operating despite message loss or delay between nodes.
It’s required in any distributed system spanning networks.
With partitions, you must choose between consistency and availability (CAP).
Designers often build retry/backoff logic to recover gracefully.
What is sharding?
Partitions very large databases the into smaller, faster, more easily managed parts called data shards.
Each shard holds a subset of rows, usually chosen by consistent hashing or ranges.
Common shard keys: user id, geo region or ranges
Pros:
Reduces the index size, improved search performance.
Less load per database, less memory per database.
Cons:
Addition or deletion of nodes from system will require some rebalance.
Cross-shard join queries will hurt performance badly. Must know how data will be queried.
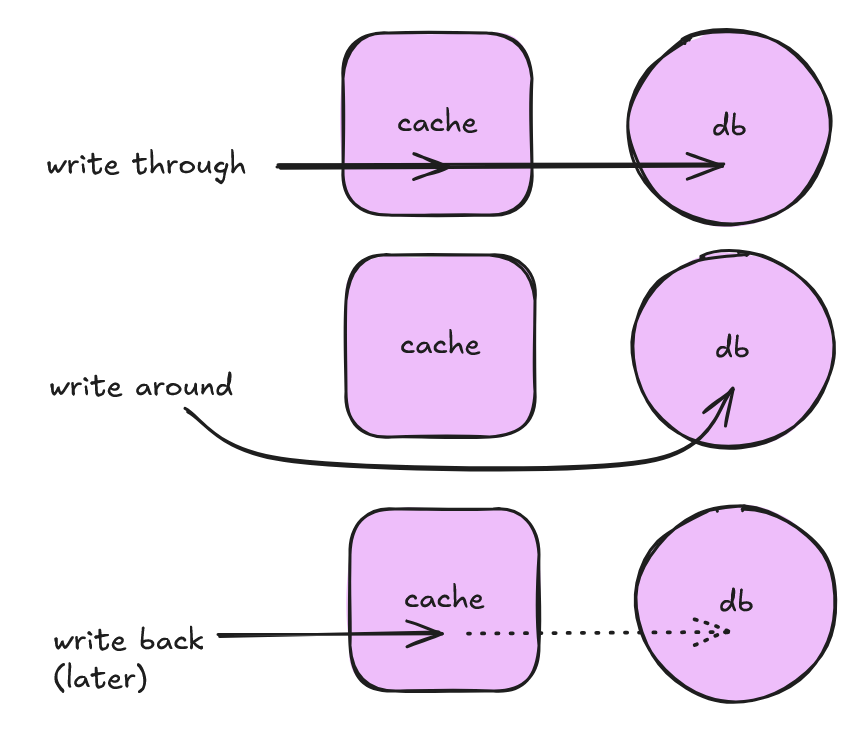
Write path - what are write-through, write-around and write-back cache?
t-cache
Write through, write around, write back.
mnem: write back = write back later
Write-through cache : Write to cache AND DB.
This is a caching system where writes go through the cache and write is confirmed as success only if writes to DB and the cache BOTH succeed. Strong consistency but slower writes as there are writes to 2 separate systems.
Write-around cache : Write to DB only, invalidate cache entry.
The cache system reads the information from DB in case of a miss. Faster writes, but slower reads in case of applications which write and re-read the information quickly.
Write-back (write-behind) cache : Write to cache only. Eventually write to db.
The write is confirmed as soon as the write to the cache completes. The cache then asynchronously syncs this write to the DB. Really fast writes and high write throughput. But risk of losing the data in case the caching layer dies. Some techniques to mitigate by replicating cache.
What is a cluster?
Generally, a cluster is group of computer machines that can individually run a software. Clusters are typically utilized to achieve high availability for a server or database.
Note - cluster can also mean running multiple servers that coordinate to appear as a single logical system. But a managed version may hide the complexity from user.
Pros:
improves high availability — if one node fails, others keep serving requests.
Allows horizontal scaling of workloads across nodes.
Cons:
Adds complexity - needs coordination, state management and failover logic
What Is Load Balancing?
Name 3 algos, and two main types of LB.
Load balancing distributes traffic across multiple servers to avoid overload.
Algorithms include round-robin, least-connections, and consistent hashing.
Load balancers also do health checks and reroute traffic from failed nodes.
Used at multiple layers:
L4 (TCP/UDP): balances based on IP/port; fast and generic; can’t see HTTP headers or cookies.(streaming video, gaming)
L7 (HTTP/HTTPS): balances based on request content (path, host, cookies, headers); supports smarter routing. (microservices)
What Is Fail Over?
Failover is the automatic switch to a backup when a node fails.
Can happen at the DB, app, or infra layer (via load balancers, DNS, or cluster managers).
Key concerns: how fast failures are detected, how safe promotion is, and how clients reconnect.
Goal: reduce downtime without introducing split-brain or data loss.
What is SOLID?
S.O.L.I.D is an acronym for the first five object-oriented design (OOD) principles by Robert C. Martin.
S - Single-responsiblity principle. A class should have one and only one reason to change, meaning that a class should have only one job.
O - Open-closed principle. Objects or entities should be open for extension, but closed for modification.
L - Liskov substitution principle. Let q(x) be a property provable about objects of x of type T. Then q(y) should be provable for objects y of type S where S is a subtype of T.
I - Interface segregation principle. A client should never be forced to implement an interface that it doesn't use or clients shouldn't be forced to depend on methods they do not use.
D - Dependency Inversion Principle. Entities must depend on abstractions not on concretions. It states that the high level module must not depend on the low level module, but they should depend on abstractions.
Explain Blue-Green Deployment Technique
Blue-green deployment is an alternate to trad staging + prod, where you have two identical production environments called Blue and Green. And one is staging, the other is prod, but then you switch at deployment.
At any time, only one of the environments is live, with the live environment serving all production traffic. For this example, Blue is currently live and Green is idle.
As you prepare a new version of your software, deployment and the final stage of testing takes place in the environment that is not live: in this example, Green. Once you have deployed and fully tested the software in Green, you switch the router so all incoming requests now go to Green instead of Blue. Green is now live, and Blue is idle.
This technique can eliminate downtime due to application deployment. In addition, blue-green deployment reduces risk: if something unexpected happens with your new version on Green, you can immediately roll back to the last version by switching back to Blue.
What Is IP Address Affinity Technique For Load Balancing?
IP address affinity is another popular way to do load balancing. In this approach, the client IP address is associated with a server node. All requests from a client IP address are served by one server node.
This approach can be really easy to implement since IP address is always available in a HTTP request header and no additional settings need to be performed. This type of load balancing can be useful if you clients are likely to have disabled cookies.
However there is a down side of this approach. If many of your users are behind a NATed IP address then all of them will end up using the same server node. This may cause uneven load on your server nodes. NATed IP address is really common, in fact anytime you are browsing from a office network its likely that you and all your coworkers are using same NATed IP address.
What is a distributed system?
A collection of independent computers that appear as a single, cohesive system.
These machines have a shared state, operate concurrently and can fail independently without affecting the whole system's uptime.
Pros: Availability, Fault tolerance
What is a stateless application?
Statelessness defines whether or not a computation is designed to depend on one or more preceding events in a sequence of interactions.
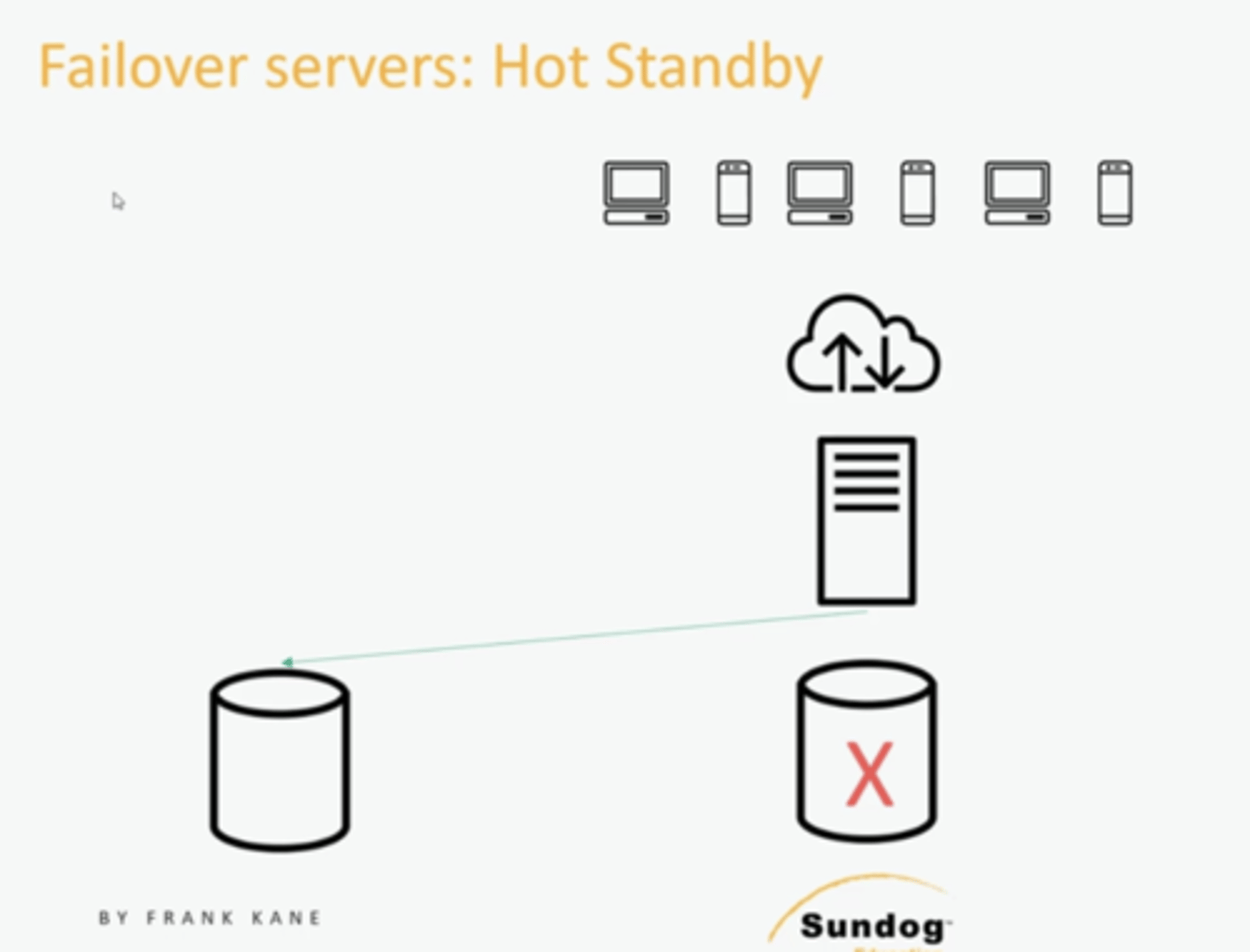
What are 3 failover strategies?
Warm standby - replication (usually automatic) but then failover to the new server
Hot standby - We're going to be writing that data simultaneously to all the different backup databases.
Cold standby - tape backup periodically
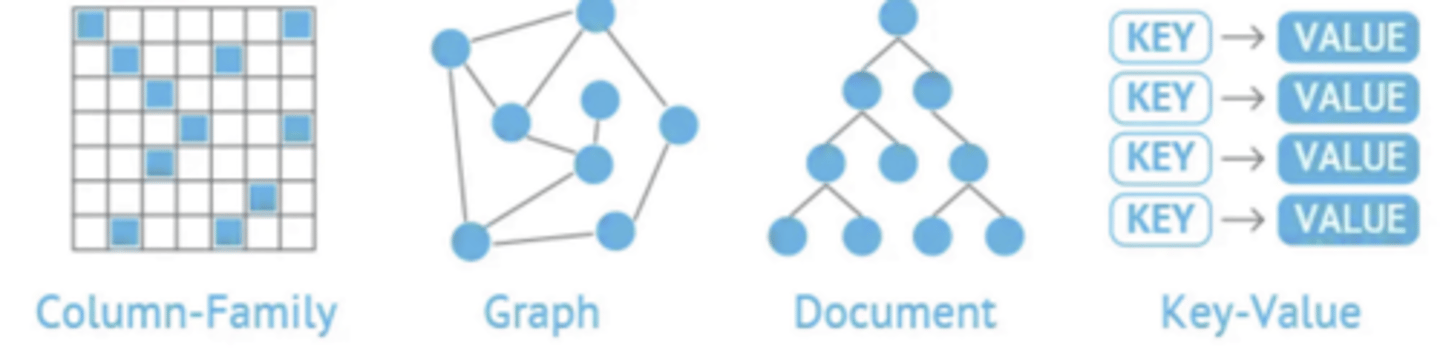
What are some types of NoSQL databases
NoSQL systems store data in various formats, such as key-value, document, wide-column, or graph.
NoSQL databases are a diverse group of non-relational databases that prioritize flexibility, scalability, and performance under specific workloads.
NoSQL databases are known for their ability to scale horizontally and handle unstructured or semi-structured data.
What are 5 differences between SQL and NoSQL databases?
1. Storage - tables vs key-value store, document or schema
2. Schema - fixed vs flexible
3. Querying - SQL vs other
4. Scalability - vertical vs horizontal
4. Reliability - ACID vs not.
What are DDL, DML, DQL, DCL
Data Definition Language - Defines and modifies the database's structure (schema), such as CREATE and DROP
Data Manipulation Language - Enables data changes in database tables. INSERT, UPDATE, DELETE
Data Query Language - Querying such as SELECT
Data Control Language - Deals with user permissions and access control for database objects GRANT and REVOKE
What is a TCL?
Transaction Control Language manages sequences of commands as transactions where all of the commands run or, none run.
Ensures ACID compliance.
What is Amazon DynamoDB?
Amazon DynamoDB is a NoSQL database service that's part of Amazon Web Services. It's a fully managed, serverless database that supports key-value and document data models.
Known for low latencies and scalability.
What is Amazon Elasticache vs ElasticSearch?
t-cache
ElastiCache
AWS managed in-memory cache (Redis or Memcached).
Stores key-value pairs in RAM.
Used for:
Low-latency lookups (sessions, feature flags).
Reducing DB read load.
Real-time leaderboards/queues.
Data is typically ephemeral — if the node dies, data can be rebuilt from source of truth.
Elasticsearch / Amazon OpenSearch Service
AWS managed search + analytics engine (based on Lucene).
Stores JSON documents with inverted indexes for full-text search.
Used for:
Search bars, autocomplete, filtering.
Log/metrics analytics (ELK stack).
Complex queries with scoring, fuzzy match, aggregations.
Data is persistent and queryable with rich search features, not just key-value lookups.
What is Redis?
t-cache
Redis is an in-memory key-value data store, often used as a cache, queue, or pub/sub broker.
Supports rich structures (lists, sets, hashes, sorted sets).
Provides persistence (RDB snapshots, AOF logs) and high availability (Sentinel, Cluster).
Common pitfalls: hot keys, large values, eviction under memory pressure.
Methods include round robin, least-connections, and consistent hashing.
Improves scalability, availability, and tail latency.
Often implemented with hardware appliances, software proxies, or cloud-managed
What is MongoDB?
MongoDB is an open source, document DB that provides support for BSON (JSON-styled), document-oriented storage systems.
Pros:
Flexible data model enables you to store data of any structure.
High performance
supports horizontal scaling through sharding.
Cons:
Weaker consistency
Lack of joins
Less transaction support
What are document databases?
Document databases are structured similarly to key-value databases except that keys and values are stored in documents written in a markup language like JSON, BSON, XML, or YAML. Each document can contain nested fields, arrays, and other complex data structures, providing a high degree of flexibility in representing hierarchical and related data.
Use cases: User profiles, product catalogs, and content management.
Examples: MongoDB, Amazon DocumentDB, CouchDB.
What are wide column databases?
Wide column databases are based on tables but without a strict column format. Rows do not need a value in every column, and segments of rows and columns containing different data formats can be combined.
Use cases: Telemetry, analytics data, messaging, and time-series data.
Examples: Cassandra, Accumulo, Azure Table Storage, HBase.
What is Apache Cassandra?
A highly scalable, distributed column-family store that provides high availability and fault tolerance, designed for handling large-scale data across many commodity servers.
What are graph databases?
Graph databases map the relationships between data using nodes and edges. Nodes are the individual data values, and edges are the relationships between those values.
Use cases: Social graphs, recommendation engines, and fraud detection.
Examples: Neo4j, Amazon Neptune, Cosmos DB through Azure Gremlin
What is Neo4j?
A graph database that offers powerful query capabilities for traversing complex relationships and analyzing connected data.
What are time series databases?
These databases store data in time-ordered streams. Data is not sorted by value or id but by the time of collection, ingestion, or other timestamps included in the metadata.
Use cases: Industrial telemetry, DevOps, and Internet of Things (IOT) applications.
Examples: Graphite, Prometheus, Amazon Timestream.
What are ledger databases?
Ledger databases are based on logs that record events related to data values. These databases store data changes that are used to verify the integrity of data.
Use cases: Banking systems, registrations, supply chains, and systems of record.
Examples: Amazon Quantum Ledger Database (QLDB).
What is Fault tolerance?
What strategies do you use?
Fault tolerance is the ability of a system to continue functioning correctly in the presence of faults or failures.
Incorporating redundancy at various levels (data, services, nodes)
Replication, sharding, and load balancing to ensure that the system can withstand failures without impacting users or overall performance.
What is a subdomain? Say for blog.example.com
A subdomain is a subdivision of a domain name, allowing the creation of separate sections or areas within a website. Subdomains appear to the left of the main domain name, such as blog.example.com, where "blog" is the subdomain of example.com.
What are Root Servers in DNS system?
t-dns
Root servers are the highest level of DNS servers and are responsible for directing queries to the appropriate TLD servers.
Root servers (in an uncached search) will tell the resolver where to find the TLD, like the server that holds all the .com or .org entries.
Every DNS resolver has a list of the 13 IP root server addresses built in.
There are 13 root server clusters worldwide, (but 100s of actual servers) managed by various organizations, each having multiple servers for redundancy and reliability.
What is TLD? What are TLD Servers?
The TLD is the top level domain such as .com. ccTLDs are the country TLDs like .uk
TLD servers store information about domain names within their specific TLD. When they receive a query, they direct it to the appropriate authoritative name server responsible for that domain.
What are Authoritative name servers?
t-dns
These servers hold the actual DNS records for a domain, like google.com, including all its IP addresses and other information. They provide the final answer to DNS queries, allowing users to access the desired website or resource.
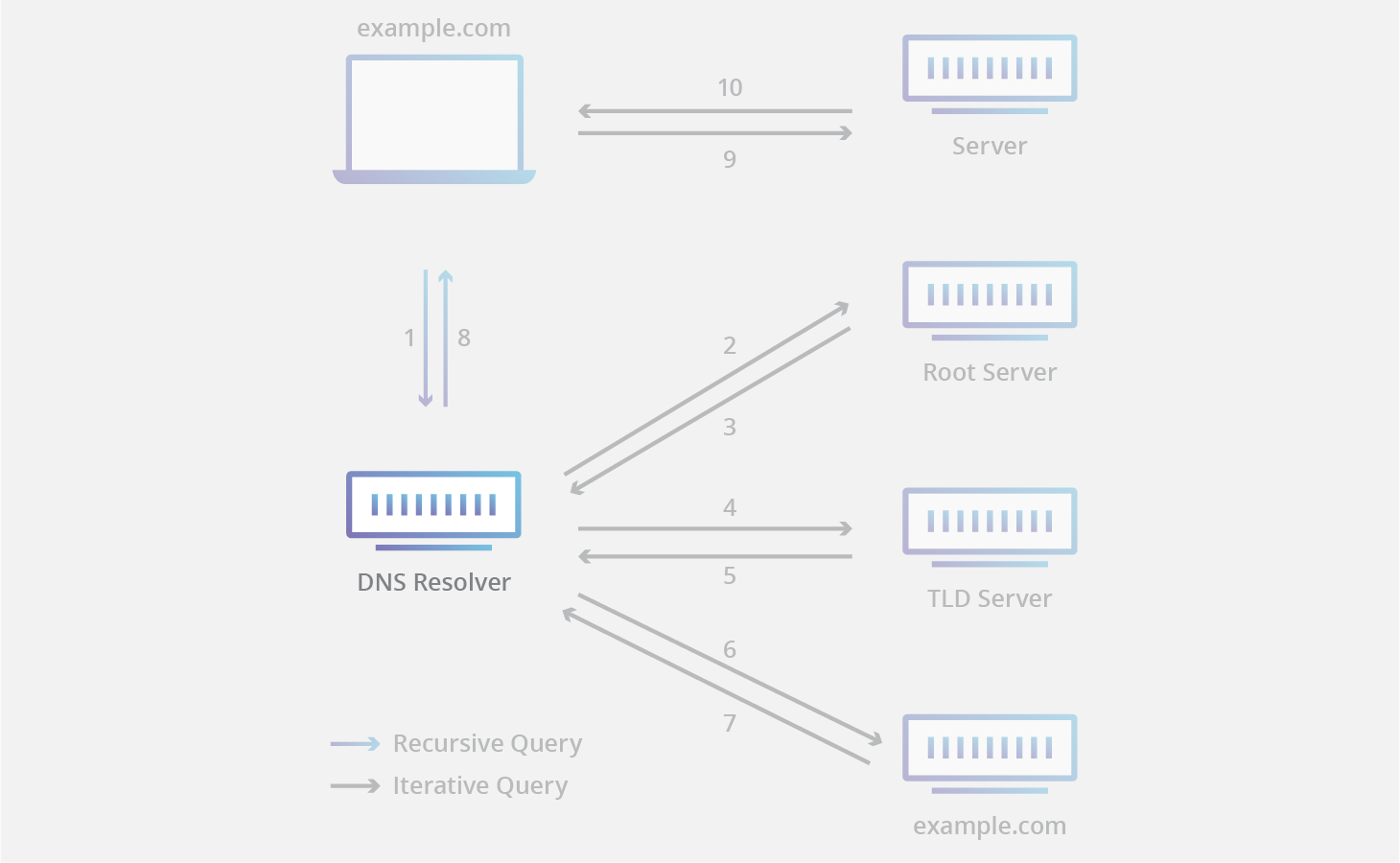
What are DNS recursive resolvers?
t-dns
DNS resolvers are usually provided by internet service providers (ISPs) or other organizations. They act as intermediaries between users and DNS servers, receiving DNS queries from users and sending them to the appropriate authorititative DNS servers to be resolved. Once the resolver receives the answer, it caches the information and returns it to the user.
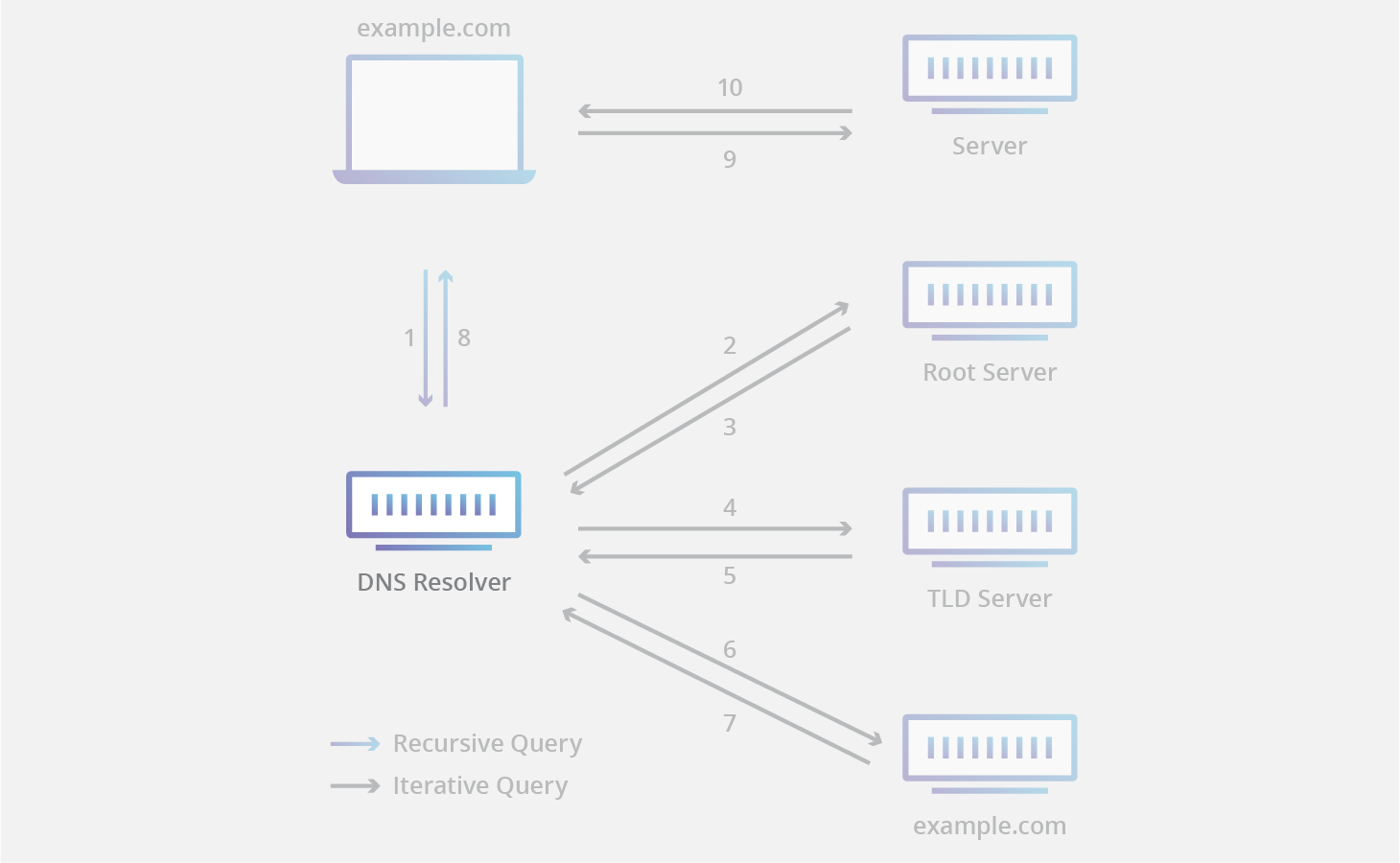
What is DNS TTL and how is it used?
t-dns
Resolvers and servers cache the results of previous queries.
Each DNS record has an associated Time To Live (TTL) value in seconds, which specifies how long the record should be stored in the cache. Once the TTL expires, the cached information is removed.
When a resolver receives a query, it first checks its cache to see if the answer is already available. If it finds the cached information, it returns the answer without contacting other servers, saving time and reducing network traffic.
What is a CDN?
t-cdn
A Content Delivery Network (CDN) is a network of distributed servers that cache and deliver web content to users based on their geographic location. CDNs help improve the performance, reliability, and security of websites and web services by distributing the load among multiple servers and serving content from the server closest to the user.
DNS plays a crucial role in the functioning of CDNs. When a user requests content from a website using a CDN, the CDN's DNS server determines the best server to deliver the content based on the user's location and other factors. The DNS server then responds with the IP address of the chosen server, allowing the user to access the content quickly and efficiently.
Name and describe 4 different "locations" for caching?
Caching can be implemented in various ways, including in-memory caching, disk caching, database caching, and CDN caching.
In-memory caching stores data in the main memory of the computer, which is faster to access than disk storage.
Disk caching stores data on the hard disk, which is slower than main memory but faster than retrieving data from a remote source.
Database caching stores frequently accessed data in the database itself, reducing the need to access external storage.
CDN caching stores data on a distributed network of servers, reducing the latency of accessing data from remote locations.
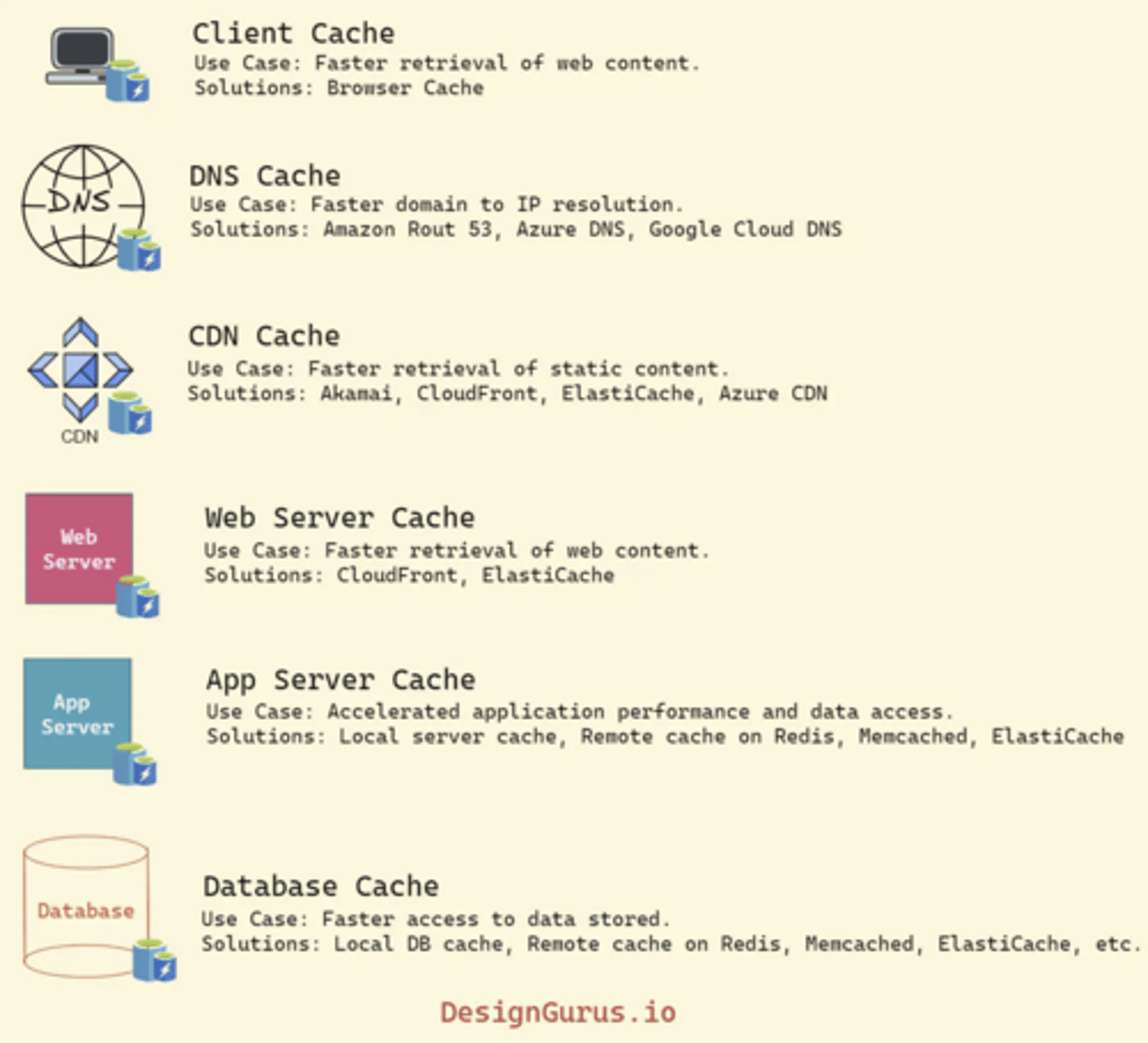
Name services used for in-memory caching?
t-cache
Memcached or Redis, or implementing custom caching logic within the application code.
AWS Elasticache is basically memcached or redis.
What are 4 different cache replacement policies?
t-cache
LRU - Least recently used
LFU - Least frequently used
FIFO - First in first out
Random - random replacement
LRU and LFU - more effective, needs data structures to track.
FIFO and random replacement - less effective, low complexity.
Must pick carefully to balance the trade-off between performance and complexity.
What are 5 cache invalidation requests?
t-cache
Purge - Updated content purges old cache entries
Refresh - Request to refresh content
Ban - Request to ban certain urls or patterns or headers
TTL expiration - When content is request, expired entries are refreshed before being returned.
Stale-while-revalidate - Similar to TTL but instead of waiting to return, return stale content, but also refresh entry.
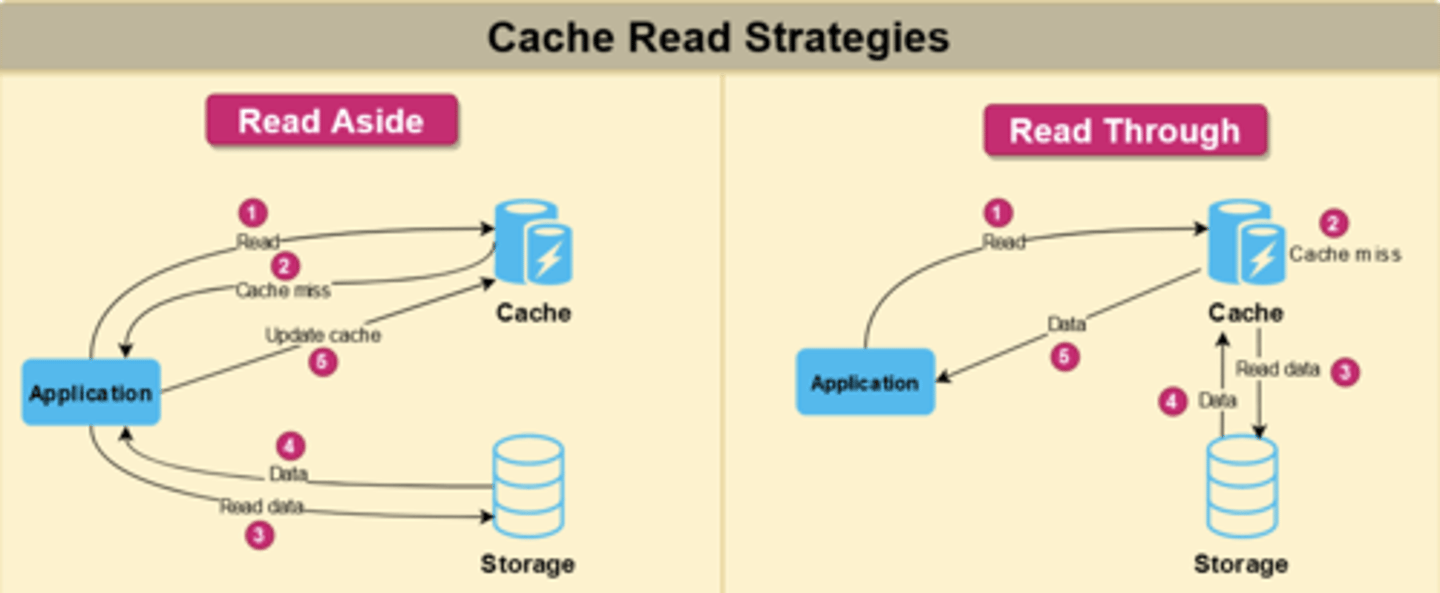
Read path: What is a read-through and read-aside (or cache-aside) cache?
t-cache
The difference is who fetches the DB on miss — app vs cache service.
Cache-aside (a.k.a. lazy loading, read-aside):
App looks in cache → if miss, app fetches from DB and updates cache.
Simple, common (Redis/Memcached raw)
First request is slow (cache miss).Read-through:
App always queries the cache; if miss, the cache itself fetches from DB and updates.
Transparent to app.
Requires smarter cache layer (Ehcache, caffeine, hazelcast).
CDNs behave like giant read through caches for content.
How do you estimate Traffic?
If you get for example, the # of reads per month is 500M
Traffic is estimated by calculation the queries per second.
If you get for example, the # of reads per month is 500M
Queries per second = 500M / (30 24 60 60) = 200 qps
Or simplify estimate 600M per month, 100,000 seconds a day.
So 600M per month
600M / 30 days = 20M per day
2 × 10^7 / 10^5 secs/day = 2 × 10² = 200 qps
Also calculate writes.
How do you estimate storage?
For e.g. if you have 500M writes per month and want to hold the data for 5 years.
Storage is estimated using total data per entry * total time expected to persist this data.
For e.g. if you have 500M writes per month and want to hold the data for 5 years. We estimate 500 bytes per entry.
5 × 10^8 writes/month x 5 × 10² bytes each
25 × 10^10 bytes/month × 10 months x 5 years
150 × 10^11 bytes = 15 × 10^12 = 15 TB
How do you estimate Bandwidth?
For e.g. if you have 200 writes per second for 500 byte entries
To estimate bandwidth, we want to calculate incoming and outgoing bytes/second
For e.g. if you have 200 writes per second for 500 byte entries
Incoming b/w = 200 w/s * 500 bytes = 100 KB/s
Also calculate outgoing.
Using base 64 encoding, expression for how many 6 character keys you can generate?
The answer would be 64^6
64^6 = ~68.7 billion possible strings.
What is the MD5 Hash?
MD5 takes an input message of arbitrary length and produces a fixed-size 128-bit (16-byte) hash value, typically represented as a 32-character hexadecimal number.
MD5 is fast, deterministic and not reversible.
Collision Vulnerability: MD5 is considered weak in security due to the possibility of hash collisions. Collisions occur when two different inputs produce the same hash value, which can be exploited by attackers.
Pseudo-Randomness: The hash output appears random, even for small changes in the input, which is crucial for spreading data distribution.
While it was widely used in the past, MD5 is now considered deprecated for security-critical applications. It's still used for non-security purposes like checksums and data integrity checks.
What is an edge server for CDNs?
t-cdn
An edge server refers to a server located geographically closer to the user requesting content. It is located at a PoP.
What is a Point of Presence for CDNs?
t-cdn
A PoP is a physical location where CDN servers are deployed, typically in data centers distributed across various geographical locations. PoPs are strategically placed close to end-users to minimize latency and improve content delivery performance.
What is an Origin Server for CDNs?
t-cdn
Primary server where the original content is stored. CDNs fetch content from the origin server and cache it on edge servers for faster delivery to end-users.
What is cache warming?
t-cache
Process of preloading content into the edge server's cache before it is requested by users, so content is available for fast delivery when needed.
What is Anycast?
t-dns t-cdn
Anycast: Anycast is a DNS network routing technique used by CDNs to direct user requests to the nearest available edge server, based on the lowest latency or the shortest network path.
In anycast routing, multiple edge servers share a single IP address. When a user sends a request to that IP address, the network's routing system directs the request to the nearest edge server based on network latency or the number of hops.
Anycast is also used to find a DNS root nameserver.
5 advantages of CDNs?
t-cdn
1. Reduced latency: By serving content from geographically distributed edge servers, CDNs reduce the time it takes for content to travel from the server to the user, resulting in faster page load times and improved user experience.
2. Improved performance: CDNs can offload static content delivery from the origin server, freeing up resources for dynamic content generation and reducing server load. This can lead to improved overall performance for web applications.
3. Enhanced reliability and availability: With multiple edge servers in different locations, CDNs can provide built-in redundancy and fault tolerance. If one server becomes unavailable, requests can be automatically rerouted to another server, ensuring continuous content delivery.
4. Scalability: CDNs can handle sudden traffic spikes and large volumes of concurrent requests, making it easier to scale web applications to handle growing traffic demands.
5. Security: Many CDNs offer additional security features, such as DDoS protection, Web Application Firewalls (WAF), and SSL/TLS termination at the edge, helping to safeguard web applications from various security threats.
How do CloudFlare, Fastly and CloudFront CDNs work?
t-cdn
First request: CDN "pulls" the content from the origin server when a user requests it similar to a read-through cache.
Subsequent requests: Once content cached on the CDN's edge server, it is served directly from the CDN, reducing the load on the origin server.
Expiry: When cached content expires or reaches its Time-to-Live (TTL), CDN will fetch the content again from the origin server.
Examples of Pull CDNs include Cloudflare, Fastly, and Amazon CloudFront.
Pros:
easy setup with minimal change to architecture
cdn handles expiration and cache management
origin server only accessed when content is not available on the cdn
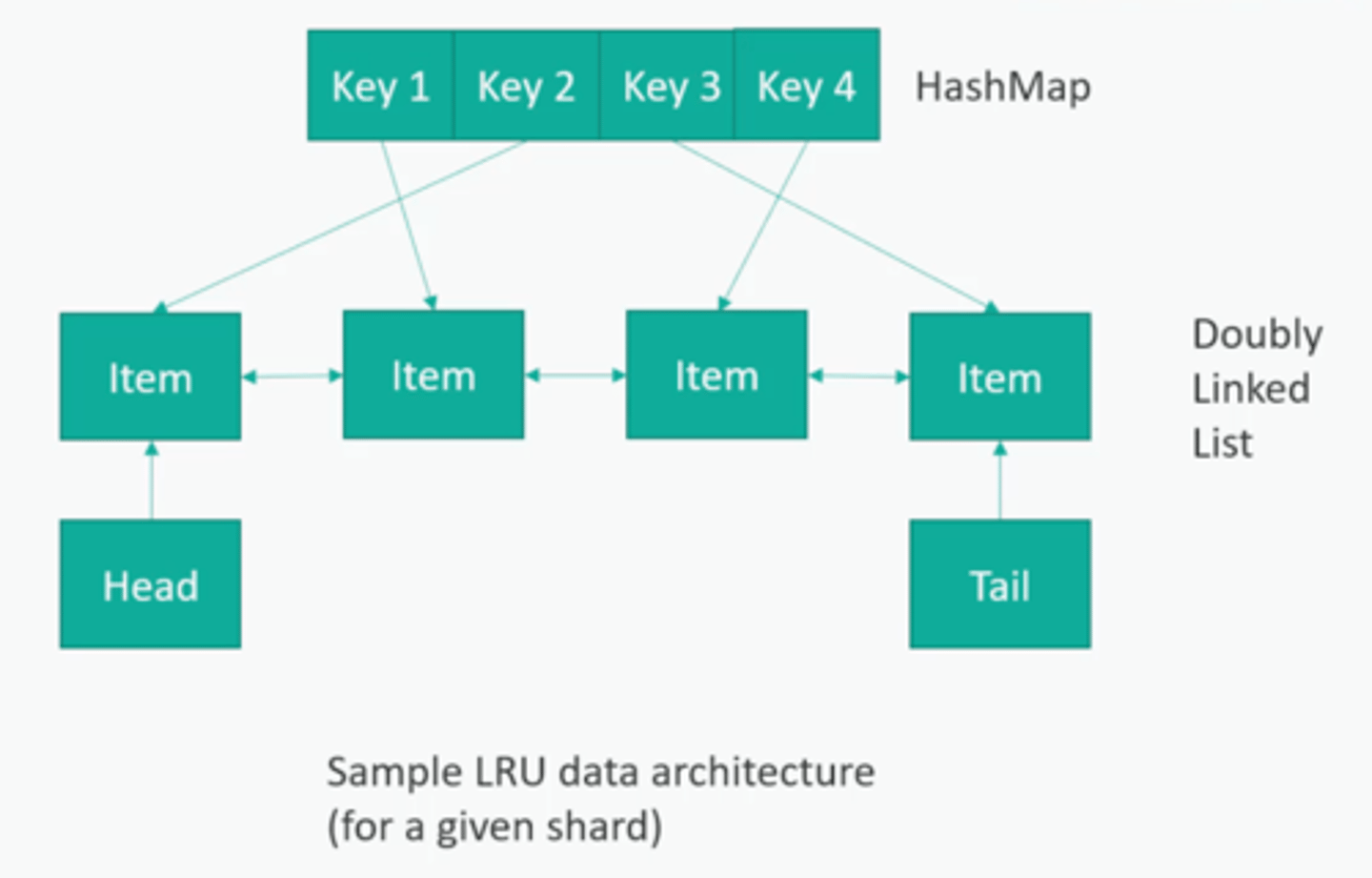
What could be a good datastructure for an LRU cache?
t-cache
Use a hashmap for key → pointer → data.
Then use a doubly linked list for the data. When you use a data item, disconnect it and move to head of list.
When you add data, keep a count, and delete the tail item if necessary.
What is memcached?
t-cache
Very simple in-memory key/value store. Open source, dead simple, been around forever.
What is elasticache?
t-cache
AWS managed in-memory cache (Redis or Memcached).
Stores key-value pairs in RAM.
Used for:
Low-latency lookups (sessions, feature flags).
Reducing DB read load.
Real-time leaderboards/queues.
Data is typically ephemeral — if the node dies, data can be rebuilt from source of truth.
How do you design the shards?
You want to organize the data
- design it so that you minimize sql joins or complex sql operations across shards
- try to make it so it's almost a basic key/value store
- hash that key to a given shard and try to read and write one customer's data to one shard.
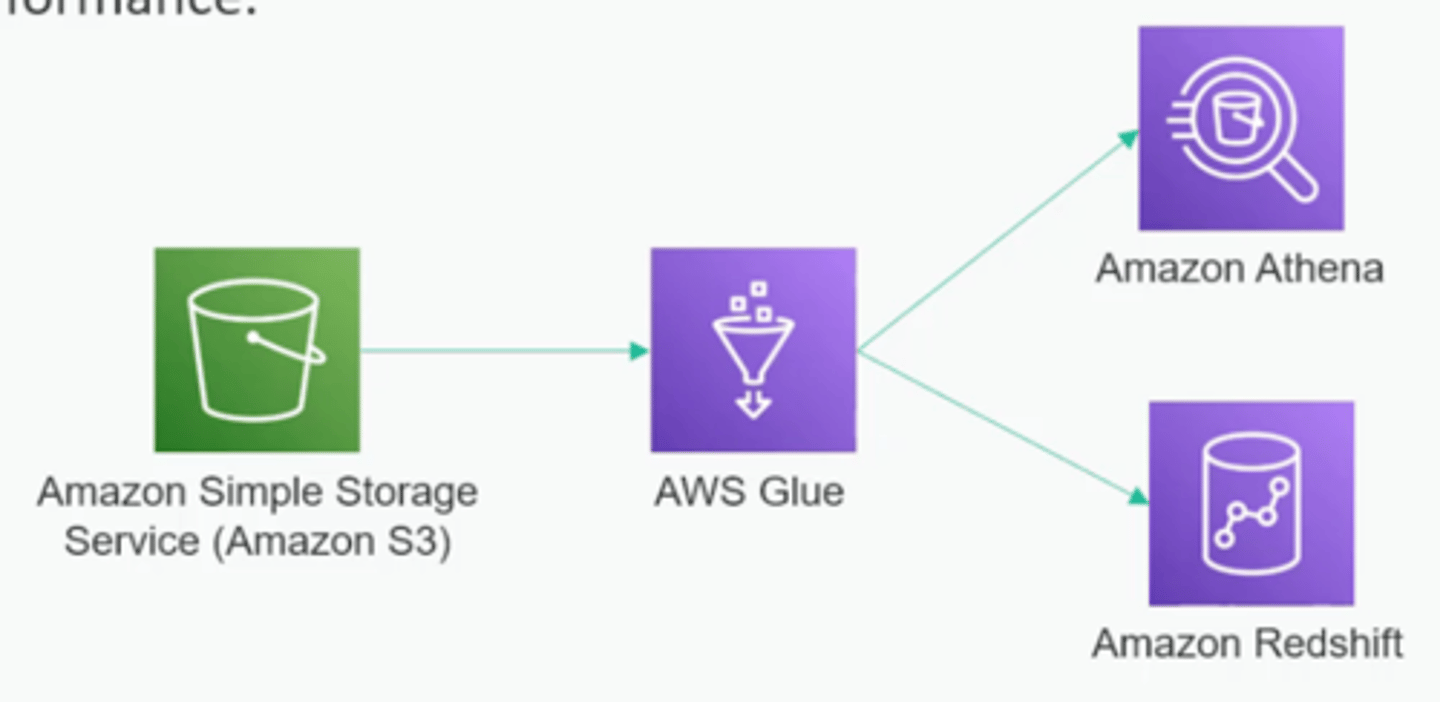
What is a datalake?
It's a way to just throw data into text files like csv or json into a big distributed storage system like Amazon S3.
This is called a data lake and it's common in the "big data" world.
Then you have a process that crawls that data, creates a schema
* Amazon Glue
And other cloud based features might let you query that data
* Amazon Athena
* Amazon Redshift
What's a reasonable ms for "low latency"
Depends on workload:
Interactive web apps: ~100–200 ms for user actions feels instant.
Non ui interactions: 500ms acceptable
Realtime apps (chat, gaming): 10–50 ms often needed.
Batch/analytics: seconds+ acceptable.
Interviewers want you to tie latency budgets to user experience and SLOs.
How does postgres handles indices?
B-tree (balanced tree) indexes are used by default for most data types.
They allow efficient sorting and range queries, not just equality.
They maintain sorted order and support:
=, <, <=, >, >=
ORDER BY, LIMIT, BETWEEN
What are the effects of declaring a PRIMARY KEY in PostgreSQL?
✅ Enforces uniqueness — no duplicate values allowed.
✅ Implies NOT NULL — cannot contain NULL values.
✅ Automatically creates a unique B-tree index for fast lookups.
🔒 Only one primary key allowed per table.
📦 Can be composite — span multiple columns.
What is the base popularly used to encode short urls and why?
Base62 uses [0–9][A–Z][a–z] → 62 characters total.
- So you can compress 1B urls well within 6 characters which cover 62⁶ ≈ 56B possible codes — plenty of space.
- Still risk of collisions if generated randomly or via hash.
- Could use counter and bijective functions (avoid guessing)
What is 10^9 bytes? 10^12 bytes?
10^3 = kilobytes
10^6 = megabytes (mega millions)
10^9 = gigabytes
10^12 = terabytes (terra twelve)
10^15 = petabytes (peta 15 dogs)
What is caching?
t-cache
Caching stores copies of data more accessibly (e.g., memory, CDN, Redis). Best for read-heavy or repeated-access data where freshness requirements are looser.
Pros:
It reduces latency by avoiding expensive recomputation or slow I/O.
It lowers load on network, databases and services.
Increases scalability - reduces load on og source.
Cons
Complexity of managing cache invalidation and staleness
Cost
It’s used in distributed databases and consensus protocols.
Helps balance consistency and availability (e.g., “read from 2 of 3 replicas”).
Prevents stale reads or conflicting writes from split-brain scenarios.
CAP = Consistency, Availability, Partition tolerance.
In a network partition, a system must trade consistency (no stale reads) vs availability (always respond).
Partition tolerance is non-negotiable in distributed systems.
What is failover, why use it?
Failover is the switch from a failed node to a healthy backup.
Automatic failover helps ensure high availability and reduce downtime.
Can be done at the application, database, or infrastructure layer.
Key design questions: detection speed, data consistency, and client reconnection behavior.
What is denormalization, and why use it?
Denormalization is intentionally storing redundant data to optimize read performance.
Example: store user name in the order table to avoid a join.
It reduces the need for expensive joins in relational databases.
Used in read-heavy, reporting, or analytics workloads.
Trade-off: increased storage and more complex write/update logic.
How do you read an EC2 instance type name like t4g.small
Format is <family><generation>[<vendor>].<size>
Family = what it’s optimized for (general, compute, memory, etc.).
tis cheap bustableGeneration = newer number → newer hardware.
vendor = CPU vendor, disk, networking, etc.
gis graviton.Size = capacity, doubles resources as you go up (
large,xlarge,2xlarge).
T = Burstable general purpose.
Cheap, earns CPU credits when idle, bursts during load.
Good for dev/test, light apps, low-cost workloads.
Common:
t3.micro,t4g.small.
M = General purpose.
Balanced CPU and RAM (≈4 GB per vCPU).
Good default choice for many apps and web servers.
Example:
m6i.large→ 2 vCPU, 8 GB RAM.
C = Compute optimized.
Higher CPU-to-memory ratio.
Best for CPU-bound workloads like batch processing, analytics, or video encoding.
Example:
c6g.xlarge→ 4 vCPU, 8 GB RAM.
R = Memory optimized.
Much more RAM per vCPU.
Ideal for databases, caching layers, and in-memory analytics.
Example:
r6i.large→ 2 vCPU, 16 GB RAM.
What is the size range of ec2 instances? And what does each step do?
The part after the dot = instance size.
Ranges from
nano→micro→small→medium→large→xlarge→2xlarge… up to32xlarge.Each step roughly doubles vCPU and RAM.
Example:
m6i.large(2 vCPU, 8 GB) →m6i.xlarge(4 vCPU, 16 GB).
a = AMD CPU (cheaper).
g = Graviton (ARM-based, energy efficient).
i = Intel (explicit branding).
d = Local NVMe disk included.
n = Extra networking throughput.
metal = Bare metal (direct hardware access).
r7g.xlarge → memory optimized, 7th gen Graviton, 4 vCPU, 32 GB RAM.
Common in billing, payments, and APIs where network retries happen.
Typically enforced by storing an idempotency key and replaying the original response.
Prevents duplicate charges or writes during client retries or timeouts.
Instead, systems aim for at-least-once delivery combined with idempotent operations, producing an exactly-once effect.
Example: Kafka commits + idempotent consumers achieve at-least-once delivery, but deduplication ensures no double processing.
Prevents abuse, protects downstream services, and enforces fairness.
Common algorithms: token bucket, leaky bucket, and fixed/sliding windows.
Often implemented at API gateways or load balancers.
Without it, queues overflow, latency spikes, and services crash.
Techniques include bounded queues, dropping requests, or telling clients to retry later.
In streaming systems (Kafka, gRPC), backpressure is essential for stability.
Timeouts: stop waiting after a limit; prevent stuck requests.
Retries: reattempt failed requests; must be bounded to avoid overload.
Jitter: add randomness to retry intervals to prevent synchronized retry storms.
Together, these make services more resilient to transient failures.
What is the circuit breaker pattern?
In a distributed/microservices system - a pattern that detects and manage failures gracefully. It is implemented on the “client” service of the service call.
Closed - Normal function
Open - When a service fails repeatedly, the circuit "trips" to the Open state, preventing further requests, responding with a failure without ever making the network call.
Half-open - After a timeout, it moves to Half-Open to test if the service has recovered before returning to a normal, Closed state.
Prevents cascading failures and wasted requests. Allows “server” service to recover.
What is the bulkhead pattern in system design?
Bulkheads isolate parts of a system so one failure doesn’t sink everything. With the bulkhead pattern, you dedicate a specific, isolated set of resources (thread pools, connection pools) to each external dependency. If it fails, other parts of the system don’t fail.
Mechanisms: Thread pools, semaphores.
Improves fault isolation and graceful degradation.
—
Learn:
Inspired by ship compartments: if one leaks, others stay afloat.
Say you have a single service communicated with several external APIs or DBs. Usually, all calls would share same pool of resources (threads or database connections).
If one of these downstream services becomes unresponsive, it could exhaust the shared pool, causing all other requests to other services and maybe to your service to be blocked. This is a classic example of cascading failure.
With the bulkhead pattern, you dedicate a specific, isolated set of resources to each external dependency. For example:
Dedicated thread pool for calls to the user service.
Separate thread pool for calls to the payment gateway.
If the user service starts timing out, only the threads in its dedicated pool will be affected. The other services (payment, notification) will continue to operate normally because their resource pools are untouched.
A message queue decouples producers from consumers with async delivery.
Examples: RabbitMQ, Kafka, SQS.
Supports at-least-once delivery by default; exactly-once effect requires idempotent consumers.
Queues smooth out traffic spikes and allow retries and DLQs (dead-letter queues).
Saga is a way to handle long-lived transactions across services. Each step has a compensating action to undo if a later step fails.
Two styles: choreography (services publish/subscribe) and orchestration (central coordinator). Common in e-commerce (reserve → charge → ship).
What is consistent hashing?
Consistent hashing assigns keys to nodes in a ring-like space.
Same key returns the same node.
When nodes are added/removed, only a small fraction of keys need to move.
Used in distributed caches (Memcached, DynamoDB) and sharding routers.
Solves “hotspot” issues better than modulo-based hashing.
Leader election chooses one node to act as coordinator among peers. Important for consensus, replication, and distributed locks.
Algorithms include Raft, Paxos, or Zookeeper’s ZAB.
Guarantees there’s only one active writer/primary at a time.
CDC streams database changes in real time to other systems. Enables building search indexes, caches, analytics pipelines, and event-driven systems.
Tools: Debezium, Kafka Connect, AWS DMS.
polling and ensures downstream systems stay in sync.
What is a cache stampede?
t-cache
A cache stampede happens when many clients request the same expired item simultaneously. Leads to thundering herd effect on the backend.
Mitigations: stale-while-revalidate, randomized TTLs (jitter), request coalescing (single-flight).