3-6. Efficient Inference with Transformers
1/28
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
29 Terms
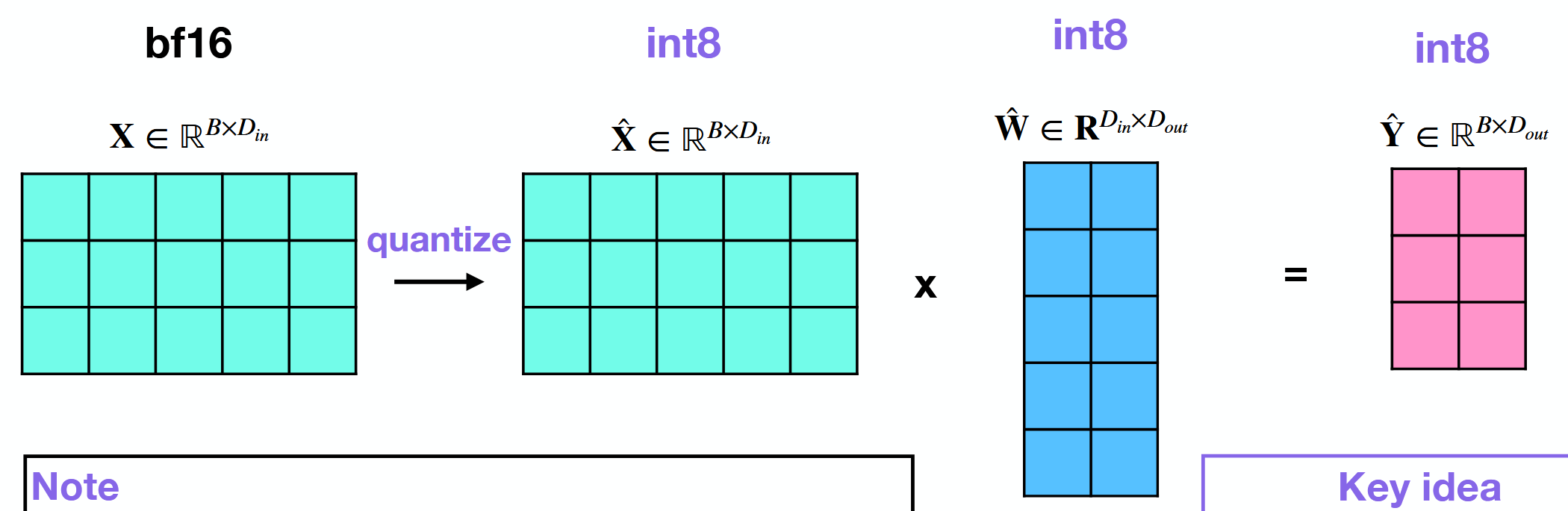
What is the advantage of also quantizing activations (inputs) in addition to the weights of a model?
All operations are then in int8.
GPU can leverage custom integer kernels.
What are disadvantages of quantizing activations (inputs)?
Activations change with every new prompt → quantization scale has to be set for every new input.
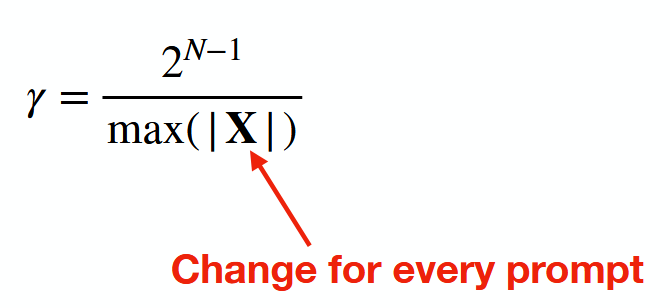
Dynamic vs. Static quantization of activations (inputs)
Dynamic:
Learn the scale for every input on the fly.
Accurate but slow.
Static:
Use a calibration dataset to learn static scale.
Fast but less accurate.
What is the idea of LLM.int8() quantization?
Problem: There are outliers in models > 3b parameters that take valuable quantization space.
Do not quantize outliers (less than 1% of weights).
Rest is quantized to int8.
=> Mixed Precision Quantization.
What is the idea behind GPTQ?
Minimize loss between output of quantized and unquantized matmul.
Updates unquantized weights to minimize.
Quantizes to lower than 8-bits, f.e. 4 or 2 bits.
Needs a calibration dataset.
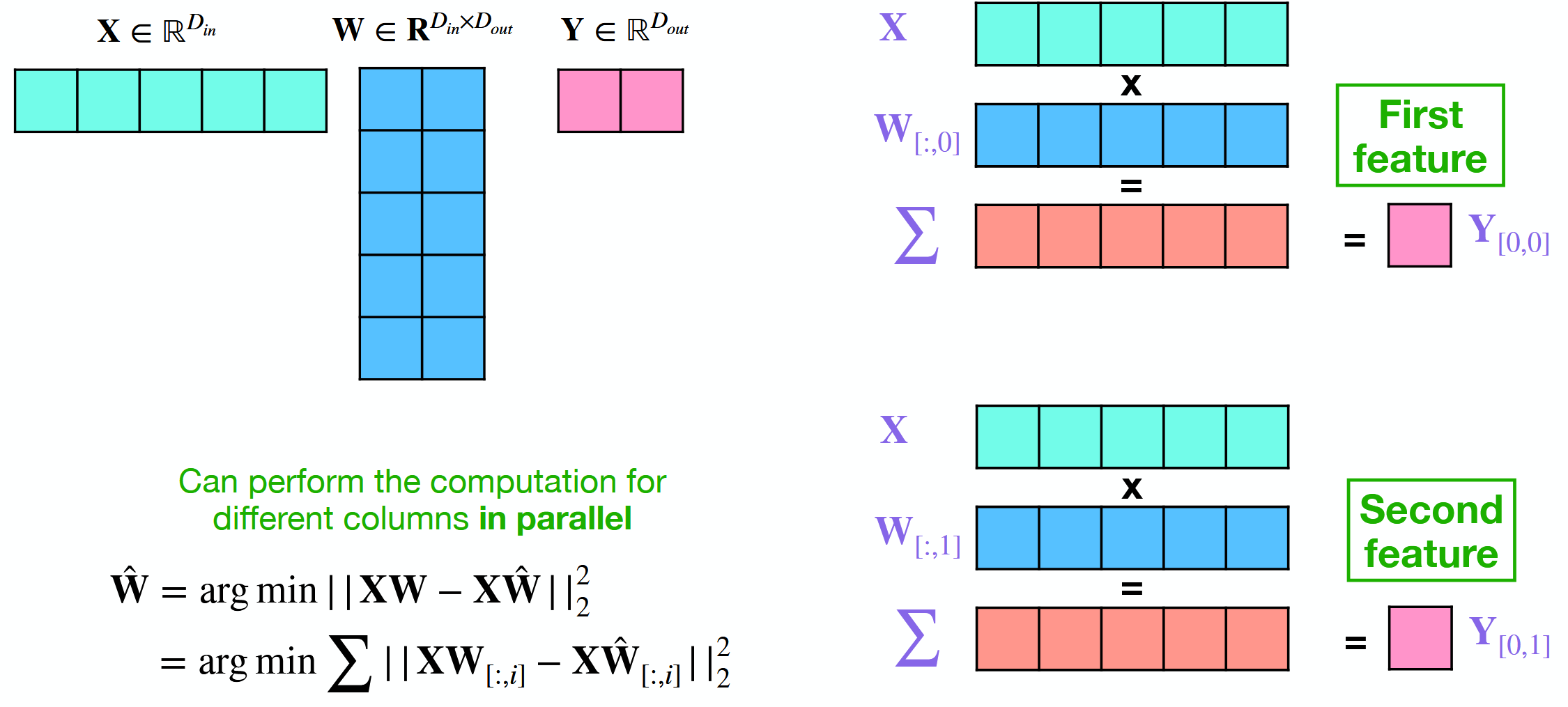
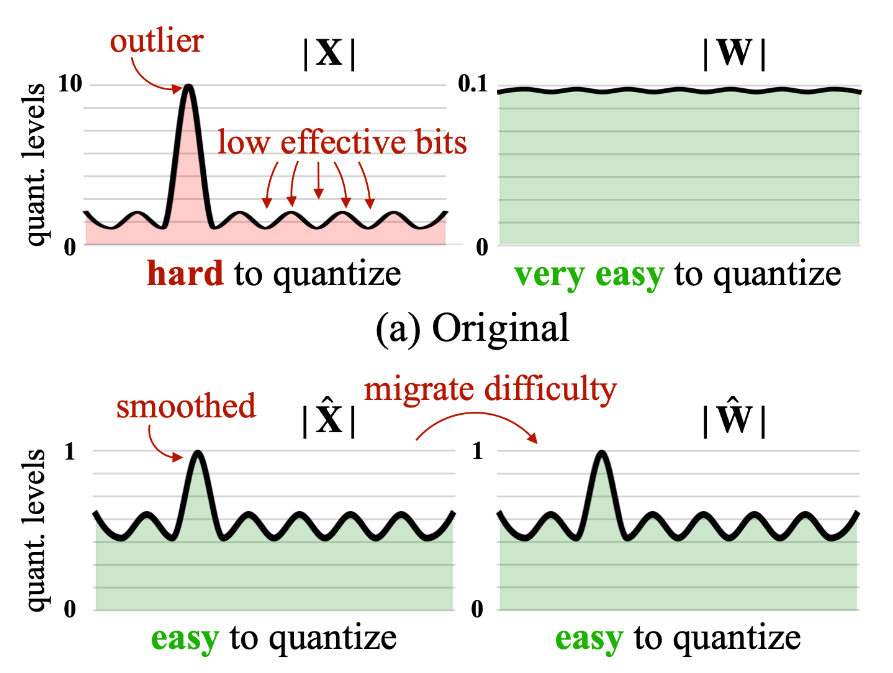
What is the idea behind SmoothQuant?
Migrate outliers between activations (many outliers) and weights (few outliers) to use quantization space more efficiently.
Needs a calibration dataset.
Can be mixed with other Quantization strategies.
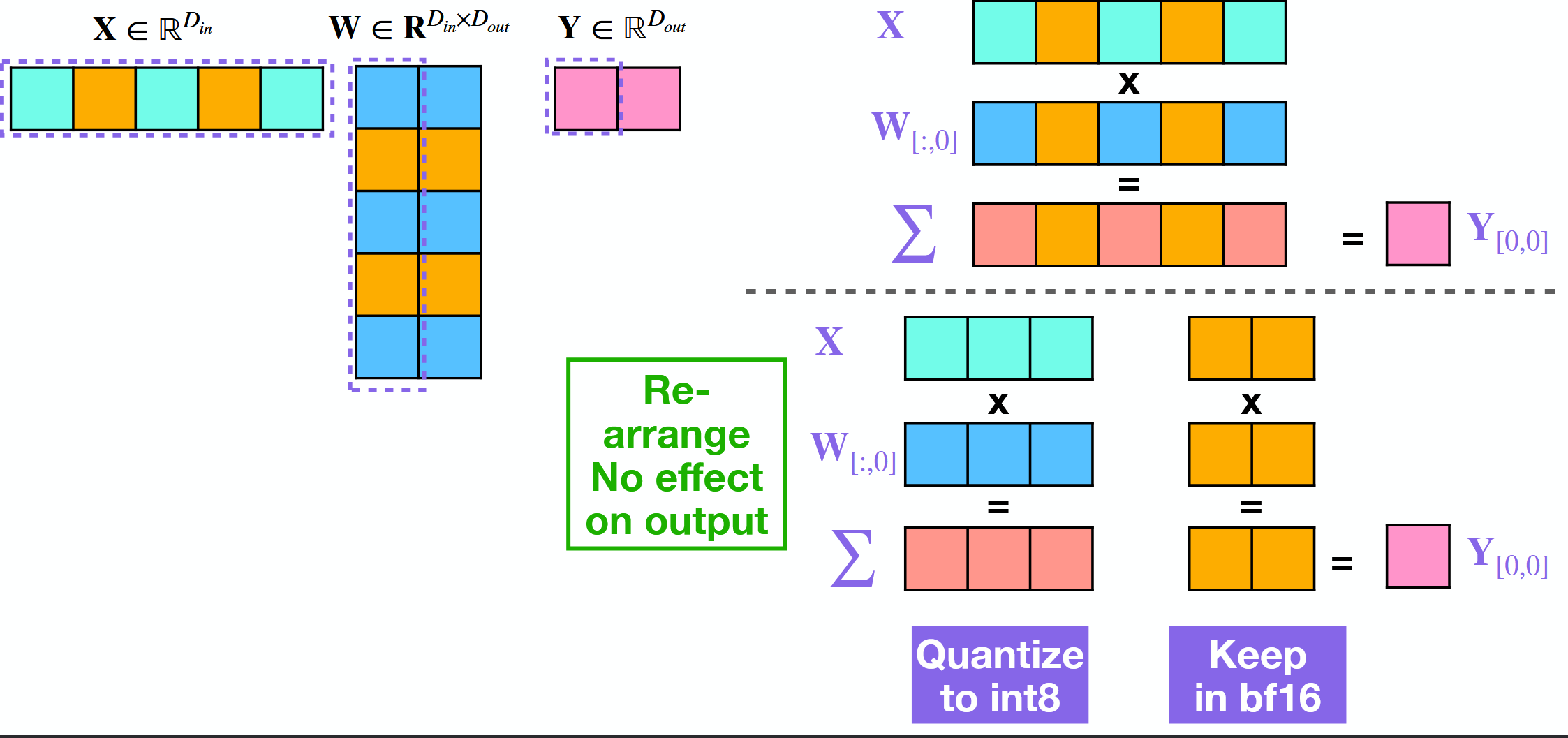
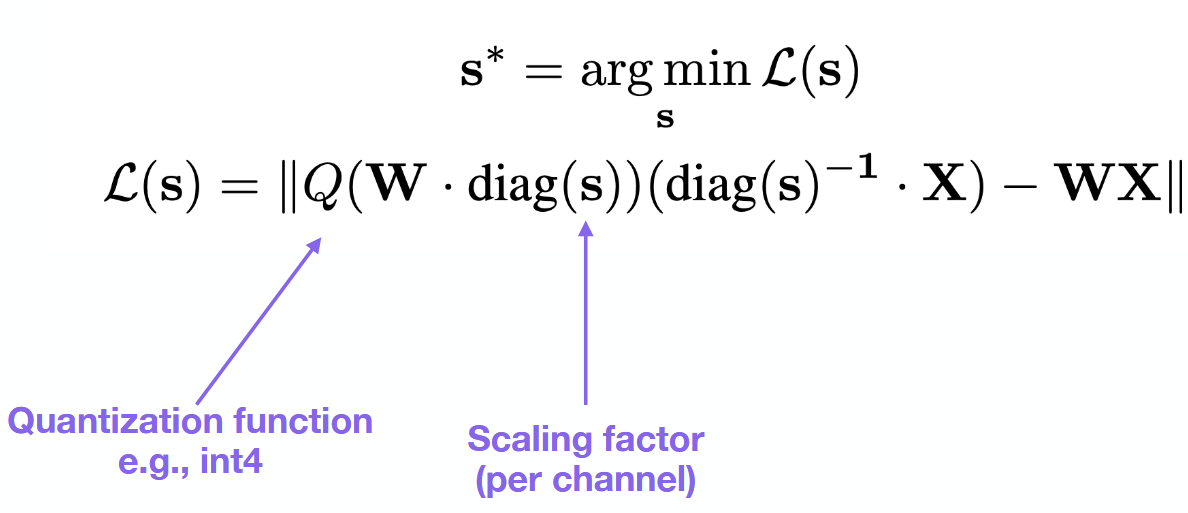
What is the idea behind AWQ?
Leave important weights in bf16 - only quantize others.
Scale weights and activations before quantiziation.
Learn quantization parameters by solving optimization problem over data.
Needs calibration dataset.
Weight-only.
What are 6 key considerations in quantization?
Do we need a calibration dataset?
Is the quantization static / dynamic?
Quantize only weights? Or activations too?
Learn quantization parameters from data or make heuristic choices?
Does my strategy have hardware support?
Space saving ≠ speed up.
What is Magnitude Pruning?
Prune (set to 0) weights that are lower than a treshold
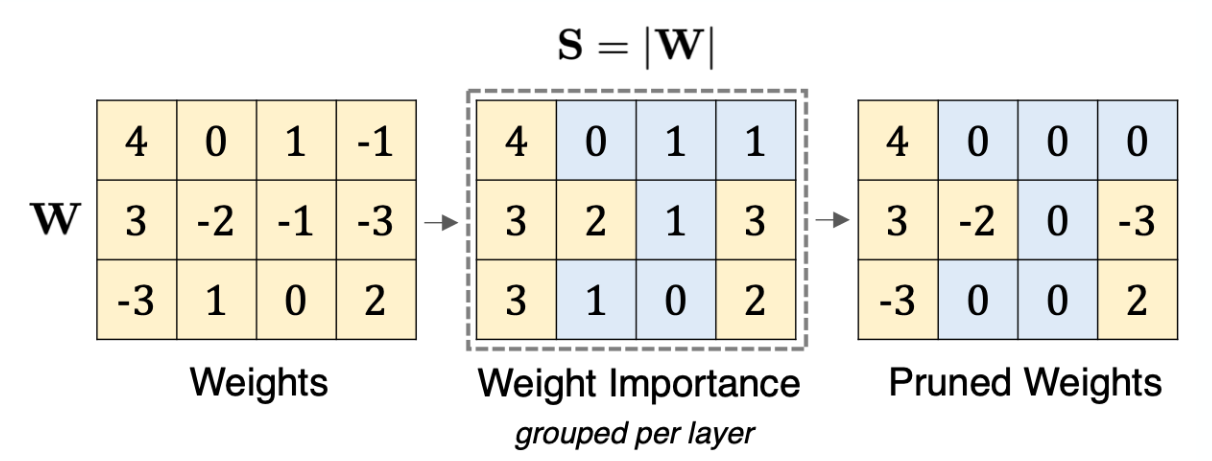
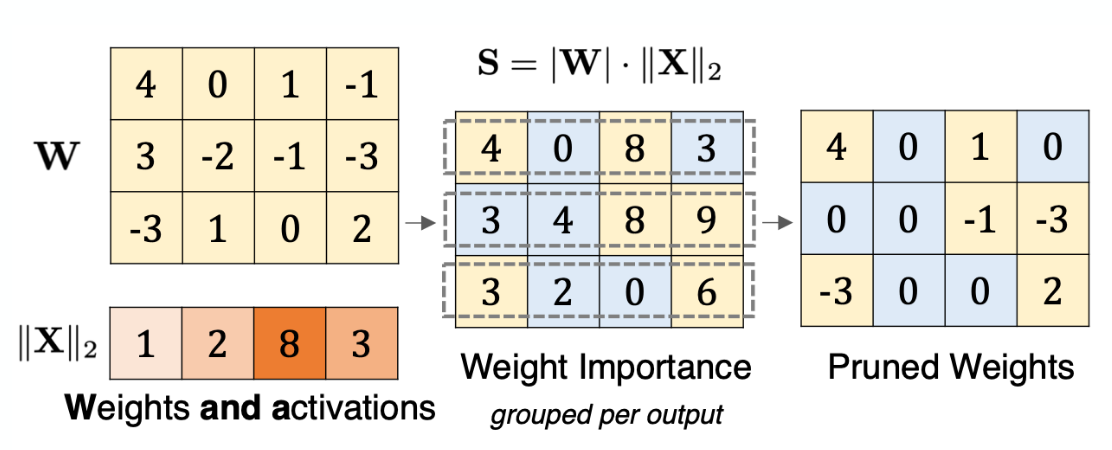
What is WandA (weights and activation pruning)?
Prune weights that have a low importance based on | W | ⋅ | | X | |2 metric.
=> Compare weights within row. F.e. drop lowest 2.
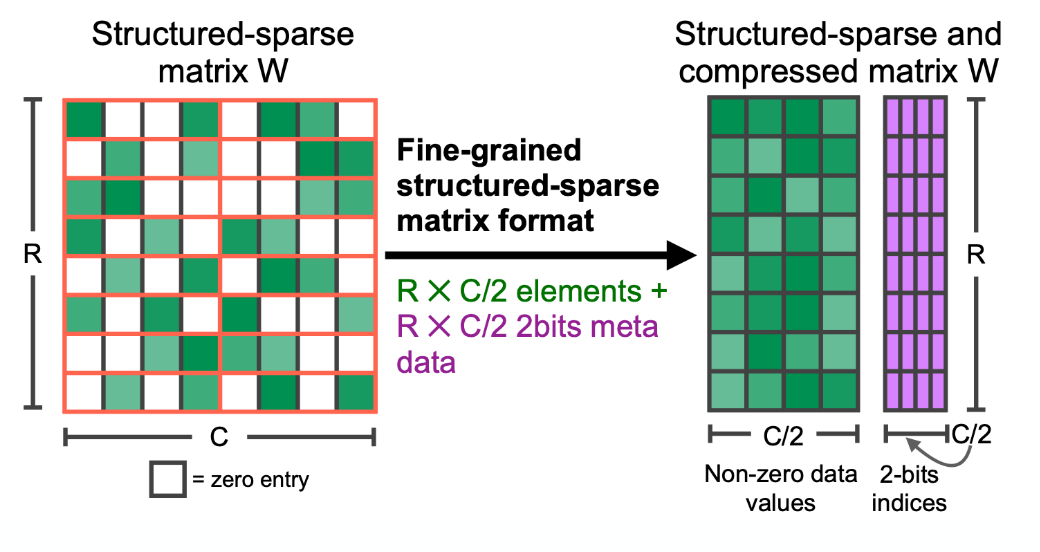
What is structured pruning?
Prune fixed ratio of weights (f.e. 2:4) between each structure.
can leverage hardware acceleration.
=> Metadata (purple) needs to be stored about what indices were non-zero.
How is a 32-bit float structured?
1 bit for sign (+,-)
8-bit biased exponent => [10-38, 1038].
24-bit fraction => 7 digit precision.
=> 32 bits is too large for modern LLMs
![<ul><li><p>1 bit for sign (+,-)</p></li><li><p>8-bit biased exponent => [10<sup>-38</sup>, 10<sup>38</sup>].</p></li><li><p>24-bit fraction => 7 digit precision.</p></li></ul><p></p><p>=> 32 bits is too large for modern LLMs</p>](https://knowt-user-attachments.s3.amazonaws.com/d9883bb7-29f3-416a-99e2-1bbe31b1230f.png)
How is a 16-bit float structured?
1 bit for sign (+,-)
5-bit biased exponent => [10-4, 104].
10-bit fraction => 3 digit precision.
=> Range is too small for LLMs
![<ul><li><p>1 bit for sign (+,-)</p></li><li><p>5-bit biased exponent => [10<sup>-4</sup>, 10<sup>4</sup>].</p></li><li><p>10-bit fraction => 3 digit precision. </p></li></ul><p></p><p>=> Range is too small for LLMs</p>](https://knowt-user-attachments.s3.amazonaws.com/bc08519a-adab-45ca-be24-93036baca7de.png)
How is a bfloat16 structured?
Idea: Less bits for precision, more for range
1 bit for sign (+,-)
8-bit biased exponent => [10-38, 1038].
7-bit fraction => 2 digit precision.
![<p>Idea: Less bits for precision, more for range</p><ul><li><p>1 bit for sign (+,-)</p></li><li><p>8-bit biased exponent => [10<sup>-38</sup>, 10<sup>38</sup>].</p></li><li><p>7-bit fraction => 2 digit precision.</p></li></ul><p></p>](https://knowt-user-attachments.s3.amazonaws.com/39a88922-76c4-45e5-a320-b42df8ca96e8.png)
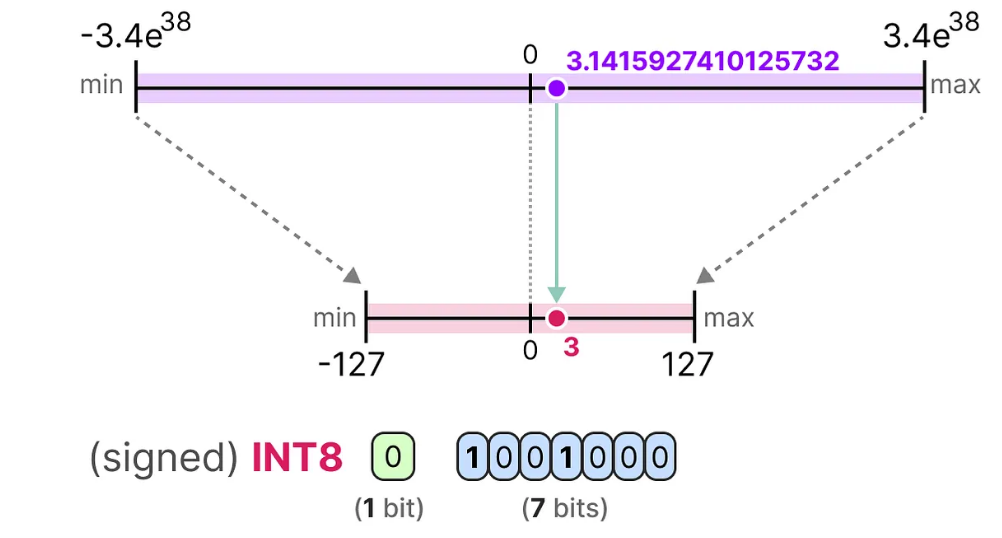
What is the idea behind Quantizing weights?
Map float values to int8 (254 distinct) values.
Uses half as much space as bfloat16.
int8 operations can be computed much faster (hardware acceleration).
→ Results in some errors, but no big difference in performance.
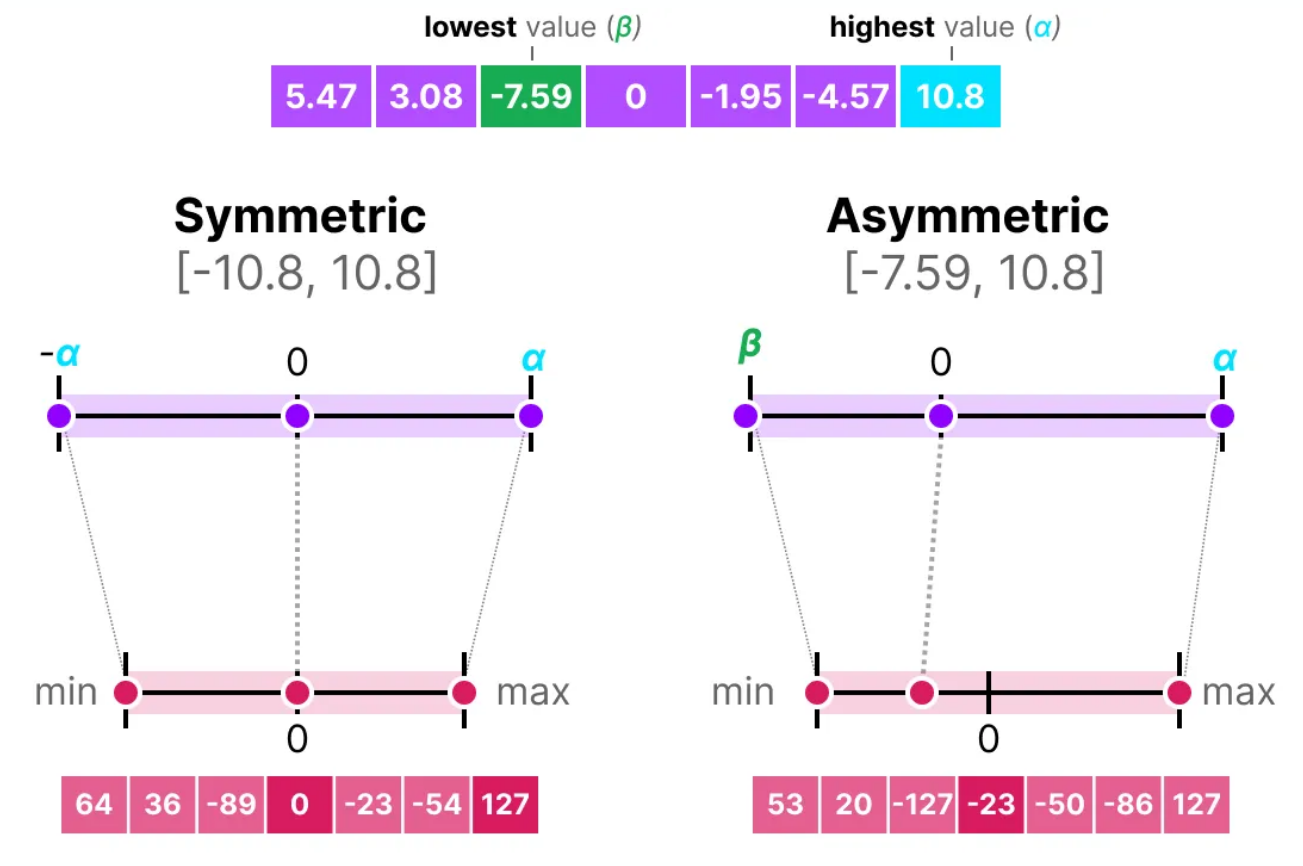
Symmetric Quantization vs. Asymmetric Quantization
Symmetric Quantization:
0 points of base and quantized match.
Min / Max are negatives of each other.
Asymmetric Quantization:
0 points do not match.
More precision than symmetric.
=> Both have problems with outliers. Can be solved by clipping weights to a pre-determined range.
What is the idea behind Mixture of Experts (MoE)?
Parameters of the model are split into disjoint blocks → “experts”.
Each Token (input) is passed through a single (or few) blocks.
Router decodes which block should process the token.
Happens for the Feed-Forward part of the Transformer model.
=> No memory saving (all experts need to be on GPU), but better parallelization = faster inference.
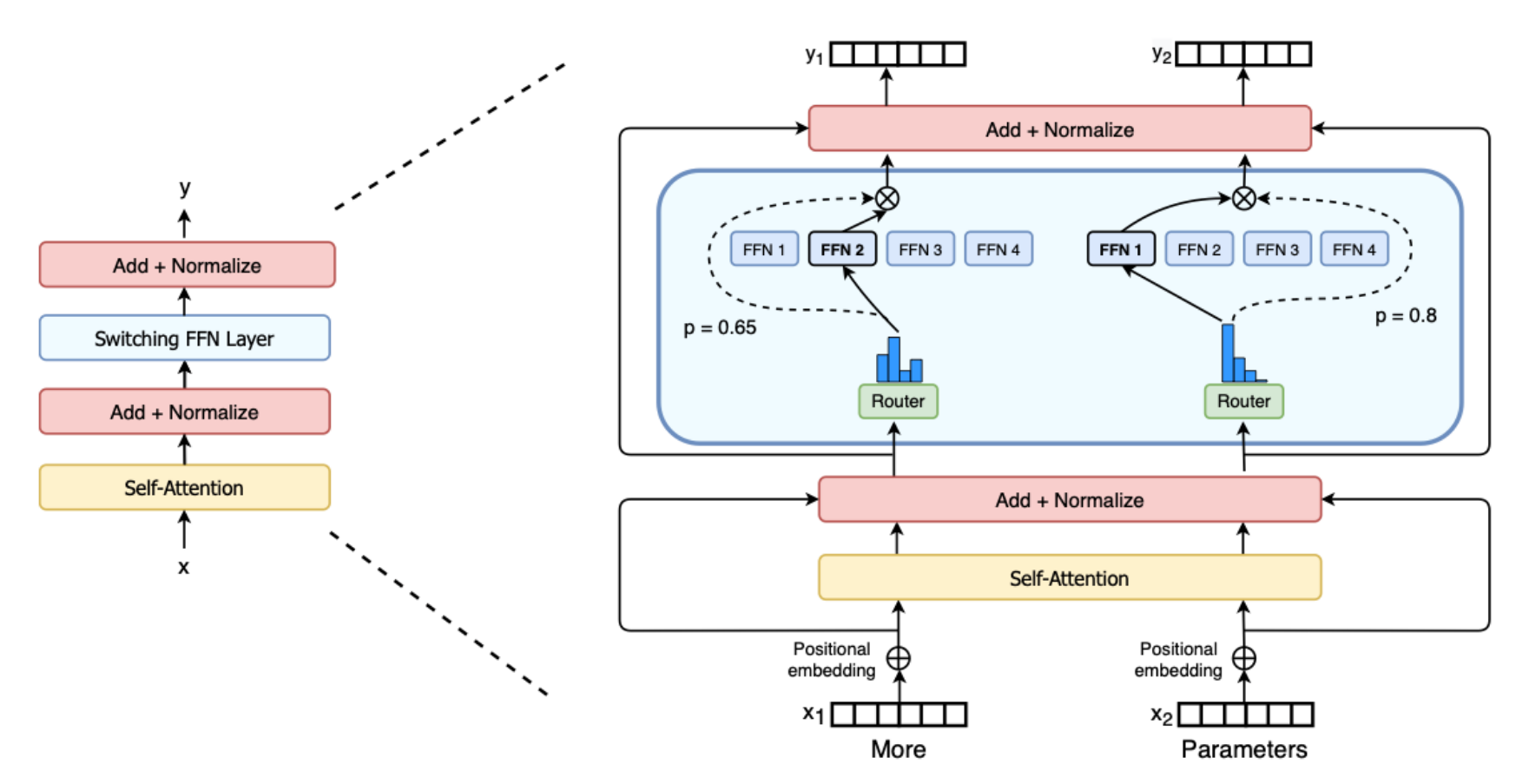
How does Routing work in Mixture of Experts (MoE)?
Router is fully connected NN model.
Outputs logits for all experts.
Approach: Pick K highest ranking experts.
Mixtral: Weigh output by softmax probability.

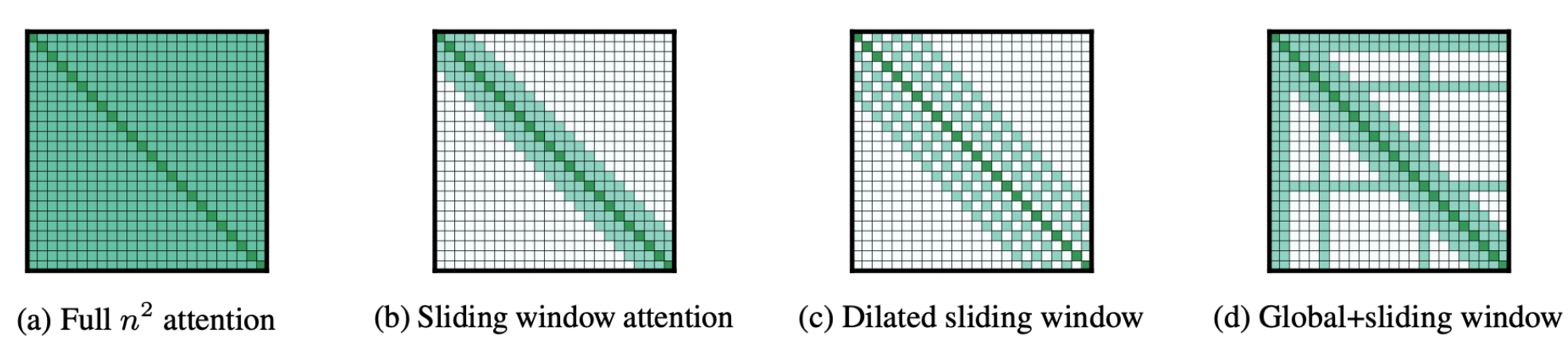
What is the idea behind Sparse Attention? (Longformer)
Reduce the O(N2) attention cost.
Only compute attention for specific tokens.
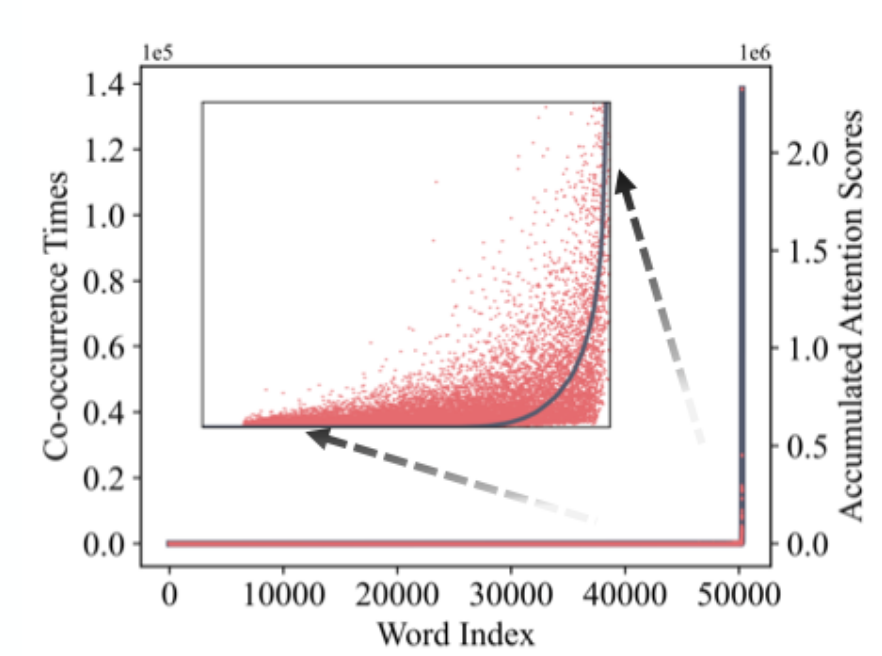
What is the H2O eviction strategy for KV-Caching?
Only a few tokens are responsible for most of the attention score → Can drop / zero-out most previous tokens from cache.
Important tokens can be found through an Attention Sparsity Score over the LLMs vocabulary.
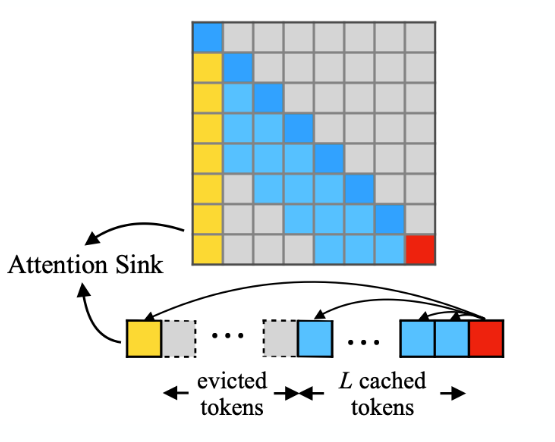
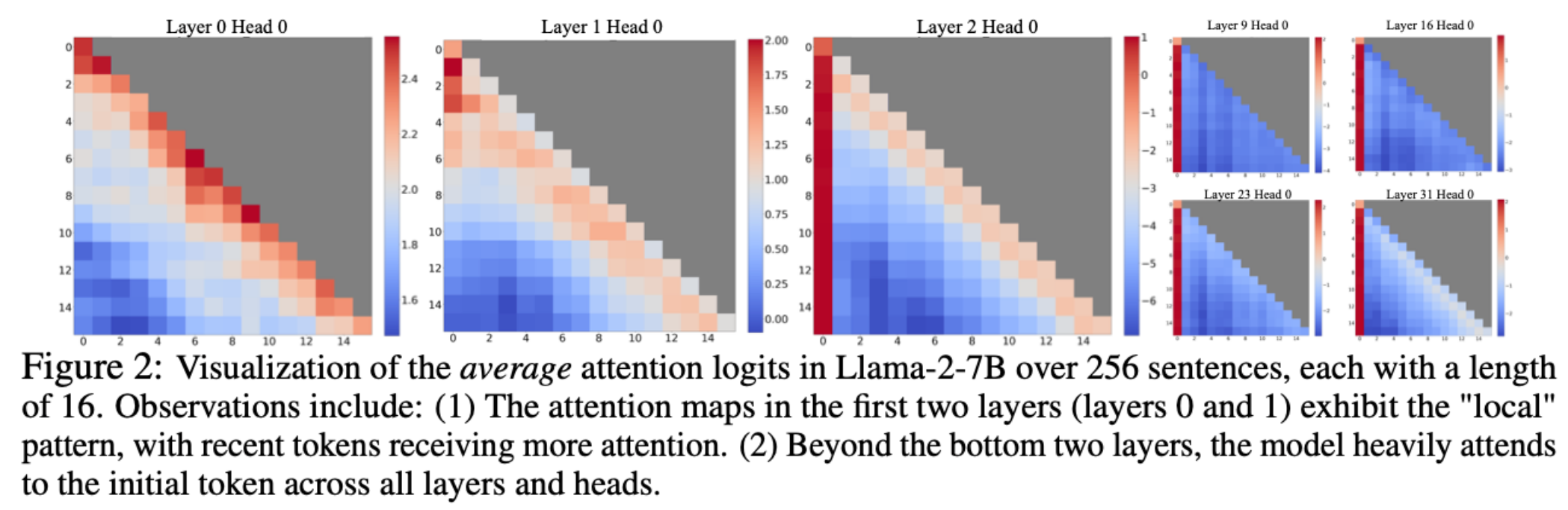
What are Attention Sinks?
Tokens in the beginning take up large attention scores, even if they are semantically unimportant.
Happens because of the softmax computation of attention needs to sum to 1 → initial token is visible from every other token.
=> Takeaway: Don’t evict initial tokens.
What is FlashAttention?
Hardware-aware optimization technique.
Use Fused Kernels to perform all attention operations at once → no back and forth between SRAM and HBM.
Matrix Tiling → load only parts of Q, K and V into SRAM.
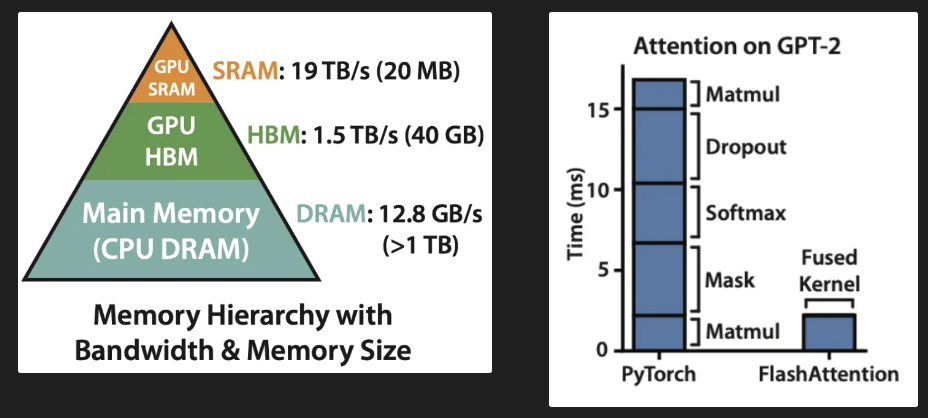
What are the 3 techniques to increase LLM inference performance with Sparcity?
Weight sparcity.
Block-level sparcity (Mixture of Experts).
KV-Cache sparcity.
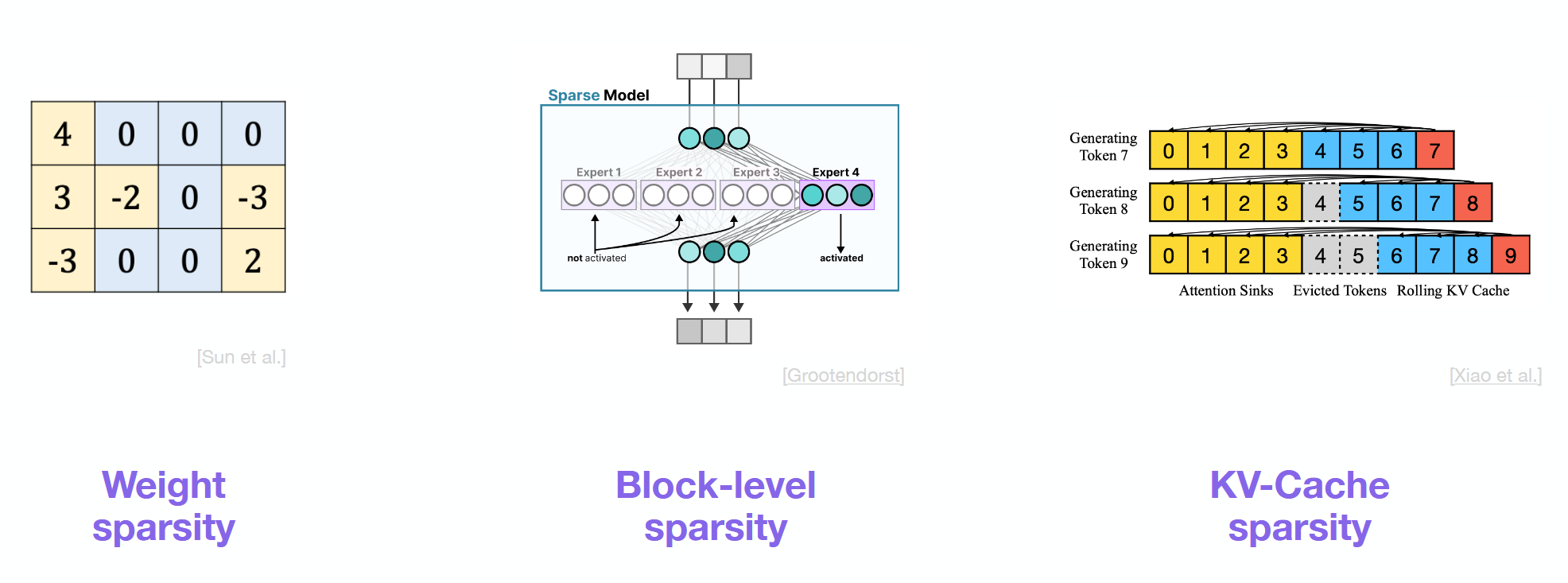
What is Paged Attention?
Split KV-Cache of each sequence into blocks.
Store the physical block in a non-contiguous, on-demand manner. Mapping between logial and physical cache blocks via Paging (block table), like in OSs.
Advantages:
Memory waste can only happen in last block of a sequence.
Efficient memory sharing, f.e. in parallel sampling.
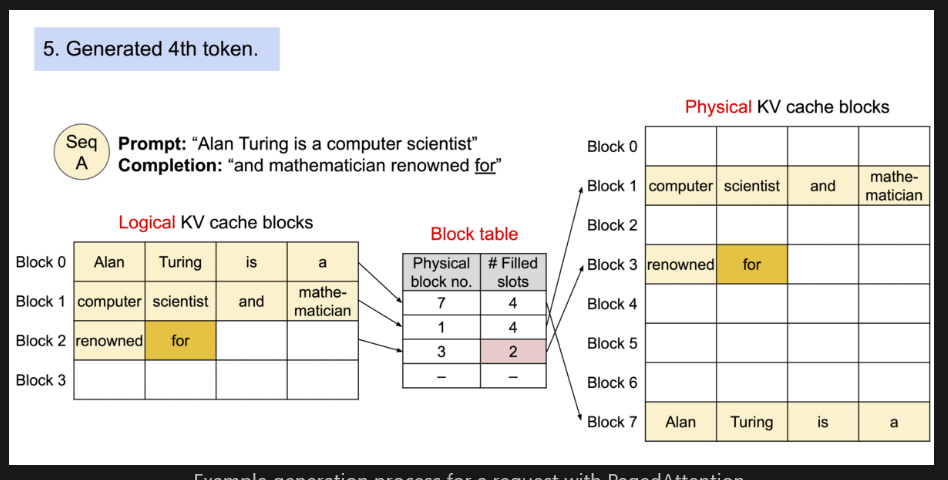
How to evict blocks in Paged Attention?
Evict block with 0 reference count (→ no running requests with this block).
If multiple blocks have 0 reference, evict leasr-recently used (LRU) block.
If LRU ties, evict block at the end of longest prefix.
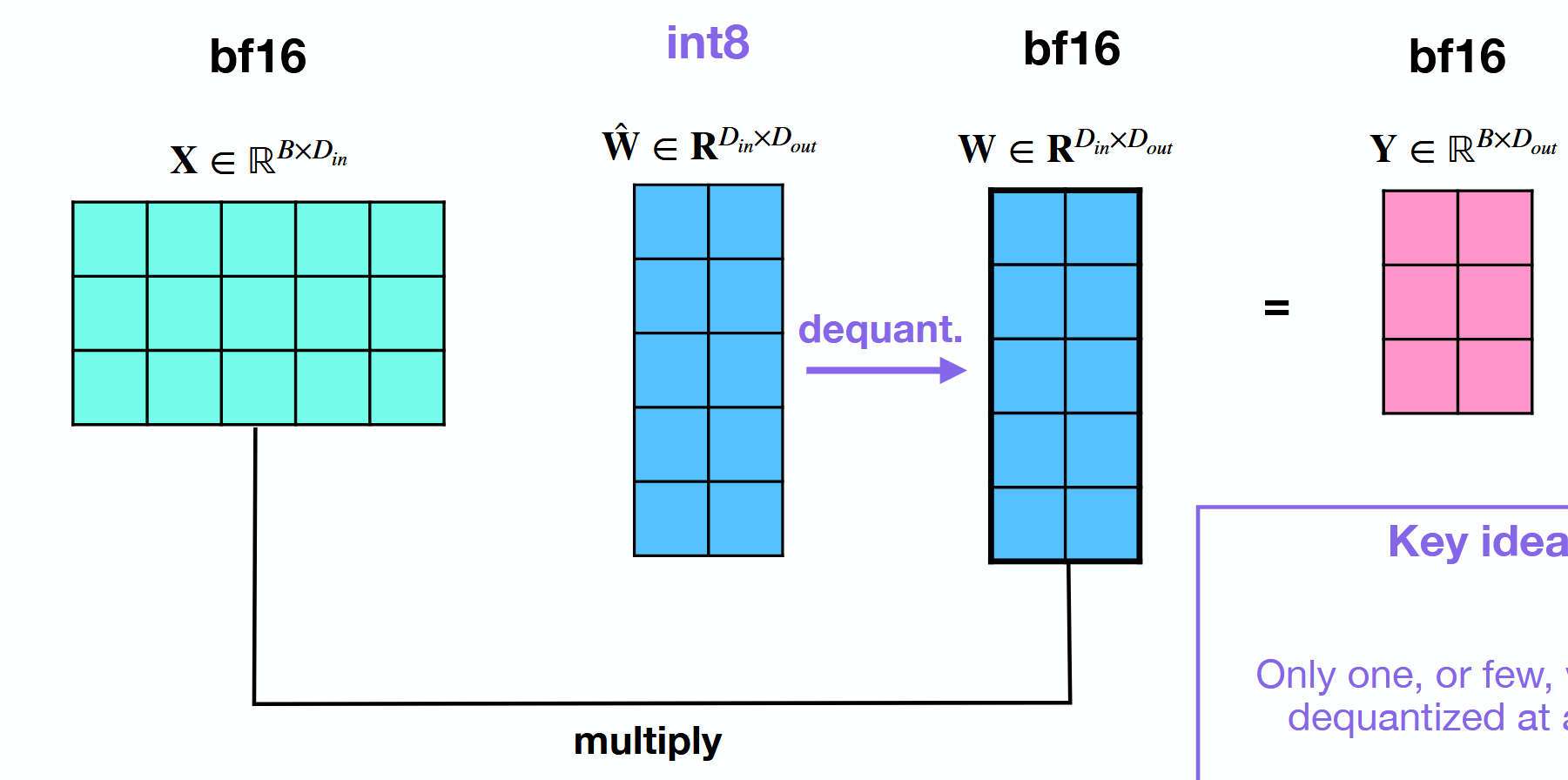
How does weight-only Quantization work?
Dequantize weight if needed.
Result of multiplication will be unquantized (f.e. bf16).
What are disadvantages of LLM.int8()?
Needs a calibration data set.
Need to set outlier threshold manually.
Paper shows that runtime is slower than base model.
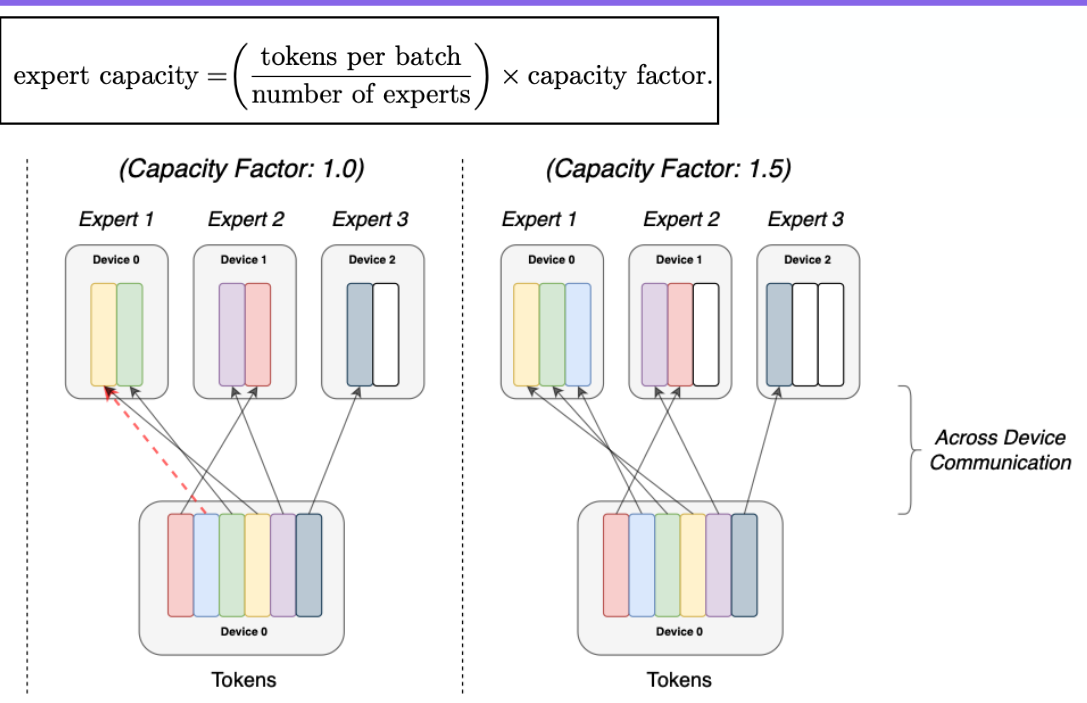
What is the idea of Load Balancing in Mixture of Experts?
Adjustment of the capacity of experts to ensure evenly split expert utilization.
Too low capacity → Tokens will get dropped.
Too high capacity → Wasted compute.
What is the idea of Streaming LLM?
Learn from knowledge about Attention Sinks.
Keep initial tokens and most recent tokens in KV cache.
=> Rest can be dropped.