IS 420 Exam 2 Review (storage, indexing, triggers, NoSQL, Column Family DB)
1/73
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
74 Terms
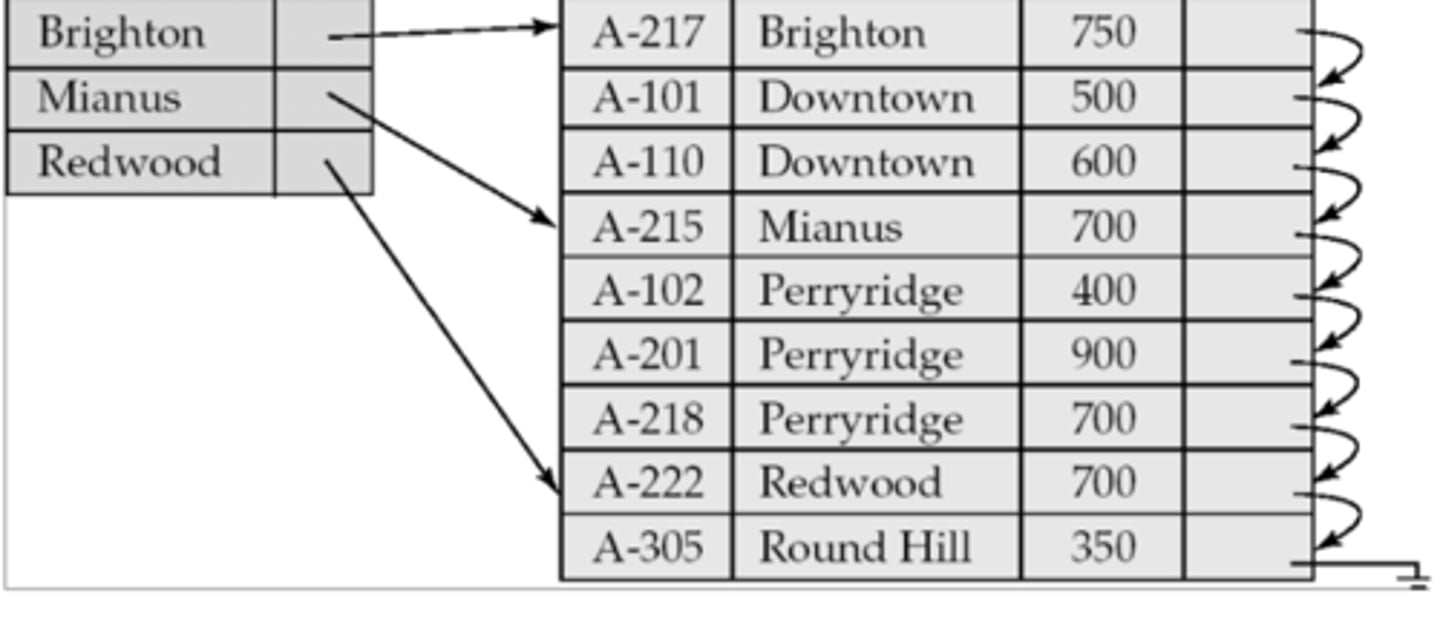
Index
Data structure to improve database query performance.
Primary Index
Unique index for a table's primary key.
Trigger
Database procedure automatically executed on events.
BEFORE Keyword
Specifies trigger execution before an operation.
Row Level Trigger
Trigger that executes for each row affected.
Statement Level Trigger
Trigger that executes once per SQL statement.
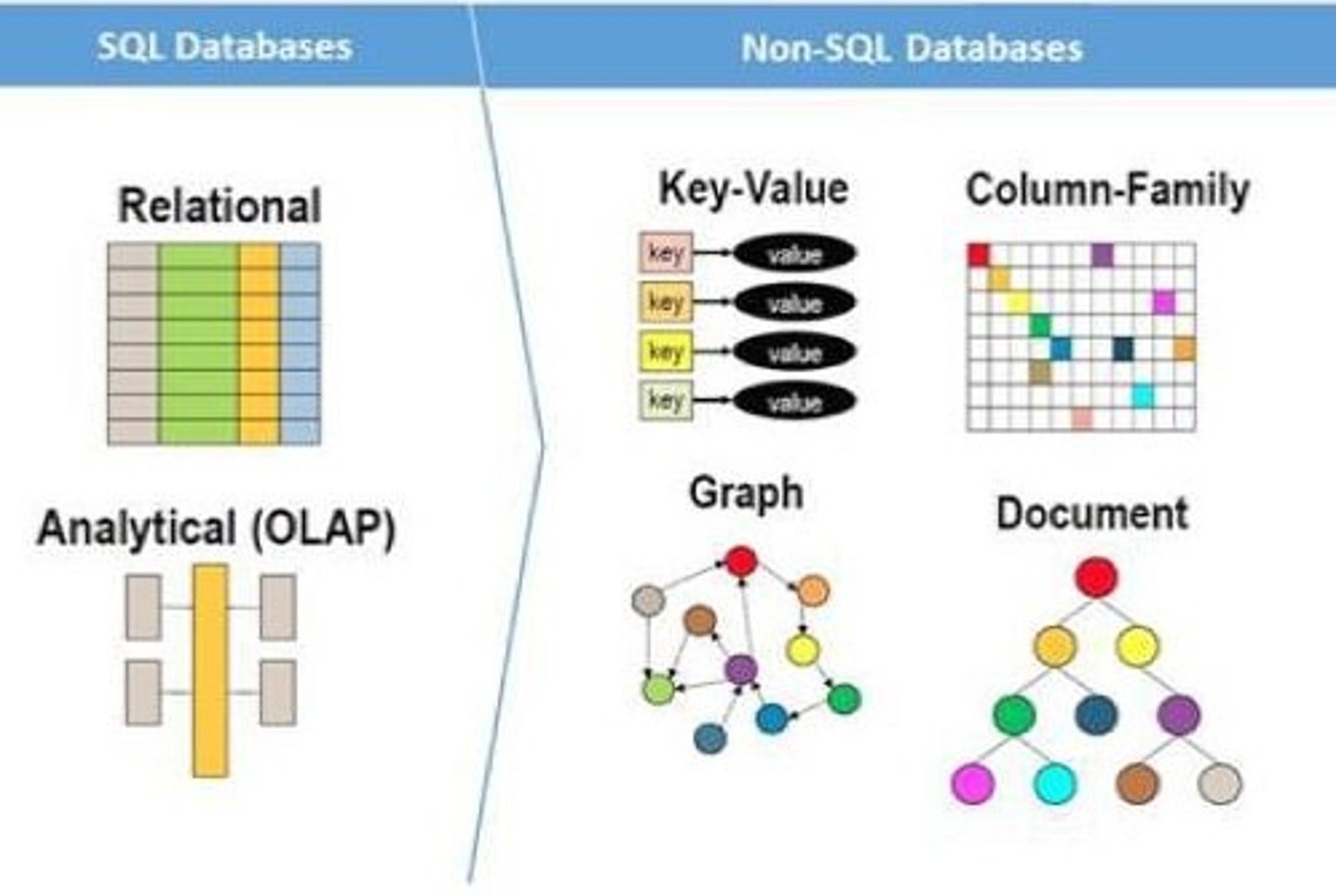
NoSQL Database
Non-relational database for unstructured data.
CAP Theorem
States consistency, availability, and partition tolerance.. there is priority assigned to each one. You must have trade offs. You have to pick TWO!
(Distributed systems can only have 2 at a time, never all 3:
- Consistency
- Availability
- Partition tolerance)
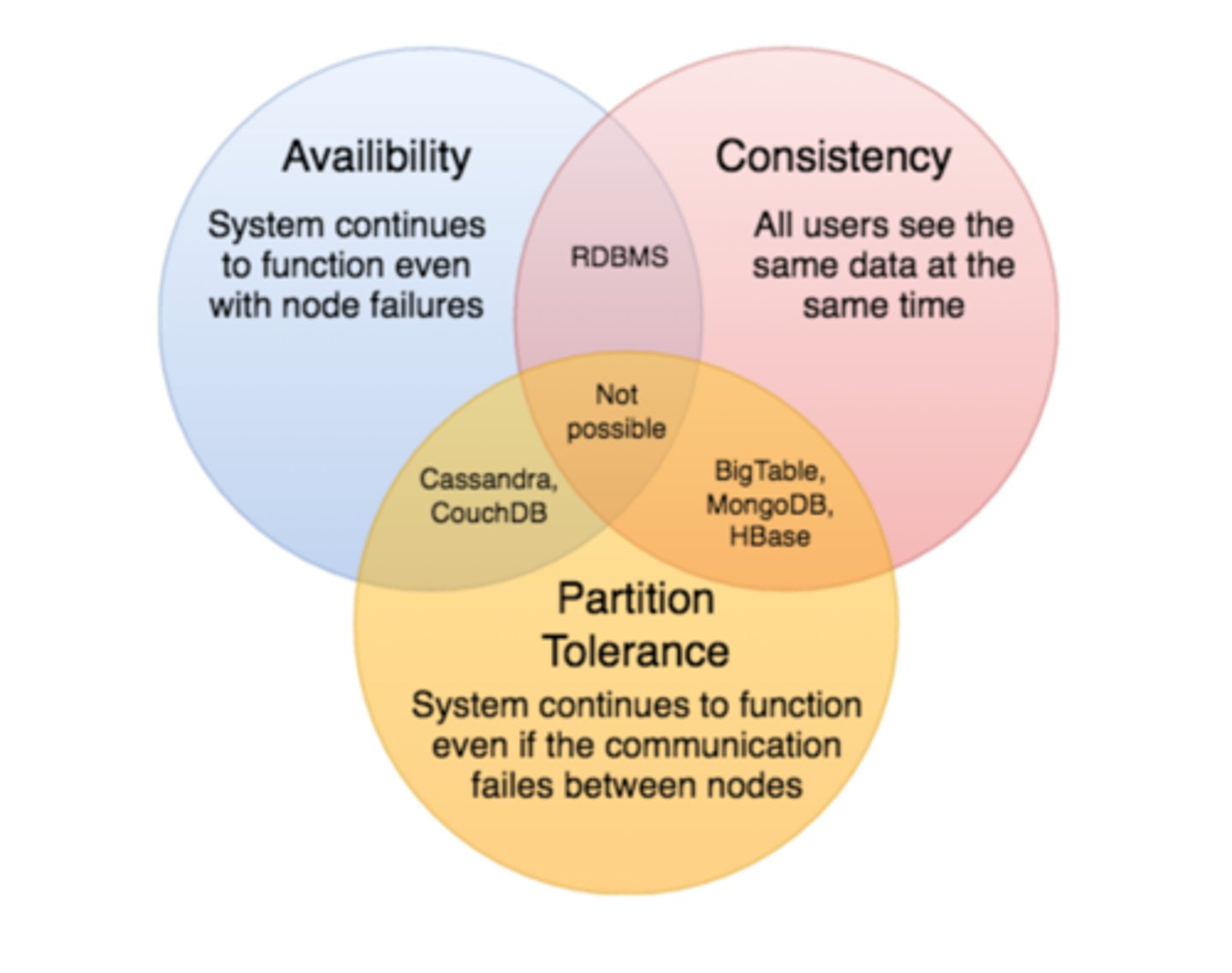
Consistency
Consistent copies of data on different servers
Availability
Response to any query
Partition tolerance
If network partition occurs (inability to send messages between servers) system can still operate correctly
Column Family Database
NoSQL database storing data in columns.

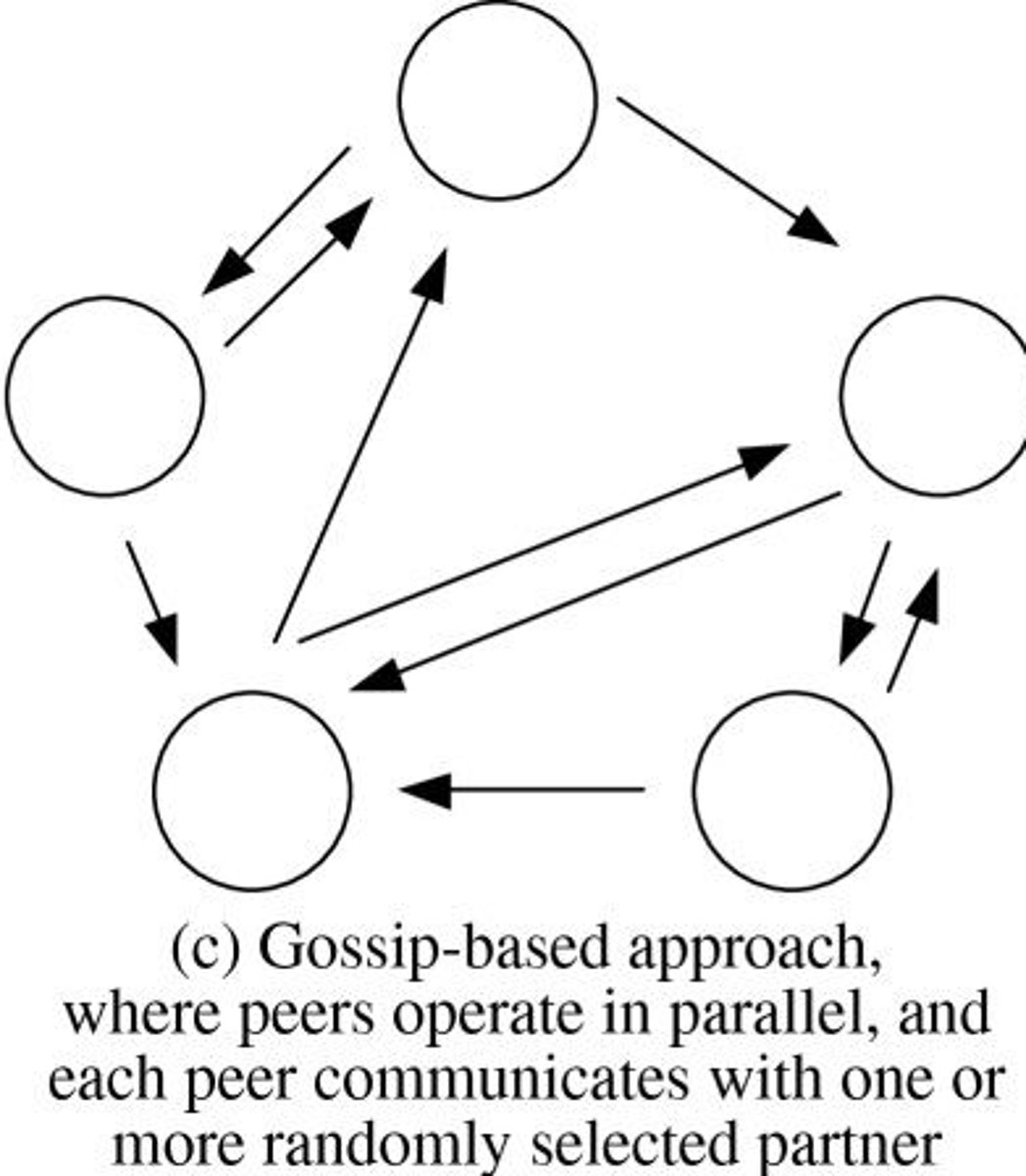
Gossip Protocol
Method for nodes to communicate in distributed systems.
Information Entropy
The more scattered and inconsistent the information is in a database, the higher its entropy.
- Measure of uncertainty in data.
- Cassandra uses an anti-entropy algorithm to correct inconsistencies among replicas.
Indexes (NoSQL)
allow for a rapid lookup of data in table
- Look up keyword (entry) in _________
- Find the page (row location) on book (disk)
- Directly access page (row)
- Each ___________ is a separate table
- allow for a rapid lookup of data in table (DB indexes work like an index of a book).
Create a trigger to do a specific task
DO THE WORK and have chat grade you.
Given PL/SQL code containing a trigger, provide the output after an operation occurs that may fire the trigger:
-- Just the table, not the trigger
CREATE TABLE employees (
id NUMBER PRIMARY KEY,
name VARCHAR2(50),
salary NUMBER
);
INSERT INTO employees VALUES (1, 'John Doe', 50000);
INSERT INTO employees VALUES (2, 'Jane Smith', 60000);
COMMIT;
-- The trigger
CREATE OR REPLACE TRIGGER trg_after_update_employee
AFTER UPDATE ON employees
FOR EACH ROW
BEGIN
DBMS_OUTPUT.PUT_LINE('Employee ' || :OLD.name || ' changed salary from ' || :OLD.salary || ' to ' || :NEW.salary);
END;
/
-- Needs this to FIRE
UPDATE employees SET salary = 55000 WHERE id = 1;
This trigger is fired after an UPDATE operation on the employees table. It logs the employee's name and their salary change.
Employee John Doe changed salary from 50000 to 55000
NoSQL: BASE
BAsically available. Data will be provided from available servers
Soft state: Data in different servers do not have to be mutually consistent
Eventual consistency: Data in different servers will become consistent at some point in time
Relational DB's: ACID
Atomic
Consistent
Isolated
Durable transactions
Relational Databases
Schema: Fixed schema (tables, columns, data types).
Data Model: Structured as tables with rows and columns.
Joins: Supports joins to combine data from multiple tables.
Scaling: Scales vertically (adding more resources to a single server).
Consistency: Strong consistency (ACID properties).
Transaction Support: Fully supports multi-row transactions.
Performance: Optimized for structured data and complex queries.
Use Cases: Best for structured data and complex relationships (e.g., banking).
NoSQL Databases
• Minimal storage and retrieval principle
• No tables, columns, constraints, foreign keys
• No joins
• No SQL
• Mapping to Rel
Schema: Schema-less or flexible schema.
Data Model: Varies: key-value, document, column-family, or graph.
NO Joins: Does not support joins; data is often denormalized.
Scaling: Scales horizontally (adding more servers).
Consistency: Eventual consistency (BASE properties).
Transaction Support: Limited or no support for multi-row transactions.
Performance: Optimized for unstructured data and high-speed operations.
Use Cases: Best for large-scale, unstructured, or semi-structured data (e.g., social media).
Relational DBs
• Tables with rows/cols
• Tables have fixed structure
• Object information may be located in multiple tables (EMP, DEPT, PROJ)
• Join operations match records from diff tables
Column DBs
• There are no tables
• Rows do not have fixed structure
• Object information is in a single (long) row
• There is no join operation
namespace
- a collection of identifiers within Key-value DB
- Keys must be unique within
- may be used for an entire db, Or, the same db may contain >1 _______________,
each one called a bucket
- a container that holds a set of identifiers or names, ensuring that they are unique to avoid any conflict
quorum
the number of servers that must
respond to a read or write operation, for the
operation to be considered complete
For a read operation
- Read from all servers
- Return the value that is equal or greater than a
configurable read-threshold
Using Quorum for Reads
• Read-threshold = 3, return value after 3 servers send same value
• Read-threshold = 1, response time? Consistency?
• Read-threshold = 5, response time? Consistency?
Using Quorum for Writes
- complete when a minimum number of server copies have been written
- Send write to all servers
- The write is complete when the number of servers that updated (made a copy of) the value is equal or greater than a configurable write-threshold
Eventual Consistency
- updates to the database will propagate through the system and eventually all data copies will be consistent
- There are periods of time that same item in different db servers does not have the same value, and the two dbs are inconsistent (temporarily)
- Reads from different db server will return different results (during that period of time)
NoSQL databases often use
Eventual Consistency
NoSQL Types
(Key-Value DBs: A key is associated with a value.
Document DBs: Values are documents (collections of items stored together)-Semi-structured (e.g., JSON, XML).
Column Family DBs: Data stored/organized in columns rather than rows.
Graph DBs: Model objects and relationships
NoSQL Properties
• Scalability
• Flexibility
• Cost control
• Availability
(... & many more)
primary storage media
- Cache (RAM) and main memory
- Fastest media but volatile (cache, main memory)
secondary storage
next level in hierarchy, non-volatile, moderately fast access time
- also called on-line storage
- E.g. flash memory, magnetic disks
tertiary storage
lowest level in hierarchy, non-volatile,
slow access time
- also called off-line storage
- E.g. magnetic tape, optical storage
Magnetic Hard Disk Mechanism: Track
Surface of platter divided into circular
- Over 16,000 per platter on typical hard disks
Magnetic Hard Disk Mechanism: Sector
Each track is divided into __________
- the smallest unit of data that can be read or written.
- size typically 512 bytes
- Typical ______________ per track: 200 (on inner tracks) to 400 (on outer
tracks)
Magnetic Hard Disk Mechanism: Cylinder
refers to the set of tracks that are aligned vertically across all platters in a hard disk at the same radial position.
It represents all the tracks on a hard disk that can be accessed without moving the read/write head laterally.
- a cylindrical intersection through the stack of platters in a disk, centered around the disk's spindle.
- holds a group of tracks that are separated by platters or heads
- the aggregate of the same track number on every platter used for recording.
Access time
the time it takes from start of a read or write request to when data transfer begins.
Consists of:
– Seek time – time to position the arm over the correct track.
• Average seek time is 1/2 the worst case seek time.
• 4 to 10 milliseconds on typical disks
– Rotational latency – time it takes for the sector to be
accessed to appear under the head.
• Average latency is 1/2 of a full rotation of the disk
• 4 to 11 milliseconds on typical disks (5400 to 15000 r.p.m.)
• Data-transfer rate – from or to the disk.
– 50-120 to MB per second is typical
Solid State Drives (SSD)
• Based on flash memory (NAND blocks)
• There are no moving parts
• Contain a controller as a bridge between the OS and the NAND block storage
- Buffer/Cache: High-speed RAM for quick data access.
- Wear Leveling
- OS boot time 10-13 sec
- Access time ~0.1 ms
- Data Transfer Rate 100-600 MB/sec
- Reliability Good, but cannot survive multiple power failures
- Cost $0.35 per GB
- Capacity Up to 16 TB (120-512GB more common)
Durability: Limited write/erase cycles.
Solid State Drives (SSDs)
Mechanics: No moving parts, uses NAND flash memory.
Controller: Handles error correction, wear leveling, and encryption.
Buffer/Cache: High-speed RAM for quick data access.
Performance: Access time: ~0.1 ms.
Data Transfer Rate: 100–600 MB/s.
Reliability: Good but prone to failure after repeated power outages.
Block Wear Issue: Blocks wear out faster with repeated writes; wear leveling helps mitigate.
Capacity: 120 GB to 16 TB.
Cost: ~$0.35 per GB.
Durability: Limited write/erase cycles.
Magnetic Disks (HDDs)
Mechanics: Uses a read-write head close to a platter to store and retrieve magnetically encoded data.
Platter Surface: Divided into tracks (16,000 per platter) and sectors (512 bytes per sector).
Disk Arm: Moves the read/write head to the correct track.
Head-Disk Assembly: Consists of 2 to 4 platters on a spindle.
Performance: Access time: 4–10 ms (seek time) + 4–11 ms (rotational latency).
Data Transfer Rate: 50–120 MB/s.
Reliability: Resistant to catastrophic failure but individual sectors may corrupt.
Capacity: Up to 8 TB.
Cost: ~$0.05 per GB.
Durability: Mechanical wear is common over time.
A table can have only one primary index, as it is tied to the table's primary key
How many primary indexes can a table have?
When is it suggested to create an index?
These are recommended for large tables, fields with a wide range of values, or fields frequently used in searches or joins.
Is an index a table?
- No, it is a separate database object designed to speed up data retrieval by maintaining pointers to the locations of records in the table.
database table index
- Distinct database table
- Contains data values with corresponding columns that specify physical locations of records that contain data values
Creating an Index
CREATE INDEX index_name
ON tablename (index_fieldname);
Create an index when
- Table contains a large number of records.
- Field contains a wide range of values.
- Field contains a large number of null values.
- Queries frequently use field in search conditions or join conditions.
- Most queries retrieve less than 2% to 4% of table rows.
Do not create index when
- Table does not contain large number of records
- Applications do not use proposed index field in query search condition
- Most queries retrieve more than 2% to 4% of table records
- Applications frequently insert or modify table data
- Decision based on judgment and experience
Composite Index
CREATE INDEX index_name
ON tablename(
index_fieldname1,
index_fieldname2, ...);
Is an Index a table?
An index is not a table; however, you may have a table with indexes
- In class, he said its anothertype of table... Google says otherwise.
How many secondary indexes can a table have?
Index on one or more column values. Either DB or application maintains index. If the DB maintains indexes, use them.
- NO MENTION IN SLIDES OR BOOK, MUST BE ANY AMOUNT THEN
- in Amazon DynamoDB, you can create up to 20 global secondary indexes and 5 local secondary indexes per table
When to Use Secondary Indexes Managed by the Column Family Database System
if you need secondary indexes on column values and the column family database system provides automatically managed secondary indexes, then you should use them. (not mentioned)
Database triggers
are objects in the database, operates on tables. When an event occurs, an action is taken
Trigger Events
INSERT, UPDATE, DELETE
Trigger Timing
BEFORE, AFTER
(Defines whether a trigger fires before or after the triggering SQL statement executes)
Trigger Level
ROW, STATEMENT
(Defines whether a trigger fires once for triggering statement or once for each row affected by the triggering statement)
Trigger Action
A PL/SQL code that will automatically execute/fire when event is realized
statement level trigger
only fired once per event
row level trigger
will fire once for each row affected by the event
Create a row level trigger
CREATE OR REPLACE TRIGGER trigger_name
{BEFORE | AFTER} {INSERT or UPDATE or DELETE} ON table_name
FOR EACH ROW [WHEN (condition)]
[DECLARE …]
BEGIN
trigger body
END;
--{} is a must
--[] is optional
--X | Y means X or Y
Create a statement level trigger
CREATE OR REPLACE TRIGGER trigger_name
{BEFORE | AFTER} {INSERT or UPDATE or DELETE} ON table_name
[DECLARE
declare local variables here]
BEGIN
trigger body
END;
-- {} is a must
-- [] is optional
-- X | Y means X OR Y
What is NEW and OLD in triggers
• Use :OLD.fieldname to reference value before the triggering event
• Use :NEW.fieldname to reference value after the triggering even
:OLD.fieldname
to reference value before the triggering event
:NEW.fieldname
to reference value after the triggering even
Commit;
In order for a trigger to be fired on (insert, delete, or update) statements you should add after your statement:
Common Errors for Row-Level Triggers
•Forget for each row
•Forget () for when condition
•Forget to use :new or :old in trigger body and new or old in when condition
Create a row level trigger that fires before the insert operation associated with employees table. The trigger displays the attribute values for first_name and last_name
Set serveroutput on;
CREATE OR REPLACE TRIGGER Inv_update_payment_transfer --make sure this line is not too long.
BEFORE UPDATE OF payment_total ON invoices
FOR EACH ROW
WHEN (NEW.payment_total + NEW.credit_total = NEW.invoice_total)
BEGIN
INSERT INTO paid_invoices (
invoice_id,
vendor_id,
invoice_number,
invoice_date,
invoice_total,
payment_total,
credit_total,
terms_id,
invoice_due_date,
payment_date
) VALUES (
:OLD.invoice_id, -- Use :OLD to reference the previous value of the invoice_id
:NEW.vendor_id, -- Use :NEW for the new value of vendor_id
:NEW.invoice_number,
:NEW.invoice_date,
:NEW.invoice_total,
:NEW.payment_total,
:NEW.credit_total,
:NEW.terms_id,
:NEW.invoice_due_date,
:NEW.payment_date
);
DBMS_OUTPUT.PUT_LINE('New paid invoice inserted');
END;
UPDATE INVOICES set PAYMENT_TOTAL=1575
WHERE INVOICE_ID=81;
Commit;
Create a row level trigger that fires before update operation on payment_total in the invoices table, the trigger should check if the value of payment_total + credit_total is greater than invoice_total . If yes, then a an exception should be raised automatically.
set serveroutput on;
create or replace TRIGGER
Inv_update_payment_transfer
before UPDATE OF payment_total ON invoices
FOR EACH ROW
WHEN (NEW.payment_total = new.invoice_total - new.credit_total)
BEGIN
INSERT INTO paid_invoices
VALUES(:old.INVOICE_ID,
:new.VENDOR_ID,
:new.INVOICE_NUMBER,
:new.INVOICE_DATE,
:new.INVOICE_TOTAL,
:new.PAYMENT_TOTAL,
:new.CREDIT_TOTAL,
:new.TERMS_ID,
:new.INVOICE_DUE_DATE,
:new.PAYMENT_DATE);
DBMS_OUTPUT.PUT_LINE('new paid invoice Inserted');
END;
/
commit;
How to maintain data availability in NoSQL environments?
Use a distributed system (a primary server and a backup/participating server)
Google announced its BigTable in 2006
The first column family DB
BigTable used in
- Web indexing (the typical google search)
- Google Earth
- Google Finance
Similarities/differences with relational databases
Gossip Protocol
• A server (peer) sends information about itself
and other servers it knows about, to another
server
• Information received from servers is aggregated before it is passed on to the next server resulting in information being passed more efficiently
• Version information about each server is also
exchanged
- allows for quick exchange of information