L12 - Operational Control of Cross-Linked Energy Systems by Means of Reinforcement Learning
1/12
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
13 Terms
Reinforcement learning (RL)
Reinforcement learning (RL) is an area of machine learning concerned with how intelligent agents take actions in an environment in order to maximize a cumulative reward.
Reinforcement learning uses the formal framework of Markov decision processes (MDPs), a discrete stochastic approach for designing a controller to minimize or maximize a measure of a dynamical system’s behavior (the reward) over time.
It uses the Markov Decision Process (MDP) framework — a mathematical model to decide actions that will improve performance over time.
policy (π)
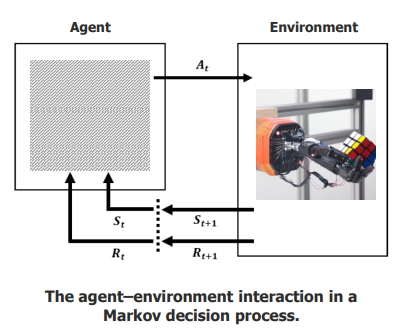
A policy is a mapping from perceived states (St ) of the environment to actions (At ) to be taken when in those states
The policy (π) is the core of an RL agent.
A policy maps states (Sₜ) to actions (Aₜ) for what to do in each situation.
The policy improves by getting rewards (Rₜ) from the environment.
A policy can be a simple lookup table or a complex search/computation.
Q-Learning
What is the goal
Lookup table
The objective of Q-Learning is to find a policy that is optimal in the sense that the expected return over all successive time steps is the maximum achievable
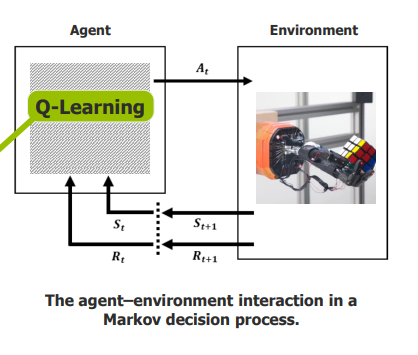
Q-Learning is a type of RL algorithm.
Goal: Find the optimal policy that maximizes the expected total reward over time.
Works by learning the value (Q-value) of taking an action in a given state.
How can we find that policy?
Policy maps states → actions.
Q-Learning solves it in 2 steps:
Find Q-values for every state–action pair.
Choose the action with the best Q-value.
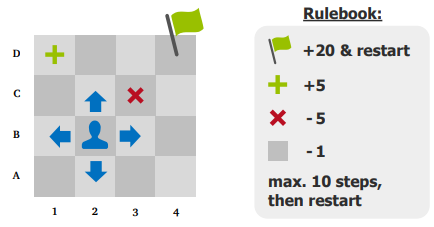
Rulebook:
Flag = +20 and restart
Green = +5
Red X = -5
Gray = -1
Max 10 steps before restart
What is Q-value?
What would happen if we know optimal Q-values?
Q-value = expected return from taking an action in a state, then following the policy.
If we knew optimal Q-values, we could use a greedy policy → always choose the action with the highest Q-value.
Bellman Equation
Q-values are updated using the Bellman optimality equation:
This is an iterative learning process — Q-table stores learned values about the environment.
Does it make sense to use the greedy policy all the time?
Pro: Yes, because we want to maximize the cumulative reward!
Contra: No, because then we will take the first solution that works and don’t explore more profitable ones!
Difference between greedy and 𝝐-greedy policy?
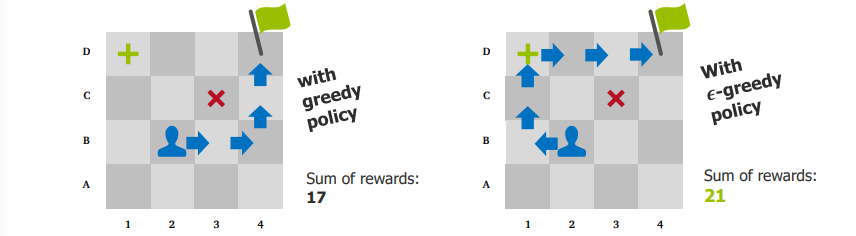
Greedy policy: Always picks the highest Q-value action → quick results, but may miss better paths.
ε-greedy policy: Sometimes picks random actions → allows discovering better solutions.
If we immediately follow the first working path we find, we might never find the extra points (or even the flag)
Exploration vs. Exploitation
Exploration is the act of exploring the environment to gather information about it
Exploitation is the act of exploiting the information that is already known in order to maximize the return
Exploration: Learning about the environment by trying different actions.
Exploitation: Using what is already known to get maximum reward.
ε-greedy policy: Mostly picks best Q-value, but with probability ε picks random action.
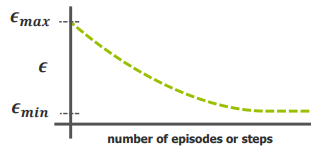
ε decreases over time (start high, end low).
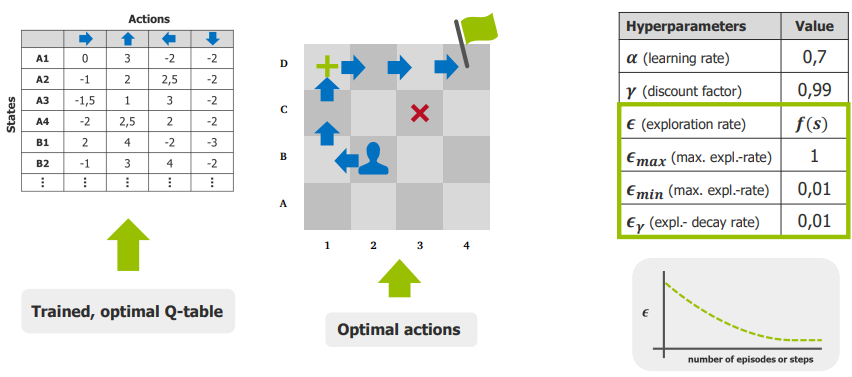
Optimal Q-Table & Hyperparameters
After training, we get an optimal Q-table.
From it, we can derive optimal actions for each state.
Key hyperparameters:
α (learning rate) = 0.7
γ (discount factor) = 0.99
ε_max = 1, ε_min = 0.01, ε_decay = 0.01
Simple vs. Complex Environments
Most environments relevant to real application cases are much more complex than our gridworld-example! It is not possible to gather and store the information about all states and actions. How is this problem solved?
Real-world environments are much more complex than the small grid example.
It’s impossible to store info for all states and actions.
Need advanced methods to handle large/continuous spaces.
What is Deep-Q Learning (DRL) ?
In normal Q-learning, we store Q-values in a table.
In Deep Q-Learning, we replace the Q-table with a deep neural network that can estimate Q-values.
RL + Deep Neural Networks = Deep Reinforcement Learning (DRL)
Advanced DRL Algorithms
Many advanced DRL algorithms exist beyond DQN, such as Proximal Policy Optimization (PPO).
These methods can be applied to games (Dota 2, Atari), robotics (robot hand), and industrial control systems.