RHMA - lecture 10 - experimental studies (evaluations in health sciences 2)
1/34
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
35 Terms
evidence based practice (EBP)
a systematic approach to making decisions that integrates the three core components.
best research evidence
clinical expertise
patient values and preferences
All three must work together — relying on evidence alone isn’t enough, and ignoring evidence for tradition or intuition is risky.
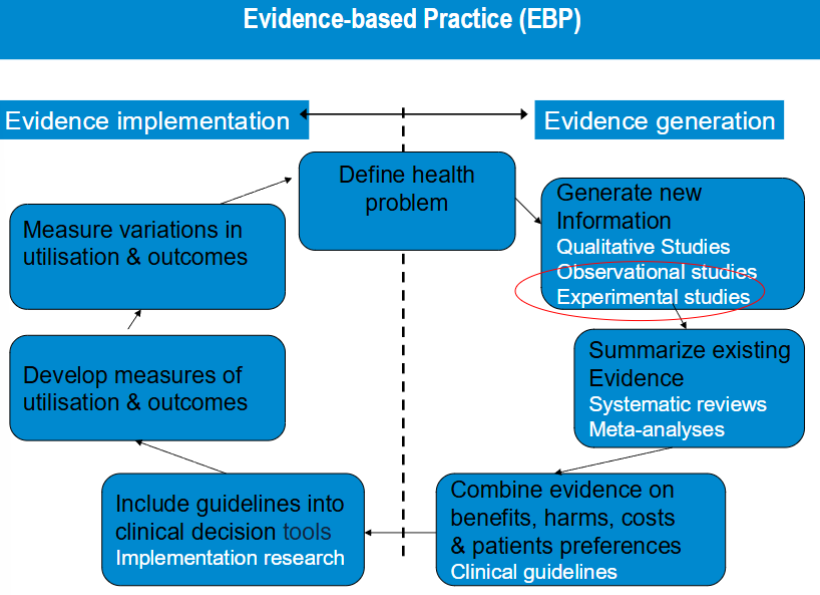
observational studies
non-experimental
observational because treatment and exposures occur in
a “non-controlled” environment individuals can be
observed prospectively, retrospectively, or currentlyImportant is that you do not manipulate exposure (in
RCT that is Treatment), you just observe in observational
studies“Confounding by indication” is always an issue
randomly controlled trials
participants are randomly assigned to intervention and control groups
prevents confounding by indication. results in prognostic comparability of the treatment arms at baseline
provides most convinding evidence of causal relationship between exposure and effect
the gold standard of research designs
HOWEVER even though it is the gold standard that does not mean that you can trust every result in the report.
When poorly designed & conducted, a lot of things can go wrong in RCTs.
flow chart design
most important is the randomisation!!!!
steps to follow when designing / interpreting RCTs
Research question
Study population (in-& exclusion criteria)
Intervention
Comparator
Outcome measures and instruments
Data collection
Data analysis
Interpretation and report
also important to know an ethics committee is involved at some point
good RCT research question
is the question relevant
is the experiment feasible
PICO → population, intervention, control, outcome measure
medical ethics committee RCT
no inacceptable risk involved
experimental and control intervention acceptable
informed consent is needed (LEGAL)
study population
recruitment → complete information given patients, informed consent
composition of the population → is chosen from the inclusion and exclusion criteria, representative for target population.
size of study population → sample size calculation
who gets what? → random allocation, no confounding by indication, prognostic comparability at baseline
sample size (part of study population)
large enough to answer research question
non respons (%)
loss to follow up → no rule for this
need to register drop outs and their reason
to prevent loss to follow up → reminders, personal contact during measurements, gifts / lottery etc.
interventions
experimental → new intervention, existing intervention (e.g. really necessary)
control (placebo, no intervention (prevention), usual care.
choosing the right control → if you would like to know if the new intervention is better than what we normally do; usual care. → pragmatic trials, effectiveness studies.
if you would like to know if the intervention has any effect → placebo studies. → efficacy studies.
the contrast between intervention and control has to be different enough → healthcare getting more expensive, need to look at where we use our resources.
primary and secondary outcome measures
used to define the main and additional goals of a study.
outcome measurement and instruments
how do you measure if an intervention is successful?
relevant and measurable → valid, reliable, and responsive measurement tools
expectations of size and direction of the effect (how much should intervention group score higher than the control group)
most important parameter for sample size calculation!
expectations of time in which the effect can be realized. → this determines the measurement schedule. (when will the intervention start working).
data collection
Baseline measurement and follow-up measurement
When and how often (= measurement schedule)
Valid and reliable measurement instruments!!
Timing of follow-up measurement should be the same in both groups
Length of follow-up period sufficient?
Data entry important essential part of RCT
Data entry control (set rules in data entry program/ double data entry )
intention to treat
RCT is always done with intention to treat
participants are analyzed in the groups to which they were originally assigned regardless of whether they actually received or completed the assigned treatment.
even if a particicpant drops out, doesn’t take the medication, volates protocol
important because this is also what happens in daily life and to preserve the benefits of randomization.
data analysis
Blinding of statistician/ researcher?
Test H0 (null-hypotheses): there is no difference in effect between groups
Adjustment for baseline differences as these may be confounders?
Report of primary outcomes & secondary outcomes
Dichotomous data (2 possible outcomes, e.g. diseased yes/no)
Risk ration of Risk difference etc presented with 95% confidence intervals
Number needed to treat
Continuous outcomes → mean differences
important parameters to look at!
beware for P value → it is not about statistically significant differences (big sample size often gives significant P value when the actual difference between the groups is very small).
imagine; the purpose of the trial was to test your H0, which was that there was no difference between intervention and control group
A good conclusion would be to report that there was a difference or no difference in effect between groups
based upon a statistically and minimal clinically relevant difference between groups in primary outcome measure.
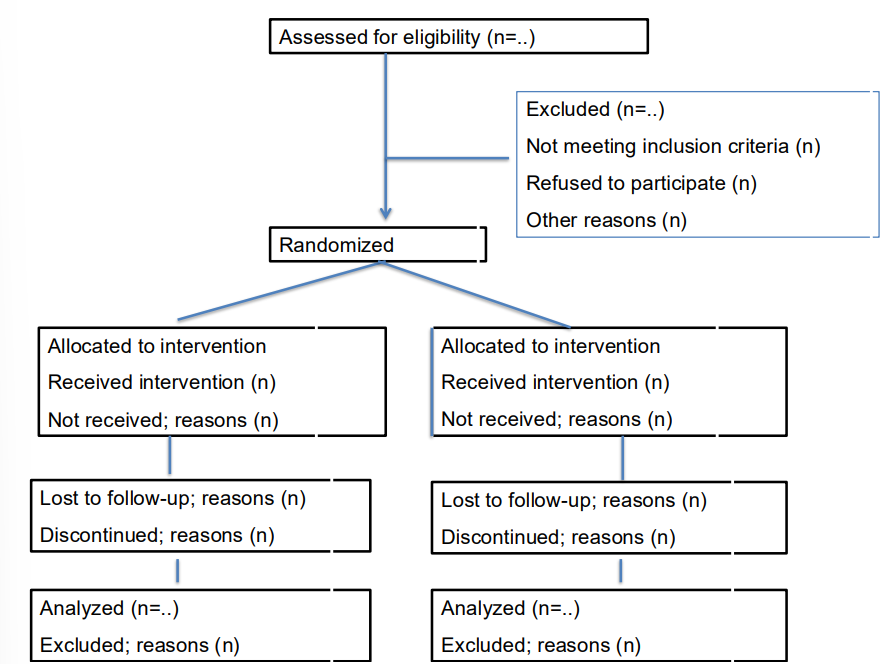
CONSORT statement
Recommendations intended to improve the reporting of an RCT, enabling readers to understand a trial's conduct and to assess the validity of results. (by using Checklist and flow diagram).
Adopted by many scientific journals
Checklist contains 25 items in 5 domains (Title and abstract, introduction, methods, results, discussion)
Flow diagram depicting information on 4 stages of a trial (enrolment, intervention allocation, follow-up, analysis)
CONSORT statement; examples what should be reported
introduction
Scientific background and explanation of rationale of the trial
Methods
Objectives, randomization, blinding
Results
Dates defining the periods of recruitment, baseline characteristics, adverse events/side-effects
Discussion
Interpretation, also the general interpretation of the results in the context of current evidence should be given
quality of an RCT
the probability that the study design does not lead to biased results (internal validity)
most commonly used term → risk of bias
an important step in systematic reviews of RCTs → lectures on systematic reviews and meta-analyses.
internal, external validity and precision in RCTs
internal validity: the extent to which a study can establish that changes in the dependent variable were caused by the independent variable, rather than by other confounding factors. (the extent to which its design & conduct are likely to prevent systematic errors, or bias)
→ Risk of BiasPrecision: the likelihood of chance effects leading to random errors. It is reflected in the confidence interval around the estimate of effect from each study
external validity: the extend to which the results of the trial can be generalized to other situations/ target populations/settings etc.
selection bias
individuals or groups in a study differ systematically from the population of interest
because of randomization (did the randomization work out properly)
randomization aims to prevent selection bias, by ensuring that the assignment to the treatment or the control is not influenced by prognostic factors.
an incorrect randomization can introduce selection bias.
what does an adequate randomization procedure include
Random sequence generation (assignment to treatment arms based on chance)
Allocation sequence concealment (prevent participants or trial personnel from knowing the forthcoming allocations )
performance bias
unequal treatment between study groups resulting in study participants altering behaviour
bv bias due to deviations from the intended intervention
not being compliant to the protocol by care provide and/or patient
exposure to factors other than the intervention/control of interest
contamination (provision of the intervention to the control group)
co-intervention (provision of unintended additional care to either comparison group)
minimizing performance bias
can be reduced / avoided by → implementing mechanisms that ensure participants, carers and trial personnel are unaware of the interventions received → blinding
attrition bias
loss to follow up (always happens!!)
systematic difference in loss to follow up between groups
detection bias
error in measurement of outcome
aka information bias → measurement bias, misclassification
in the context of RoB assessment the differential measurement errors are important!
Such measures are systematically different between experimental and comparator intervention groups
less likely when outcome assessors are blinded to intervention
assignment
selective reporting bias
Refers to systematic differences between reported and unreported findings
criteria for internal validity
randomisation procedure
comparable groups at baseline
blinding of randomisation allocation to ;
patients
outcome assessors
care provider
statistician or researcher performing the analysis
compliance to the protocol by patients and care providers
loss to follow up
intention to treat analysis
criteria for external validity
relevant research questions
description of in- and exclusion criteria
description of intervention
description of control intervention
relevant outcome measurements
length of follow up / timing of follow up measurements
criteria for precision / accuracy
sample size of study population large enough in both groups
outcome measures presented with confidence intervals
cluster randomized trial
Randomisation at level of cluster (e.g practice, hospital) and not at level of individual patient
Outcome measurement at level of individual patient
Advantages in case of:
Intervention aimed at cluster level (e.g. department)
Difficult for HCPs to switch between treatments
Prevents contamination
RoB and statistical analysis in cluster RCT
Statistical analyses: patients within any one cluster (e.g. a practice) are often more likely to respond in a similar manner, and thus can no longer be assumed to act independently
multi level structure in the data
Risk of Bias less straightforward
RoB at Cluster level (Baseline imbalance, selective drop out)
RoB at Individual level (differential individual recruitment or differential consent procedures)
non-inferiority trial (NI)
seeks to determine whether a new treatment is not worse than a reference treatment by more than an acceptable amount (the intervention is not perse better but definitely not worse either)
e.g. less intense chemotherapy
Because proof of exact equivalence is impossible, a prestated margin of NI (Δ) for the treatment effect in a primary patient outcome is defined
Equivalence trials are very similar, except that equivalence is defined as the treatment effect being between −Δ and +Δ.
non-inferiority trial - issues for discussion
Is the gain (e.g less burden) of the new treatment a real gain?
Choice appropriate comparator (at least not placebo).
Current treatment is better then placebo
Determining NI margin (Δ) is a challenge
ITT vs per protocol analyses
In sum: Interpretation is not straightforward
phase 1 to pase 4 trials
phase 1
After ‘promising’ findings in animal experiments
Pharmacological & metabolic effect & side effects
Healthy volunteers
Phase 2 trials
For the first time the relevant patients are targeted
Important aims are to assess safety and optimal dose
Often focus on intermediate outcomes
Phase 3 trials
Focus on the ‘real life’ situation (‘real’ patients, clinically relevant outcomes)
Phase 4 trials
postmarketing (surveillance) mainly to detect rare side effects.