AB MEGAKVÍZ - Záróvizsga 2025
1/59
Earn XP
Description and Tags
Téma követelmények: https://www.cs.ubbcluj.ro/wp-content/uploads/TematicaInformatica_2025_Hu.pdf
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
60 Terms
Mi az ABKR (DBMS)?
Az ABKR az AdatBázis Kezelő Rendszer rövidítése, angolul Database Management System (DBMS). Ez a rendszer implementálja az adatok tárolását, kezelését és lekérdezését.
Mit nevezünk relációnak?
A reláció az attribútumok nem feltétlenül kizáró halmazain értelmezett Descartes-féle szorzat részhalmaza. A relációk az adatbázisokban táblázatokként jelennek meg.
A1,A2,…,An - attribútumok halmaza
R - reláció az attribútumok között
R ⊆ A1 × A2 × … × An
Mit nevezünk relációsémának?
A reláció nevét és a reláció attribútumainak a halmazát együtt relációsémának nevezzük.
Mik a relációs adatmodell tulajdonságai?
A tábla nem tartalmazhat két teljesen azonos sort.
Kulcsok:
A relációnak nem lehet két sora, melynek értékei megegyeznek a kulcsot alkotó attribútumok esetén.
A kulcsot alkotó attribútumok egyetlen valódi részhalmaza sem rendelkezik az előző tulajdonsággal.
A táblázat sorainak vagyis az egyedelőfordulásoknak a sorrendje lényegtelen.
Két attribútumnak nem lehet ugyanaz a neve.
A táblázat oszlopainak a sorrendje lényegtelen.
Milyen attribútumok lehetnek kulcsjelöltek?
Egy reláció esetén azok az attribútumok lehetnek kulcsjelöltek, amelyek értéke egyedi minden egyes előfordulásra nézve.
Mi lehet elsődleges kulcs?
Elsődleges kulcsot a kulcsjelöltek közül kell választani, ez lehet összetett is.
Mindig kell legyen elsődleges kulcs, ha más nem, a teljes sor mindig egyedi.
Elsődleges kulcs értéke soha nem lehet null vagy üres.
Miért van szükség összetett kulcsra?
Ha nincs olyan tulajdonság, amelynek értéke egyedi lenne az egyed-előfordulásokra nézve, akkor több tulajdonság értéke együtt fogja jelenteni az elsődleges (összetett) kulcsot.
Milyen típusú megszorítások léteznek?
Egyedi kulcs feltétel
Egy relációban nem lehet két sor, melyeknek ugyanaz a kulcsértéke.
Hivatkozási épség megszorítás
Külső kulcs esetén a hivatkozott értéknek léteznie kell a hivatkozott táblában.
Értelmezéstartomány-megszorítás
Egy attribútum az értékeit a megadott értékhalmazból vagy értéktartományból veheti fel.
Általános megszorítás
Tetszőleges követelmények, amelyeket be kell tartani az
adatbázisban.
Jelölések
R(A1, A2,…, An) - reláció
A = {A1, A2,…, An} - attribútumok halmaza
X, Y ⊂ A
X → Y - az Y funkcionálisan függ X-től
Mit nevezünk funkcionális függőségek?
X attribútumhalmaz funkcionálisan meghatározza Y attribútumhalmazt (vagy Y funkcionálisan függ X-től), ha R minden előfordulásában ugyanazt az értéket veszi fel Y, amikor az X értéke ugyanaz.
pl. SzállID → {SzállNév, SzállCím}
Egy kulcs funkcionálisan meghatározza a reláció minden más attribútumát.
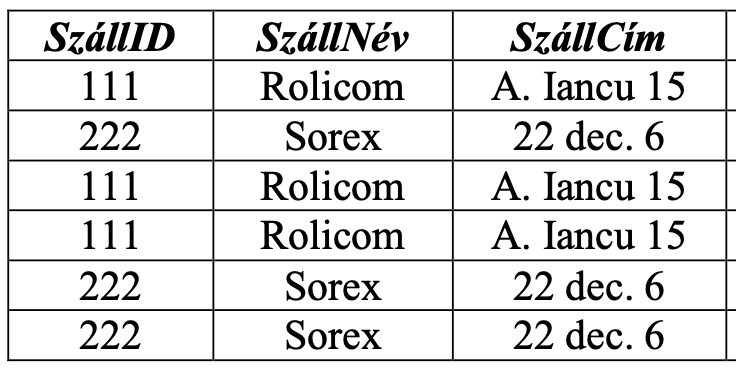
Mit nevezünk szuperkulcsnak?
Szuperkulcsoknak nevezzük azon attribútumhalmazokat, melyek tartalmaznak kulcsot.
A szuperkulcsok eleget tesznek a kulcs definíció első feltételének, de nem feltétlenül tesznek eleget a minimalitásnak.
Tehát minden kulcs szuperkulcs.
Mit nevezünk prím attribútumnak?
Ai attribútum prím, ha létezik egy C kulcsa az R-nek, úgy hogy Ai ∈ C. Ha egy attribútum nem része egy kulcsnak, akkor nem prím attribútumnak nevezzük.
Mit nevezünk triviális funkcionális függőségnek?
Triviális funkcionális függőségről beszélünk, ha az Y attribútum halmaz részhalmaza az X attribútum halmaznak (Y ⊂ X) , akkor Y attribútum halmaz funkcionálisan függ X attribútum halmaztól (X → Y).
pl. {SzállID, ÁruID} → SzállID
Mit nevezünk nem triviális funkcionális függőségnek?
Nem triviális egy funkcionális függőség, ha az Y-ok közül legalább egy különbözik az X-ektől, X → Y függőség esetén.
Mit nevezünk teljesen nem triviális funkcionális függőségnek?
Teljesen nem triviális egy funkcionális függőség, ha az Y-ok közül egy sem egyezik meg az X-ek valamelyikével, X → Y függőség esetén.
Mit nevezünk parciális függőségnek?
X → Y parciális függőség, ha C egy kulcsa az R relációnak, az Y attribútumhalmaz valódi részhalmaza a C-nek (Y ⊂ C) és A egy attribútum, mely nem része az Y-nak (A ∉ Y).
Más szóval, az A függ a kulcs egy részétől.
Mit nevezünk tranzitív függőségnek?
Y → B tranzitív függőség, ha Y ⊂ A egy attribútumhalmaz és B egy attribútum, mely nem része Y-nak és ha Y nem szuperkulcs R relációban és nem is valódi részhalmaza R egy kulcsának.
Tehát C → Y és Y → B, és erre mondhatjuk, hogy B tranzitív függőséggel függ C-től.
pl.
Rendelések (RendelésSzám, Dátum, VevőID, VevőNév, Részletek)
RendelésSzám → VevőID
VevőID → VevőNév
Tehát RendelésSzám → VevőNév tranzitív függőség.
Mik az anomáliák?
Azokat a problémákat, amelyek akkor jelennek meg, amikor túl sok információt probálunk egyetlen relációba belegyömöszölni, anomáliának nevezzük.
Típusai:
Redundancia
Az információk feleslegesen ismétlődnek több sorban.
Módosítási problémák
Megváltoztatjuk az egyik sorban tárolt információt, miközben ugyanaz az információ változatlan marad egy másik sorban.
Törlési problémák
Ha az értékek halmaza üres halmazzá válik, akkor ennek mellékhatásaként más információt is elveszthetünk.
Illesztési problémák
Például, ha hozzáilleszteni akarunk egy szállítót, amely nem szállít egy árut sem, a szállító címét kitöltjük úgy, hogy az áruhoz „null” értékeket viszünk be, melyet majd utólag ki kell törölni, ha el nem felejtjük.
Miket nevezünk normálformáknak?
Az optimális adatmodell kialakítására egyéb technikák mellett a normalizálás szolgál. A normalizálás az a folyamat, amellyel kialakítjuk a relációk normálformáját (NF).
A normálformák: 1NF < 2NF < 3NF < BCNF < 4NF < 5NF
A normálalakok nem függetlenek egymástól, hanem logikusan egymásra épülnek.
Mikor van egy reláció 1NF-ben?
Egy R reláció 1NF–ben van, ha az attribútumoknak csak elemi (nem összetett vagy ismétlődő) értékei vannak.
pl. A reláció nincs 1NF-ben mert a Cím összetett attribútum, a Helység, Utca és Szám attribútumokból áll. A Gyerek1, SzülDát1,…, Gyerek5, SzülDát5 ismétlődő attribútum.

Hogyan kell 1NF-re alakítani egy relációt?
Az összetett attribútum helyett beírjuk az azt alkotó elemi attribútumokat.
Az ismétlődő attribútumok esetén két relációra bontjuk fel az eredetit. Az egyik relációban a kulcs attribútum mellett az ismétlődő attribútumok fognak szerepelni (csak egyszer), a másikban pedig a kulcs mellett azon attribútumok, melyek nem ismétlődőek.
pl. Átalakítás után:
Alkalmazottak(SzemSzám, Név, Helység, Utca, Szám)
AlkalmazottakGyerekei(SzemSzám, GyerekNév, SzülDátum)

Mikor van egy reláció 2NF-ben?
Egy reláció 2NF formában van, ha már 1NF és nem tartalmaz Y → B alakú parciális függőséget, ahol B nem prím attribútum.
Csak akkor tevődik fel, hogy egy reláció nincs 2NF-ben, ha a kulcs összetett.
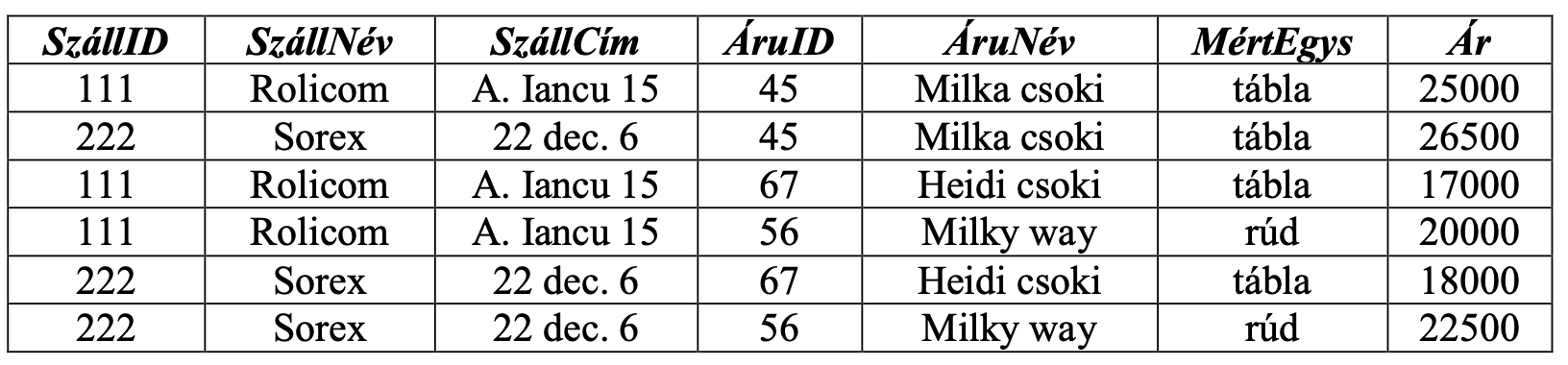
pl. A SzállításiInformációk relációja nincs 2NF-ben, mivel a reláció kulcsa a {SzállID, ÁruID} és fennáll a SzállID → SzállNév, tehát SzállNév függ a kulcs egy részétől is, tehát létezik parciális függőség.
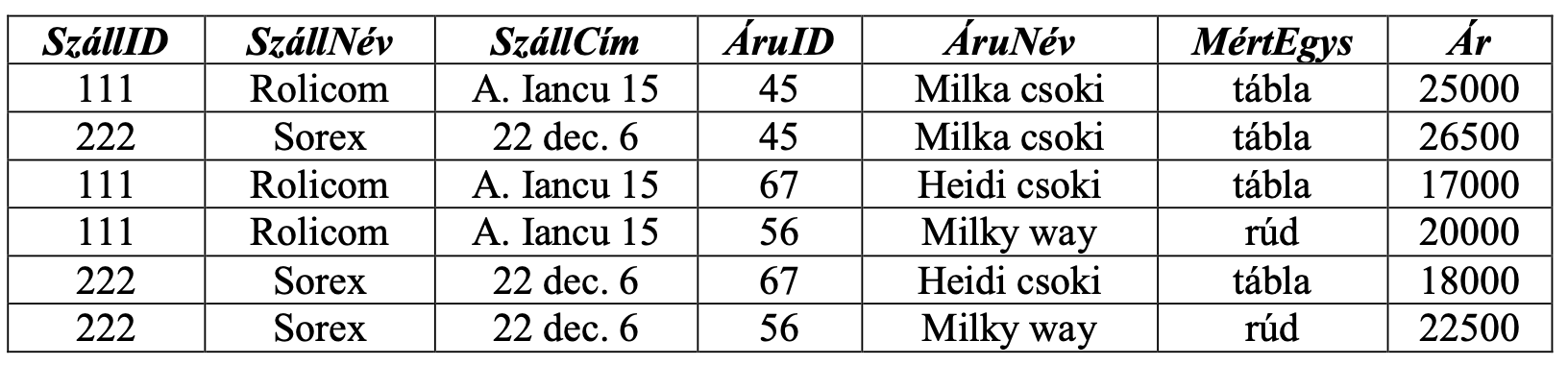
Hogyan kell 2NF-re alakítani egy relációt?
Az R relációt felbontjuk két relációra, melyek sémái:
S(A - B)
A - Az összes attribútum
B - Az attribútumhalmaz amely függ a kulcs egy részétől.
T(D, B)
D - A kulcsnak az a része amelytől függ B.
pl. Első lépésben B = {SzállNév, SzállCím}, D = {SzállID}. Felbontás után:
Szállítók (SzállID, SzállNév, SzállCím)
SzállInf (SzállID, ÁruID, ÁruNév, MértEgys, Ár)
A Szállítók reláció 2NF-ben van, mivel a kulcs nem összetett. A SzállInf nincs 2NF-ben, mert fennáll a ÁruID → {ÁruNév, MértEgys}. Ebben az esetben B = {ÁruNév, MértEgys}, D = {ÁruID}. További felbontás után:
Áruk (ÁruID, ÁruNév, MértEgys)
Szállít (SzállID, ÁruID, Ár)
Mikor van egy reláció 3NF-ben?
Egy reláció 3NF formában van, ha már 2NF és nem tartalmaz Y → B alakú tranzitív funkcionális függőséget, ahol B nem prím attribútum.
pl. Rendelések (RendelésSzám, Dátum, VevőID, VevőNév, Részletek)
A Rendelések reláció nincs 3NF-ben, mivel tartalmaz tranzitív funkcionális függőséget:
RendelésSzám → VevőID
VevőID → VevőNév
Hogyan kell 3NF-re alakítani egy relációt?
Az R relációt felbontjuk két relációra, melyek sémái:
S(A - B)
A - Az összes attribútum
B - Az attribútumhalmaz amely tranzitívan függ a kulcstól (D → B).
T(D, B)
D - Azok az attribútumok amelyek nem kulcsok, függnek a kulcstól és a B-ben lévők tőlük függnek: C → D, D → B. (C - kulcs)
pl. Rendelések (RendelésSzám, Dátum, VevőID, VevőNév, Részletek)
A Rendelések reláció esetén: B = {VevőNév}, D = {VevőID}, a felbontás után:
Vevők (VevőID, VevőNév)
RendelésInf (RendelésSzám, Dátum, VevőID)
Melyik az öt alapvető relációs algebrai művelet?
Kiválasztás (selection)
Vetítés (projection)
Descartes szorzat
Egyesítés
Különbség
Ez az öt az alapvető művelet. Még vannak hasznos műveletek: ezek az öt alapvető művelettel kifejezhetőek.
Mi a Kiválasztás (Selection) relációs algebrai művelet?
Az R relációra alkalmazott kiválasztás operátor f feltétellel olyan új relációt hoz létre, melynek sorai teljesítik az f feltételt. Az eredmény reláció attribútumainak a száma megegyezik az R reláció attribútumainak a számával.
Jelölés: σf (R) (sigma)
pl. σFizetés <= 500 (Alkalmazottak)
Megfelel annak, hogy:
SELECT *
FROM R
WHERE f_azaz_feltetelekMi a Vetítés (Projection) relációs algebrai művelet?
A vetítés művelet eredményeként olyan relációt kapunk, mely R-nek csak bizonyos attribútumait tartalmazza. Ha kiválasztunk k attribútumot az n-ből: A1,A2,…,Ak-et, és ha esetleg a sorrendet is megváltoztatjuk, az eredmény reláció a kiválasztott k attribútumhoz tartozó oszlopokat fogja tartalmazni, viszont az összes sorból. Mivel az eredmény is egy reláció, nem lehet két azonos sor a vetítés eredményében, az azonos sorokból csak egy marad az eredmény relációban.
Jelölés: πA1, A2,…,Ak (R) (pi)
pl. πNév, Fizetés (Alkalmazottak)
Megfelel annak, hogy:
SELECT DISTINCT attr1, attr2, … attrk
FROM RMi a Descartes szorzat relációs algebrai művelet?
Ha adottak az R1 és R2 relációk, a két reláció Descartes szorzata azon párok halmaza, amelyeknek első eleme az R1 tetszőleges eleme, a második pedig az R2 egy eleme. Az eredményreláció sémája az R1 és R2 sémájának egyesítése.
Jelölés: R1 × R2
pl. lásd kép
Megfelel annak, hogy:
SELECT *
FROM R1, R2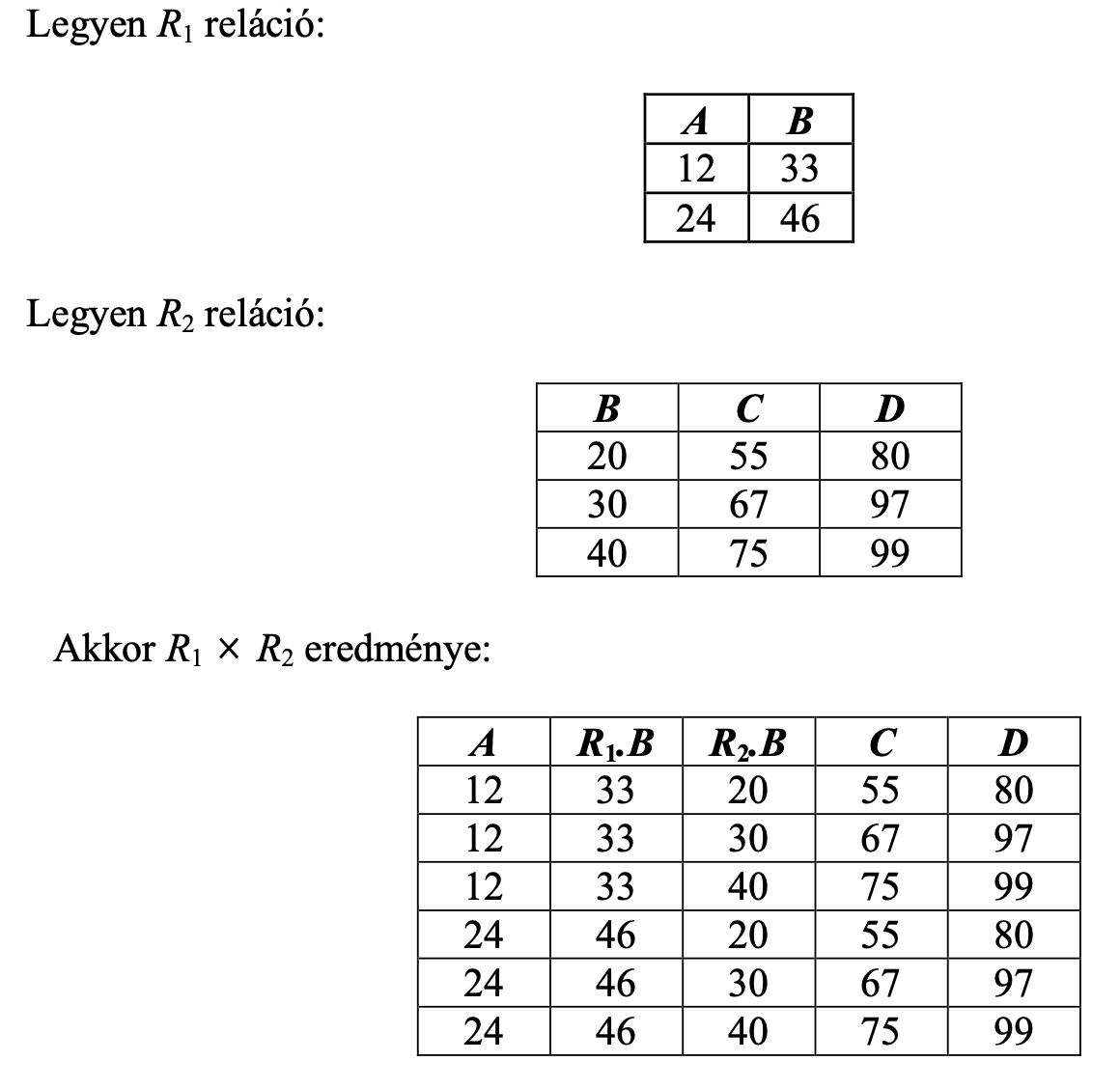
Mi az Egyesítés relációs algebrai művelet?
Ha adottak az R1 és R2 relációk, R1 és R2 attribútumainak a száma megegyezik, és ugyanabban a pozícióban levő attribútumnak ugyanaz az értékhalmaza, a két reláció egyesítése tartalmazni fogja R1 és R2 sorait. Az egyesítésben egy elem csak egyszer szerepel, még akkor is, ha jelen van R1- és R2-ben is.
Jelölés: R1 ∪ R2
pl. lásd kép
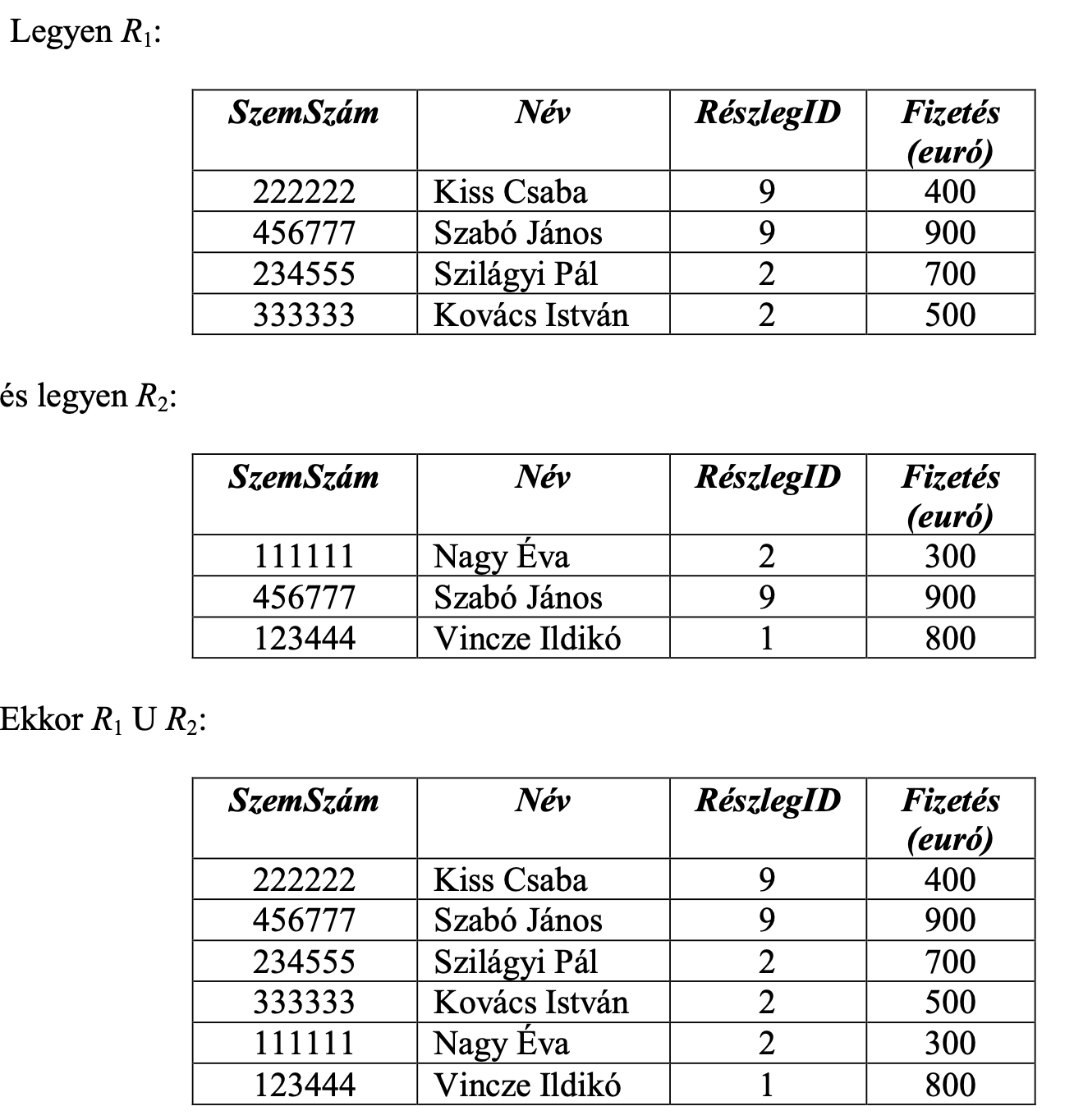
Mi a Különbség relációs algebrai művelet?
Ha adottak az R1 és R2 relációk, R1 és R2 attribútumainak a száma megegyezik és ugyanabban a pozícióban levő attribútumnak ugyanaz az értékhalmaza, a két reláció különbsége azon sorok halmaza, amelyek R1-ben szerepelnek és R2-ben nem.
Jelölés: R1 - R2
pl. lásd kép
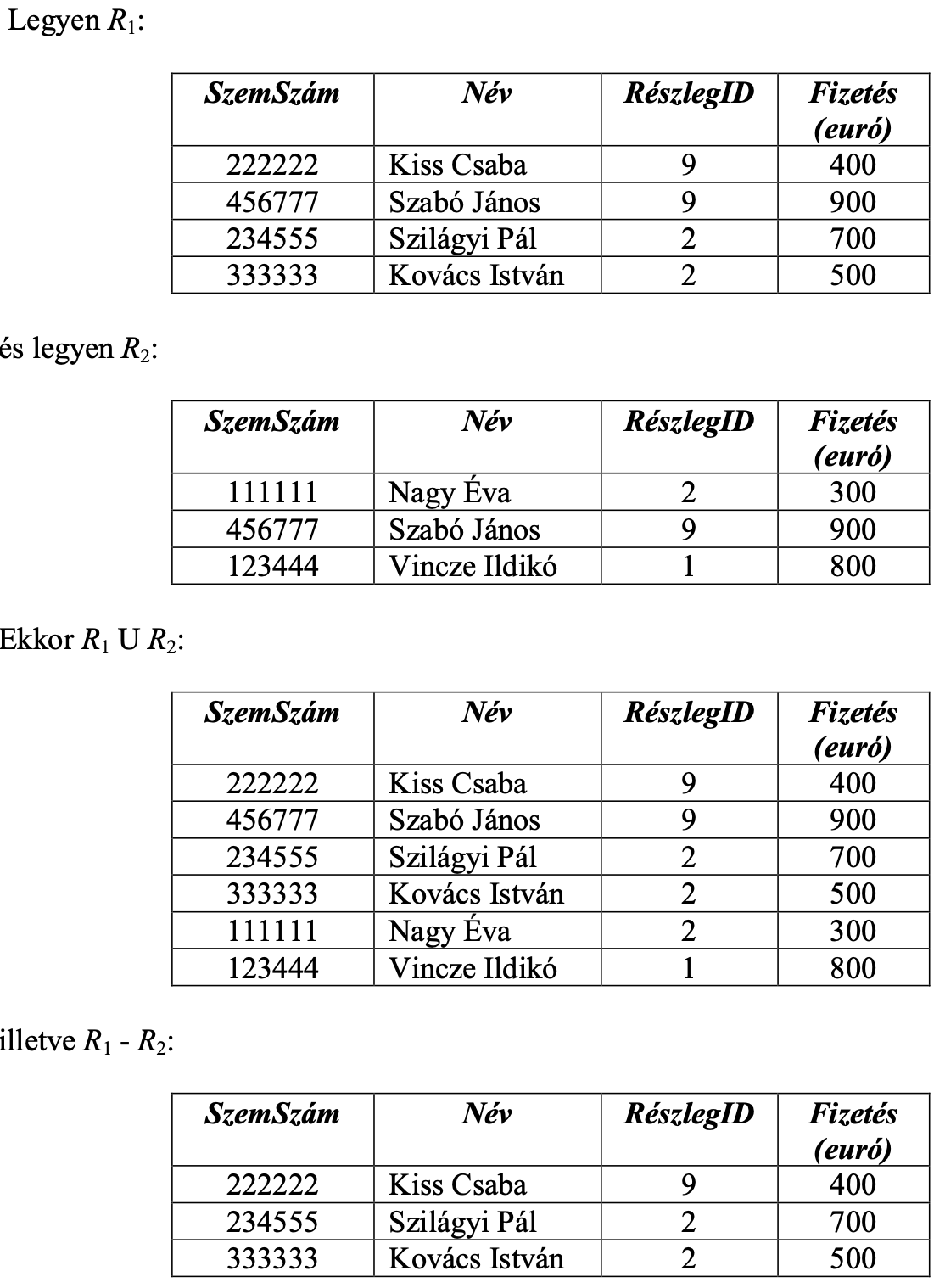
Mi a Metszet relációs algebrai művelet?
Legyenek az R1 és R2 relációk, a két reláció metszete:
R1 ∩ R2 = R1 - (R1 - R2)
Jelölés: R1 ∩ R2
pl. Hasonló a különbséghez de a közös elemek tűnnek el
Mi a Théta-összekapcsolás (theta-join) relációs algebrai művelet?
Legyenek az R1 és R2 relációk. A Théta-összekapcsolás során az R1 és R2 relációk Descartes szorzatából kiválasztjuk azon sorokat, melyek eleget tesznek a θ feltételnek, vagyis: R1 ⋈θ R2 = σθ(R1 × R2) (a theta alulírott kéne legyen, de azt nem lehet)
Jelölés: R1 ⋈θ R2 (theta)
Pl. lásd kép
Megfelel annak, hogy:
SELECT *
FROM R1, R2
WHERE theta_feltetelek
Mi a Természetes összekapcsolás (natural join) relációs algebrai művelet?
Legyenek az R1 és R2 relációk. A természetes összekapcsolás művelete akkor alkalmazható, ha az R1 és R2 relációknak egy vagy több közös attribútuma van. Legyen B az R1, illetve C az R2 reláció attribútumainak a halmaza, a közös attribútumok pedig: B ∩ C = {A1, A2, …, Ap}. A természetes összekapcsolást a következő képlettel fejezhetjük ki:
R1 ⋈ R2 = πB∪C(R1 ⋈(R1.A1 = R2.A1)^…(R1.Ap = R2.Ap) R2)
Jelölés: R1 ⋈ R2
pl. Az összes sima join
Megfelel annak, hogy:
SELECT *
FROM R1
JOIN R2 ON R1.A1 = R2.A1 AND … R1.Ap = R2.Apvagy
SELECT *
FROM R1, R2
WHERE R1.A1 = R2.A1 AND … R1.Ap = R2.ApMi a Átnevezés (rename) relációs algebrai művelet?
Legyen R(A1, A2, …, An) egy reláció, az átnevezés operátor: ρS(B1, B2, …, Bn) (R) az R relációt S relációvá nevezi át, az attribútumokat pedig balról jobbra B1, B2, …, Bn-né. Ha az attribútum neveket nem akarjuk megváltoztatni, akkor ρS (R) operátort használunk.
Jelölés: ρS(…) (R) (rho)
Pl. sima átnevezés amit a select-be írunk
Megfelel annak (ha mindent átnevezünk), hogy:
SELECT A1 AS B1, …, An AS Bn
FROM R AS SMi a Hányados (quotient) relációs algebrai művelet?
{…nagyon hosszú érthetetlen magyarázat… akit nagyon érdekel olvassa el…ha nem akkor a példába jól látszik}
Jelölés: R1 DIVIDE BY R2
pl. lásd kép

Melyek az SQL nyelv logikai műveletei és ezek eredményei? Mi a végrehajtási sorrend?
AND, OR és NOT
A NOT megelőzi az AND és OR műveletet, az AND pedig az OR-t.
Egy kifejezés logikai értéke lehet: igaz (1), hamis (0), ismeretlen (unknown) (0.5). Egy kifejezés logikai értéke akkor ismeretlen, ha a kifejezésben szereplő valamelyik operandus értéke NULL.

Mire való a LIKE kulcsszó? Milyen szerepet töltenek be a “%” és “_” szimbólumok?
A LIKE kulcsszót karakterláncok összehasonlítása esetén használhatjuk, hogy a karakterláncokat egy mintával hasonlítsunk össze a következőképpen:
k LIKE m
ahol k egy karakterlánc és m egy minta. A mintában használhatjuk a % és _ karaktereket. A % jelnek a k-ban megfelel bármilyen karakter 0 vagy nagyobb hosszúságú sorozata. Az _ jelnek megfelel egy akármilyen karakter a k-ból.
pl.
SELECT *
FROM Alkalmazottak
WHERE Név LIKE ‘Kovács%’;Mire való a BETWEEN kulcsszó?
A BETWEEN kulcsszó segítségével megadunk egy intervallumot, és azt vizsgáljuk, hogy adott oszlop, mely értéke esik a megadott intervallumba.
pl.
SELECT Név
FROM Alkalmazottak
WHERE Fizetés BETWEEN 300 AND 500;Mire való az IN kulcsszó?
Az IN operátor után megadunk egy értéklistát, és azt vizsgáljuk, hogy az adott oszlop mely mezőinek értéke egyezik az adott lista valamelyik elemével.
pl.
SELECT Név
FROM Diákok
WHERE CsopKod IN ('531', '532', '631');k darab reláció összekapcsolása esetén hány join feltétel szükséges?
Ha az összekapcsolandó relációk száma k, és minden két-két relációnak egy-egy közös attribútuma van, akkor a join feltételek száma k–1.
Mit nevezünk sorváltozónak? Mikor használatos? Mire kell odafigyelni ennek használatakor?
A FROM záradékban szereplő R relációhoz hozzárendelhetünk egy másodnevet, melyet sorváltozónak nevezünk.
Sorváltozót akkor használunk, ha rövidebb vagy más nevet akarunk adni a relációnak, illetve ha a FROM után kétszer is ugyanaz a reláció szerepel.
Ha használtunk másodnevet, akkor az adott lekérdezésben azt kell használjuk.
pl.
SELECT Alk1.Név AS Név1, Alk2.Név AS Név2
FROM Alkalmazottak AS Alk1, Alkalmazottak AS Alk2
WHERE Alk1.Cím = Alk2.Cím
AND Alk1.Név < Alk2.Név;Milyen halmazműveleteket támogat az SQL nyelv?
UNION - egyesítés
(SELECT Név, UtcaSzám FROM Szállítók WHERE Helység = 'Kolozsvár') UNION (SELECT Név, UtcaSzám FROM Vevők WHERE Helység = 'Kolozsvár');INTERSECT - metszet
(SELECT SzemSzám, Név FROM Alkalmazottak) EXCEPT (SELECT SzemSzám, Név FROM Managerek, Alkalmazottak WHERE Managerek.SzemSzám = Alkalmazottak.SzemSzám);EXCEPT - különbség (helyettesíthető NOT EXISTS vagy NOT IN operátorokkal)
(SELECT SzemSzám FROM Alkalmazottak) EXCEPT (SELECT SzemSzám FROM Managerek);
Mire való a DISTINCT kulcsszó?
A SELECT parancs eredményében szerepelhet két vagy több teljesen azonos sor, viszont van lehetőség ezen ismétlődések megszüntetésére.
A SELECT kulcsszó után a DISTINCT szó segítségével kérhetjük az azonos sorok megszüntetését.
Milyen esetben vonja össze a rendszer az ismétlődéseket? Hogyan lehet ezt meggátolni?
A SELECT paranccsal ellentétben, a UNION, EXCEPT és INTERSECT halmazelméleti műveletek megszüntetik az ismétlődéseket. Ha nem szeretnénk, hogy az ismétlődő sorok eltűnjenek, a műveletet kifejező kulcsszó után az ALL kulcsszót kell használjuk.
pl.
(SELECT Név FROM Tanárok)
UNION ALL
(SELECT Név FROM Diákok);Milyen összesítőfüggvények léteznek az SQL nyelvben?
SUM, megadja az oszlop értékeinek az összegét
AVG, megadja az oszlop értékeinek a átlagértékét
MIN, megadja az oszlop értékeinek a minimumát
MAX, megadja az oszlop értékeinek a maximumát
COUNT, megadja az oszlopban szereplő értékek számát, beleértve az ismétlődéseket is, ha azok nincsenek megszüntetve a DISTINCT kulcsszóval
A COUNT összesítőfüggvény milyen formákkal rendelkezik? (Mire lehet mehívni?)
COUNT(*) - az eredmény-reláció kardinalitását (az összes sor számát) adja vissza
COUNT(oszlop_név) - azon sorok számát adja vissza, ahol oszlop_név értéke NULL-tól különböző érték
COUNT(DISTINCT oszlop_név) - megszámolja, hány különböző értéke van az oszlop_név mezőnek.
A GROUP BY használatakor, mire kell odafigyelni a SELECT után megadott attribútumok esetében?
A GROUP BY után megadjuk a csoportosító attribútumok (oszlopok) listáját, melyek azonos értéke szerint történik a csoportosítás. Csak ezeket az oszlopokat válogathatjuk ki a SELECT kulcsszó után és azokat, melyekre valamilyen összesítő függvényt alkalmazunk.
Ha a SELECT kulcsszó után olyan oszlopot választunk ki, melynek értékei különbözőek a lekérdezett relációban, a lekérdezés processzor nem tudja, hogy a különböző értékekből melyiket válassza az eredménybe.
A SELECT parancs megengedi viszont, hogy a csoportosító attribútum hiányozzon a vetített attribútumok listájából.
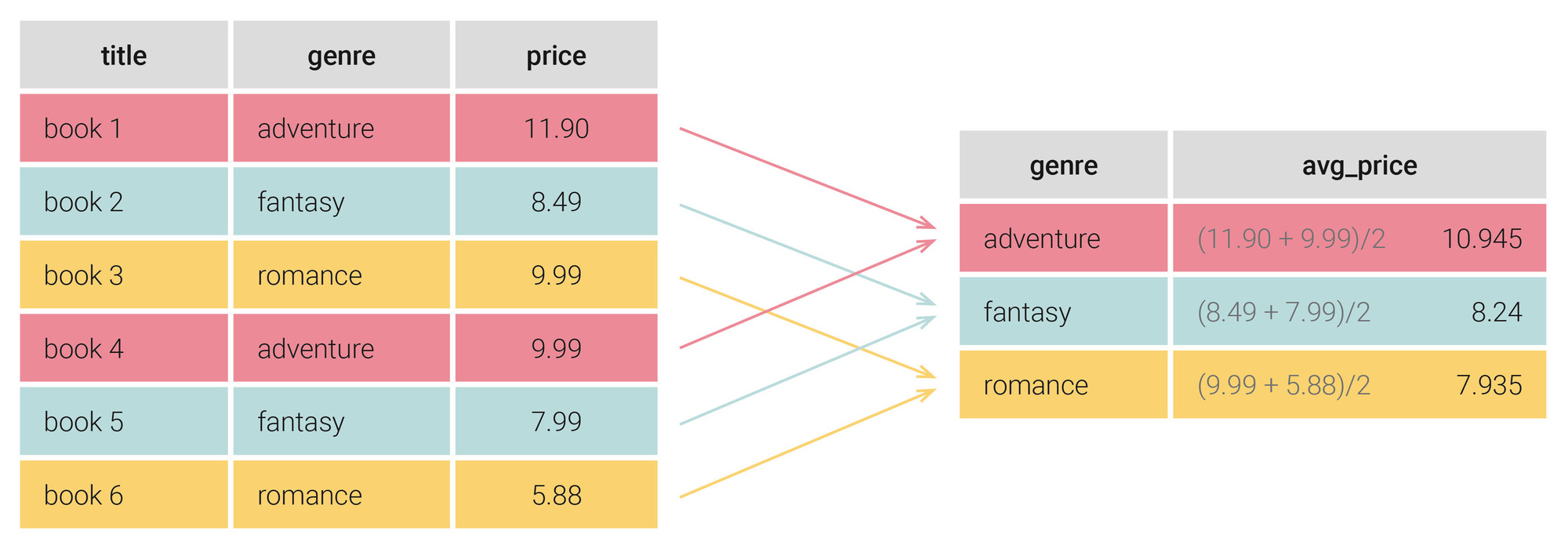
Hogyan tudunk feltételeket szabni a csoportosítás után?
A csoportosítás után kapott eredmény reláció soraira a HAVING kulcsszót használva egy feltételt alkalmazhatunk. Ha csoportosítás előtt szeretnénk kiszűrni sorokat, azokra a WHERE feltételt lehet alkalmazni. A HAVING kulcsszó utáni feltételben azon oszlopok szerepelhetnek, melyekre a SELECT parancsban összesítő függvényt alkalmaztunk.
pl.
SELECT RészlegID, AVG(Fizetés)
FROM Alkalmazottak
GROUP BY RészlegID
HAVING AVG(Fizetés) > 500
ORDER BY AVG(Fizetés);Hogyan valósítható meg és hogyan működik egy alkérés?
Alkérdést tartalmazó SELECT parancs általános formája a következő:
SELECT attribútum_lista
FROM tábla
WHERE kifejezés operátor
(SELECT attribútum_lista
FROM tábla);A rendszer először az alkérdést hajtja végre és annak eredményét használja a „fő” lekérdezés, kivéve a korrelált alkérdéseket.
Többsoros alkérések esetén, milyen operátorokkal tudunk feltételeket alkalmazni az eredményen?
A többsoros alkérdések esetén a WHERE záradék feltétele olyan operátorokat tartalmazhat, amelyeket egy R relációra alkalmazhatunk, ebben az esetben az eredmény logikai érték lesz. Bizonyos operátoroknak egy skaláris s értékre is szükségük van. Ilyen operátorok:
EXISTS R – feltétel, mely akkor és csak akkor igaz, ha R nem üres.
s IN R, mely akkor igaz, ha s egyenlő valamelyik R-beli értékkel. Az s NOT IN R akkor igaz, ha s egyetlen R-beli értékkel sem egyenlő.
s > ALL R, mely akkor igaz, ha s nagyobb, mint az R reláció minden értéke, ahol az R relációnak csak egy oszlopa van. A > operátor helyett bármelyik összehasonlítási operátort használhatjuk. Az s <> ALL R eredménye ugyanaz, mint az s NOT IN R feltételé.
s > ANY R, mely akkor igaz, ha s nagyobb az R egyoszlopos reláció legalább egy értékénél. A > operátor helyett akármelyik összehasonlítási operátort használhatjuk.
Mit nevezünk korrelált alkérésnek?
A beágyazott alkérdéseket úgy is lehet használni, hogy az alkérdés többször is kiértékelésre kerül. Az alkérdés többszöri kiértékelését egy, az alkérdésen kívüli sorváltozóval érjük el. Az ilyen típusú alkérdést korrelált alkérdésnek nevezzük.
pl.
SELECT Név, CsopKod
FROM Diákok D1
WHERE Átlag = 10 AND NOT EXISTS
(SELECT D2.BeiktatásiSzám
FROM Diákok D2
WHERE D1.CsopKod = D2.CsopKod
AND D1.BeiktatásiSzám <> D2.BeiktatásiSzám
AND D2.Átlag = 10);A lekérdezés kiértékelése során a D1 sorváltozó végigjárja a Diákok relációt. Minden sorra a D1-ből a D2 sorváltozó segítségével ismét végigjárjuk a Diákok relációt.
Mit eredményez az OUTER kulcsszó használata egy JOIN esetén? Milyen változatai vannak?
Az OUTER JOIN kulcsszó segítségével azon sorok is megjelennek az eredményben, melyek értéke a közös attribútumra nem található meg a másik táblában, vagyis a lógó sorok, melyekben a másik tábla attribútumai NULL értékeket kapnak.
R LEFT OUTER JOIN S ON R.X = S.XAz eredmény tartalmazza a bal oldali R reláció összes sorát, azokat is, amelyek esetében az X attribútumhalmaz értéke nem létezik az S reláció X értékei között.
R RIGHT OUTER JOIN S ON R.X = S.XAz eredmény a jobb oldali S reláció összes sorát tartalmazza, azokat is amelyek esetében az X attribútumhalmaz értéke nem létezik az R reláció X értékei között.
R FULL OUTER JOIN S ON R.X = S.XAz eredmény azon sorokat tartalmazza, melyek esetében a közös attribútum értéke megegyezik mindkét relációban és mind a bal oldali R reláció lógó sorait, mind az S reláció lógó sorait magában foglalja.
Milyen sorrendben hajtódnak végre az SQL záradékok?
FROM és/vagy JOIN
WHERE
GROUP BY
HAVING
SELECT
DISTINCT
ORDER BY
LIMIT
Hogyan kell egy táblát létrehozni SQL nyelvben?
pl. (A legfontosabb kulcsszavakkal)
CREATE TABLE Employees (
EmpID INT PRIMARY KEY,
EmpNum INT UNIQUE,
FirstName VARCHAR(50) NOT NULL,
LastName VARCHAR(50) NULL,
Age INT CHECK (Age >= 18 AND Age <= 65),
DeptID INT,
Salary DECIMAL(10,2) DEFAULT 3000.00,
CONSTRAINT FK_Dept FOREIGN KEY (DeptID) REFERENCES Departments(DeptID)
);Hogyan kell értékeket beszúrni egy táblába SQL nyelvben?
pl.
INSERT INTO Employees (EmpID, EmpNum, FirstName, LastName, Age, DeptID)
VALUES
(100, 2001, 'János', 'Kiss', 30, 1),
(101, 2002, 'Anna', 'Nagy', 25, 2);Hogyan kell értékeket frissíteni SQL nyelvben?
pl.
UPDATE Employees
SET Salary = 3500.00
WHERE EmpID = 100;Hogyan kell sorokat törölni SQL nyelvben?
pl.
DELETE FROM Employees
WHERE EmpID = 101;Hogyan kell egy meglévő táblát módosítani SQL nyelvben?
pl.
-- Új oszlop hozzáadása
ALTER TABLE Employees
ADD Email VARCHAR(100) UNIQUE;
-- Egy meglévő oszlop módosítása
ALTER TABLE Employees
ALTER COLUMN Age INT NULL;
-- Egy megszorítás (CHECK) hozzáadása
ALTER TABLE Employees
ADD CONSTRAINT CHK_Salary CHECK (Salary >= 2000);
-- Egy megszorítás (UNIQUE) eltávolítása
ALTER TABLE Employees
DROP CONSTRAINT CHK_Salary;
-- Egy oszlop törlése
ALTER TABLE Departments
DROP COLUMN DeptLocation;Hogyan lehet limitálni a sorok számát egy lekérdezésben?
A TOP kulcsszó arra szolgál SQL-ben, hogy lekérdezések eredményében korlátozzuk a visszaadott sorok számát.
pl.
-- Az első 3 sort adja vissza
SELECT TOP 3 * FROM vasarlok;
-- Az első 50%-át adja vissza
SELECT TOP 50 PERCENT * FROM vasarlok;