BA476 Exam
1/162
Earn XP
Description and Tags
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
163 Terms
What is the threshold to predict a label of 1 in a logistic regression model?
It is typically set at 0.5, meaning if the predicted probability is greater than or equal to 0.5, the label is predicted as 1; otherwise, it is predicted as 0.
Given a logistic regression model p(x) = 1 / (1+e−(β0+β1x1+β2x2)), how do you calculate the odds of observing label 1 for a predicted probability of 0.7?
The odds are calculated as p(x)/(1−p(x)) = 0.7/1−0.7 = 2.33
What is the Gini Index used for in decision trees?
It measures the impurity of a node, with values closer to 0 indicating purer nodes. It is used to evaluate the best split at each node.
How do you calculate the Gini Index at a node with class distribution [0.7, 0.3]?
It is calculated as G=1−(p²1 + p²2), where p1 and p2 are the proportions of each class. G = 1 - (0.7² + 0.3²) = 1 - (0.49 + 0.09) = 0.42.
Best possible Gini index
0
Worst possible Gini index
0.5
In Random Forests, how do you select predictors at each split?
At each split, a random subset of predictors is selected, and the best split is chosen based on that subset. This helps reduce overfitting by decorrelating the trees.
What is the general idea behind Random Forests' ensemble learning approach?
use multiple decision trees trained on bootstrapped samples of the data. The final prediction is the majority vote (for classification) or average (for regression) from all trees.
What is the key difference between Bagging and Boosting?
Bagging trains independent models on different bootstrapped samples, while Boosting sequentially trains models, with each new model focusing on the residuals (errors) of the previous one.
How does AdaBoost work in boosting?
assigns higher weights to misclassified instances, making the subsequent model focus more on correcting those mistakes. The final prediction is a weighted sum of all models' predictions.
How do you compute the prediction for a new instance in KNN?
The prediction is based on the majority class (for classification) or average value (for regression) of the k nearest neighbors to the new instance, where k is the number of nearest neighbors.
For a new instance with X1=4, X2=6, and k=2, how do you compute the prediction using Euclidean distance?
Compute the Euclidean distance to each training instance. The two closest instances are selected, and their labels are averaged (for regression) or the majority label is chosen (for classification).
How does forward selection work in feature selection?
Start with an empty model. For each predictor, fit a model and calculate the MSE. Add the predictor that minimizes the MSE. Repeat until the desired number of predictors is reached.
How does backward selection work in feature selection?
Start with a model containing all predictors. For each predictor, remove it and fit a model, calculating the MSE. Remove the predictor that results in the smallest decrease in MSE. Repeat until the desired number of predictors is reached.
How does Ridge regression differ from Lasso regression in terms of the penalty term?
Ridge regression uses an L2 penalty (sum of squared coefficients), while Lasso uses an L1 penalty (sum of absolute values of coefficients). Lasso can shrink coefficients to zero, performing feature selection, while Ridge tends to shrink them toward zero without eliminating them.
When should you use Ridge regression instead of Lasso?
Ridge regression is preferable when all predictors are likely to be useful and there is multicollinearity. Lasso is better when you believe some predictors have zero effect on the outcome and you want a sparse model.
What is the purpose of K-fold cross-validation?
It helps estimate the model's performance on unseen data by splitting the dataset into k folds, training on k−1 folds, and testing on the remaining fold. This process is repeated for each fold.
What is nested cross-validation used for?
hyperparameter tuning and model selection. It has an inner loop for hyperparameter tuning and an outer loop for estimating the model's generalization performance.
What is supervised learning?
Supervised learning involves training a model on labeled data, where the input-output pairs are known, to make predictions or classifications on unseen data.
What is the difference between classification and regression in supervised learning?
Classification predicts categorical outcomes, while regression predicts continuous numerical outcomes.
What are the steps in the supervised learning workflow?
1. Define the problem. 2. Collect labeled training data. 3. Choose an algorithm. 4. Train the model. 5. Evaluate the model. 6. Make predictions.
What is unsupervised learning?
a method that involves training a model on data that has no labels, with the goal of discovering hidden patterns or structures (e.g., clustering).
What is clustering in unsupervised learning?
Clustering is the process of grouping similar data points together based on their features.
What is the main goal of dimensionality reduction in unsupervised learning?
The goal is to reduce the number of features while retaining the most important information, making the data easier to visualize or model.
What is the equation for simple linear regression?
Y = B0 + B1X + e, where Y is the dependent variable, X is the independent variable, and e is the irreducible error term.
What do B0 + B1 represent in linear regression?
B0 is the intercept, and B1 is the slope of the regression line.
What is the purpose of the Mean Squared Error (MSE) in linear regression?
MSE measures the average squared difference between the observed values and the values predicted by the model, helping to assess model accuracy.
What is a decision tree in machine learning?
a model that splits the feature space into regions based on certain conditions, making predictions by assigning labels to the leaves of the tree.
What is the Gini Index used for in decision trees?
The Gini Index measures the impurity of a node, helping to determine the best feature to split on.
What is entropy in decision trees?
measures the uncertainty or disorder in a set of data, used to determine the best split during tree construction.
What is Random Forest?
an ensemble learning method that builds multiple decision trees and combines their predictions to improve accuracy and reduce overfitting.
How does Random Forest reduce overfitting?
By averaging predictions from many decision trees trained on different subsets of the data, reducing variance and improving generalization.
How are trees trained in Random Forest?
Trees are trained using bootstrapped samples of the training data, and at each split, a random subset of predictors is considered.
What is Boosting?
an ensemble technique where new models are trained to correct the mistakes (residuals) of previous models, typically using weighted data.
What is K-Nearest Neighbors (KNN)?
a simple algorithm that makes predictions based on the majority class (classification) or average value (regression) of the k closest instances in the training set.
What is cross-validation in machine learning?
a technique used to assess how a model generalizes by splitting the data into multiple folds and training/testing the model on different subsets.
What is the advantage of using cross-validation over a single training/test split?
it provides a more reliable estimate of model performance by using different data splits, reducing the risk of overfitting to a single test set.
What is regularization in machine learning?
a technique that adds a penalty to the loss function to prevent overfitting by discouraging overly complex models.
Why is it important to standardize data when using Ridge regression?
Ridge regression is sensitive to the scale of features, so standardizing ensures that all features contribute equally to the penalty term.
What is the bias-variance tradeoff?
the balance between bias (error from overly simplistic models) and variance (error from overly complex models), which affects model performance.
What happens when a model has high bias?
the model is underfitting, making overly simplistic assumptions about the data and unable to capture the underlying patterns.
What happens when a model has high variance?
the model is overfitting, capturing noise in the training data and performing poorly on unseen data.
What is a Support Vector Machine (SVM)?
a supervised learning algorithm used for classification and regression, which finds the optimal hyperplane that maximizes the margin between classes.
What is the kernel trick in SVM?
it allows SVM to work in high-dimensional spaces by applying a kernel function to map data to a higher-dimensional space, making it easier to find a separating hyperplane.
What is a neural network?
a machine learning model inspired by the human brain, consisting of layers of interconnected nodes (neurons) that process input data and learn complex patterns.
What is an activation function in a neural network?
something that introduces non-linearity into the model, enabling it to learn complex patterns. Examples include ReLU, sigmoid, and tanh.
What is the purpose of backpropagation in neural networks?
the process of adjusting the weights in a neural network by calculating the gradient of the loss function with respect to each weight and updating them accordingly.
What are hyperparameters in machine learning?
parameters that are set before training the model, such as learning rate, number of trees in a random forest, or the depth of a decision tree.
How is grid search used for hyperparameter tuning?
it involves exhaustively searching through a manually specified hyperparameter space to find the best combination of hyperparameters for a given model.
What is random search in hyperparameter tuning?
it selects hyperparameter combinations randomly from the search space and evaluates model performance, often more efficiently than grid search.
What is accuracy in classification models?
the proportion of correctly classified instances out of the total number of instances.
What is precision in classification?
Precision is the proportion of true positive predictions out of all positive predictions made by the model.
What is recall in classification?
the proportion of true positive predictions out of all actual positive instances.
How does Random Forest reduce overfitting compared to a single decision tree?
it reduces overfitting by averaging predictions from multiple trees trained on different data subsets and using random subsets of features at each split.
What is the MSE for f(x) = 1 - 2x on the training set {(-2,6), (-1,2), (0,1), (2,-2), (3.5,-5)}?
Plug in each x, calculate the squared residuals
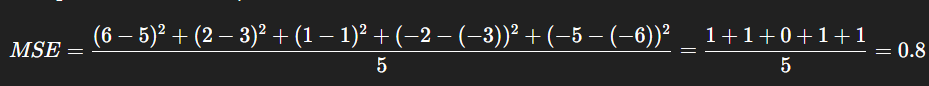
What is the Lasso objective value for an MSE of 0.8 with α = 0.1?
MSE + α * ({|B0| + |B1| = 0.8 + 0.1(1 + 2) = 1.1
What is the Ridge objective value for an MSE of 0.8 with α = 0.1?
MSE + α * ({|B02| + |B12| = 0.8 + 0.1(1² + (-2)²) = 1.3
Which is more flexible: Lasso with α = 0.1 or α = 1?
Lasso with α = 0.1 is more flexible (weaker penalty).
What happens to training MSE when α increases in Ridge or Lasso?
Training MSE increases due to stronger regularization.
What is forward selection in linear regression?
Start with no variables; add one at a time based on lowest MSE.
What is backward selection in linear regression?
Start with all variables; remove one at a time based on highest MSE reduction.
In forward selection, if X3 has the lowest MSE when added alone, what’s the first variable picked?
X3
What is the key limitation of backward selection?
It can remove useful predictors early, and once removed, they’re not reconsidered.
For k = 2, what are the predicted labels for instance 0 using KNN?
Neighbors: 0, 3 → Prediction = (1 + 4)/2 = 2.5
What is the Euclidean distance from point (4,6) to point (1,-1)?
sqrt( (4 - 1)² + (6 - (-1))² ) = sqrt(9 + 49) = sqrt(58) ~ 7.62
What’s the impact of high k in KNN?
Reduces variance but increases bias.
Equation for logistic regression
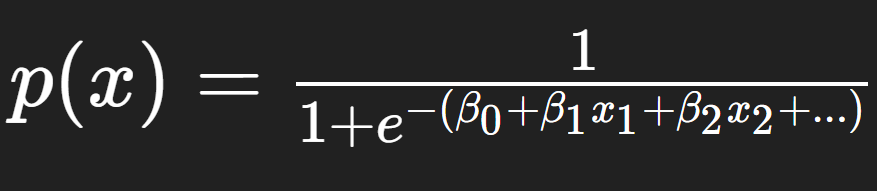
How are the coefficients interpreted in logistic regression?
As the log odds ratio: eβi is the odds ratio for a unit change in xi
If p(x) = 0.7, what are the odds?
Odds = 0.7 / 0.3 = 2.33
What is cost-complexity pruning?
A method to balance tree complexity and accuracy by minimizing E+α∣T∣, where E = error, T = number of leaves.
If tree A has 0 misclassifications and 4 leaves, what’s its cost with α = 2?
C = 0 + 2 × 4 = 8
Which tree is preferred with α = 0.5: Tree A (0 errors, 4 leaves) or Tree B (1 error, 3 leaves)?
Tree B = C = 1 + 0.5 × 3 = 2.5 > 2.0 of Tree A so Tree A
Why does Random Forest outperform a single tree?
It averages multiple de-correlated models, reducing variance.
What does it mean to sample predictors at each split?
At each split, randomly choose a subset of features and pick the best among them.
What type of models are used in Random Forests?
Decision Trees (can be regression or classification).
What’s an “out-of-bag” instance?
A data point not included in a tree’s bootstrap sample; used for validation.
How do Random Forests handle multicollinearity?
By selecting subsets of features at each split, reducing dependency between predictors.
What is a born-again tree?
A simplified tree that mimics the predictions of the entire Random Forest.
In RF, how does increasing number of trees B affect bias/variance?
Bias stays the same, variance decreases.
What is the impact of max_features parameter in RF?
Controls randomness; low value increases diversity, high value reduces variance.
What happens to model bias in boosting?
Bias decreases as boosting reduces training error.
What is the effect of overfitting in boosting?
Boosting can overfit if too many trees or too complex trees are used.
Why are shallow trees (stumps) used in boosting?
To keep models weak because it focuses on combining many simple models.
In classification, how does AdaBoost combine trees?
Weighted majority vote, where each tree’s weight depends on accuracy.
What does boosting optimize in regression?
It minimizes the residual (loss) in each iteration.
Why is boosting more prone to overfitting than bagging?
Because models are built sequentially on mistakes, which may reinforce noise.
What is the formula for accuracy?
TP + TN / All
What is precision?
TP / TP + FP
What is recall?
TP / TP + FN
What is the F1 score?
Harmonic mean of precision and recall: 2× (P * R) / (P + R)
When is precision more important than recall?
When false positives are more costly (e.g., spam filter)
When is recall more important than precision?
When false negatives are more costly (e.g., cancer detection)
What is model interpretability?
The ability to understand and explain how a model makes predictions.
Why is interpretability important in healthcare or legal systems?
Decisions must be explainable and justifiable to stakeholders or courts.
What is the main downside of ensemble methods like RF/Boosting?
They reduce interpretability compared to simpler models like linear regression.
What is univariate imputation?
Filling missing values with the mean, median, or mode of the column.
What is multivariate imputation?
Using multiple other features to predict and fill in missing values.
What is MICE?
Multiple Imputation by Chained Equations—an iterative technique for filling missing values.
Why is standardization important for regularization models?
To ensure all variables are on the same scale, especially important for penalty terms.
What is multicollinearity and how is it detected?
High correlation among predictors, detected with VIF > 10.