Theme 2 theorie methoden & statistiek
1/63
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
64 Terms
Wat is data?
numerieke feiten
bijv. getal of codering van een categorie (1 = man, 2 = vrouw)
Wat kan statistiek met data?
Statistiek omvat verzameling, organisatie en interpretatie van data
→ door patronen te herkennen in variabele data kan een fenomeen beschreven, begrepen en voorspeld worden
Wat zijn de verschillende onderdelen uit een dataset?
Cases of units
Variabele
Label
Case of unit
subjecten (mensen) of objecten waar onderzoek naar is gedaan / die worden beschreven door data
Variabele
kenmerk of karakteristiek van case
Label
specifieke variabele: unieke identificatie van een case
→ alle cases hebben een andere score, bijv. burgerservicenummer
Categorische of kwalitatieve variabele
Variabele die een case plaatst in een groep/categorie waarde, aangeduid met namen/labels of een identificerend nummer
bijv. studie, leeftijdsgroep, plaats, geslacht, oogkleur, religie
Kwantitatieve variabele
Waarde van variabele gebruikt bepaalde meeteenheid die numeriek uitgedrukt kan worden
→ het is hierbij logisch en waardevol om met waardes te rekenen (bijv. het berekenen van een gemiddelde, optellen van waardes, omzetting van frequentie naar rate (=mate))
vb. leegtijd, aantal kinderen in gezin, IQ-score
Discrete variabele
kan geen tussenliggende waardes aannemen (vaak in vast bereik)
vb. 0, 1, 2 of 3 kinderen
→ vorm van kwantitatieve variabele
Continue variabele
kan altijd nieuwe tussenliggende waardes aannemen (door toevoeging decimalen)
→ in praktijk vaak omgezet naar discrete variabele door afronding of gebruik van eenheden
vb. tijd, bloeddruk
→ vorm van kwantitatieve variabele
Onafhankelijke variabele
aangenomen oorzaak van een causale relatie tussen variabelen
Afhankelijke variabele
aangenomen gevolg van een causale relatie tussen variabelen
Experimenteel onderzoek
manipulatie, variatie of selectie van variabele(n) om invloed op uitkomst(en) te onderzoeken
→ soms onethisch of praktisch onmogelijk, wordt dan enkel gemeten in beschrijvend onderzoek
Beschrijvend onderzoek
onderzoek waar variabele enkel worden gemeten (en niet gemanipuleerd) om verbanden tussen variabelen te onderzoeken
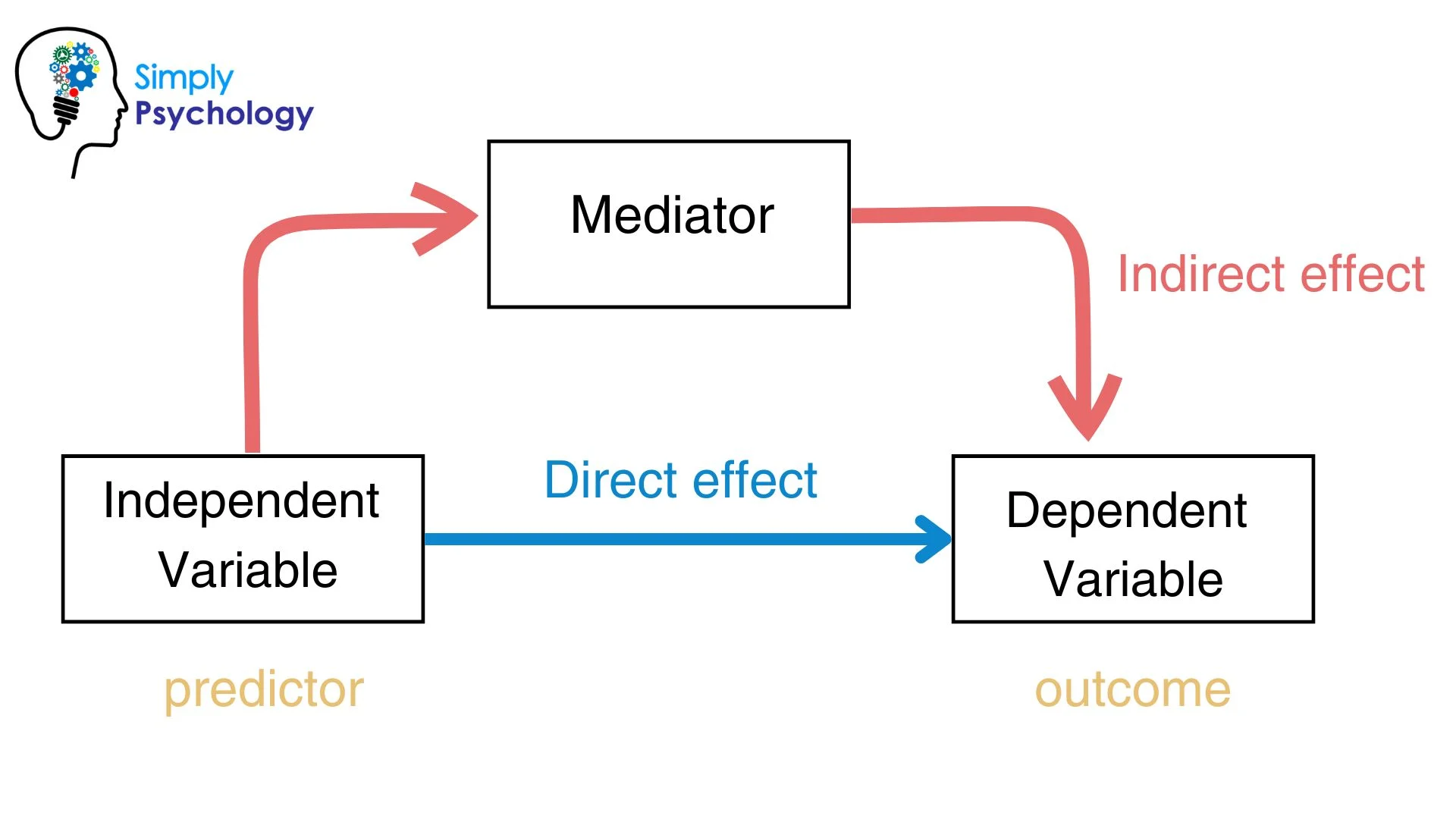
Mediator variabele
verstrekt een causale verbinding in opeenvolging van onafhankelijke tot afhankelijke variabele
bijv. telefoongesprek à afleiding à verminderde autorijprestaties
Moderator variable
beïnvloedt kracht en richting tussen onafhankelijke en afhankelijke variabele
bijv. mate van verkeer bepaalt relatie tussen bellen & rijprestaties
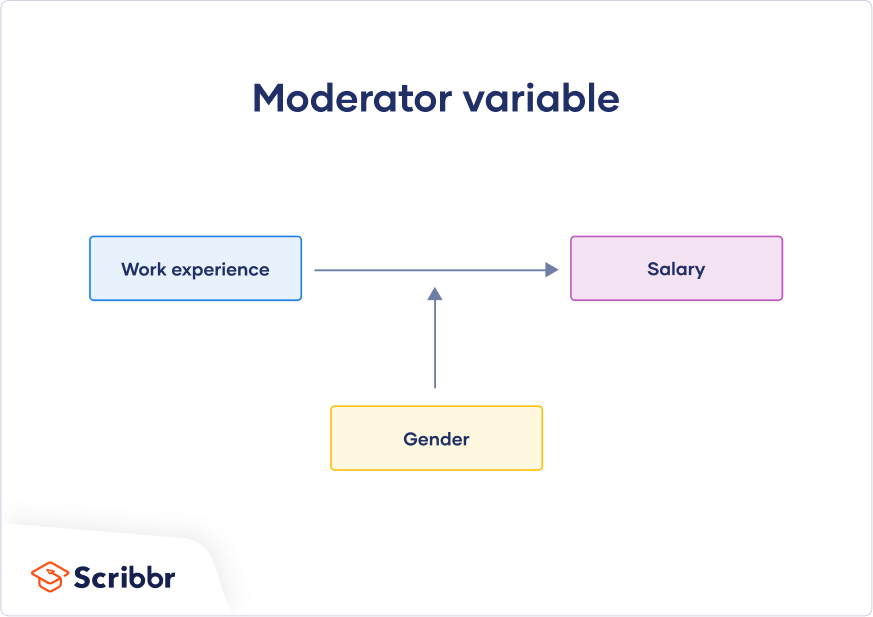
Situationele variabele
karakteristiek dat verschilt tussen omgevingen of stimuli
bijv. temperatuur, geluid, aanwezigheid van anderen
Subject variabele
persoonlijk karakteristiek dat verschilt tussen individuen
bijv. IQ, gewicht, geslacht, gemoedstoestand
Observatie
ander woord voor data (of waardes van variabelen) van een case
Wat zijn de belangrijkste vragen m.b.t. een dataset?
Wie: welke cases beschrijft/onderzoekt de data? Hoeveel cases bevat een dataset?
Wat is er gemeten? (aantal variabelen, definitie en waardes van variabelen, meetniveau/eenheid)
Waarom/met welk doel is dataset verzameld?
vb. antwoord op specifieke vraag? Trekken van conclusies over andere cases? Is data geschikt?
Hypothetisch construct
niet-waarneembaar, onderliggend karakteristiek afgeleid van meetbaar gedrag of reactie in psychologisch onderzoek
Conceptuele definitie
definitie variabele/concept van interesse
→ verschilt per individu/onderzoek
vb. definitie van stress of intelligentie
Operationele definitie
definitie variabele a.d.h.v. gebruikte procedures om variabele te meten/manipuleren
→ maakt abstract concept tast-, waarneem- en meetbaar; duidelijk voor reproductie
vb. scores van vragenlijst, gedragsobservaties, fysiologische metingen, manipulatie van omgeving, rubric schoolopdracht
Nominaal meetniveau
categorisch; categorieën hebben geen rangorde, meeteenheid of nulpunt
→ toont enkel absolute, kwalitatieve verschillen/overeenkomsten tussen cases
bijv. sekse
Ordinaal meetniveau
categorisch; categorieën hebben rangorde, maar geen informatie over grootte van relatieve verschillen (meeteenheid) of nulpunt
bijv. socioeconomische status (laag-middel-hoog)
Kun je rekenen met een categorische variabele?
Ja, je kunt de mediaan, frequentie en percentage bepalen
Interval meetniveau
kwantitatief; waardes hebben volgorde en gelijke afstanden in verschillen (meeteenheid), maar een arbitrair, niet vast nulpunt
→ afstand tussen 1 en 2 is hetzelfde als afstand tussen 3 en 4
bijv. cijfers op een bloktoets, temperatuur, intelligentie (IQ)
Ratio meetniveau
kwantitatief; waardes hebben volgorde, meeteenheid en absoluut nulpunt = absentie/ontbreken van attribuut of factor
→ een waarde kan x keer zoveel hoger of lager zijn
bijv. aantal correct beantwoorde vragen op een bloktoets, gewicht, snelheid
Wat wordt er bedoeld met een gestandaardiseerde procedure van dataverzameling?
elke meting wordt gedaan onder zo gelijk mogelijke condities
Nauwkeurigheid (accuracy)
mate waarin meetmethode resultaten oplevert die overeenkomen met/gekalibreerd zijn tegen bekende standaard
→ moeilijk te bepalen voor psychologische variabelen omdat bekende standaarden niet bestaan
Systematische fout of bias
consistente mate van fout bij elke meting, vermindert nauwkeurigheid
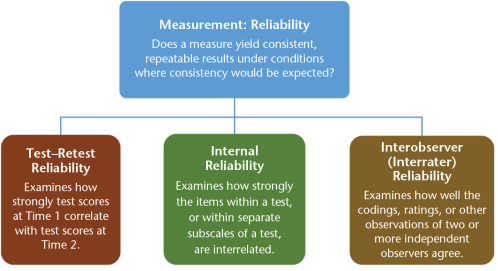
Betrouwbaarheid (reliability)
consistentie van meetmethode onder gelijke condities
Random measurement error of standaardfout E
willekeurige variaties gedurende meting waardoor verkregen resultaten afwijken van daadwerkelijke waarde T
bijv. tijdelijke fluctuaties in persoonlijke karakteristieken, omgeving van meting of meetinstrument
Hoe kun je betrouwbaarheid bepalen?
Test-Retest Reliability (equivalentie methode) = zelfde meting bij zelfde deelnemer onder zelfde condities op minstens twee afzonderlijke momenten
Internal Reliability = bepaling inter-relaties van onderdelen binnen meting
→ scores van items op vragenlijst die zelfde attribuut meten moeten correlerenSplit-half reliability = items worden gesplitst in twee subsets, waarna correlatie tussen subsets wordt bepaald
Cronbach’s alpha = statistiek die reflecteert hoe sterk indiivudele items correleren met elkaar
Interobserver (interrater) reliability = mate waarop onafhankelijke waarnemers overeenkomen in observaties
→ meet betrouwbaarheid van waarnemer/gebruiker, niet die van de meetmethode!
Wat houdt validiteit (validity) in? Wat is de relatie van betrouwbaarheid tot validiteit?
Conclusies moeten volgens logische redenering gebaseerd kunnen worden op meetmethode (en daarvan verkregen resultaten)
→ bijv. persoonlijkheidstesten, diagnostische testen voor persoonlijkheidsstoornissenHoge betrouwbaarheid is noodzakelijk, maar niet voldoende
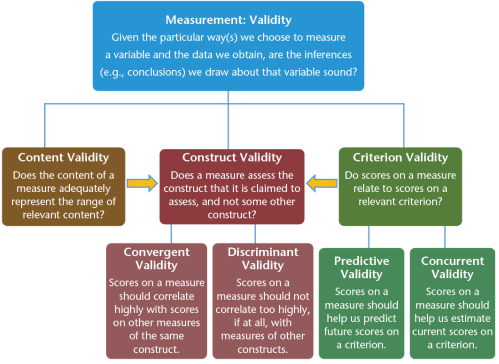
Face validity (indruksvaliditeit)
mate waarop onderdelen van test redelijk lijken
→ oppervlakkig & niet wetenschappelijk; zegt weinig over daadwerkelijke validiteit
Content validity (inhoudsvaliditeit)
mate waarop onderdelen van test representatief zijn voor alle mogelijke onderdelen van te meten construct
bijv. statistiektentamen bevat alle behandelde thema’s
Criterion validity (criteriumvaliditeit)
aantoning van relatie tussen meetresultaten en andere uitkomsten (= criteria):
Predictive validity = meetresultaat voorspelt toekomstig criterium
→ longitudinale bepalingConcurrent validity = relatie tussen op zelfde moment bepaalde meetresultaat en criterium
Construct validity
aantoning dat gemeten/gemanipuleerde constructen in meetmethode daadwerkelijk constructen van interesse zijn
→ meest theoretische soort van validiteit, wordt bepaald door content & criterion validity, en…
Convergent validity = scores van verschillende meetmethoden die hetzelfde construct meten moeten overeenkomen/correleren
Discriminant validity = scores van verschillende meetmethoden die verschillende constructen meten moeten zo min mogelijk correleren
Distributie van een variabele
variatie of verspreiding van waardes van een variabele tussen verschillende cases
Wat doet exploratory data analysis?
beschrijft belangrijkste kenmerken van data, vaak voor predictive analysis (= maken van voorspellingen voor toekomst) door:
onderzoek naar individuele variabelen en samenhang
weergeving van verspreiding van variabele m.b.v. grafische weergaven en numerieke samenvattingen
Wat doen grafische weergaven?
Geven per variabele aan
welke waardes voorkomen
hoe vaak deze waardes voorkomen
of waardes een bepaald patroon volgen
→ geeft veel informatie over vorm van verdeling
Wat zijn de grafische weergaven voor kwalitatieve variabelen met nominale of ordinale meetniveaus?
Taartdiagram: percentage/proportie
Staartdiagram: telling/frequentie of percentage/proportie
Wat zijn de grafische weergaven voor kwantitatieve variabelen met interval of ratio meetniveaus?
Histogram: kwantatieve waarde als klasse (logische groep met bereik) op X-as, telling op Y-as
→ geschikt voor grote datasetsStemplot of steelbladdiagram: weergave van reeks door stam (bijv. honderd- of tiental) en blad (eenheid); toont pieken
→ vooral handig bij kleine datasets met positieve waardes
Hoe kan je een stemplot / steelbladdiagram aanpassen?
splitsen van waardes als bladeren te groot worden
(0-4 en 5-9)trimmen of afronden van waardes bij teveel stammen
→ verwijdert laatste getallen
Wat is een back-to-back stemplot?
Stemplot met bladeren aan beide kanten met gedeelde stam
→ maakt vergelijking van gerelateerde distributies mogelijk
Hoe kan je het algehele patroon een grafische weergave beschrijven?
Middelpunt: verdeelt observaties in twee helften
Vorm
Aantal pieken of modes
bijv. unimodaal, bimodaal of mulitmodaalSymmetrie
Symmetrisch: centraal middelpunt met twee gelijke helften
Left-skewed of right-skewed: meerderehid van scores zit aan hogere of lagere kant van variabele
→ verdeling heeft langere linker- of rechterstaart
Spreiding: grootste en kleine waardes
→ extreme waardes liggen in staarten van verdeling
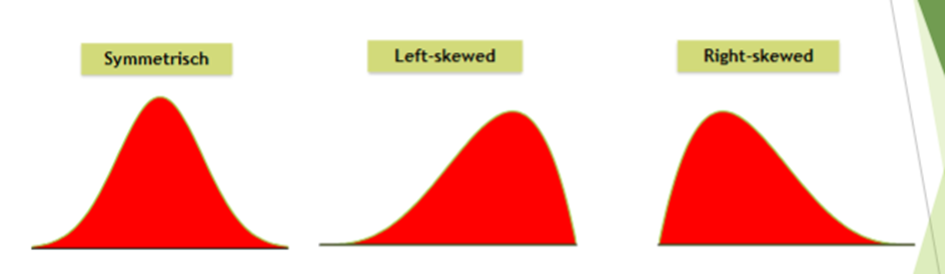
Hoe kun je de afwijking van een patroon beschrijven?
Dit zijn outliers of uitbijters = observaties die losstaan van patroon
→ probeer deze te verklaren en te corrigeren
Time plot
Plotten van observaties die over langere periode zijn verzameld met
tijd op X-as
observatie op Y-as
Wat doen numerieke samenvattingen?
Geven specifieke infromatie over het centrum en de spreiding van variabelen met behulp van cijfers
Wat zijn de centrummaten?
Modus = meest voorkomende score (kan meerdere waardes aannemen)
→ bruikbaar bij alle meetniveausMediaan M = middelste score; 50% is lager en 50% hoger
→ enkel bruikbaar bij rangorde, vrij resistent/robuustGemiddelde score (arithmetic mean)
→ niet resistent of robuust (beïnvloedbaar door extreme waardes en veranderingen in klein aantal observaties); enkel bruikbaar bij kwantitatieve variabelen
Wat zijn spreidingsmaten?
Percentiel p = waarde met p% van observaties daaronder
Onderste kwartiel (Q1) = 25e percentiel
→ mediaan onderste helft dataMediaan (Q2) = 50e percentiel
Bovenste kwartiel (Q3) = 75e percentiel
→ mediaan bovenste helft data
Variantie s2 = maat waarin scores rond gemiddelde verspreid zijn
Standaarddeviatie s = geeft spreiding o.b.v. variantie in originele meeteenheid en voor normaalverdelingen
→ enkel waardevol wanneer centrummaat gemiddelde is; sterk beïnvloed door outliers
Five number summary
laagste waarde
Q1
mediaan (Q2)
Q3
hoogste waarde
→ nuttig voor beschrijving van skewed distributions
Boxplot, interkwartiel range en variaties
visuele weergave van five number summary
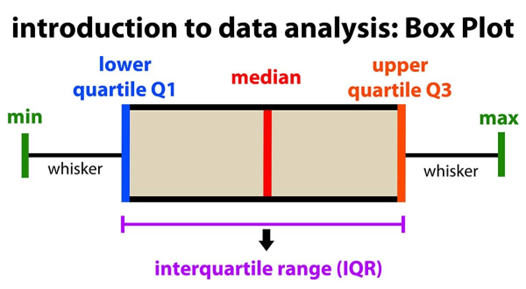
Interkwartiel range (IQR) wordt gebruikt om outliers te bepalen, wordt weergegeven met whiskers
Modified boxplot: lengte van whiskers zijn aangepast (modified) aan eerste/laatste waarde die geen outlier is
→ outliers zijn individueel geplotSide-by-side boxplot: vergelijking van boxplots van meerdere groepen in één grafiek
Wat is het gevolg van lineaire transformatie met xnieuw = a + bx van waardes voor centrum en spreiding?
Vermenigvuldiging met b beïnvloedt ook centrum- en spreidingsmaten
→ dus zowel mediaan, gemiddelde, IQR en sOptellen van a beïnvloedt enkel centrummaten (en géén spreiding)
→ dus enkel mediaan en gemiddelde, géén IQR en s
Kansdichtheidsfunctie (density curve)
histogram waarover een smooth curve is gemodelleerd (wiskundig model van kwantitatieve verdeling; negeert kleine onregelmatigheden)
Wat zijn de kenmerken van een kansdichtheidsfunctie? (5)
Beschrijft patroon van verdeling
Bevindt zich altijd boven horizontale as
Heeft altijd een oppervlakte van 1
→ geeft de proportie van de observaties aanMediaan bevindt zich op punt wat oppervlakte precies halveert
Gemiddelde bevindt zich op balanspunt
→ t.o.v. mediaan meer richting staart bij skewed distributions
Normaalverdeling N
ideale symmetrische, unimodale kansdichtheidsfunctie in vorm van bel
Hoe worden de vorm en functie van een normaalverdeling N bepaald?
vorm en functie worden bepaald door µ en σ, wordt ook vaak afgekort tot N(µ, σ)
Gemiddelde van normaalverdeling = µ
→ verschuift normaalverdeling langs horizontale as; gelijk aan mediaanStandaarddeviatie van normaalverdeling = σ
→ verhoging zorgt voor hogere spreiding; bevindt zich op verandering van curvature
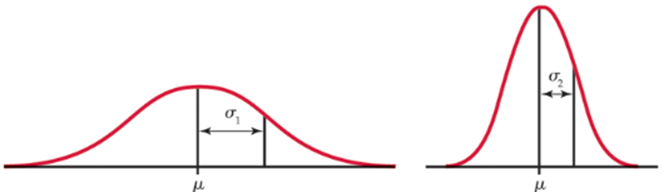
Wat zijn de belangrijke statistische eigenschappen van een normaalverdeling?
Geeft vaak-redelijk goede beschrijving van echte data
Geven vaak goede benaderingen van resultaten die verkregen worden op basis van kans
Veel statische conclusies gelden ook voor andere ± symmetrische verdelingen
68-95-99.7 rule:
± 68% van alle observaties vallen tussen σ en µ
± 95% van alle observaties vallen tussen 2σ en µ
± 99,7% van alle observaties vallen tussen 3σ en µ
Wat is standaardisatie van observaties en het nut hiervan?
Het omzetten van een waarde in een z-score
Maakt vergelijking tussen afwijking/standaarddeviatie van gemiddelde en kansen mogelijk
Afwijking boven gemiddelde = positieve Z-score
Afwijking onder gemiddelde = negatieve Z-score
Wat is een standaard normaalverdeling?
normaalverdeling N(0,1) variabele met µ = 0 en σ = 1
→ hierbij horen z-scores
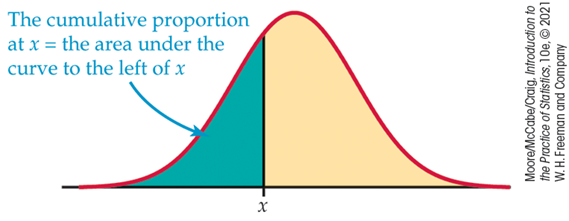
Cumulatieve proportie
proportie van observaties in verdeling onder of op gegeven waarde
→ oppervlak aan linkerkant van gegeven waarde; berekend m.b.v. software of tabel (standaard normale cumulatieve proportie)
Normal quantile plot functie en stappenplan
bepaling of verdeling normaal is of niet
Orden observaties van klein naar groot
Bereken welk percentiel van de data elk punt omvat
Gebruik Normale berekeningen om de z-scores van percentielen te berekenen
→ = Normal scoresPlot datapunten van x tegen normale scores
→ bij Normale verdeling van data zullen punten op een rechte lijn liggen; bij duidelijke afwijkingen is data dus niet normaal verdeeld