Distributed Computing Finals
1/57
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
58 Terms
Processor
provides a set of instructions along with the capability of
automatically executing a series of those instructions.
Thread
a minimal software processor - in whose context - a series of instructions can be executed. Saving a thread context implies stopping the current execution and saving all the data needed to continue the execution at a later stage.
is the unit of execution within a
process performing a task.
Process
a software processor - in whose context - one or more threads may be executed. Executing a thread means executing a series of instructions in the context of that thread.
can have single or multiple threads.
when a process starts, memory and resources are allocated which are shared by each thread.
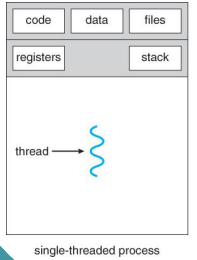
single-threaded
in a ______ process, both the process and thread are the same.
a______ process can perform one task at a time.
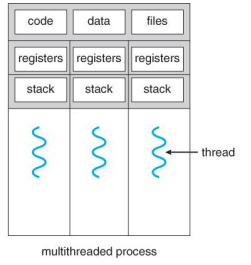
multi-threaded
a _____ process can perform multiple tasks at the same time.
How do you think can we make a processor truly perform multiple tasks parallelly?
▪ In relation to hardware, add more CPUs (servers with multiple CPU sockets).
▪ All the modern processors are multi-core processors, meaning, a single physical processor will have more than one CPU in it.
▪ Multi-core processors are capable of running more than one process or thread at the same time. Example, a quad-core processor has 4 CPU cores, it can run 4 processes or threads at the same time in parallel (Parallelism).
Parallelism
Run processes/threads at the same time in parallel
Processor Context
the minimal collection of values stored in the registers
of a processor used for the execution of a series of instructions (e.g., stack pointer, addressing registers, program counter).
Thread Context
the minimal collection of values stored in registers and
memory, used for the execution of a series of instructions (i.e., processor context, thread state – running/waiting/suspended).
Process Context
the minimal collection of values stored in registers and
memory, used for the execution of a thread (i.e., thread context, but now also at least memory management information such as Memory Management Unit (MMU) register values).
Context Switching OBSERVATIONS
1. Threads share the same address space. Thread context switching can be done entirely independent of the operating system.
2. Process switching is generally (somewhat) more expensive as it involves
getting the OS in the loop, i.e., trapping to the kernel.
3. Creating and destroying threads is much cheaper than doing so for processes.
threads
are lightweight units of execution that allow efficient
multitasking within a process.
processes
are heavier, independent units of execution that require more overhead for creation, switching, and destruction.
Why Use Threads?
❖ AVOID NEEDLESS BLOCKING: a single-threaded process will block when doing I/O; in a multi-threaded process, the operating system can switch the CPU to another thread in that process.
❖ EXPLOIT PARALLELISM: the threads in a multi-threaded process can be scheduled to run in parallel on a multiprocessor or multicore processor.
❖ AVOID PROCESS SWITCHING: structure large applications not as a collection of processes, but through multiple threads.
Avoid Process Switching
*Avoid expensive context switching
Trade-offs:
o Threads use the same address space: more prone to errors.
o No support from OS/HW to protect threads using each
other’s memory.
o Thread context switching may be faster than process context.
Threads and Operating Systems
o Main Issue - Should an OS kernel provide threads, or should they be implemented as user-level packages?
o User-space solution | threads are managed by a library/user-level package than the kernel:
✓ All operations can be completely handled within a single process ⇒ Implementations
can be extremely efficient.
✓ All services provided by the kernel are done on behalf of the process in which a thread resides ⇒ if the kernel decides to block a thread, the entire process will be
blocked.
✓ Threads are used when there are lots of external events: threads block on a per-event basis ⇒ if the kernel can’t distinguish threads, how can it support signaling events to them?
o Kernel solution | to have the kernel contain the implementation of a thread package. This means that all operations return as system calls.
✓ Operations that block a thread are no longer a problem: the kernel schedules another available thread within the same process.
✓ Handling external events is simple: the kernel (which catches all events) schedules the thread associated with the event.
✓ The problem is (or used to be) the loss of efficiency due to the fact that each thread operation requires a trap (system call that causes the CPU to switch from user mode to kernel mode) to the kernel.
Conclusion – but: try to mix user-level and kernel-level threads into a single concept, however, performance gain has not turned out to outweigh the increased complexity.
User-space solution
| threads are managed by a library/user-level package than the kernel:
✓ All operations can be completely handled within a single process ⇒ Implementations
can be extremely efficient.
✓ All services provided by the kernel are done on behalf of the process in which a thread resides ⇒ if the kernel decides to block a thread, the entire process will be
blocked.
✓ Threads are used when there are lots of external events: threads block on a per-event basis ⇒ if the kernel can’t distinguish threads, how can it support signaling events to them?
Kernel Solution
to have the kernel contain the implementation of a thread package. This means that all operations return as system calls.
✓ Operations that block a thread are no longer a problem: the kernel schedules another available thread within the same process.
✓ Handling external events is simple: the kernel (which catches all events) schedules the thread associated with the event.
✓ The problem is (or used to be) the loss of efficiency due to the fact that each thread operation requires a trap (system call that causes the CPU to switch from user mode to kernel mode) to the kernel.
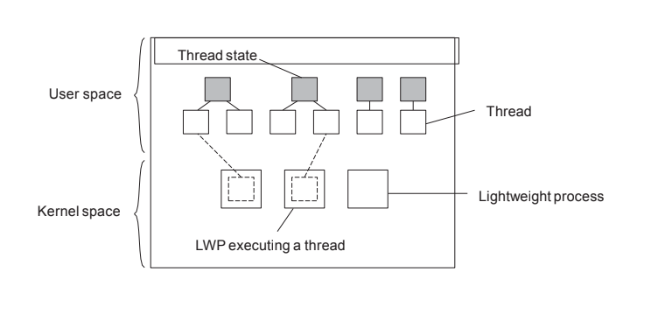
Lightweight Processes
Basic idea
Introduce a two-level threading approach: lightweight processes that can execute user-level threads.
Principle Operation
▪ User-level thread does a system call ⇒ the LWP that is executing that thread, blocks. The thread remains bound to the LWP.
▪ The kernel can schedule another LWP having a runnable thread bound to it.
Note: this thread can switch to any other runnable thread currently in user space.
▪ A thread calls a blocking user-level operation ⇒ do a context switch to a runnable thread, (then bound to the same LWP).
▪ When there are no threads to schedule, an LWP may remain idle, and may even be removed (destroyed) by the kernel.
Multithreaded Web Client
Hiding network latencies:
▪ The web browser scans an incoming HTML page and finds that more files need to be fetched.
▪ Each file is fetched by a separate thread, each doing a (blocking) HTTP request.
▪ As files come in, the browser displays them.
Using Threads at the Client Side
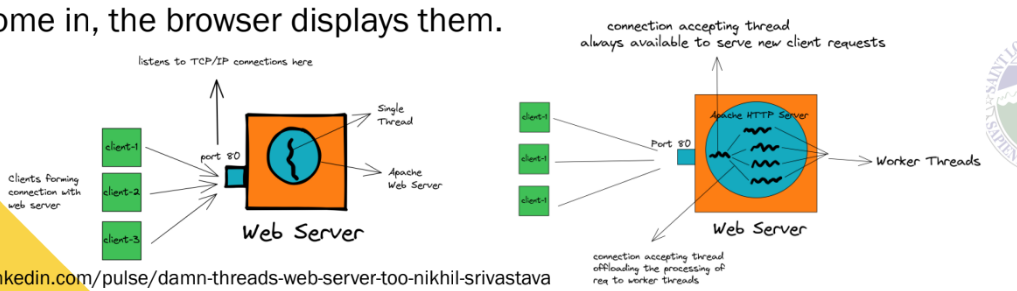
Multiple request-response calls to other machines (RPC)
▪ A client does several calls at the same time, each one by a different thread.
▪ It then waits until all results have been returned.
▪ Note: if calls are to different servers, we may have a linear speed-up.
Using Threads at the Client Side
Using Threads at the Server Side
Improve Performance
▪ Starting a thread is cheaper than starting a new process.
▪ Having a single-threaded server prohibits simple scale-up to a multiprocessor system.
▪ As with clients: hide network latency by reacting to the next request while the previous one is being replied.
Better Structure
▪ Most servers have high I/O demands. Using simple, well-understood blocking calls simplifies the overall structure.
▪ Multithreaded programs tend to be smaller and easier to understand due to the simplified flow of control.
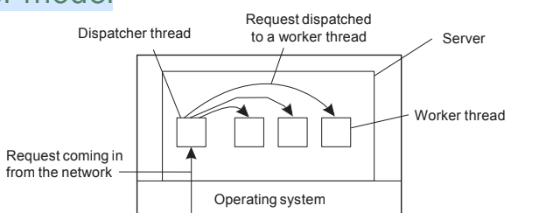
Dispatcher/worker model
Overview
Dispatcher/Worker Model
Model Characteristics
Multithreading
Parallelism
Blocking system calls
Single-threaded Process
No parallelism
Blocking system calls
Finite-State Machine
Parallelism
Nonblocking system calls
Types of Virtualization
Application
Server
Desktop
Storage
Network
Data
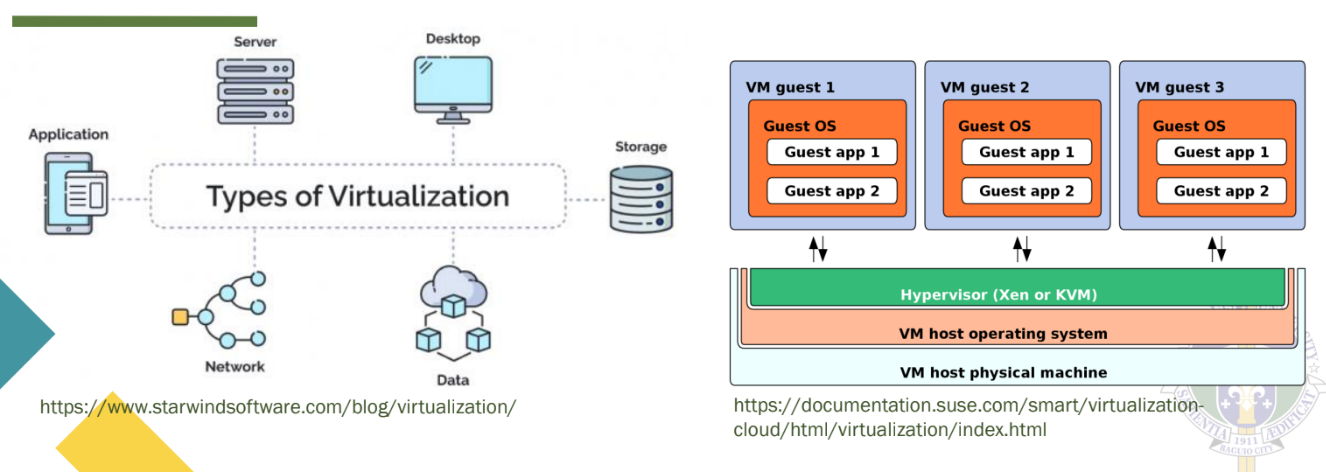
Virtualization
Observation | Virtualization is important:
▪ Hardware changes faster than software
▪ Ease of portability and code migration
▪ Isolation of failing or attacked components
Principle: mimicking interfaces
▪ simulating hardware or software interfaces in a virtual environment
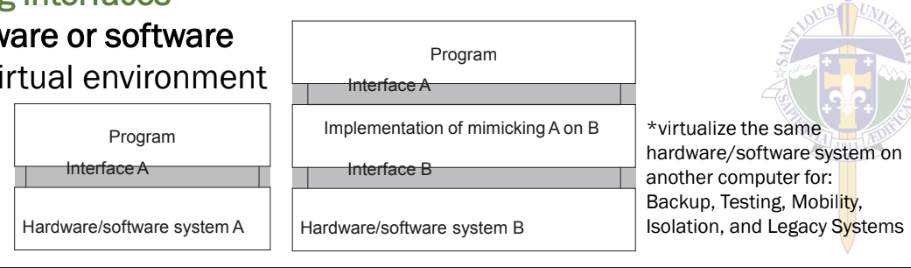
Interfaces at three different levels
1. Instruction set architecture: the set of machine instructions, with two subsets:
⦿Privileged instructions: allowed to be executed only by the operating system.
⦿General instructions: can be executed by any program.
2. System calls as offered by an operating system.
3. Library calls, known as an application programming interface (API).
Mimicking Interfaces
Ways of Virtualization
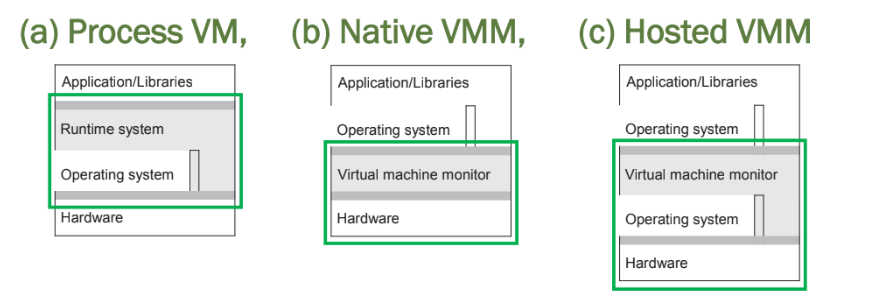
(a) Process VM, (b) Native VMM, (c) Hosted VMM
Differences:
a) Platform-independent; separate set of instructions - an interpreter/emulator, running atop an OS.
b) Has direct access to hardware; Low-level instructions, along with bare-bones minimal OS instructions.
c) Runs on top of an existing OS; may be slower to native VMM due to extra OS layer.
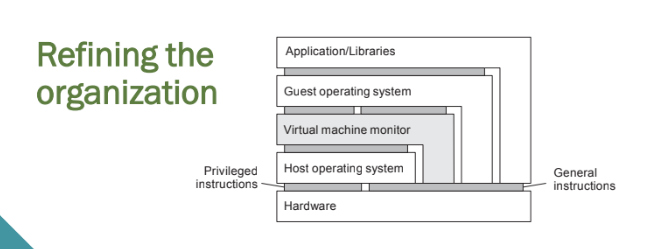
Zooming into VMs: Performance
▪ Privileged instruction: if and only if executed in user mode, it causes a trap to the OS (switch control from user to kernel mode for the OS to perform a privileged operation on behalf of the user program)
▪ Nonprivileged instruction: the rest
Special instructions
▪ Control-sensitive instruction: may affect the configuration of a machine, may trap (e.g., one affecting relocation register or interrupt table).
▪ Behavior-sensitive instruction: effect is partially determined by the system context (e.g., POPF sets an interrupt-enabled flag, but only in system mode).
Condition for virtualization
Necessary condition
For any conventional computer, a virtual machine monitor may be constructed if the set of sensitive instructions for that computer is a subset of the set of privileged instructions.
Problem: the condition is not always satisfied
There may be sensitive instructions that are executed in user mode without causing a trap
to the operating system.
Solutions
▪ Emulate all instructions
▪ Wrap nonprivileged sensitive instructions to divert control to VMM
▪ Paravirtualization: modify guest OS, either by preventing nonprivileged sensitive instructions, or making them nonsensitive (i.e., changing the context).
- guest OS uses hypercalls for privileged operations.
Three types of cloud services
❖ INFRASTRUCTURE-AS-A-SERVICE: covering the basic infrastructure
❖ PLATFORM-AS-A-SERVICE: covering system-level services
❖ SOFTWARE-AS-A-SERVICE: containing actual applications
VMs and cloud computing
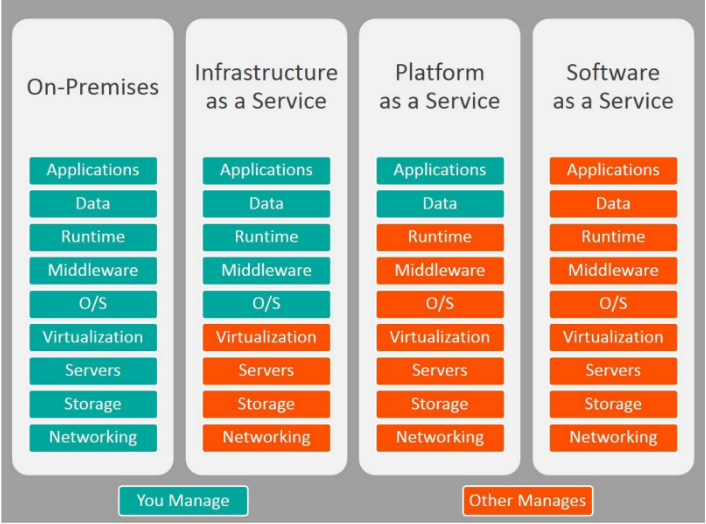
IaaS
Instead of renting out a physical machine, a cloud provider will rent out a VM (or VMM) that may possibly be sharing a physical machine with other customers ⇒ almost complete isolation between customers (although performance isolation may not be reached).
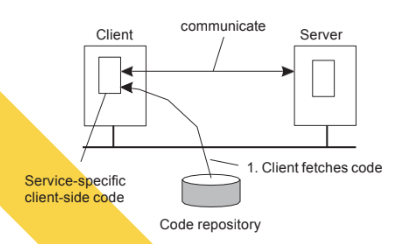
Client-server interaction
Application-level
Each new application must implement its own protocol logic, leading to higher development effort and less reuse.
Middleware-level
Promotes code reuse, interoperability, and simplifies development by abstracting network details from the application.
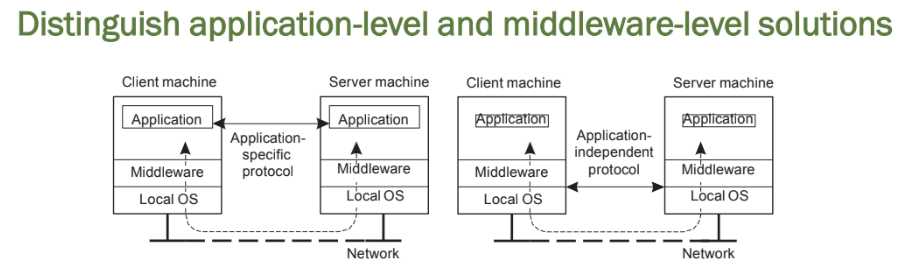
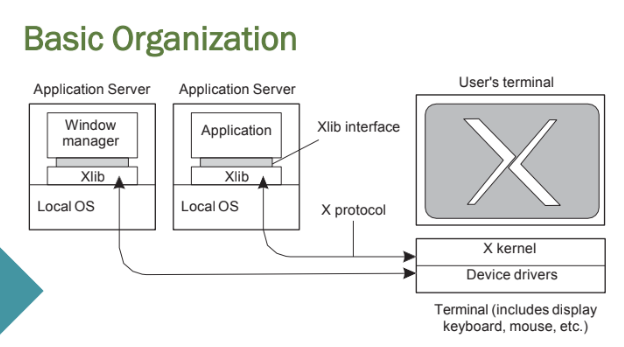
ex: The X Window System
1. The client app (on a remote machine) uses Xlib to communicate.
2. It sends GUI commands over the X protocol to the X server.
3. The X server renders graphics and sends back user input (keyboard/mouse) events.
X client and server
The application acts as a client to the X-kernel, the latter running as a server on the client’s machine.
Improving X
Practical Observations
▪ There is often no clear separation between application logic and user-interface commands (mixed)
▪ Applications tend to operate in a tightly synchronous manner with an X kernel (affects performance – waits for responses)
Alternative approaches
▪ Let applications control the display completely, up to the pixel level (e.g., VNC)
▪ Provide only a few high-level display operations (dependent on local video drivers), allowing more efficient display operations.
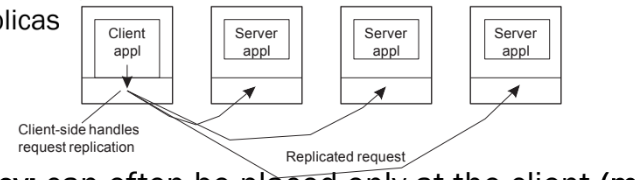
Client-side software
Generally tailored for distribution transparency
▪ Access transparency: conceal resource access using client-side stubs for RPCs
▪ Location/migration transparency: conceal resource location and let client-side software keep track of the actual location
▪ Replication transparency: multiple invocations handled by the client stub: *clients do not see replicas
▪ Failure transparency: can often be placed only at the client (mask server and
communication failures).
Servers: General organization
Basic model
A process implementing a specific service on behalf of a collection of clients. It waits for an incoming request from a client and subsequently ensures that the request is taken care of, after which it waits for the next incoming request.
Concurrent servers
▪ Iterative server: The server handles the request before attending the next request.
▪ Concurrent server: Uses a dispatcher, which picks up an incoming request that is then passed on to a separate thread/process. It can handle multiple requests in parallel (at the same time).
Observation
Concurrent servers are the norm: they can easily handle multiple requests, notably in the presence of blocking operations (to disks or other servers).
Iterative Server
The server handles the request before attending the next request.
Concurrent Server
Uses a dispatcher, which picks up an incoming request that is then passed on to a separate thread/process. It can handle multiple requests in parallel (at the same time).
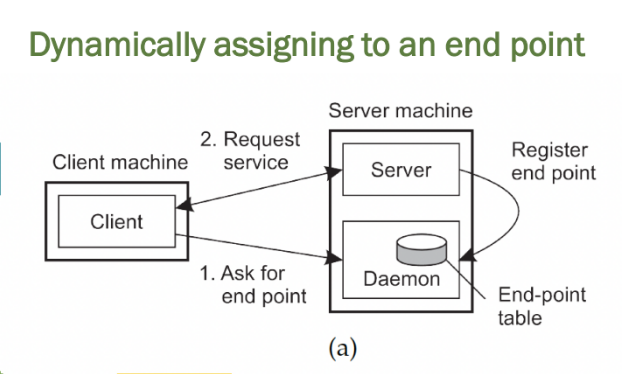
Contacting a server (Daemon Registry)
Observation
Most services are tied to a specific port
1. The client asks the daemon on the server machine for an available endpoint.
2. The daemon provides the client with the endpoint and the client uses it to request service from the appropriate server.
3. The server registers its endpoint with the daemon (which maintains an endpoint table).
Diagram (a) uses a daemon to manage and register server endpoints, where the server is always running and clients request endpoints dynamically. This approach suits persistent services but can be resource-intensive.
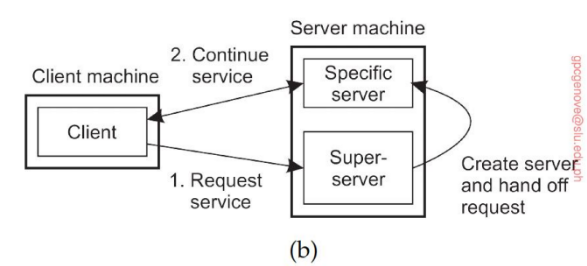
Contacting a server (Super-Server Model)
1. The client sends a request for service to a super-server.
2. The super-server dynamically creates or activates a specific server.
3. The specific server takes over and continues servicing the client directly.
diagram (b) employs a super-server that activates or spawns a specific server only when a client request arrives, making it more resource-efficient and scalable—ideal for on-demand or multi- service environments.
Out-of-band communication
Issue
Is it possible to interrupt a server once it has accepted (or is in the process of accepting) a service request?
Solution 1: Use a separate port for urgent data
▪ Server has a separate thread/process for urgent messages
▪ Urgent message comes in ⇒ associated request is put on hold
▪ Note: we require OS supports priority-based scheduling
Solution 2: Use facilities of the transport layer
▪ Example: TCP allows for urgent messages in same connection
▪ Urgent messages can be caught using OS signaling techniques
Stateless servers
Never keep accurate information about the status of a client after having handled a request:
▪ Don’t record whether a file has been opened (simply close it again after access)
▪ Don’t promise to invalidate a client’s cache
▪ Don’t keep track of your clients
Consequences
▪ Clients and servers are completely independent
▪ State inconsistencies due to client or server crashes are reduced
▪ Possible loss of performance because, e.g., a server cannot anticipate client behavior (think of prefetching file blocks)
Servers and state
Stateful servers
Keeps track of the status of its clients:
▪ Record that a file has been opened, so that prefetching can be done
▪ Knows which data a client has cached, and allows clients to keep local copies of shared data
Observation
The performance of stateful servers can be extremely high, provided clients are allowed to keep local copies. As it turns out, reliability is often not a major problem. However, this may be harder to scale.
Servers and state
Comparison
Stateless servers:
• do not retain any information about client interactions between requests, treating each request as independent and self-contained
• highly scalable, easier to manage, and fault-tolerant—ideal for RESTful APIs and services like DNS
• could be inconsistent
In contrast, stateful servers:
• maintain session information across requests, useful for more personalized and context-aware interactions, such as in online banking, shopping carts, or gaming
• harder to scale and less resilient to failures, often requiring more complex infrastructure to manage session state
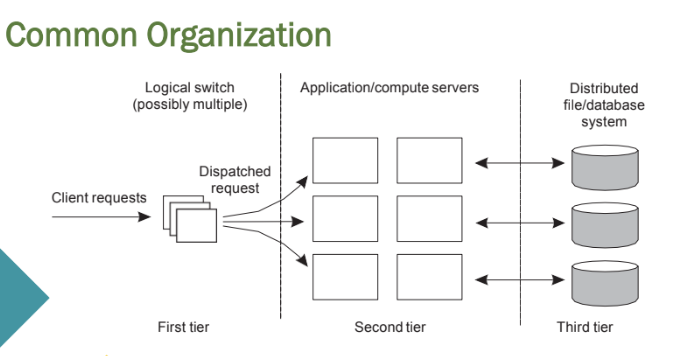
Three Different Tiers
Per tier:
1. Client requests first hit a logical switch or load balancer. The switch distributes the requests among multiple servers.
2. Each server processes business logic, performs computations, or prepares requests for the backend.
3. Handles data persistence, retrieval, and updates.
Crucial Element
The first tier is generally responsible for passing requests to an
appropriate server: request dispatching
Request Handling
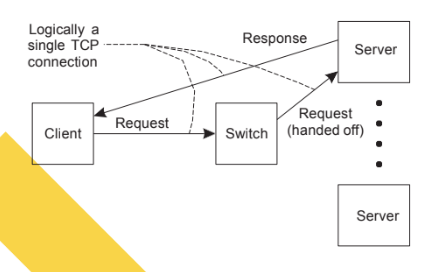
Observation
Having the first tier handle all communication from/to the cluster may lead to a bottleneck. Imagine only having one load balancer.
A solution: TCP handoff
With the TCP handoff:
• The selected server takes over the connection and continues communication with the client.
• The server processes the request and sends a response directly to the client.
• From the client’s perspective, it feels like a single continuous connection.
Server Clusters
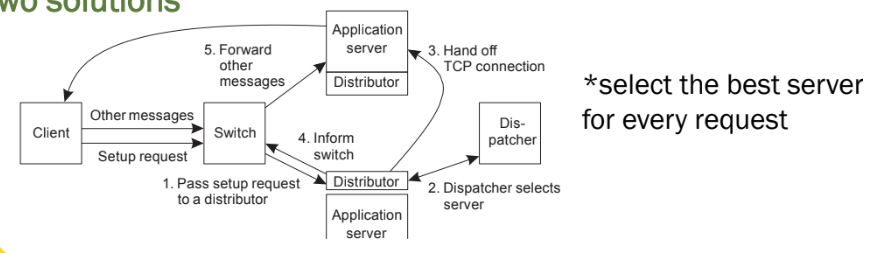
The front end may easily get overloaded: special measures may be needed
• Transport-layer switching: Front end simply passes the TCP request to one of the servers, taking some performance metric into account.
• Content-aware distribution: Front end reads the content of the request and then selects the best server.
Combining two solutions
When servers are spread across the Internet
Observation
Spreading servers across the Internet may introduce administrative problems. These can be largely circumvented by using data centers from a single cloud provider.
Request dispatching: if the locality is important
Common approach: use DNS:
1. Client looks up specific service through DNS – client’s IP address is part of the request
2. DNS server keeps track of replica servers for the requested service, and returns the address of most local or NEAREST servers.
Client Transparency
To keep the client unaware of distribution, let the DNS resolver act on behalf of the client. The problem is that the resolver may actually be far from local to the actual client.
Distributed servers with stable IPv6 address(es)
Route optimization can be used to make different clients believe they are communicating with a single server, where, in fact, each client is communicating with a different member node of the distributed server (Figure).
• When a distributed server's access point forwards a request from client C1 to server node S1 (with care-of address CA1), it includes enough information for S1 to begin a route optimization process.
• This process makes C1 believe that CA1 is the server’s current location, allowing C1 to store the pair (HA, CA1) for future communication. The access point and the home agent tunnel most of the traffic, ensuring the home agent does not detect a change in the care-of address.
• As a result, the home agent continues to communicate with the original access point, maintaining session continuity.
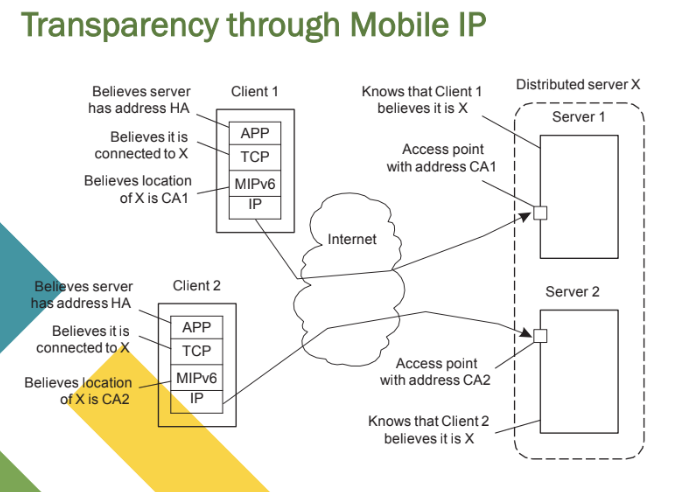
Distributed servers: addressing details
Essence: Clients having MobileIPv6 can transparently set up a connection to any peer
❖ Client C sets up connection to IPv6 home address HA.
❖ HA is maintained by a (network-level) home agent, which hands off the connection to a registered care-of address CA.
❖ C can then apply route optimization by directly forwarding packets to address CA (i.e., without the handoff through the home agent).
Collaborative distributed systems
Origin server maintains a home address, but hands off connections to the address of collaborating peer ⇒ origin server and peer appear as one server.
Example: PlanetLab
Essence:
Different organizations contribute machines, which they subsequently share for various experiments.
PlanetLab was a global research network that allowed researchers to test new protocols and services on a real-world, wide-area network. It consisted of hundreds of nodes (servers) hosted by universities and research institutions around the world.
Problem
We need to ensure that different distributed applications do not get into each other’s way ⇒ Virtualization
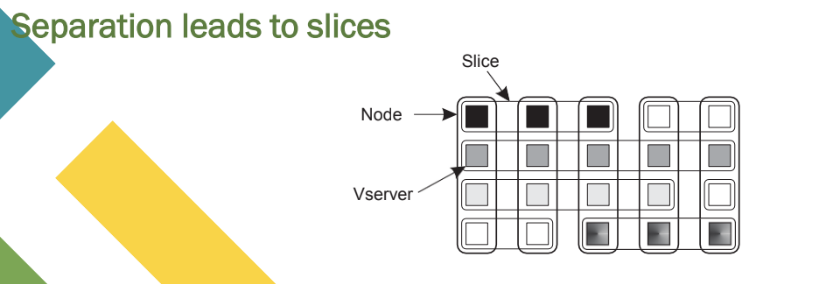
Vserver
Independent and protected environment with its own libraries, server versions, and so on.
Distributed applications are assigned a collection of Vservers distributed across multiple
machines
PlanetLab VServers and slices
Essence
❖ Each Vserver operates in its own environment.
❖ Linux enhancements include proper adjustment of process.
❖ Two processes in different Vservers may have same user ID, but does not imply the
same user.
Reasons to migrate code
Load distribution
❖ Ensuring that servers in a data center are sufficiently loaded (e.g., to prevent waste of energy)
❖ Minimizing communication by ensuring that computations are close to where the data is (think of mobile computing).
Flexibility: moving code to a client when needed
Code migration is the process of moving executable code from one machine to another in a distributed system to improve performance, efficiency, or flexibility. Avoids pre-installing software and increases dynamic configuration.
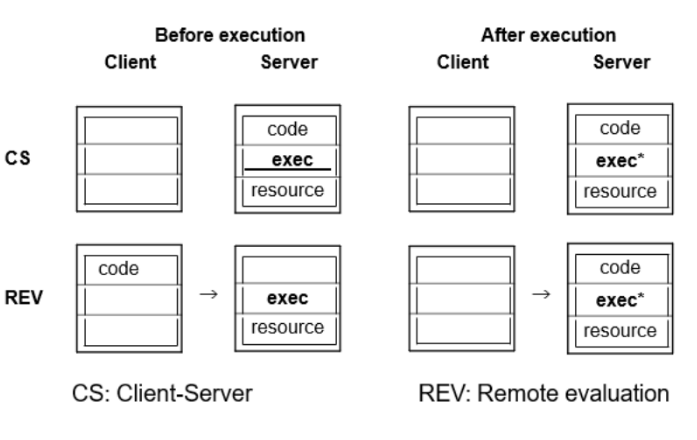
Models for code migration CS REV
Client-Server
• The client sends a request to a server. The server processes the request locally and sends back the result.
• Code stays put, only data moves between client and server.
Remote Evaluation
• The client sends code to the server to be executed there. Useful when the server has more data or resources.
• Code moves from client to server.
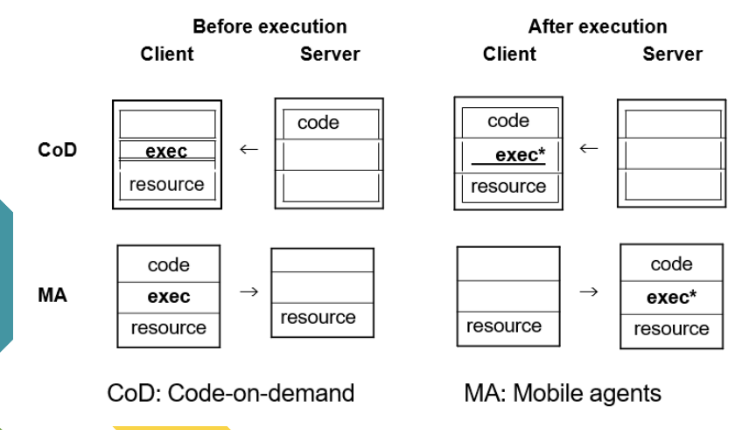
Models for code migration CoD MA
Code on Demand
• The server sends code to the client, where it's executed. Often used when clients need dynamic behavior or updates.
• Code moves from server to client.
Mobile Agents
• A mobile agent (code + execution state + data) moves from host to host, executing parts of its task at each.
• Code and state move between systems.
Strong and weak mobility
Object components in Code Migration
❖ Code segment: contains the actual code
❖ Data segment: contains the state
❖ Execution state: contains the context of the thread executing the object’s code
Weak mobility: Move only code and data segment (and reboot execution)
❖ Relatively simple, especially if the code is portable
❖ Distinguish code shipping (push) from code fetching (pull)
Strong mobility: Move component, including execution state
❖ Migration: move the entire object from one machine to the other
❖ Cloning: start a clone, and set it in the same execution state.
Migration in heterogeneous systems
Main Problem
❖ The target machine may not be suitable to execute the migrated code
❖ The definition of process/thread/processor context is highly dependent on local hardware, operating system and runtime system
Only solution: abstract machine implemented on different platforms
❖ Interpreted languages, effectively having their own VM
❖ Virtual machine monitors
❖ Migrate entire virtual machines including (OS and processes)
Migrating a virtual machine
Migrating images: three alternatives
1. Pushing memory pages (unit of memory management) to the new machine and resending the ones that are later modified during the migration process.
2. Stopping the current virtual machine; migrate memory, and start the new virtual
machine.
3. Letting the new virtual machine pull in new pages as needed: processes start on the new virtual machine immediately and copy memory pages on demand.

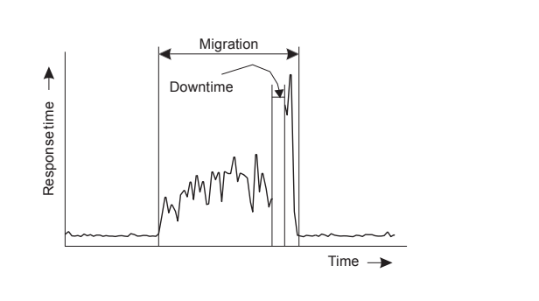
Performance of migrating virtual machines
Problem
A complete migration may actually take tens of seconds. We also need to realize that
during the migration, a service will be completely unavailable for multiple seconds.
Measurements regarding response times during VM migration