quantitative research methodology
1/155
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
156 Terms
Selvdiagnosticering
en proces, hvori individet identificerer symptomer og tilskriver sig selv en mental helbredstilstand.
Det gøres uden brug af professionel vejledning, men i stedet baseret på personlig research eller information fra sociale medier
Bekræftelsesbias (confirmation bias)
en tilbøjelighed til at søge og forstå information på en måde, der bekræfter ens egne overbevisninger.
Denne menneskelige tendens kan således resultere i, at individer ikke formår at have en neutral vurdering af egne symptomer, men i stedet forstærker en foregående tanke om den pågældende psykiske lidelse
Valideringseffekten (the validation effect)
Effekten beskriver en tilbøjelighed til, at individer opfatter vage og universelle udtalelser på en måde, således de kan finde en mening, der passer specifikt til dem
Denne tendens kan resultere i, at individet øjeblikkeligt identificerer sig med en diagnose på baggrund af indhold på sociale medier, som ofte er præget af den slags vage og universelle udtalelser. Individer vil hurtigt søge en identificering, selvom de mangler forståelse for at symptomerne, som indholdet beskriver, også kan opleves af individer, der ikke har den pågældende diagnose
Sociale medier
muliggør kontinuerlig kommunikation og interaktion mellem brugere og kombinerer elementer fra både masse- og interpersonel kommunikation
karakteriseret ved, at brugerne kan producere og dele indhold, hvilket kan styrke interaktionen på platformen og skabe et digitalt fællesskab
TikTok
en platform, hvor brugere kan skabe videoer på 15 til 60 sekunder.
Særligt for TikTok er dens algoritmestyrede “For You”-funktion, som målretter indhold baseret på brugerens præferencer og tidligere interaktioner
Opmærksomhed
en målrettet koncentration af mentale ressourcer, der gør det muligt for individet at udvælge og bearbejde en begrænset mængde information fra omgivelserne
fungerer dermed som en nødvendighed i mødet med en konstant strøm af sanseindtryk, og er afgørende for, hvilke informationer, der får adgang til videre kognitiv bearbejdning.
Opmærksomhed ift. sociale medier
afgørende for, hvilke stimuli der registreres
ikke al tilgængelig information bearbejdes, men kun udelukkende det, der fanger brugeren.
Opmærksomhed ift. projektet
afgrænser således informationsstrømmen og er med til at forme, hvilke typer indhold, der fremstår meningsfulde for den enkelte.
Perception
en aktiv kognitiv proces, hvor individet anvender sin viden og tidli- gere erfaringer til at indsamle og fortolke sanseindtryk
kombinerer aspekter fra både den ydre og indre verden for at skabe mening
Perception ift. projektet
hvordan personer forstår og bearbejder den nye information
Internalisering
betegner en proces, hvor ydre information assimileres og gradvist kan integreres i individers selvforståelse og selvregulering
Internalisering ift. projektet
forklare hvordan eksponering af diagnoseindhold på sociale medier potentielt kan internaliseres i individets selvforståelse => kan føre til, at personer skaber en ny forståelse af sin psykiske tilstand ud fra symptomer set på sociale medier
ADHD
neuropsykiatrisk udviklingsforstyrrelse
skyldes en kombination af miljømæssige og genetiske faktorer, som påvirker hjernens styring af opmærksom- hed og adfærd samt måde at bearbejde information på
ADHD kernesymptomer
opmærksomhedsproblemer, hyperaktivitet, impulsivitet, og humørsvingninger
Opmærksomhedsproblemer
opmærksomhedsproblemer, koncentrationsbesvær, glemsomhed, samt at have svært ved at lytte til og optage information
Hyperaktivitet
udgøres af flere aspekter, herunder en indre følelse af uro og at have svært ved at sidde stille
Impulsivitet
hvordan individer med ADHD ofte afbryder andre, er utålmodige, og foretager handlinger uden at tænke nærmere over konsekvenserne
Humørsvingninger
henviser til et typisk iltert temperament og mange ændringer i humøret på daglig basis
Falsifikationsprincippet
hensigt at kunne modbevise vores opstillede hypotese og ikke blot søge at bekræfte dem.
Hvis hypoteserne ikke afvises, er det ikke ensbetydende med verifikation, men blot at hypoteserne har fundet støtte
Den hypotetisk-deduktive metode
kombination af opstilling af hypoteser og deduktion
Formålet med metoden er, at forskeren anvender teorier til at udvikle og afprøve hypoteser, som derefter testes gennem observationer og eksperimenter. Teorien danner rammerne for at forstå, hvordan fænomener hænger sammen.
Hypotese
en testbar påstand om verden, der udspringer af generelle mønstre eller teorier.
Formålet er at formulere en forudsigelse, der kan operationaliseres ved at gå fra generelle teorier til noget, der kan observeres og måles
Deduktion (ift. den hypotetisk-deduktive metode)
Deduktion går man fra de teoretiske forudsætninger til en konkret afprøvning af teorien i form af en testbar forudsigelse. Det betyder, at hvis noget observeres, kan det antages, at det kan generaliseres til fremtidige tilfælde.
Data støtter hypotesen over tid
Det betyder ikke nødvendigvis, at den er sand, men indikerer blot, at der ikke er tilstrækkelig evidens til at afvise den.
Data giver negative eller blandede resultater
Sandsynligheden for at kunne afvise eller revidere hypotesen øges.
Den kvantitative metode
Forskningsmetode, der fokuserer på at opnå viden ud fra kvantificerbare data, som repræsenteres numerisk gennem målinger eller optællinger
Nettet:
Metode der arbejder med tal, målinger og statistisk analyse.
Formål: generalisering.
Spørgeskema
Faktuelle og adfærdsmæssige, holdningsmæssige, demografiske, samt vidensmæssige.
Kan afdække en stor mængde respondenter på forholdsvis kort tid.
Fået adgang til individer, som vi ikke ellers havde haft adgang til.
Tidsbesparende, idet dataindsamlingen kan foregå samtidig med øvrige opgaver
Demografiske spørgsmål
uddannelse, køn, hvor de er fra osv.
Adfærdsmæssige spørgsmål
spørge ind til hvornår, hvor, eller hvor ofte noget er sket, hvilket kan bidrage til en forståelse af respondentens oplevelser og erfaringer.
Likert skala
Rensis Likert
Bruges som et psykometrisk værktøj
Ordinalskala brugt til holdningsmålinger
Bygger på niveauet af enig- eller uenighed hos respondenterne med en række udsagn relateret til eksempelvis objekter, personer eller begivenheder.
Likert skala ift. projektet
I stedet for at undersøge enig- eller uenighed hos respondenterne, anvender vi en variation af valgmuligheder, der undersøger hyppigheden af symptomerne fra spørgsmålene
Validitet
undersøgelsens gyldighed og omhandler, hvorvidt et måleinstrument måler det, som tilstræbes.
= om man faktisk måler det, man tror at man måler.
Intern validitet
hvor høj grad en effekt i undersøgelsen kan tilskrives manipulation af den uafhængige variabel og ikke konfunderende variable.
refererer til, hvorvidt et studies procedure, måleudstyr, spørgsmål, analyser osv. tillader forskeren at måle det, som studiet er designet til at måle.
Det beskæftiger sig med, hvorvidt der er en kausal forbindelse mellem den uafhængige- og afhængige variabel
Ekstern validitet
undersøgelsens resultater kan generaliseres til kontekster, der er anderledes end den eksperimentelle
refererer til, hvorvidt et studies resultater kan generaliseres til de situationer og befolkningsgrupper, som studiet forsøger at undersøge ude i den virkelige verden.
Reliabilitet
overensstemmelsen af den psykologiske skala, og omhandler, hvorvidt undersøgelsens resultater kan reproduceres
= hvor stabilt og præcist måleinstrumentet er fx Cronbach’s alfa.
Intern reliabilitet
undersøgelsens konsistens i sig selv, og det er vigtigt for den interne reliabilitet, at respondenter svarer tilsvarende på lignende spørgsmål og ikke modsiger sig selv
Ekstern reliabilitet
resultaternes stabilitet på tværs af forskellige kontekster.
vigtigt for en undersøgelses eksterne reliabilitet, at den samme stikprøve producerer samme resultat hver gang den testes
Cronbach’s alfa
Et mål for reliabilitet, der angiver, hvor godt de enkelte elementer i en skala hænger sammen og måler den samme underliggende egenskab.
For at kunne vurdere at en test har tilstrækkelig reliabilitet, skal værdien for Cronbach’s alfa være på omkring .75 til 1
Hvis variansen er høj for de individuelle elementer i relation til variansen i den overordnede test => lav reliabilitet => testen vurderes som upålidelig.
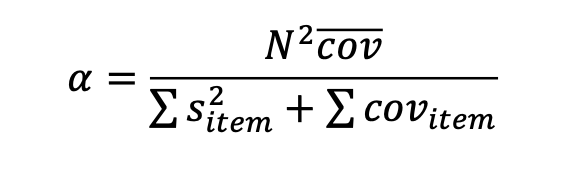
Hypotesetestning
Det undersøges, om data giver statistisk støtte til hypotesen ved hjælp af matematiske metoder, som anvendes til at afdække mulige sammenhænge eller effekter i data
Variable
For at kunne teste en hypotese må man identificere og måle relevante …, der kan variere på tværs af individer, geografiske enheder eller over tid
Den uafhængige variabel
Den variabel man manipulerer eller grupperer efter (årsag).
Forskeren manipulerer eller antager som den mulige årsag.
Den afhængige variabel
Den variabel man måler (effekt).
Det repræsenterer den målte effekt og antages at afhænge af den uafhængige variabel
Konfunderende variable
En tredje variabel, der har indflydelse på både den uafhængige variabel og afhængige variabel, og dermed kan påvirke den egentlige relation mellem dem
Nulhypotese H0
Angiver, at der ingen reel effekt er, og at de observerede resultater skyldes tilfældigheder,
Alternative hypotese H1
forudsiger en faktisk effekt baseret på den underliggende teori
Signifikansniveau (p-værdi)
Sandsynlighed for at få resultatet, hvis nulhypotesen er sand. Typisk p < 0,05 som grænse.
Angiver sandsynligheden for at få det observerede resultat, hvis H0 ikke forkastes
Det vurderes, at resultatet er statistisk signifikant (værdi mindre end .05) => H0 forkastes.
Det betyder dog, at H1 er sand, men at der er tilstrækkelig evidens til at støtte den.
Type I fejl
hvis det antages, at der er en effekt, når den reelt ikke eksisterer i en population. Risikoen, for at denne fejl kan forekomme, betegnes som alfa-niveauet og er .05 ved brug af standardkriteriet, forudsat at der ingen reel effekt er.
=> Her forkastes H0, selvom den er korrekt.
Type II fejl
Det antages, at der ikke er en effekt, selvom den reelt eksisterer i en population
=> Her forkastes H0 ikke, selvom den er forkert.
Denne type fejl kan ske, hvis man indsamler en lille test statistik, fordi der eksempelvis kan være naturlig varians i ens stikprøve
Jævnfør Jacob Cohen (1992 if. Field, 2018, p. 82) bør den maksimalt acceptable risiko for Type II fejl være .20, hvilket betegnes som beta-niveauet.
Statistisk styrkeberegning
Vurdere, hvor stor vores stikprøve skal være for at identificere en effekt med tilstrækkelig sandsynlighed.
Det angiver sandsynligheden for at opdage en effekt, hvis den reelt findes i populationen.
Standardværdierne er ofte 𝛼 = .05 og 1-β = .8.
Kan beregnes som 1-β, og en styrke på minimum .8 anses generelt som tilstrækkelig til at opdage en reel effekt
Effektstørrelse
Er den faktiske forskel, som man finder i sit studie. Viser hvor stor forskellen/ sammenhængen er.
Standardiseret mål, som gør det muligt at sammenligne resultaterne på tværs af studier
Cohens d, Pearsons korrelationskoefficient r & oddsratio
Cohen’s d
angiver den gennemsnitlige forskel mellem to grupper
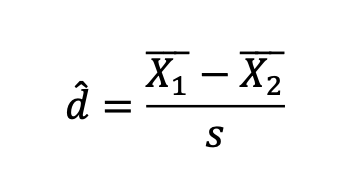
Shapiro-Wilk testen
vurdere, hvorvidt et datasæt er normalfordelt.
Testen konstruerer en teoretisk normalfordeling ud fra datasættets gennemsnit og standardafvigelse. Efterfølgende sammenlignes de observerede værdier med denne fordeling.
p > .05 => ikke er en signifikant afvigelse fra normaliteten, og datasættet kan derfor betragtes som normalfordelt
p < .05 => en signifikant afvigelse fra normalfordelingen
Standardfejl
et mål for, hvor repræsentativt vores stikprøvegennemsnit afviger fra den sande værdi i en population
Skævhed
Hvorvidt data er fordelt symmetrisk eller asymmetrisk omkring gennem- snit. Ved skæve fordelinger ligger de fleste værdier grupperet enten mod højre eller venstre
Skævhed = 0
en symmetrisk fordeling => normalfordeling
Positiv skævhed (skævhed > 0)
en lang hale i histogrammet, hvilket betyder, at der er mange lave værdier og få høje
Negativ skævhed (skævhed < 0)
illustreres som en lang hale til venstre på histo- grammet med mange høje værdier og få lave
Kurtosis
graden af, hvor spids eller flad en fordeling er, sammenlignet med en normalfordeling
Positiv kurtosis
værdien er > 0.
Histogrammet fremgår spidst, idet det har tunge haler og mange ekstreme værdier.
Negativ kurtosis
værdien er < 0
Histogrammet vil være mere fladt fordelt med få ekstreme værdier, hvorfor det fremstår mere jævnt
Varians
Et mål for, hvordan dataen i et datasæt afviger fra gennemsnit og viser spredningen af dataudfald omkring gennemsnit
Hver gang vi måler noget, så får vi altid varians f.eks. Hvis man måler en æske med tændstikker, så vil alle tændstikker afvige en smule fra gennemsnittet.
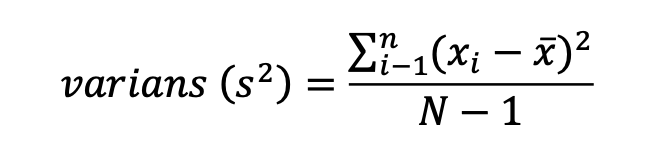
I formlen beskrives stikprøvens varians (s2); den enkelte observation (xi); Gennemsnit af obser- vationerne (x), hvilket udgør den kvadrerede standardafvigelse fra gennemsnittet (Field, 2018, p. 30f). Derudover ses antallet af observationer i stikprøven (N).
Levene’s test for ensartet varians
Ved at bruge denne test kan man identificere heteroskedasticitet (ændring i varians på tværs af grupper). Der testes om variansen er ens i forskellige grupper.
Hvis testen er signifikant (p ≤ 0.05), betyder det, at variansen er forskellig, og antagelsen om homoskedasticitet er brudt. Man vil derfor efter en rettelse
Hvis testens p-værdi er ikke-signifikant (p > 0.05), kan man konkludere, at variansen er ens, og antagelsen om homogeniteet/ensartet varians holder.
Variansen af en undersøgelses udfald bør være den samme i hver stikprøve
T-test for uafhængige stikprøver
testning af sammenligning af gennemsnittene for to forskellige grupper for at kunne afgøre, om der findes en statistisk signifikant forskel mellem dem => bruges til between-subjects design
Generelt gælder det, at H0 hævder, at de to gruppers gennemsnit vil være ens. T-testen bruges derfor til undersø- gelsen af, hvorvidt forskellen mellem gruppens gennemsnit er signifikant.
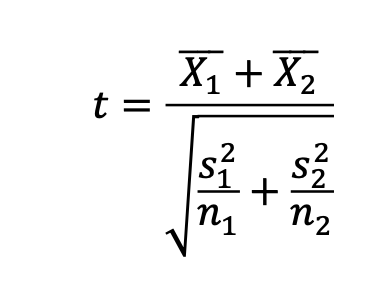
I formlen beskrives gennemsnit (X̅ 1) og (X̅ 2) for grupperne; varians, eller kvadreret standardaf- vigelse (s2) for grupperne; antal observationer i hver gruppe (n) (Field, 2018, p. 449f).
Bootstrap
En statistisk metode, der anvendes til at estimere egenskaber ved en stikprøvefordeling uden antagelsen om, at dataene følger en normalfordeling.
Relevant, når man arbejder med data, der ikke er normalfordelte, eller hvis datasættet indeholder ekstreme outliers, der kan påvirke resultaterne.
Virkning: gentagne gange trækker den tilfældige stikprøver fra den oprindelige stikprøve ved at lægge hver observation tilbage i stikprøven, før en ny trækkes.
Percentil-konfidensinterval
Særlig metode til at beregne konfidensintervaller i bootstrap.
Man genererer mange resamples (bootstrap samples), beregner estimatet for hver, og sorterer dem.
Man tager så fx de nederste 2,5% og øverste 2,5% værdier blandt disse estimerede værdier som grænserne for 95% KI. Intervallet fortæller: "Vi er 95% sikre på, at det rigtige gennemsnit ligger et sted mellem de her to værdier."
Den uafhængige variabel i projektet
Eksponering for diagnoseindhold.
Blev operationaliseret gennem to forskellige versioner af spørgeskemaet
Den afhængige variabel i projektet
Graden af selvdiagnosticering, som måles gennem et spørgeskema, hvor deltagerne bliver bedt om at angive, hvor ofte (Likert-skala) de oplever en række symptomer relateret til ADHD.
Potentielle konfunderende variable i projektet
Alder; køn; uddannelsesniveau; beskæftigelsesstatus; omfanget af brug af sociale medier; eksisterende kendskab til ADHD; tidligere eksponering for lignende indhold.
ASRS-v1.1
Screeningsværktøj, der består af 18 kriterier for ADHD. Skemaet opdeles i to afsnit. Afsnit A indeholder seks spørgsmål, der er særligt in- dikatoriske for ADHD. Afsnit B består af de øvrige 12 spørgsmål, som giver yderligere indsigt, men indgår ikke i en samlet score og angiver i sig selv ikke en diagnostisk sandsynlighed. Denne opdeling er udviklet med henblik på klinisk screening og diagnostisk vurdering
Tre generelle forskningsetiske krav om informeret og frivilligt samtykke
Information, kompetence & frivillighed
Nordens fælles etiske hovedprincipper
Respekt for klientens rettigheder og værdighed; kompetence; ansvar; integritet
Respektprincippet
udvise respekt og tilskynder at fremme personers rettigheder, værdighed og integritet
Respektprincippet i projektet
fuld anonymisering af respodenterne & at besvarelserne udelukkes anvendes ift. projektet
Kompetenceprincippet
hvordan man vil bestræbe sig på at vedligeholde og udvikle sine faglige kompetencer i takt med sit arbejde
Kompetenceprincippet i projektet
Bevidstheden om begrænsningerne ved vores kompetencer som psykologistuderende. For ikke at bevæge os ud over eget kompetenceniveau, er der derfor anvendt den diagnostiske skala, ASRS v1.1.
Ansvarsprincippet
indebærer det videnskabelige ansvar for at forblive professionel og ansvarlig for ikke at gøre nogen former for skade
Ansvarsprincippet i projektet
projektet omhandler en psykisk lidelse og spørgsmålene tager udgangspunkt i diagnostiske vurderingsspørgsmål. Vi har derfor nøje overvejet de etiske dilemmaer og konsekvenser.
I spørgeskemaerne stilles ikke en endelig diagnose efter afsluttet besvarelse, ligesom der ikke bliver udleveret en opsummeret score for graden af selvdiagnosticering samt for mængden af ADHD-symptomer. Dette er for at beskytte individet mod unødvendig skade, men også fordi vi som psykologistuderende ikke har kvalifikationerne til at kunne udføre sådan en vurdering.
Integritetsprincippet
hvordan man i det psykologiske felt skal søge at fremme integritet og ærlighed samt fremtræde respektfuld over for involverede individer
Integritetsprincippet i projektet
Så transparente som muligt omkring processen. Dette indebærer overvejelser omkring forskningsformålet, projektets me- todevalg, samt de ovenstående etiske overvejelser i forhold til respondenternes deltagelse i pro- jektets undersøgelse.
Outliers
En observation, der afviger markant fra resten af datasættet (ekstrem værdi). Outliers kan trække gennemsnittet op eller ned.
Når outliers afviger markant fra de øvrige data, kan det skjule den reelle variation og forvride centrale estimater som gennemsnit og standardafvigelse, hvilket gør det vanskeligere at vurdere, om der er en faktisk forskel mellem grupperne.
Within-subjects design
“Definition”
Design hvor de samme personer undersøges under forskellige niveauer af en given uafhængig variabel (faktor)
Før-og-efter forsøg er hvor de samme personer er involveret.
Den samme person kan bruges som sin egen kontrol-person.
Projektet
Respondenterne skulle besvare de samme 18 spørgsmål både før og efter eksponeringen.
Et sådant design ville have gjort det muligt at undersøge ændringer i individets egen vurdering. Det blev dog konkluderet, at dette design ville øge risikoen for læringseffekter og bevidsthed om eksponeringen, hvilket kunne påvirke målingen af den effekt, vi havde til hensigt at undersøge.
Between-subjects design
“Definition”
Design hvor forskellige personer optræder under forskellige niveauer af en given uafhængig variabel (faktor)
Forskellige grupper af respondenter i hver gruppe (fx kontrol- og eksperimentalgruppen.
Én gruppe oplever betingelse A, en anden oplever betingelse
Projektet:
Valget af forskningsdesign medfører dog visse metodiske begrænsninger. Eftersom hver re- spondents besvarelse blot måles én gang, er der større risiko for, at observerede forskelle skyl- des variation mellem grupperne snarere end effekten af eksponeringen alene. Dette blev afspej- let i vores data, hvor kontrolgruppen udviste en mere markant skævhed og højere kurtosis sam- menlignet med eksperimentalgruppen. For at imødekomme denne udfordring blev randomise- ring anvendt ved allokering af grupper.
Central tendency bias
=> respondenter har tendens til at undgå ekstreme værdier med henblik på svarmuligheder.
Tendensen kan have haft indflydelse på vores resultater, idet respondenterne muligvis har undgået disse svarmuligheder.
Likert skalas midterværdi
“Nogen gange”
Tvetydig betydning i valget af denne besvarelse, da den både kan betyde, at respondenten har en neutral position i henhold til spørgsmålet, eller at de er splittet mellem hvilken retning, de tilhører.
Denne pointe kan ydermere have påvirket respondenternes svar, eftersom de enten ikke har vidst, hvad de skulle svare, eller har været usikre omkring selve udsagnet i spørgsmålet.
Intern reliabilitet i projektet
anvendt crobach’s alfa.
Den lave interne reliabilitet betyder, at vi må udvise en vis usikkerhed om måleinstrumentets kvalitet i sammenhæng med indeværende projekt og dermed også, hvorvidt vi kan drage konklusioner på baggrund af vores resultater.
Ekstern reliabilitet i projektet
Det vurderes ved at tage stilling til dets stabilitet på tværs af forskellige kontekster.
Forsøgt ved at søge demografiske oplysninger om vores respondenter i spørgeskemaerne samt beskrive vores procedure så udførligt som muligt.
Med henblik på hvorvidt respondenternes svar er konsistente, kan der antages at være en vis usikkerhed. Spørgeskemaet blev udfyldt efter én eksponering, hvorfor det er uklart, hvorvidt deres rapportering af symptomer havde været anderledes efter gentagen eksponering. På denne måde er der risiko for, at vores resultater illustrerer en kortvarig og situationel reaktion og ikke en stabil vurdering af egne symptomer. Det kan heraf være vanskeligt at drage konklusioner om, hvorvidt projektet har en høj ekstern reliabilitet.
Intern validitet i projektet
Vi har forsøgt at styrke projektets interne validitet gennem vores forskningsdesign.
Dette har skabt forudsætningerne for en vurdering af, hvorvidt eksponeringen har haft en reel effekt på graden af selvdiagnosticering. Ved at inddrage en kontrolgruppe mindskes risikoen for konfunderende variable. Den manglende effekt peger dog på, at eksponeringen ikke påvirker selvdiagnosticering i konteksten af vores specifikke undersøgelse. Dette kan understøtte projektets interne validitet, idet vi med rimelighed kan antage, at vores data ikke er blevet påvirket af konfunderende variable, der kan have skabt en kunstig effekt. Der kan imidlertid forekomme usikkerhed omkring visse konfunderende variable, som kan have skjult en reel effekt og dermed svækket projektets in- terne validitet.
Ekstern validitet i projektet
vurderes gennem overvejelser om, hvorvidt vores resultater kan generaliseres til andre kontekster fx replikation og projektets transparens.
Der er dog visse forhold, der kan have svækket den eksterne validitet.
Indledningsvist er det usikkert, hvorvidt resultaterne blot afspejler den eksperimentelle situation. På trods af bestræbelserne på at skabe en realistisk repræsentation gennem en autentisk TikTok- video, er det vanskeligt at rekonstruere den virkelige situation, hvor individer ofte udsættes for gentagen eksponering.
Vi kunne med fordel have inkluderet flere eksponeringer for yderligere at tilnærme os en virkelighedsnær oplevelse.
Sammensætningen af vores stikprøve have svækket den eksterne validitet.
KORT om projektet (hvad vi ønsker at undersøge, formålet og resultatet)
undersøge, hvorvidt en enkelt eksponering for diagnoseindhold om ADHD påvirker individers perception af egne psykologiske symptomer.
projektet bidrager således til eksisterende litteratur ved at anvende et between-subjects design til at under- søge effekten af én kortvarig eksponering af diagnoseindhold om ADHD.
Projektets statistiske analyse fandt ikke nogen signifikant effekt, og vi kunne dermed ikke forkaste H0.
Fremtidig forskning i projektet
Faktorer såsom
længerevarende
gentagen eksponering
individers forhåndsviden
tidligere erfaringer med denne type indhold
autentisk og mere virkelighedsnær TikTok-format
kan potentielt have en mere væsentlig indflydelse. Disse faktorer ville være relevante at undersøge nærmere gennem en lignende undersøgelse.
Nominalskala / Kategoriskala
“Definition”
Observationer indordnes efter kategori
Kategorier uden rangorden
Ingen ens intervaller
Intet absolut nulpunkt
Kan kodes med tal (fx 1 kvinde, 2 mand), men tallene har ingen værdi
Eksempel
Køn (mand, kvinde, andet)
Nationalitet
Religionskategori (buddhist kristen, muslim mv.)
Blodtype (A, B, AB, 0)
Øjenfarve (brun, blå, grøn)
Postnummer
CPR-nummer (unik identifikation)
Ordinalskala
“Definition”
Observationer indordnes efter rækkefølge
Minder på mange måder om nominalniveau, men kan dog rangordnes. Dog er afstanden mellem kategorierne ukendt.
Eksempler
Uddannelsesniveau (folkeskole, gymnasium, bachelor, kandidat, ph.d.)
Smerteniveau (mild, moderat, stærk)
Holdninger (negativ, positiv, neutral)
Placering i en konkurrence (1., 2. el. 3. plads)
7-trinsskala (karakterer på uni)
Socioøkonomisk status (lav, middel, høj)
Likert-skala (enig, lidt enig, neutral, lidt uenig, uenig)
Intervalskala
“Definition”
Ens intervaller, men 0 er ikke "intet" fx år 0.
Man kan ikke sige "dobbelt så meget"
Data der kan rangordnes efter en enhedsskala. Hver enhed stiger eller falder er den samme enhed.
Numeriske data med ens intervaller, men uden absolut nulpunkt.
Observationer indordnes efter værdi og hvor der er præcise angivelser af afstanden mellem målepunkt
Eksempler:
Temperatur i Celsuis eller Fahrenheit
Årstal
Klokkeslæt på et døgn (fx kl. 12 er ikke dobbelt så meget som kl. 6)
Kalenderdatoer
Ratioskala
“Definition”
Numeriske data med ens intervaller og et absolut nulpunkt, så man kan lave forholdsberegninger (fx 6 kg er dobbelt så meget som 3 kg)
Samme skala som en interval-skala men hvor skala har et ægte nulpunkt
Eksempler:
Højde
Vægt (kg, g)
Længde (cm, m, km osv.)
Alder (i år, måneder)
Indkomst i kroner
Antal børn i en familie (fx kan man ikke have 1,5 barn)
Deskriptiv statistik
Beskrivende statistik, hvis formål er at opsummere og visualisere data uden at drage konklusioner.
give et overblik – hvordan skal vi forstå overblikket over ens data
Fx histogram (fx normalfordeling, skævhed), boksplot (median, kvartiler, outliers), middelværdi, median, standardavigelse, frekvenser osv.
Inferentiel statistik
= statistik hvorfra vi kan udlede noget. Tester hypoteser på baggrund af stikprøvedata.
Fx t-test, ANOVA, korrelation, bootstrap t-test
Operationalisering
angiver en mere eller mindre valid metode til at måle en (del af en) hypotetisk konstruktion fx intelligens
Hvordan du omsætter et teoretisk begreb til noget målbart (fx ADHD-symptomerne)
Analysis of variance (ANOVA)
Sammenligner gennemsnit (3+ grupper)
Korrelation (fx Pearson / Spearman)
forhold mellem variablerne, således at de hænger sammen (optræder sammen).
Siger noget om hvor tit noget sker
Hvor stærk sammenhængen er
og hvor godt passer sammenhængen på en lineær model
Regression
Forudsiger AV ud fra UV’er fx R² og standardfejl
Randomisering
Når et andet variabel, end det tilsigtede uafhængige variabel skaber variansen hos den afhængige variabel
