Modern Database Management - Ch 5
1/120
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
121 Terms
A requirement to begin designing physical files and databases is:
A) normalized relations.
B) definitions of each attribute.
C) technology descriptions.
A key decision in the physical design process is:
selecting structures.
Designing physical files requires of where and when data are used in various ways.
descriptions
The storage format for each attribute from the logical data model is chosen to maximize and minimize storage space.
data integrity
Database access frequencies are estimated from:
transaction volumes.
A detailed coding scheme recognized by system software for representing organizational data is called a(n):
data type.
All of the following are objectives when selecting a data type EXCEPT:
A) represent all possible values.
B) improve data integrity.
C) support all data manipulations.
D) use a lot of storage space
All of the following are valid datatypes in Oracle 11g EXCEPT:
A) varchar2.
B) boolean.
C) blob.
D) number.
boolean.
The smallest unit of application data recognized by system software is a:
field.
Which of the following is an objective of selecting a data type?
A) Represent a small number of possible values
B) Maximize storage space
C) Limit security
D) Improve data integrity
Improve data integrity
In which data model would a code table appear?
Physical
An integrity control supported by a DBMS is:
range control.
The value a field will assume unless the user enters an explicit value for an instance of that field is called a(n):
default value.
A method for handling missing data is to:
substitute and estimate for the missing data. track missing data with special reports. perform sensitivity testing.
Sensitivity testing involves:
checking to see if missing data will greatly impact results.
Common denormalization opportunities
two entities with a one-to-one relationship.
a many-to-many relationship with nonkey attributes.
reference data.
In most cases the goal of dominates the design process.
efficient data processing
Distributing the rows of data into separate files is called:
horizontal partitioning.
Horizontal partitioning makes sense:
when different categories of a table's rows are processed separately.
An advantage of partitioning is:
efficiency.
A disadvantage of partitioning is:
extra space and update time.
Horizontal partitioning methods in Oracle
Key range partitioning
Hash partitioning
composite partitioning
partitioning distributes the columns of a table into several separate physical records.
Vertical
Another form of denormalization where the same data are stored in multiple places in the database is called:
data replication.
Within Oracle, the named set of storage elements in which physical files for database tables may be stored is called a(n):
tablespace.
While Oracle has responsibility for managing data inside a tablespace, the tablespace as a whole is managed by the:
operating system.
A contiguous section of disk storage space is called a(n):
extent.
A(n) is a field of data used to locate a related field or record.
pointer
A(n) is a technique for physically arranging the records of a file on secondary storage devices.
file organization
Factors to consider when choosing a file organization is:
fast data retrieval.
security.
efficient storage
One field or combination of fields for which more than one record may have the same combination of values is called a(n):
secondary key.
An index on columns from two or more tables that come from the same domain of values is called a:
join index.
A(n) is a routine that converts a primary key value into a relative record number.
hashing algorithm
In which type of file is multiple key retrieval not possible?
Hashed
A file organization that uses hashing to map a key into a location in an index where there is a pointer to the actual data record matching the hash key is called a:
hash index table.
Which type of file is most efficient with storage space?
Sequential
Which type of file is easiest to update?
Hashed
A method to allow adjacent secondary memory space to contain rows from several tables is called:
clustering.
A rule of thumb for choosing indexes is to:
• be careful indexing attributes that may be null.
• index each primary key of each table.
• use an index when there is variety in attribute values.
A method that speeds query processing by running a query at the same time against several partitions of a table using multiprocessors is called:
parallel query processing.
A command used in Oracle to display how the query optimizer intends to access indexes, use parallel servers and join tables to prepare query results is the:
explain plan.
Requirements for response time, data security, backup and recovery are all requirements for physical design.
Answer: TRUE
One decision in the physical design process is selecting structures.
Answer: TRUE
The logical database design always forms the best foundation for grouping attributes in the physical design.
Answer: FALSE
Efficient database structures will be beneficial only if queries and the underlying database management system are tuned to properly use the structures.
Answer: TRUE
SOX stands for the Sorbet-Oxford Act.
Answer: FALSE
Adding notations to the EER diagram regarding data volumes and usage is of no value to the physical design process.
Answer: FALSE
The smallest unit of named application data is a record.
Answer: FALSE
One objective of selecting a data type is to minimize storage space.
Answer: TRUE
A default value is the value that a field will always assume, regardless of what the user enters for an instance of that field.
Answer: FALSE
A range control limits the set of permissible values that a field may assume.
Answer: TRUE
One method to handle missing values is to substitute an exact value.
Answer: FALSE
Sensitivity testing involves ignoring missing data unless knowing a value might significantly change results.
Answer: TRUE
Denormalization is the process of transforming relations with variable-length fields into those with fixed-length fields.
Answer: FALSE
Keeping the zip code with the city and state in a table is a typical form of denormalization.
Answer: TRUE
Denormalization almost always leads to more storage space for raw data.
Answer: TRUE
Horizontal partitioning refers to the process of combining several smaller relations into a larger table.
Answer: FALSE
Horizontal partitioning is very different from creating a supertype/subtype relationship.
Answer: FALSE
Security is one advantage of partitioning.
Answer: TRUE
Reduced uptime is a disadvantage of partitioning.
Answer: FALSE
Hash partitioning spreads data evenly across partitions independent of any partition key value.
Answer: TRUE
Free range partitioning is a type of horizontal partitioning in which each partition is defined by a range of values for one or more columns in the normalized table.
Answer: FALSE
Vertical partitioning means distributing the columns of a table into several separate physical records.
Answer: TRUE
An extent is a named portion of secondary memory allocated for the purpose of storing physical records.
Answer: FALSE
A tablespace is a named set of disk storage elements in which physical files for the database tables may be stored.
Answer: TRUE
A pointer is a field of data that can be used to locate a related field or record of data.
Answer: TRUE
A file organization is a named portion of primary memory.
Answer: FALSE
Fast data retrieval is one factor to consider when choosing a file organization for a particular database file.
Answer: TRUE
In a sequential file, the records are stored in sequence according to primary key.
Answer: TRUE
A key is a data structure used to determine the location of rows in a file that satisfy some condition.
Answer: FALSE
A join index is a combination of two or more indexes.
Answer: FALSE
A hashing algorithm is a routine that converts a primary key value into a relative record number.
Answer: TRUE
Clustering allows for adjacent secondary memory locations to contain rows from several tables.
Answer: TRUE
Indexes are most useful on small, clustered files.
Answer: FALSE
Indexes are most useful for columns that frequently appear in WHERE clauses of SQL commands, either to qualify the rows to select or for linking.
Answer: TRUE
Using an index for attributes referenced in ORDER BY and GROUP BY clauses has no significant impact upon database performance.
Answer: FALSE
Parallel query processing speed is not significantly different from running queries in a non-parallel mode.
Answer: FALSE
Along with table scans, other elements of a query can be processed in parallel.
Answer: TRUE
The query processor always knows the best way to process a query.
Answer: FALSE
SQL Overview
Structured Query Language
The Standard for Relational Database Management Systems (RDBMS)
RDBMS (Relational Database Management Systems)
A database management system that manages data as a collection of tables in which all relationships are reprented by common values in related tables
Original Purpose of SQL Standard
Specify syntax/semantics for data definition and manipulation
Define data structures and basic operations
Enable portability of a database definition and application modules
Specify minimal (level 1) and complete (level 2) standards
Allow for later growth/enhancement to standard (referential integrity, transaction management, user-defined functions, extended join operations, national character sets)
Benefits
Reduced trainings costs
Productivity
Application portability
Application longevity
Reduced dependence on a single vendor
Cross-system communication
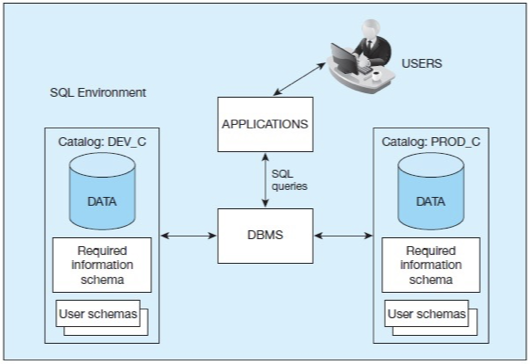
Catalog
A set of schemas that constitute the description of a database
city = catalog
Schema
The structure that contains descriptions of objects created by a user (base tables, views, contraints)
neighborhoods = schemas
data definition language (ddl)
Commands that define a database, including creating, altering, and dropping tables and establishing constraints
data manipulation language (dml)
Commands that maintain and query a database
data control language (dcl)
Commands that control a database, including administering privileges and committing data
SQL environment
Shows two databases one for production and development
Strings (SQL Data Types)
CHARACTER (n), VARYING CHARACTER (n)
Binary (SQL Data Types)
Binary Large Object (BLOB)
Any type of data up to 4 gb (catch all attribute)
Number (SQL Data Types)
Numeric (precision, scale), Decimal (p,s), Integer
Temporal (SQL Data Types)
Timestamp, Timestamp with local time zone
Boolean (SQL Data Types)
True or False values
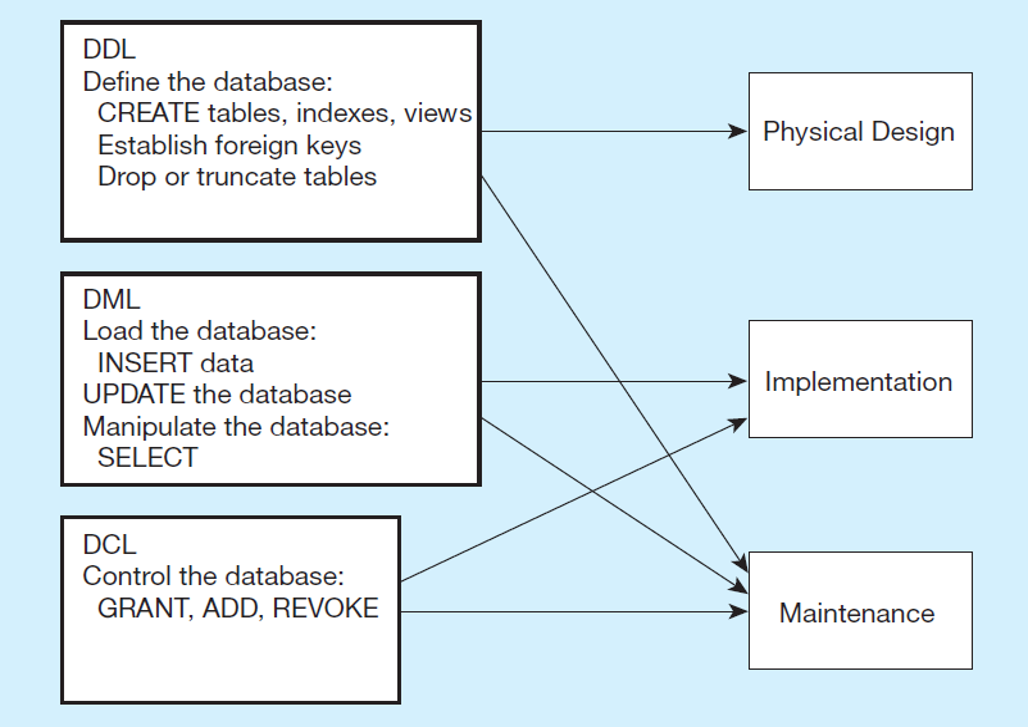
DDL, DML, DCL, and the Database Development Process
SQL is composed of three sub-languages, DDL, DML, and DCL.
DDL
Used to create the metadata of the database (tables, attributes, data types, indexes, primary and foreign keys)
Language designers use to create the database
Physical Design and Maintenance
DML
Includes all query, update, insert, and delete statements
Implementation
Maintenance
DCL
Specify who can access the data and the types of data and operations these users are authorized to manipulate
Implementation
Maintenance
Data Definition Language (DDL) Commands
CREATE
ALTER
DROP
TRUNCATE
RENAME
Major CREATE statements
CREATE SCHEMA:
defines a portion of the database owned by a particular user
CREATE TABLE
defines a new table and its columns
CREATE VIEW
defines a logical table from one or more tables or views
Other CREATE statements: CHARACTER SET, COLLATION, TRANSLATION, ASSERTION, DOMAIN

Steps in Table Creation
1.Identify data types for attributes
2.Identify columns that can and cannot be null
3.Identify columns that must be unique (candidate keys)
4.Identify primary key–foreign key mates
5.Determine default values
6.Identify constraints on columns (domain specifications)
7.Create the table and associated indexes
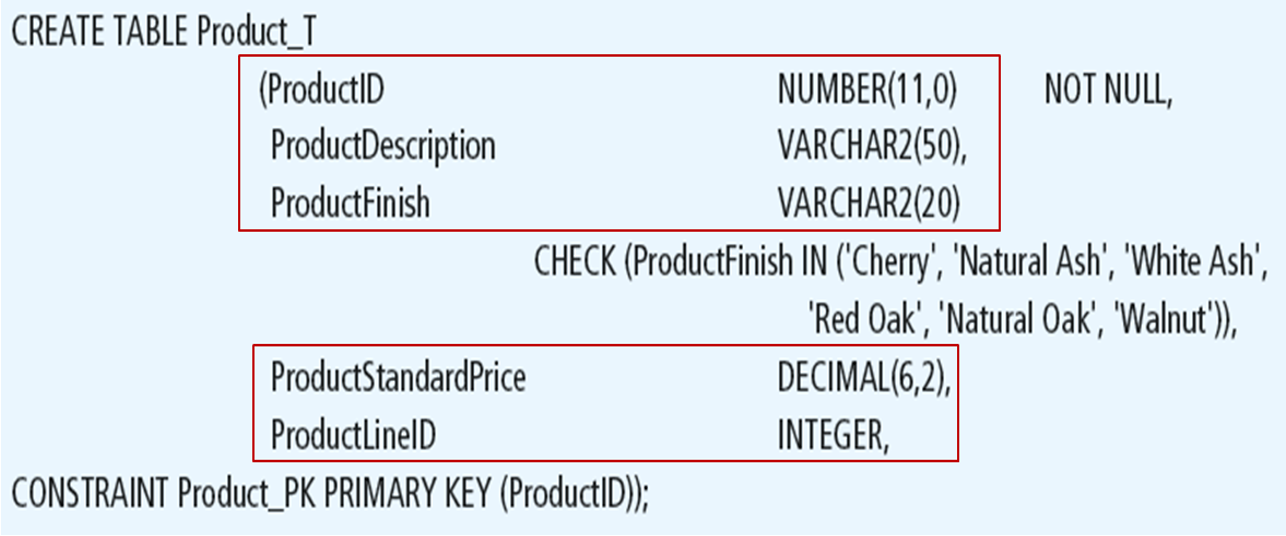
Defining Attributes and Their Data Types
Each column has a data type. In this case, some are numeric, and some are character (text). You can also specify column sizes. For numeric columns, you can specify whether they will be integer (which ProductID is) or allow decimal values (such as ProductStandardPrice).
Non-Nullable Specificatons
