CS241: processes
1/59
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
60 Terms
Process
A program in execution; an active entity with its own address space and system resources.
Program
A passive entity stored on disk as an executable file.
link between program and process
A program becomes a process when it is loaded into memory. Execution can be started by many methods (double click, command line etc.)
process in memory (draw diagram)
Text segment: Part of process memory that stores instructions.
Data segment: Part of process memory that stores global variables.
Heap: Dynamically allocated memory during process run-time.
Stack: Stores local variables and function parameters like return addresses.
space between stack and heap allow them to grow or shrink
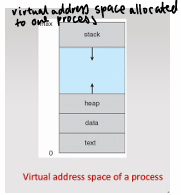
Text segment
Part of process memory that stores instructions.
Data segment
Part of process memory that stores global variables.
Heap
Dynamically allocated memory during process run-time.
Stack
Stores local variables and function parameters like return addresses.
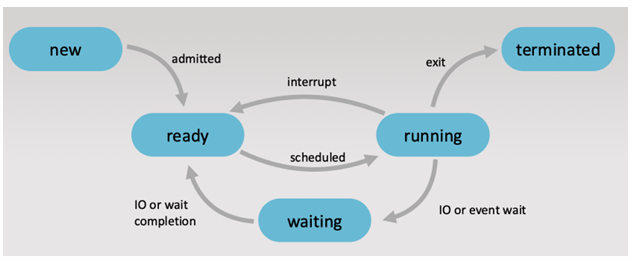
Process States (draw diagram)
Different states a process can be in: new, ready, running, waiting, terminated.
New: Process is being created.
Running: Instructions are being executed.
Waiting: Process is waiting for an event to occur.
Ready: Process is waiting to be assigned to a processor.
Terminated: Process has finished execution.
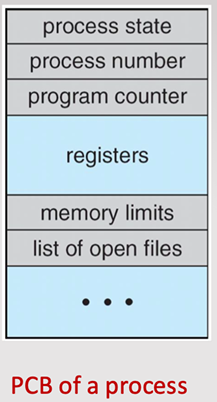
Process Control Block (PCB)
Data structure used by the operating system to store all information about a process. But the PCB is maintained by the OS, not by the process itself:
The Operating System kernel owns and maintains all PCBs.
the PCB represents the process in the OS
Process Control Block structure (draw)
Process State | Current status: new, ready, running, waiting, or terminated |
Program Counter | Address of the next instruction to execute |
CPU Registers | Contents of all process-specific registers |
Memory Management Info | Details like page tables, memory limits, etc. |
CPU Scheduling Info | Priority, scheduling queue pointers, etc. |
Accounting Info | CPU usage, process start time, etc. |
I/O Status Info | List of open files, I/O devices assigned, etc. |
includes pointer field that points to the next PCB in the ready queue
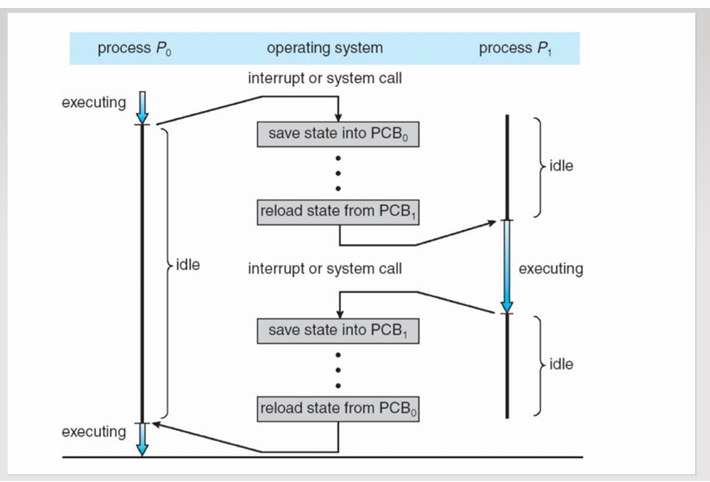
Context Switch ( explain process)
Switching the CPU from one process to another by saving and loading states:
system saves the state of the current process in PCB (performs state save of current process)
system loads the saved state of the new procee (performs state restor of new process)
why is context switch time an overhead?
During the switch, the CPU isn't doing any useful "real" work for the user—it’s just saving/loading states.
It’s purely system overhead.
Time is dependent on hardware support
concurrency
The ability of the system to execute multiple processes or threads simultaneously, allowing for efficient resource usage and improved performance.
What are the queues the OS schedulers maintains for processes
Job Queue: Set of all processes in the new state. managed by long term scheduler
Ready Queue: Set of processes waiting to be assigned to the CPU( in ready state). managed by short term scheduler. stored as linked list
Device Queue: Set of processes that are waiting for an IO device. each device has its own device queue
Job Queue
Set of all processes in the new state. long term scheduler
Ready Queue
Set of processes loaded in memory, waiting to be assigned to the CPU. short term scheduler. stored as linked list
Device Queue
Set of processes that are waiting for an IO device. each device has its own device queue
Short-term Scheduler
Selects next process from the ready queue for execution.
operates often and rapidly
must be fast
The short-term scheduler is responsible for selecting a process from the ready queue and allocating the CPU to it. It operates frequently and makes rapid decisions, often every few milliseconds, to maximize CPU utilization and system responsiveness. The short-term scheduler determines which process will execute next among the processes that are ready and waiting in memory
Long-term Scheduler
selects proceses in the new state to bring into main memory in the ready queue
much less frequent
controls degree of multi-programming: no. processes in memory
if stable, job arrivate rate= completion rate
The long-term scheduler controls the admission of new processes into the system. It selects processes from the job pool (typically stored on disk) and loads them into main memory to enter the ready queue. The long-term scheduler regulates the degree of multiprogramming by controlling the number of processes in memory, balancing CPU-bound and I/O-bound processes to optimize system performance.
processes can be described as:
IO bound (more time on IO and waiting for devices) , CPU bound (more time on computation). Long-term schedulers strive for a good process mix
I/O Bound
Process that spends more time on I/O than computation. short CPU bursts
CPU Bound
Process that spends more time on computation than I/O. Long CPU bursts
Process ID (PID)
A unique number used to identify a process.
how is a process created?
A system process (parent) creates a user process (child)using the fork system call in Unix-like operating systems.
fork()
System call used to create a child process in UNIX-based systems.
how does fork() work?
if successful fork() creates a child process and returns PID to parent
if unsuccessful fork() returns a negative
creates child process whose address space is a copy of the parent’s address space
execlp() system call erases the old content of the address space and replaces it with a new executeable file and starts runnign newly loaded program
execlp()
System call that replaces the current process image with a new program (executeable file).
What are the options for process creation?
Address space options: In fork(), the child’s address space is a duplicate of that of its parent. they are separate copies, changes in child’s memory don’t impact the parent
Resource (CPU, memory, file) sharing options: Parent and children share all resource (like threads often do). Children share subset of parent resources but memory is separate. Parent and child share no resources
Execution options: After a fork, who runs when? Parent and children execute concurrently. Parent waits until children terminates
Process termination
A process terminates automatically after executing its last statement or via the exit() system call.
how does process termination work?
return a status value(exit code) to parent
all resources of the process released back to OS
zombie process
orphan process
abort()
Zombie process
A terminated child process whose exit status has not yet been collected by its parent. all resources of the child are released but its entry is still in the process table.
Orphan process
A child process whose parent has terminated without invoking wait.
init process periodically issues the wait() to collect the exit status of all orphan processes
allows exit status to be collected and releases the orphan’s PID and process table entry
what is abort()? when is it used?
System call used by a parent to terminate a child process.
child exceeds its allocate resources
task assigned isn’t needed anymore
cascading termination: parent is exiting and OS doesn’t allow a child to continue if the parent terminates
wait()
allows parent to obtain exit status of child. also returns PID of terminated child
Inter-process Communication (IPC)
Method for processes to communicate and synchronize their actions. can use one of two models: shared memory, message passing.
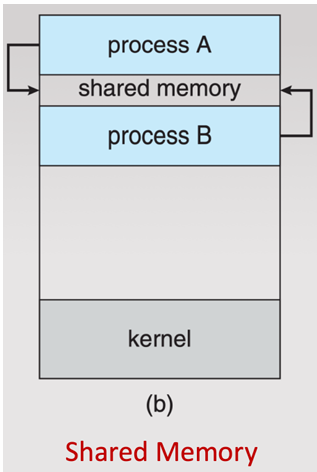
Shared Memory
A memory region shared between processes for communication.
shared memory is in the address space of the communicating process creating a shared memory segment
other processes need permisssion to access it
kernel is required to set yp shared memory and grant necessary permissions
once shared memory is established, processes are repsonsible for maintaining proper synch
Message Passing
Processes communicate by sending and receiving messages.
kernel provides a logical communication channel
system calls are used to pass messages
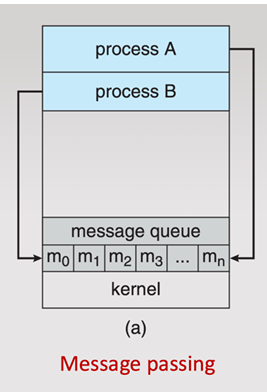
when to use message passing
Processes are on different systems (e.g., in a distributed system or over a network).
You want strong isolation between processes (each with separate memory).
Simpler and easier to implement—no need for complex synchronization.
Communication is less frequent or small in volume.
You want modular and loosely coupled process design.
✅ Examples:
Client-server communication over sockets (e.g., a web browser and a web server).
Microkernel OS where user-level services interact with the kernel via message passing.
A chat app where messages are sent between clients using a server as a broker.
when to use shared memory
Processes run on the same machine and need high-speed data exchange.
You’re working with large amounts of data or need low-latency communication.
You need to share a lot of state or data structures (e.g., buffers, logs).
You can (or want to) implement fine-grained synchronization using semaphores, mutexes, etc.
Examples:
Video/audio processing pipelines, where producer and consumer processes share frame/audio buffers.
Database systems, where multiple processes access shared in-memory data caches.
Real-time systems, like robotics or sensor fusion systems that need fast shared access to data
Producer
Process that generates data to be consumed and inserts items into a shared buffer
Consumer
Process that uses data produced by another process and removes items from a shared buffer
shared buffer
It’s a bounded memory space (limited in size).
Acts as a communication channel between producer and consumer.
Often implemented as a circular queue (as in your diagram), where:
inpoints to the next index to insert data.outpoints to the next index to consume data.When
in == out, the buffer is empty.When
(in + 1) % buffer_size == out, the buffer is full.
why is there a wait in the shared buffer?
Consumer waits if buffer is empty (nothing to consume).
Producer waits if buffer is full (no room to produce).
this is the boudned-buffer probelm, example of synchronisation
how to solve the bounded-buffer issue/ synch issues?
Mutex (lock): Ensures only one process accesses the buffer at a time.
Semaphore (counting): Tracks empty and full slots in the buffer.
Condition variables: Sometimes used to block and wake threads/processes when buffer states change.
send(message)
System call to send a message to another process.
receive(message)
System call to receive a message from another process.
implementation of message passing system depends on
link implementation: direct or indirect communication
sycnhronisation between send() and receive()
buffer size for link
Direct Communication
Processes explicitly name each other to send/receive messages.
Indirect Communication
Processes communicate via mailboxes or ports.
synchronisation
blocking is considered synchronous
Blocking Send
Sender is blocked until the message is received. synch
Blocking Receive
Receiver is blocked until a message is available. synch
Non-blocking Send
Sender sends a message and continues execution. asynch
Non-blocking Receive
Receiver gets a message if available, otherwise continues. asynch
Zero Capacity Buffer
Sender must wait until the message is received. max length of zero
Bounded Capacity Buffer
Buffer has finite size; sender waits if full.
Unbounded Capacity Buffer
Buffer has no size limit; sender never blocks. queue’s length is potentially infinite
Pipe
Unidirectional communication channel between processes.
Named Pipe
Persistent pipe identified by a name in the filesystem.